目录
1 数据准备与可视化
2 简单数据探索与清洗
3 差分处理
4 绘制ACF与PACF图像,完成模型选择
5 建立ARIMA和SARIMA模型
5.1 初步建模
5.2 精细化建模
5.3 最终的模型
ARIMA作为成熟的统计学模型已被各种软件以各种方式实现,在Python中我们最常使用的一般是statsmodel库。statsmodels是Python中专用于统计模型估计、统计测试和统计数据探索的库。现在我们就使用数据集1 (下载链接) 中的负荷数据进行实验,来实现statsmodel下的ARIMA模型。
我们在ARIMA建模之前完成平稳性检验、样本的相关性检验,并在ARIMA建模完成之后完成一系列验证白噪声的混成检验,不过有时候我们会省略样本相关性检验,因为我们将在ARIMA建模过程中使用ACF和PACF辅助判断ARIMA模型的参数,如果样本与样本之间缺乏相关性,我们在绘制ACF和PACF时就能够发觉这一点。在开始建模之前,我们需要简单复习一下ARIMA模型实验的基本流程
- 序列平稳化检验;确定d值
- 确定p值和g值
- 参数估计与诊断检验
- 预测未来的值
1 数据准备与可视化
首先导入实验需要的库文件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline然后读取数据并进行可视化,本数据原始数据是多输入单输出的数据,需要进行截取,变成单输入单输出数据
data=pd.read_csv(r'C:\Users\Qin\Myfile\07课题组\05学习案例\Machine-Learning-for-Time-Series-Forecasting-main\Notebooks\data\energy.csv')
#可视化
data.plot(figsize=(10,5),grid=True);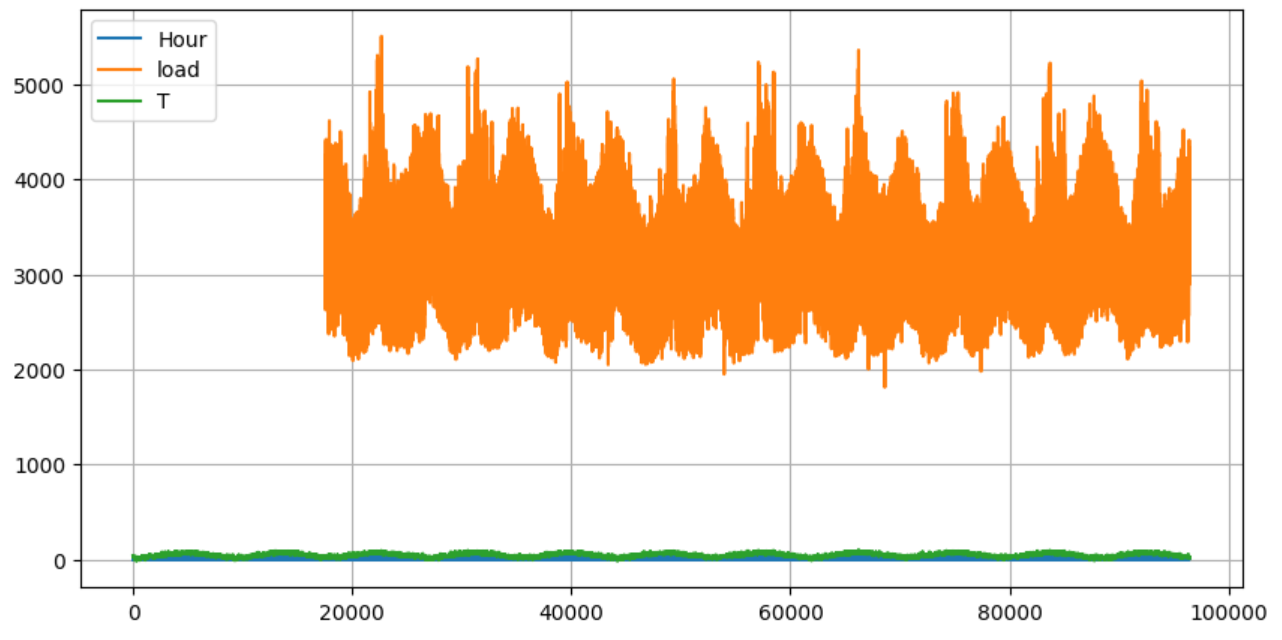
通过可视化发现,发现标签load前面存在大量缺失值,同时时间和特征Hour可以合并,对原始数据进行截取
# 将数据变成单输入单输出数据
df = pd.DataFrame(data, columns=['Date', 'load'])
# 将时间和特征Hour可以合并
df['Date'] = data["Date"].astype(str) + ' ' + data["Hour"].astype(str)
# 截取20天的数据并重置索引
df = df[17544:17544+24*20].reset_index(drop=True)2 简单数据探索与清洗
首先检查数据类型和缺失值
#检查是否数据类型和缺失值
df.info()### 输出 ###
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 480 entries, 0 to 479
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 480 non-null object
1 load 480 non-null float64
dtypes: float64(1), object(1)
memory usage: 7.6+ KB最后对使用的数据进行可视化
df.plot(figsize=(12,5),grid=True);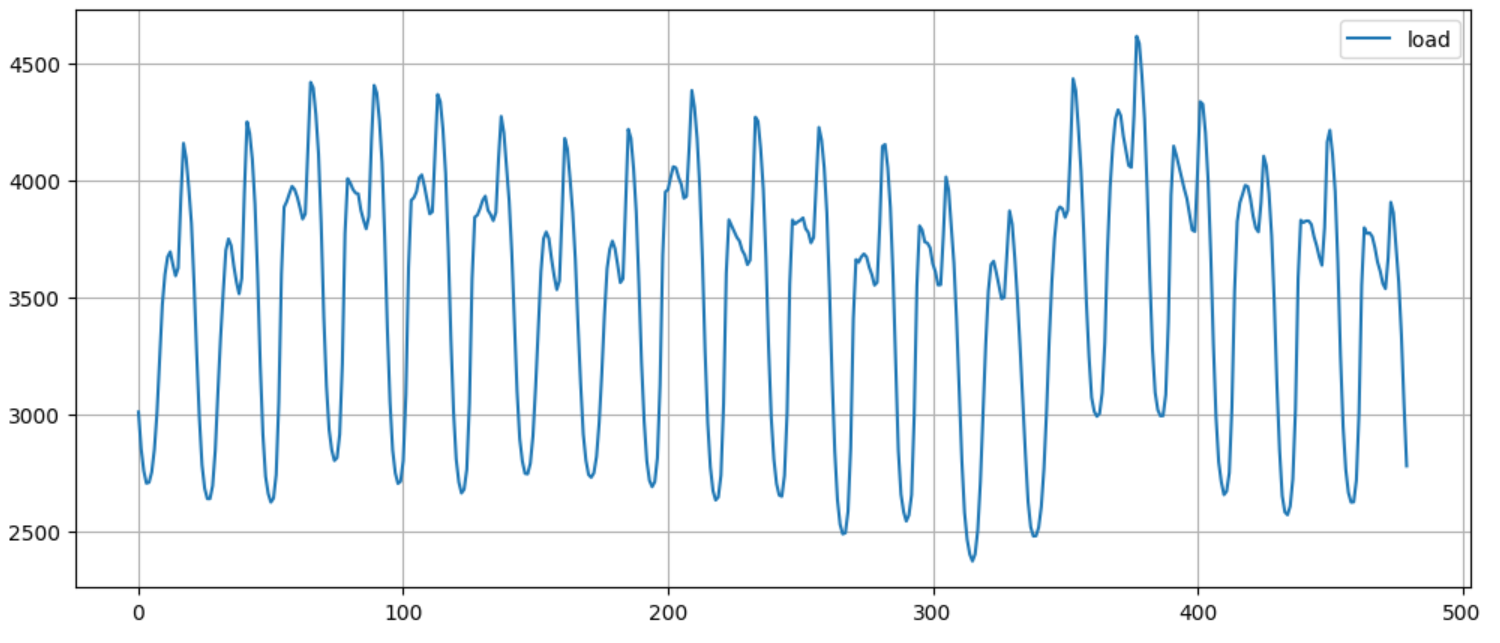
很明显,数据具有周期性,因此数据大概率是无法满足平稳性条件的。具体地来说,每天会出现一个峰值、一个谷底,峰值出现在每天的用电高峰,谷底出现在夜晚用电低谷。接下来我们进行平稳性检验。
