数据服务化在京东的实践
导读 本次分享的主题为数据服务化在京东的实践,主要包含三个模块:数据服务化的缘起、成长、如何将系统做得更好。
01
缘起:数据服务化从 0 到 1
1. 缘起
京东数据智能部负责维护数据资产和对外提供数据服务,很多业务方要求我们尽快地提供开放的数据 API 供其使用,但开发一个 API 的平均周期在两周左右,遇到 618 大促时还要提供 80 个接口。在这样的情况下,数据开发工程师提出诉求,是否能只贴 SQL 就可以生成开放数据的 API 接口,同时又能保证接口的性能、支持传入动态的 SQL 参数。基于该诉求而开发了一套解决方案的框架:EZD 框架。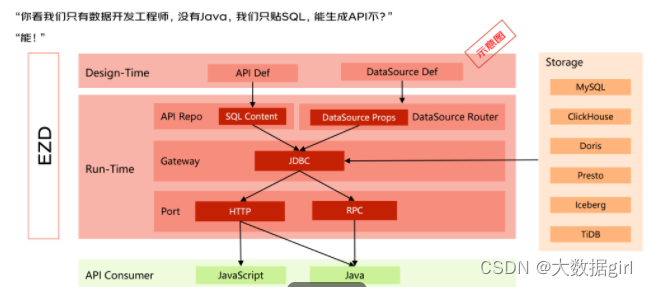
上图为解决方案的示意图,这是相对传统固定的 API 开发模式。最下面的JavaScript 和 Java 是 API 的消费方,上面为 API 的提供方,右边是所有 API 需要用到的数据源。将数据源通过 JDBC 从存储系统中读取出来,然后通过 HTTP 协议或者 RPC 协议开放给业务方使用。基于此套框架,数据开发工程师只需要填写 SQL 后点击发布,系统就会根据 SQL 的内容,通过热部署的方式生成 API 接口,达到一键发布的敏捷交付目标。
2. 接口性能
平台第一个版本的性能存在一些瓶颈,如上图最上面一行为数据库查找 API 的各个环节耗时。系统需要先去查找 SQL 的定义,如果 SQL 是存放在数据库里,那么每一个请求进来时,系统都要先去寻址找到 SQL 后再去数据库里查询,这样的效率并不高。后来把 SQL 都缓存到各个节点组成一张内存路由表来去查找 API 的定义,查找的过程就变得非常地快。后面连接池更换成性能更加高的 Hikari 连接池。最后经过一系列的调优,平台的耗时占比从优化前的 97% 下降到优化后的 1%。
3. 接口的灵活性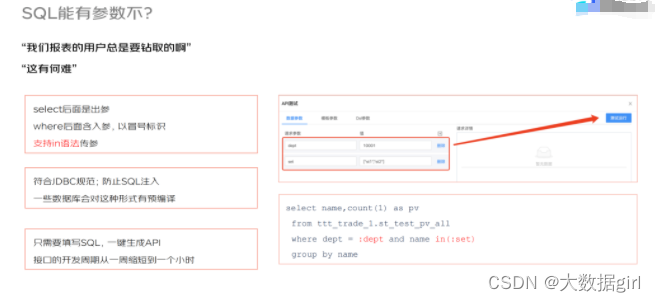
好多 API 希望能传入参数,比如查询某条 SQL 时传入部门的 ID,再比如使用 IN 关键字时能否传入一个集合。这些又怎么来处理呢?如上图右小角所示,通过使用冒号的语法将 API 传入的参数注入到 SQL 语句中。
一些查询条件是动态变化的,比如 WHERE 关键词后边到底是使用哪个条件?A、B、C 3 个条件构成的排列组合非常多,从而导致接口的数量较多,能否使用某种方式减少接口的数量?系统使用 SQL 与 FreeMarker 模板结合的方式来解决上述难题,从而减少 API 的数量,比如上图最左边使用 IF 模块判断,只有 IF 语句为 true 时系统才会使用其内部嵌套的 AND 语句。基于这种方法,所有的查询条件都可以是动态,同时它还支持 Switch Case、遍历集合等操作。通过这种形式,可以将原来的 80 个接口减少到 5 个接口。
02
扛鼎:数据服务化 – 从 1 到 10
