前言:
本人的一些简历上要回答的点。所以再此整理。
亮点:
使用Filter过滤器进行未登录状态自动跳转到登录页面的拦截,实现统一的权限管理。
1 登陆功能
1.1实体类和结果类
前端页面


约定 res.data.code为1时是登录成功。
数据库的employee员工表:
员工表存储员工的用户名、密码、身份证等信息,用来后台页面登录。

这里password是加密后的数据,真实数据是123456
创建实体类Employee
@Data
//实体类实现Serializable接口,把对象转换为字节序列。序列化操作用于存储时,一般是对于NoSql数据库。
public class Employee implements Serializable {
//在反序列化的过程中,如果接收方为对象加载了一个类,如果该对象的serialVersionUID与对应持久化时的类不同,那么反序列化的过程中将会导致InvalidClassException异常。
private static final long serialVersionUID = 1L;
@JsonFormat(shape = JsonFormat.Shape.STRING)
private Long id;
private String username;
private String name;
private String password;
private String phone;
private String sex;
private String idNumber;
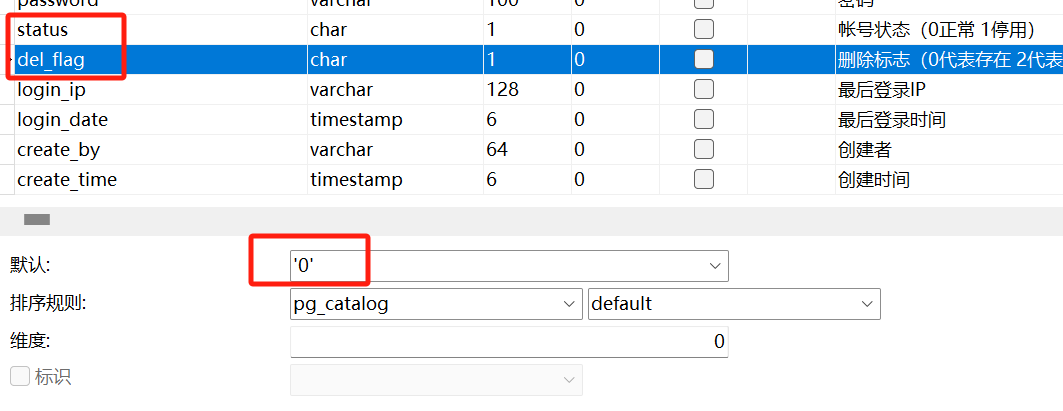
private Integer status;
@TableField(fill=FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(fill =FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
//阿里巴巴的开发规范中推荐每个表都带有一个createTime 和一个 updateTime, 但是每次自己手动添加太麻烦了,可以配置MP让其自动添加,使用@TableField的fill注解。
@TableField(fill = FieldFill.INSERT)
@JsonFormat(shape = JsonFormat.Shape.STRING)
private Long createUser;
@TableField(fill = FieldFill.INSERT_UPDATE)
@JsonFormat(shape = JsonFormat.Shape.STRING)
private Long updateUser;
}
R结果类:
//用泛型格式,如果controller返回的是页面数据,则return R.success(page);如果返回的是成功消息,则return R.success("success");如果返回错误消息,return R.error("错误原因");
@Data
public class R<T> {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
private Map map = new HashMap(); //动态数据
//静态类,controller返回时直接return R.success(T);
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
//添加动态数据
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
1.2 dao,service,controller
dao层:
@Mapper
public interface EmployeeDao extends BaseMapper<Employee> {
}service层:
public interface EmployeeService extends IService<Employee> {
}
@Service
public class EmployeeServiceImpl extends ServiceImpl<EmployeeDao, Employee> implements EmployeeService {
}这里业务接口继承了IService,业务实现类继承了ServiceImpl<M extends BaseMapper, T>,这样service就继承了Mybatis-plus的各方法、变量。
ServiceImpl<M extends BaseMapper, T>类各方法(未过期)的作用
getBaseMapper() getEntityClass() saveBatch() saveOrUpdate() saveOrUpdateBatch() updateBatchById() getOne() getMap() getObj() ServiceImpl类各属性的作用
log:打印日志 baseMapper:实现了许多的SQL操作 entityClass:实体类 mapperClass:映射类
controller层:

@Slf4j
@RestController
@RequestMapping("/employee")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
/**
* 员工登录
* @param request
* @param employee
* @return