- 假设检验:平稳性检验
在使用统计学模型进行建模时,我们往往需要完成一系列假设检验的工作。对ARIMA模型而言,我们必须要完成的建模前检验主要是平稳性检验。对ARIMA模型来说,如果数据是不平稳的、比如带有持续上升或下降的趋势、或者数据在不同时间阶段的波动程度明显不同,那我们则需要对数据进行差分处理直到数据平稳为止。
通过前文的讲解,在这里我们将要使用的是ADF单位根检验。在概率论与数理统计当中,单位根是趋势性的象征。如果一个序列中存在单位根,那该序列应该有较强的趋势性,在这样的序列上建模的难度会很大、模型也很容易失效,因此单位根检验能够帮助我们判断“趋势”这一因素在多大程度上影响了一个时间序列的值。如果在检验中我们发现单位根存在,则说明该时间序列受到“趋势”影响很大。
在这个检验中,两项假设如下:
- 原假设H0:数据是不平稳序列。如果该假设没有被拒绝,则表示时间序列里有单位根,意味着它是不平稳的,它很大程度上受到“趋势性”的影响。
- 备择假设H1:数据是平稳的。如果拒绝原假设,则说明该时间序列没有单位根,则数据是平稳的,它基本不受“趋势性”的影响。
在测试中,我们使用测试的p值来解释这个结果:
- p>0.05:无法拒绝原假设,数据有单位根且不平稳。
- p<=0.05:拒绝原假设,数据没有单位根,是平稳的序列。
# ADF检验
result=adfuller(df['load']) #这就可以完成一次检验
result### 输出 ###
(-2.7122595076597857,
0.07194075827270735,
18,
461,
{'1%': -3.4446148284445153,
'5%': -2.8678299626609314,
'10%': -2.5701203107928157},
5237.469230118977)以上返回的结果分别是检验值、p值、使用的滞后数、使用的样本数、在1%、5%、10%显著性水平上的检验值、以及当前数据上使用ARIMA时可能的AIC值。在这些值当中,我们最为关心前2项数值,因此我们可以将前2项打包到函数中,并让函数直接输出检验的结果:
def adfuller_test(sales):
#将唯一的标签:销售额放入检验
result=adfuller(sales)
#让statsmodel的DF单位根检验为我们返回检验值 & p值 & 添加了多少滞后 & 使用的样本量
labels = ['ADF Test Statistic','p-value']
#打包标签和结果
for value,label in zip(result,labels):
print(label+' : '+str(value) )
#如果p值小于等于0.05,则说明我们可以拒绝原假设,认为数据是平稳的。如果p值大于0.05,则说明我们需要接受原假设,数据不平稳。
if result[1] <= 0.05:
print("拒绝原假设,数据具有平稳性")
else:
print("无法拒绝原假设,数据不平稳")
return result[1]
pvalue = adfuller_test(df['load'])### 输出 ###
ADF Test Statistic : -2.7122595076597857
p-value : 0.07194075827270735
无法拒绝原假设,数据不平稳3 差分处理
编写函数通过循环,查看究竟多少步差分能够让这一序列满足单位根检验,如果许多差分都能够满足单位根检验,我们通常选择ADF值最小、或差分后数据方差最小的步数
#可以通过循环,查看究竟多少步差分能够让这一序列满足单位根检验