京东 618 大促期间对外公布的成交额、热门品类、公关媒体的数据,各平台的实时销量,PV、UV、优惠券的发放情况都需要有看板去支撑,看板上特别多的指标数据都是通过上述提到的数据 API 展示出来的。
系统是如何在短期内迅速地支持这么多的指标呢?比如京东的年货节,需要在两周内完成几百个指标的开发。另外,一些响应比较慢的存储,能不能一键添加缓存?如何充分利用存量的 API?接口之间会形成一个特别复杂的请求链路,怎么来调试这个复杂的链路呢?一些业务方有自己的 elasticsearch、Redis、HBase,这些存储怎么去开放这个 API 呢?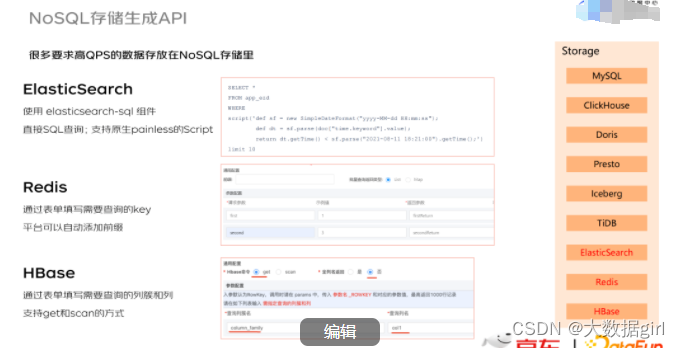
1. NoSQL 存储生成 API
我们使用 elasticsearch-sql 组件执行 SQL 查询 ES 存储,该组件支持原生 painless 的 Script。对于 Redis 我们会让这个用户直接填好需要读写的 KV(系统支持添加通用的前缀),系统返回 list、map 等数据格式。对于 Hbase,用户填写需要查询的列簇和列,系统支持 get 和 scan 方式。
2. 一键添加缓存
作为通用的数据服务平台,目标是希望做到添加缓存的机制与业务解耦。即无论是什么样的业务,进行一键添加缓存的操作时,数据开发工程师只需要填写 SQL,系统都会自动地增加缓存。基于这些考虑,我们设计了两种缓存的机制,一种是被动缓存,一种是主动缓存。
被动缓存的更新是由用户来触发的,或者说是接口请求时触发的。当系统收到一个请求时,如果缓存的条目没有击中,那么就会去创建缓存条目,它的优点是传入的参数是可以动态变化的。比如有三个请求进来,分别传入了参数 A、参数 AB、参数 ABC,那么这三个不同的参数组合会分别生成不同的缓存条目。被动缓存的缺点是 QPS 有毛刺,因为当条目不存在时,第一次请求接口时需要查询数据库。
为了解决被动缓存的毛刺问题,我们提出了主动缓存的机制,将缓存更新的逻辑托管给平台,由平台定时地去更新缓存。另外,针对传入参数动态变化的情况,数据开发工程师只需要提前填好缓存的参数,当平台定时更新缓存时就会取这些参数去加载数据。主动缓存的优点是不会出现缓存失效的情况,所有的请求都会命中缓存,所以它的 QPS 是没有毛刺的,缺点是需要提前填好入参的排列组合。
平台不支持缓存全量的数据,缓存存储的不应该是全量数据,而是高热的数据。如果是业务方的需求是想要使用内存数据库提高查询效率,那么我们建议他们使用专门的内存数据库。
3. 服务编排
一些特别复杂的需求,需要大量的 API 来通过编排、组合,甚至中间的进行二次加工,然后加上一些条件判断来形成一个复杂 API。如何来完成这样的挑战呢?比如在 618 大促遇到如下挑战,618 活动是从 17 号晚上 8 点钟开始到 19 号 0 时,这 28 小时内的不同时间段的统计逻辑是不一样的,使用的接口也是不一样的。我们希望把这些不同的统计逻辑都封装到 API 里,屏蔽掉这些复杂的业务逻辑。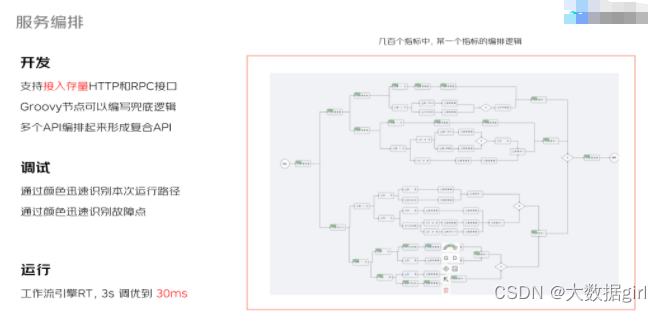