*/
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request,@RequestBody Employee employee){
//1、将页面提交的密码password进行md5加密处理。同一个数据多次md5加密的结果是一样的,所以md5不能解密,但可以通过碰撞解密。
String password = employee.getPassword();
password = DigestUtils.md5DigestAsHex(password.getBytes());
//2、根据页面提交的用户名username查询数据库
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(Employee::getUsername,employee.getUsername());
Employee emp = employeeService.getOne(queryWrapper);
//3、如果没有查询到则返回登录失败结果
if(emp == null){
return R.error("用户名或密码错误");
}
//4、密码比对,如果不一致则返回登录失败结果
if(!emp.getPassword().equals(password)){
return R.error("登录失败");
}
//5、查看员工状态,如果为已禁用状态,则返回员工已禁用结果
if(emp.getStatus() == 0){
return R.error("账号已被禁用");
}
//6、登录成功,将员工id存入Session并返回登录成功结果
//被忘了存Session,默认有效期30分钟
request.getSession().setAttribute("employee",emp.getId());
return R.success(emp);
}
/**
* 员工退出
* @param request
* @return
*/
@PostMapping("/logout")
public R<String> logout(HttpServletRequest request){
//清理Session中保存的当前登录员工的id
request.getSession().removeAttribute("employee");
return R.success("退出成功");
}
}
@Slf4j
@RestController
@RequestMapping("/employee")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
/**
* 员工登录
* @param request
* @param employee
* @return
*/
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request,@RequestBody Employee employee){
//1、将页面提交的密码password进行md5加密处理。同一个数据多次md5加密的结果是一样的,所以md5不能解密,但可以通过碰撞解密。
String password = employee.getPassword();
password = DigestUtils.md5DigestAsHex(password.getBytes());
//2、根据页面提交的用户名username查询数据库
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(Employee::getUsername,employee.getUsername());
Employee emp = employeeService.getOne(queryWrapper);
//3、如果没有查询到则返回登录失败结果
if(emp == null){
return R.error("用户名或密码错误");
}
//4、密码比对,如果不一致则返回登录失败结果
if(!emp.getPassword().equals(password)){
return R.error("登录失败");
}
//5、查看员工状态,如果为已禁用状态,则返回员工已禁用结果
if(emp.getStatus() == 0){
return R.error("账号已被禁用");
}
//6、登录成功,将员工id存入Session并返回登录成功结果
//被忘了存Session,默认有效期30分钟
request.getSession().setAttribute("employee",emp.getId());
return R.success(emp);
}
/**
* 员工退出
* @param request
* @return
*/
@PostMapping("/logout")
public R<String> logout(HttpServletRequest request){
//清理Session中保存的当前登录员工的id
request.getSession().removeAttribute("employee");
return R.success("退出成功");
}
}MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。
md5是一种不可逆的加密,一定记住是不可逆的。即得到密文无法还原明文。
同一个数据多次md5加密的结果是一样的,所以md5不能解密,但可以通过碰撞解密。