#如果许多差分都能够满足单位根检验,我们通常选择ADF值最小、或差分后数据方差最小的步数
columns = ["D1","D2","D3","D4","D5","D6","D7","D8","D9","D10","D11","D12","D24","D36"]
pvalues = []
stds = []
for idx,degree in enumerate([*range(1,13),24,36]):
#打印差分的步数
print("{}步差分".format(degree))
#计算差分列
df[columns[idx]] = df['load'] - df['load'].shift(idx+1)
#进行ADF检验,提取P值,并计算差分列的标准差
pvalue = adfuller_test(df[columns[idx]].dropna())
std_ = df[columns[idx]].std()
#保存P值和标准差
pvalues.append(pvalue)
stds.append(std_)
#对结果进行打印
print("差分后数据的标准差为{}".format(std_))
print("\n")### 输出 ###
1步差分
ADF Test Statistic : -15.04966453828655
p-value : 9.33360597580164e-28
拒绝原假设,数据具有平稳性
差分后数据的标准差为196.46922954307323
2步差分
ADF Test Statistic : -16.29765178325621
p-value : 3.290283138175626e-29
拒绝原假设,数据具有平稳性
差分后数据的标准差为370.118759085922
3步差分
ADF Test Statistic : -18.10835313744563
p-value : 2.5417172879071722e-30
拒绝原假设,数据具有平稳性
差分后数据的标准差为516.0701985963952
4步差分
ADF Test Statistic : -12.212093452012402
p-value : 1.1575596271658605e-22
拒绝原假设,数据具有平稳性
差分后数据的标准差为637.530782228096
5步差分
ADF Test Statistic : -8.427256072491113
p-value : 1.9119982547299384e-13
拒绝原假设,数据具有平稳性
差分后数据的标准差为735.5323395039408
6步差分
ADF Test Statistic : -3.808930036426557
p-value : 0.002817259184627013
拒绝原假设,数据具有平稳性
差分后数据的标准差为809.0926365719258
7步差分
ADF Test Statistic : -8.065521894930814
p-value : 1.6002046598852696e-12
拒绝原假设,数据具有平稳性
差分后数据的标准差为858.9712521678126
8步差分
ADF Test Statistic : -3.986627589360495
p-value : 0.0014821747210727353
拒绝原假设,数据具有平稳性
差分后数据的标准差为888.1440385449231
9步差分
ADF Test Statistic : -5.2743084989186535
p-value : 6.188084027315802e-06