如上图左侧是一个线上运行的编排图,整个编排链路中存在好多节点和分支,通过条件判断选择分支,调试的时候输入参数便可以直接看到接口请求的执行的链路(图中绿色的点),一目了然且方便排查问题。系统的编排的底层逻辑是一个工作流引擎,它与审批工作流不一样,它是自动流,无需人工介入。内部的好多指标都是通过这种形式来迅速的搭建 API。
03
静思:数据服务治理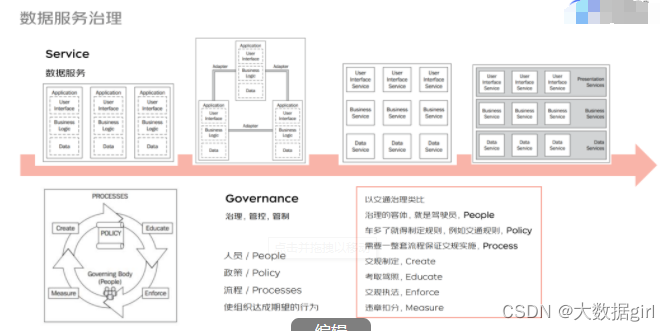
早期的服务简单,直接使用单体应用提供服务,后面随着业务越来复杂,会将服务拆分成多个层级和模块,从而导致系统的复杂性急剧上升,如何对数据服务进行有效治理呢?
抛开业务和技术,治理无非是包含人员、政策、流程等因素,通过这些因素的组合,使组织达到一个期望的行为。上图左下角展示的环状图就是一个流程,其中包含了政策的创建、管控、治理、宣讲、执行。比如交通治理,驾驶员为客体,执法部门制定交通规则,交警执法进行约束,从而使整个流程正常运转。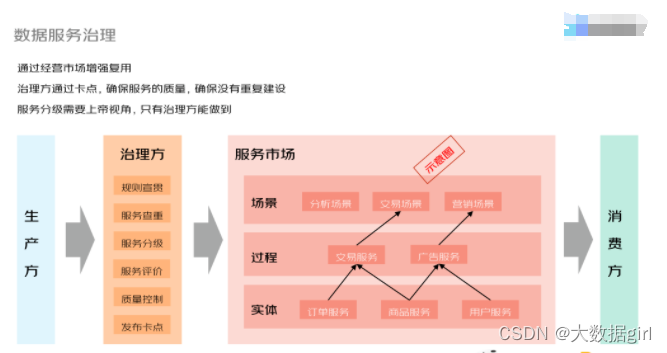
数据服务由提供数据的生产方、使用数据的消费方以及治理方组成。服务市场将数据服务分层,由最底层的订单、商品、用户实体提供服务,中间存在实体交互的过程,比如交易、广告投放,最上面是具体的应用场景,比如分析、交易、营销。
经过治理方的规则贯宣,服务查重,服务分级,服务评价,质量控制,发布卡点等一系列前置操作后,才能将服务提交到服务市场中。通过生产方、消费方、治理方互动的形式来完成数据服务治理的过程。
04
问答环节
Q1:数据服务的灵活性非常地高,但这种灵活性是否会带来安全或者性能等的冲击挑战?
A1:平台包含 MySQL、ClickHouse 等数据来源,每个数据源都有所有者或者负责人,数据源的负责人要对自己数据源的安全性进行把关。由负责人将数据源授权给某个 API 的分组,只有被授权的分组才能使用该数据源。对于系统性能这个问题,平台的负载仅仅占到 1%,对于 API 而言,其最大的性能瓶颈在于数据库,性能优劣完全取决于数据库的性能以及 SQL 语句,针对这个情况我们引导用户直接与数据库团队进行沟通协调、压力测试,通过这样的协作模式来保证服务的质量和稳定性。另外,系统拥有分布式限流的能力,在请求量超过系统能承受的最大负载时进行快速熔断,从而保护系统。
Q2:写了一个 MySQL 数据源的 API,能否可以把数据源更换成ClickHouse 或者其他的 SQL 数据源?
A2:如果 SQL 语句能够在新的数据源上执行,那么是可以的。如果 SQL语句中存在某些特定关键词或者函数只能在原有数据库引擎上执行,那么就不能直接将数据源修改成其它数据库。
今天的分享就到这里,谢谢大家。