比如你得到一个md5加密串"E10ADC3949BA59ABBE56E057F20F883E",你有N个密码,通过md5加密加密N个密码,得到其中一个和"E10ADC3949BA59ABBE56E057F20F883E"一致,那么则密码一致。
md5解密网站(实际是靠碰撞解密):md5在线解密破解,md5解密加密
登出功能:删除Session
@RequestMapping("/logout")
public R logout(HttpServletRequest request){
//尝试删除
try {
request.getSession().removeAttribute("employee");
}catch (Exception e){
//删除失败
return R.error("登出失败");
}
return R.success("登出成功");
}可以看到点击退出后就清除存储信息了。


1.3 拦截页面登陆(添加过滤器,未登录状态自动跳转登录页面)
这里的话用户直接url+资源名可以随便访问,所以要加个拦截器或者过滤器,没有登陆时,不给访问,自动跳转到登陆页面。
过滤器和拦截器回顾
拦截器和过滤器之间的区别:
归属不同:Filter属于Servlet技术,依赖于Servlet容器;Interceptor属于SpringMVC技术,不依赖于servlet容器。 拦截内容不同:Filter对所有访问进行增强,几乎对所有请求起作用;Interceptor仅针对SpringMVC的访问进行增强,只能对action请求起作用。 调用次数不同:在action的生命周期中,过滤器只能在容器初始化时被调用一次,而拦截器可以多次被调用。 获取bean的权限不同:过滤器不能获取IOC容器中的各个bean;拦截器就可以,因为拦截器本身是个bean。这点很重要,在拦截器里注入一个service,可以调用业务逻辑。 底层机制不同:过滤器是基于函数回调,拦截器是基于java的反射机制的。
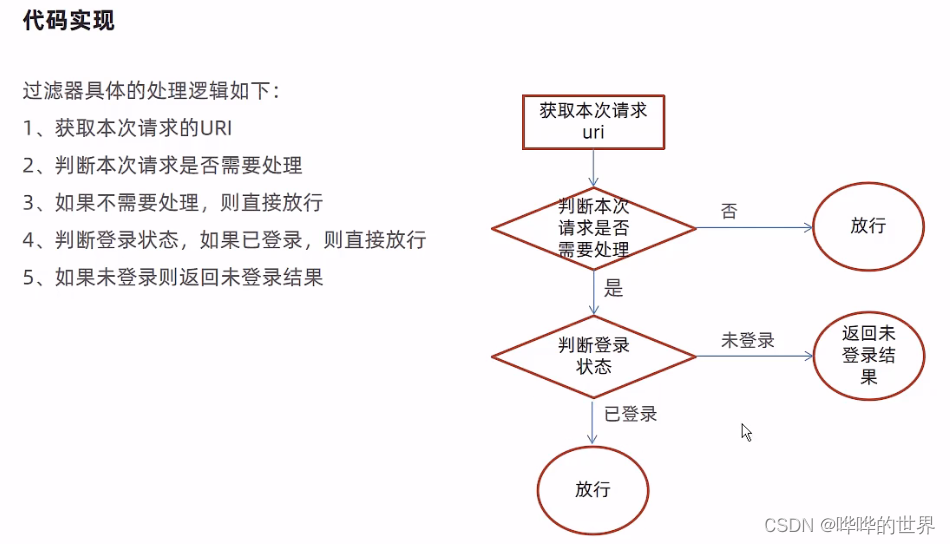
代码实现:
1.在引导类注解**@ServletComponentScan**
2.在filter包下编写过滤器
//坑点,路径是"/*",别忘了*
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter{
//路径匹配器,支持通配符,别忘了
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
//0.要先把请求响应ServletXxx转成它的子接口HttpServletXxx,从而多了一些针对于Http协议的方法
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
//1、获取本次请求的URI
String requestURI = request.getRequestURI();// /backend/index.html
log.info("拦截到请求:{}",requestURI);
//定义不需要处理的请求路径,前端页面可以放行,只是除登录登出的后端拦截就行。
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
//2、判断本次请求是否需要处理
boolean check = check(urls, requestURI);
//3、如果不需要处理,则直接放行
if(check){
log.info("本次请求{}不需要处理",requestURI);
filterChain.doFilter(request,response);
return;
}
//4、判断登录状态,如果已登录,则直接放行
if(request.getSession().getAttribute("employee") != null){
log.info("用户已登录,用户id为:{}",request.getSession().getAttribute("employee"));
filterChain.doFilter(request,response);
return;
}
log.info("用户未登录");
//5、如果未登录则返回未登录结果,通过输出流方式向客户端页面响应数据
//必须错误信息NOTLOGIN,因为前端根据msg==“NOTLOGIN”和code==0判断未登录
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 路径匹配,检查本次请求是否需要放行
* @param urls
* @param requestURI
* @return
*/
public boolean check(String[] urls,String requestURI){
for (String url : urls) {
//这里是坑点,不能用equals
boolean match = PATH_MATCHER.match(url, requestURI);
if(match){
return true;
}
}
return false;
}
}坑点:
- 0.别忘了引导类注解@ServletComponentScan
- 1.通配符/*,别忘了*号
- 2.别忘了创建静态final对象AntPathMatcher ,用它的match()方法进行url匹配,不能用equals
响应到前端的是否登录信息将在requeset.js中处理:
其实所有前端页面都引用了js/request.js里的前端拦截器,前端拦截器完成跳转到登陆页面,不在后端做处理