拒绝原假设,数据具有平稳性
差分后数据的标准差为899.8903760966008
10步差分
ADF Test Statistic : -5.452074920857974
p-value : 2.6307700522164034e-06
拒绝原假设,数据具有平稳性
差分后数据的标准差为900.7550646561206
11步差分
ADF Test Statistic : -6.121643384720841
p-value : 8.826171805323979e-08
拒绝原假设,数据具有平稳性
差分后数据的标准差为899.4711717537107
12步差分
ADF Test Statistic : -3.8927045263314537
p-value : 0.0020891986455885032
拒绝原假设,数据具有平稳性
差分后数据的标准差为899.9772611011314
24步差分
ADF Test Statistic : -5.1781941701238425
p-value : 9.73951803250042e-06
拒绝原假设,数据具有平稳性
差分后数据的标准差为901.6634469701739
36步差分
ADF Test Statistic : -4.145310100643183
p-value : 0.0008143374624994226
拒绝原假设,数据具有平稳性
差分后数据的标准差为905.2053218960154通过可视化p值和标准差输出可以看到,差分都能够满足单位根检验,标准差呈现递增的趋势,此时最优的差分步为0,考虑到负荷数据具有明显的以天为单位的周期性,可也考虑最优的差分步为24,在SARIMA模型中有差分步参数的设置,ARIMA模型中只有差分阶数的设置。
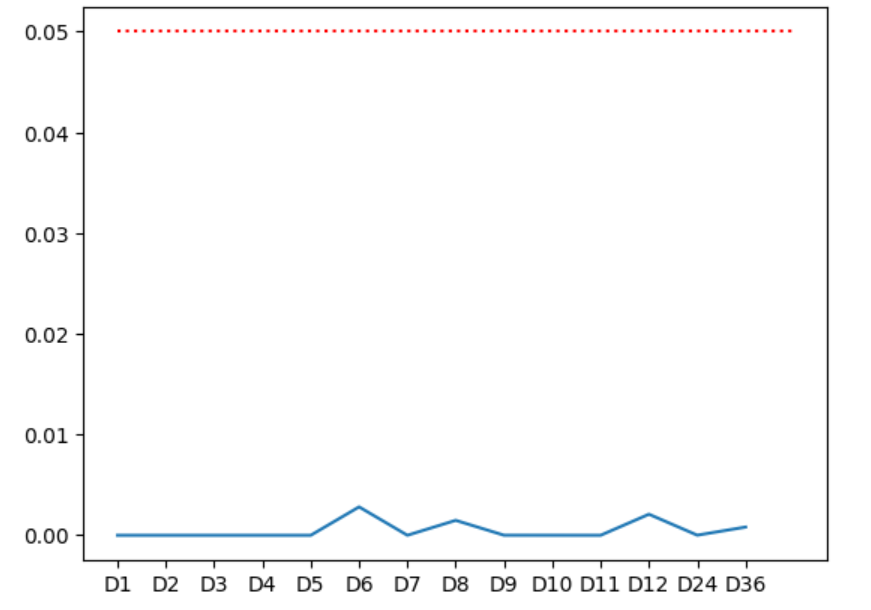
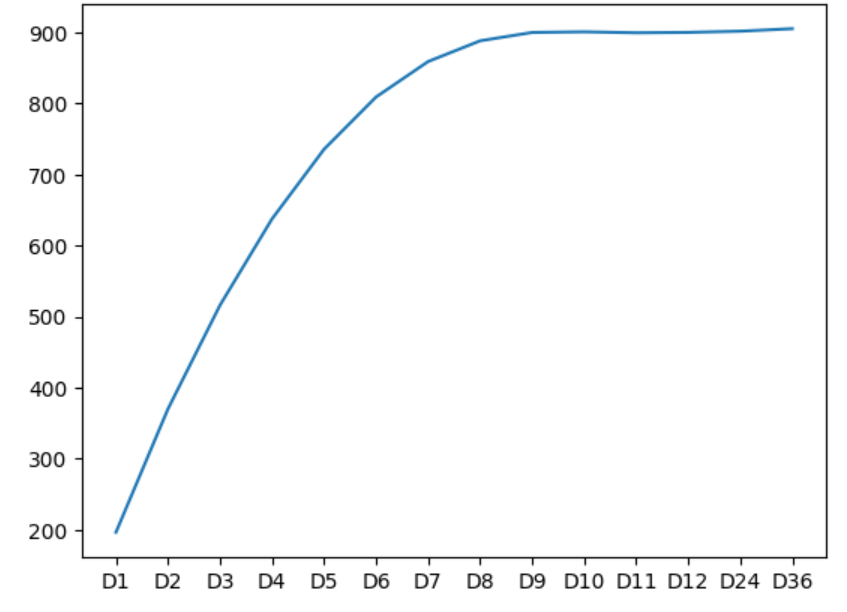
4 绘制ACF与PACF图像,完成模型选择
绘制ACF与PACF图像,完成模型选择
from statsmodels.tsa.arima_model import ARIMA
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf,plot_pacffig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(df['D1'].dropna(),lags=40,ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(df['D1'].dropna(),lags=40,ax=ax2)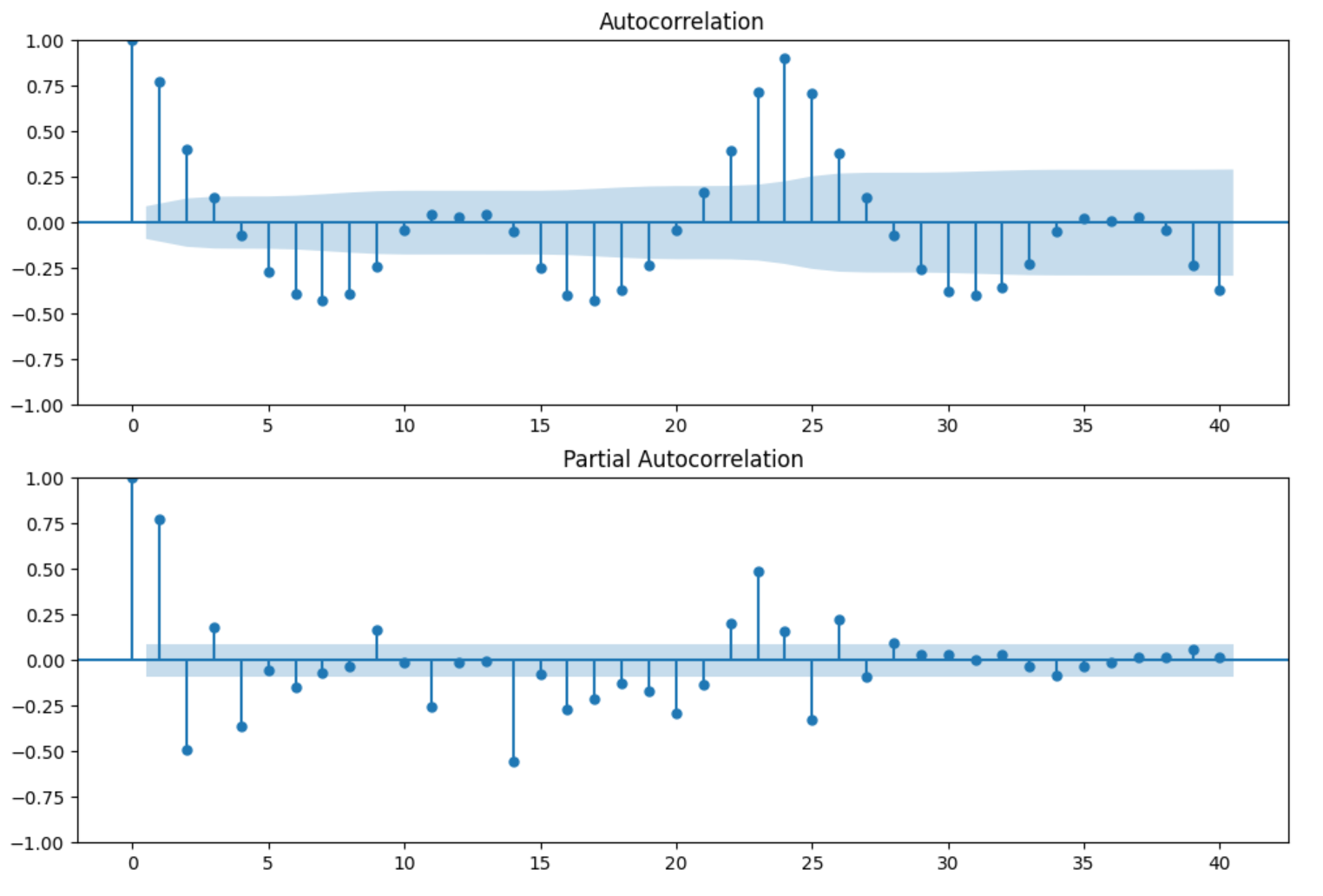
观察ACF和PACF的状态,很明显,两个自相关系数都没有呈现拖尾的情况、而是更加随机地排列,因此p和q都不为0,在确定p和q都不为0后,我们需要先确定合适的d值、再建模寻找合适的p和q。根据之前我们讲解的理论,我们一般会尝试[0,1,2,3]阶差分,并取这些差分当中不存在过差分问题的、方差较小、噪音较少的阶数作为d的取值。当我们对数据的ACF绘图时,如果滞后为1的ACF为负,就说明数据存在过差分问题。依据这些理论,我们来打印4个不同阶差分的标准差和ACF图像:
from statsmodels.graphics.tsaplots import plot_acf
diff = [df['load'],df['load'].diff().dropna()
,df['load'].diff().diff().dropna()
,df['load'].diff().diff().diff().dropna()
]
titles = ["d=0","d=1","d=2","d=3"]
fig, (ax1, ax2, ax3, ax4) = plt.subplots(4,1,figsize=(8,14))
for idx, ts, fig, title in zip(range(4),diff,[ax1,ax2,ax3,ax4],titles):
print("{}阶差分的标准差为{}".format(idx,ts.std()))
plot_acf(ts, ax=fig, title=title)### 输出 ###
0阶差分的标准差为538.1409590325272
1阶差分的标准差为196.46922954307325
2阶差分的标准差为131.69638621457582
3阶差分的标准差为153.37183416857923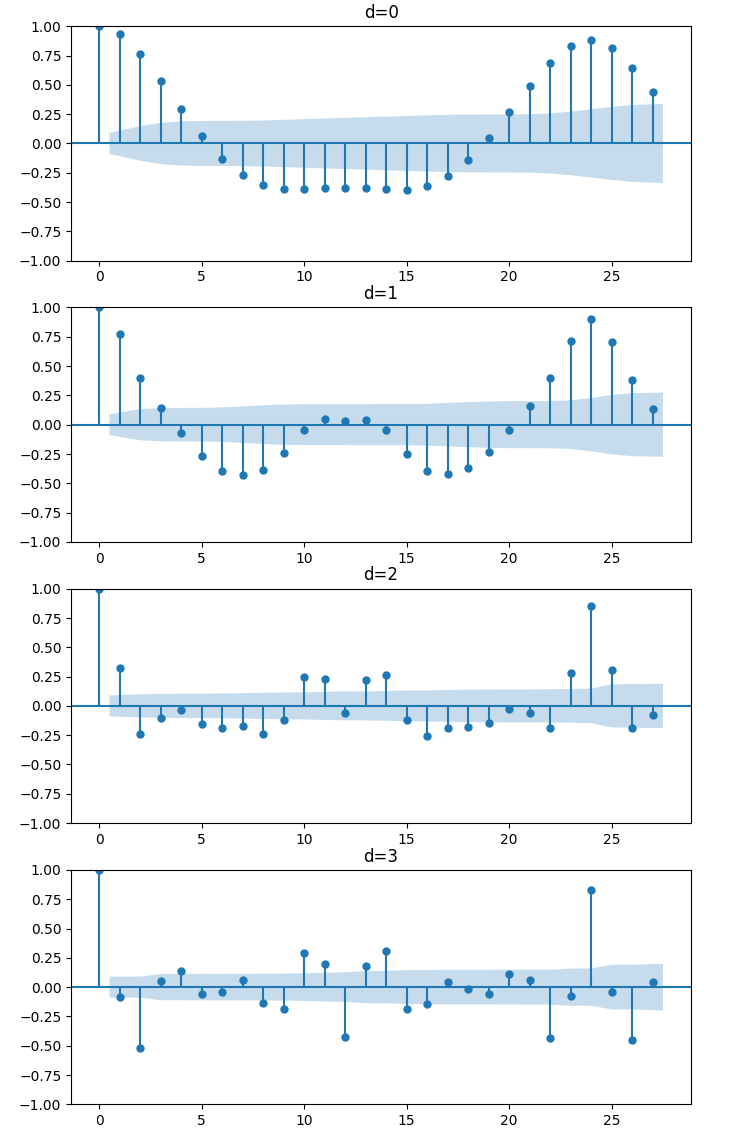
很明显,d=3出现了“过差分”的情况(滞后为1的ACF值为负),d=2 的标准差小于任何差分数据,因此我们可以判断对ARIMA模型而言最佳的d取值为2。
在这里,除了ARIMA(p,d,q)之外,我们还可以考虑使用SARIMA(p,d,q,s)模型。SARIMA是季节性ARIMA模型,非常擅长处理周期性数据,它的前三个超参数含义与ARIMA完全相同,而最后一个超参数s则代表差分的步数,这说明SARIMA模型可以同时完成多步差分和高阶差分两个任务,相比之下ARIMA模型只能做高阶差分。
在之前的平稳性检验中,我们已经知道当前时间序列具有较强的周期性、且能够让序列变得平稳的最佳选择是24步差分,因此自带多步差分功能、且擅长处理周期性数据的SARIMA模型可能是更好的选择。SARIMA模型规定,当原始序列明显周期性明显时,d的值至少是2,因此我们可以暂时将SARIMA模型的d值确认为2。
5 建立ARIMA和SARIMA模型
5.1 初步建模
首先导入库文件,并忽视不必要的警告信息。
import statsmodels
from statsmodels.tsa.arima.model import ARIMA
#在0.12及以上版本的statsmodel中,ARIMA一个类可以实现AR、MA、ARMA、ARIMA和SARIMA模型
from pandas.tseries.offsets import DateOffset
# ignore警告
import warnings
warnings.filterwarnings("ignore")初步建立模型,预测的时间为最后一天的数据
#对每个备选模型,我们进行训练、打印训练结果,并绘制预测图像
arima_0=ARIMA(endog = df['load'],order=(1,0,1))
arima_0=arima_0.fit()
df['arima']=arima_0.predict(start=480-24,end=480,dynamic=True)
df[['load','arima']].plot(figsize=(12,4));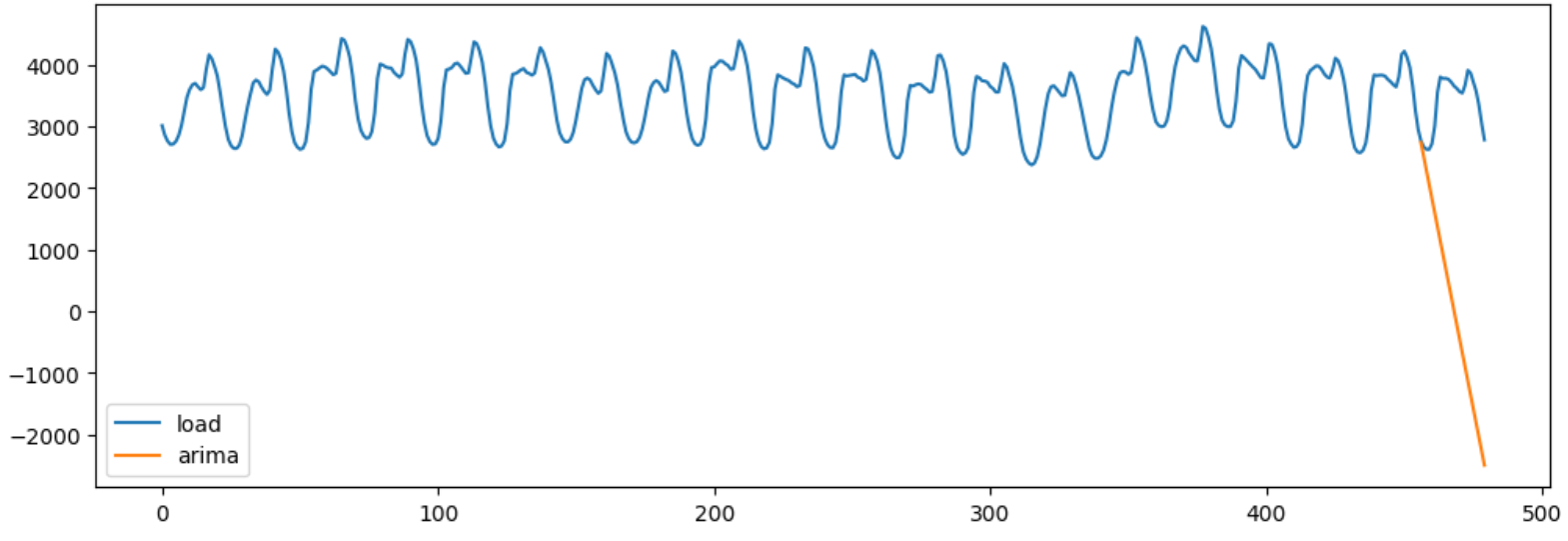
从预测出的图像我们大概可以看出模型在预测上没有任何作用,当预测的图像不合格时我们可以直接更换参数,当预测的图像看起来相对合理时我们可以打印当前模型的更多详情进行查看。
5.2 精细化建模
#alpha:人为规定的显著性水平,一般都使用0.05或者0.01
print(arima_0.summary(alpha=0.05))输出后标记summary中参数的具体含义,帮助我们更好的建模
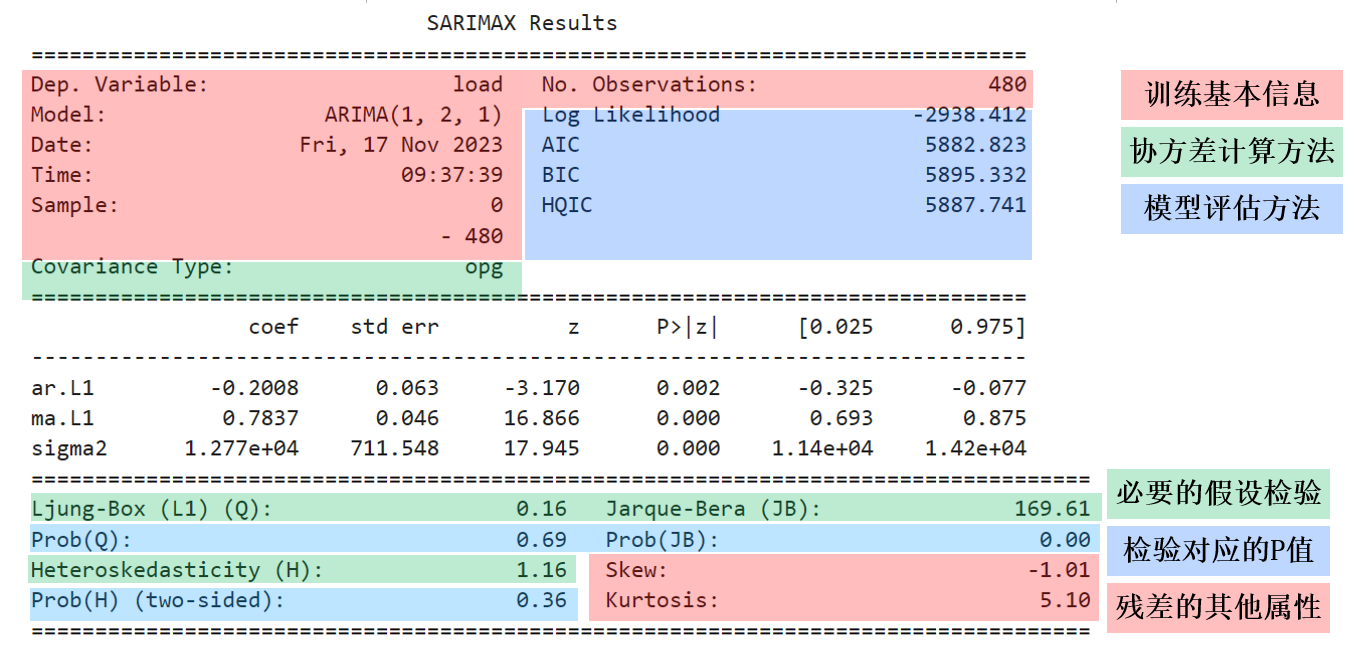
summary方法返回的第一部分是当前模型最基本的信息和最基本的评估指标。如上图所示,训练的基本信息,包括了当前建立的ARIMA模型、建模时间、样本数量等等信息。
在statsmodels中存在6种以上不同的协方差计算方法,默认的方法是opg(即等同于皮尔逊相关系数中的协方差计算方法),一般保持默认的选项。
值得注意的是模型评估方法,这里列出的四个指标分别是对数似然估计、AIC、BIC、HQIC四个评估指标,其中对数似然估计Log Likehood是越大越好,而其他三个指标AIC、BIC和HQIC是越小越好。通常来说我们会直接关注AIC的指标,优先选出AIC最低的模型进行进一步的参数选取。
summary方法返回的第二部分(没有标记部分)展示了训练好的ARIMA模型中每一个具体的项的值、以及这些项的显著性水平,结合第二部分和我们建立的ARIMA模型时设置的p、d、q值,我们可以写出当前ARIMA模型的具体公式:
以现在的ARIMA(1,2,1)为例,当前ARIMA由MA(1)和RA(1)共同构成,因此公式如下:
![]()
在这个公式中,常数![]() 对应着表格左侧第一项
对应着表格左侧第一项const,AR模型的唯一项![]() 对应着
对应着ar.L1,MA模型的唯一项![]() 就对应着
就对应着 ma.L1。如此不难发现,ar.L1中的L1指的是滞后1,表示值带有滞后1这一项的AR模型,ma.L1同理。你可以看到,该表格中左侧的项是与ARIMA的项一 一对应的,因此当我们设置的p、d、q值不同时,该表格中反馈的项也会不一样。
在此基础上,该表格中值得关注的列有:
- coef:该项的系数,比如
ar.L1的coef就是𝛽1的取值,ma.L1的coef就是𝜃1的取值。当该项是常数项时,coef就等于该项本身。- std err:当前项的标准误,衡量当前项对整个ARIMA模型的预测损失的影响。一个项的std err越大,说明这个项对当前模型的损失贡献越大,说明模型对这个项的参数估计可能越不准确。
- 𝑷>|𝒛|:该项的系数在统计学上是否显著的p值。在这里我们完成的是针对每一个系数的单变量检验。
单变量检验的原假设(H0):当前系数coef为0(当前项与标签不相关)
单变量检验的备择假设(H1):当前系数coef不为0(当前项与标签相关)很明显,对模型来说理想的状态是拒绝原假设、接受备择假设,因此在我们规定的显著性水平𝛼(0.05)下,如果有任意项的p值大于𝛼,则说明当前项的系数没能通过显著性检验,模型对当前项的系数没有足够的信心。例如,在当前表格中,ar.L1的p值为0,小于显著性水平0.05,则说明系数0.7837是可靠的。
在一个模型当中,如果很多系数的p值都大于0.05,则可能说明模型处于复杂度过高的状态(即,许多项看起来都与标签无关,所以我们可能创造了许多原本不需要的项)。此时我们可以选择更简单的模型。
在读表格的这一部分的时候,我们首先会观察p值,确定是否有任何项的p值大于我们设置的显著性水平𝛼。如果存在这样的项,那我们大概率就不会关注当前的模型了。在ARIMA模型选择过程中,我们选出的模型应当是所有项的p值都小于显著性水平的模型。
Summary表单的第三部分是针对残差完成的各项假设检验。在混成检验的定义中,残差是真实标签与当前ARIMA的预测标签之间的差异,即:
𝒓=𝒚−𝒚̂
需要注意的是,MA模型求解过程中不断估计出的 [𝜖𝑡,𝜖𝑡−1,...,𝜖𝑡−𝑘] 也是残差,但建模过程中估计出的残差与建模结束后才计算的残差序列𝒓具体数值上有巨大的差别。序列𝒓是在ARIMA模型训练完毕后才结合真实标签计算出来的,因此相当于使用了最后、最新的、迭代完毕的𝛽值,而MA模型中的[𝜖𝑡,𝜖𝑡−1,...,𝜖𝑡−𝑘]是一系列中间变量,在模型迭代过程中会不断发生变化。注意不要混淆两个残差序列。
statsmodel中的ARIMA自动完成以下三项检验:
- Ljung-Box test,为LBQ检验。LBQ检验是检查样本之间是否存在自相关性的检验。在查看LBQ测试的p值时,我们希望这是一个大于显著性水平(0.05)、令我们接受原假设的p值。
LBQ检验原假设(H0):样本之间是相互独立的
LBQ检验备择假设(H1):样本之间不是相互独立的,存在一些内在联系总结一下,LBQ下的Prob(Q)项大于0.05时模型可用,否则可考虑更换模型的超参数组合。
- Heteroskedasticity test,异方差检验。在一个序列当中,随机抽出不同的子序列并计算这些子序列的方差,如果每个子序列的方差不一致,则称该序列存在“异方差现象”,否则称该序列为“同方差序列”。我们对残差做异方差检验,可以帮助我们进一步确认残差是否高度类似于白噪音数据。同理,我们想要的是接受原假设的结果,因此同LBQ测试,我们希望异方差检验的p值是大于显著性水平的(大于0.05)。
异方差检验(White's test)原假设(H0):该序列同方差
异方差检验(White's test)备择假设(H1):该序列异方差总结一下,异方差检验的Prob(H)大于0.05时模型可用,否则可考虑更换超参数组合。
- Jarque-Bera test,雅克贝拉检验。是正态性检验中的一种,用于检验当前序列是否符合正态分布。同理,我们希望检验结果无法拒绝原假设,因此我们希望该检验的p值是大于显著性水平的。
雅克-贝拉检验原假设(H0):序列是正态分布的
雅克-贝拉检验备择假设(H1):序列不是正态分布的
总结一下,雅克-贝拉检验的Prob(JB)大于0.05时模型可用,否则可考虑更换超参数组合。
对ARIMA模型而言,最佳的情况是三个检验都无法拒绝原假设,但现实往往不会这么完美。在实际选择模型过程中,如果实在找不到能让三个检验都接受原假设的参数组合,也可以选择没通过的检验中、p值最大的参数组合。另外,也可以调低显著性水平,例如将0.05调整为0.01,从而让检验全都接受原假设。
5.3 最终的模型
对于ARIMA模型,我们建立如下9个备选模型,而对SARIMA模型,我们同样建立9个备选模型:
#备选模型
arimas = [ARIMA(endog = df['load'],order=(1,1,1))
,ARIMA(endog = df['load'],order=(1,1,2))
,ARIMA(endog = df['load'],order=(2,1,1))
,ARIMA(endog = df['load'],order=(2,1,2))
,ARIMA(endog = df['load'],order=(1,1,3))
,ARIMA(endog = df['load'],order=(3,1,1))
,ARIMA(endog = df['load'],order=(3,1,2))
,ARIMA(endog = df['load'],order=(2,1,3))
,ARIMA(endog = df['load'],order=(3,1,3))
]
sarimas = [ARIMA(endog = df['load'],seasonal_order=(1,1,1,24))
,ARIMA(endog = df['load'],seasonal_order=(1,1,2,24))
,ARIMA(endog = df['load'],seasonal_order=(2,1,1,24))
,ARIMA(endog = df['load'],seasonal_order=(2,1,2,24))
,ARIMA(endog = df['load'],seasonal_order=(1,1,3,24))
,ARIMA(endog = df['load'],seasonal_order=(3,1,1,24))
,ARIMA(endog = df['load'],seasonal_order=(3,1,2,24))
,ARIMA(endog = df['load'],seasonal_order=(2,1,3,24))
,ARIMA(endog = df['load'],seasonal_order=(3,1,3,24))
]SARIMA模型规定,最少要使用1阶差分,1步差分,所有d和s都需要大于1,不然会报错。通过函数循环训练显示:
def plot_summary(models,summary=True,model_name=[]):
"""绘制图像并打印summary的函数"""
for idx,model in enumerate(models):
m = model.fit()
if summary:
print("\n")
print(model_name[idx])
print(m.summary(alpha=0.01))
else:
df["model"] = m.predict(start=480-24,end=480,dynamic=True)
df[['load','model']].plot(figsize=(12,2),title="Model {}".format(idx))ARIMA模型的9个模型的效果如下:
#先进行图像的绘制,从预测结果中选出效果可能比较好的参数组合
plot_summary(arimas,False) 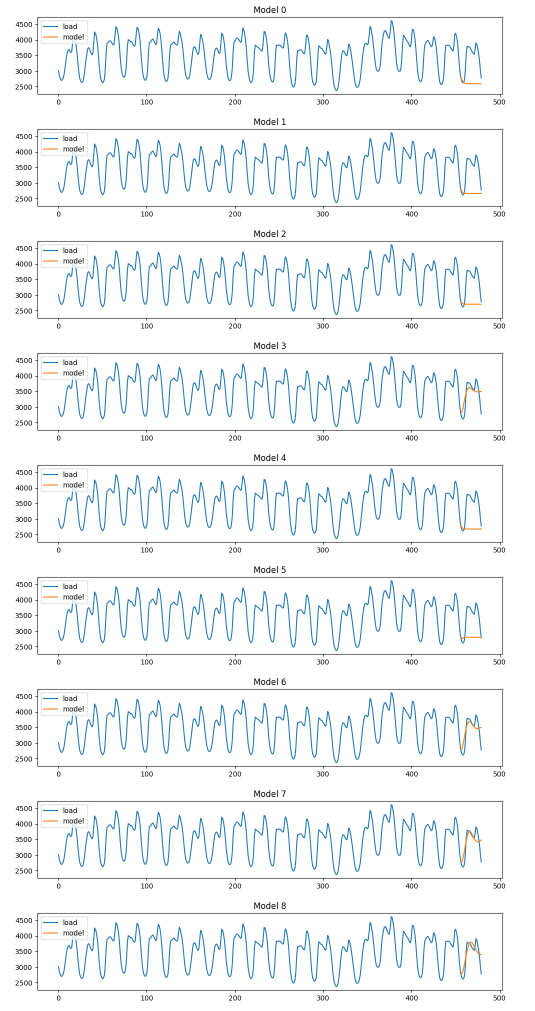
ARIMA系列模型看起来都问题很大,索引3,6,7,8的模型大略地捕捉到了一点点趋势,但是和准确的预测比起来还是有很大地差异。接着继续绘制SARIMA备选模型的图像。
#先进行图像的绘制,从预测结果中选出效果可能比较好的参数组合
plot_summary(sarimas,False) 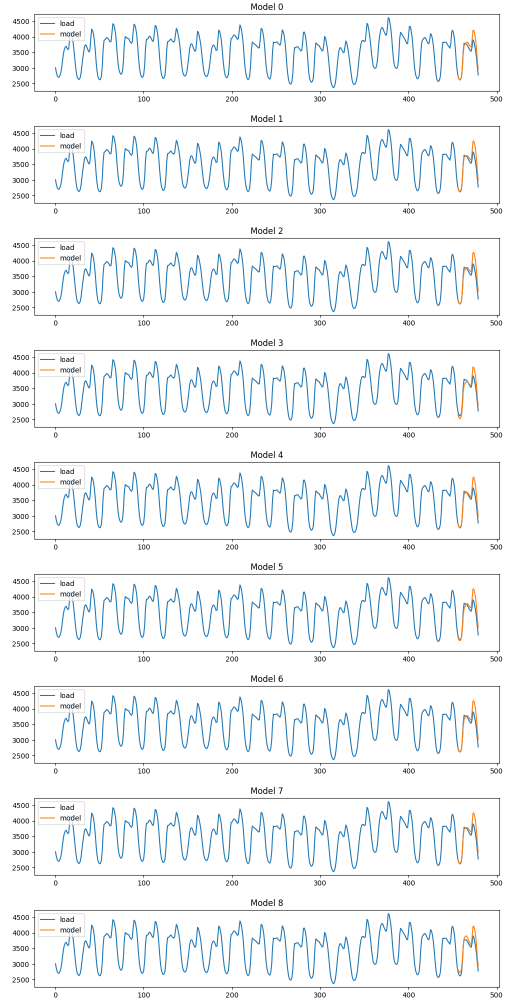
可以看出,SARIMA的情况明显比ARIMA要好很多,所有的SARIMA模型看起来都能够较为精准地捕捉到数据的趋势,接下来我们可以查看这些SARIMA模型的summary总结,来观察这些模型能否被使用。
#打印较好的参数组合的summary
plot_summary([sarimas[0],sarimas[1],sarimas[2],sarimas[3],sarimas[4],sarimas[5],sarimas[6],sarimas[7],sarimas[8]]
,model_name=["SARIMA0","SARIMA1","SARIMA02","SARIMA03","SARIMA04","SARIMA05","SARIMA06","SARIMA07","SARIMA08"])
从打印的summary来看,所有建立的模型并没有很好的满足要求,03号模型的AIC=6049.452最低,因此我们应该考虑03号模型,模型参数的调整可以根据流程进一步优化,最后可视化最后的预测效果图。