大数据分析与应用实验任务八
实验目的
- 进一步熟悉pyspark程序运行方式;
- 熟练掌握pysaprk RDD基本操作相关的方法、函数。
实验任务
进入pyspark实验环境,在图形界面的pyspark命令行窗口中完成下列任务:
在实验环境中自行选择路径新建以自己姓名拼音命名的文件夹,后续代码中涉及的文件请保存到该文件夹下(需要时文件夹中可以创建新的文件夹)。
一、 参考书上例子,理解并完成RDD常用操作(4.1.2节内容);
1.转换操作
(1)filter(func)
filter(func)操作会筛选出满足函数 func 的元素,并返回一个新的数据集。例如:
lines = sc.textFile("file:///root/Desktop/luozhongye/wordlzy.txt")
linesWithSpark = lines.filter(lambda line: "Spark" in line)
linesWithSpark.foreach(print)

(2)map(func)
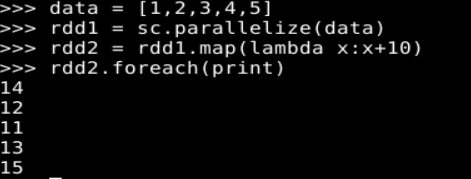
map(func)操作将每个元素传递到函数 func 中,并将结果返回为一个新的数据集。例如:
data = [1,2,3,4,5]
rdd1 = sc.parallelize(data)
rdd2 = rdd1.map(lambda x:x+10)
rdd2.foreach(print)
下面是另外一个实例:
lines = sc.textFile("file:///root/Desktop/luozhongye/wordlzy.txt")
words = lines.map(lambda line:line.split(" "))
words.foreach(print)

(3)flatMap(func)
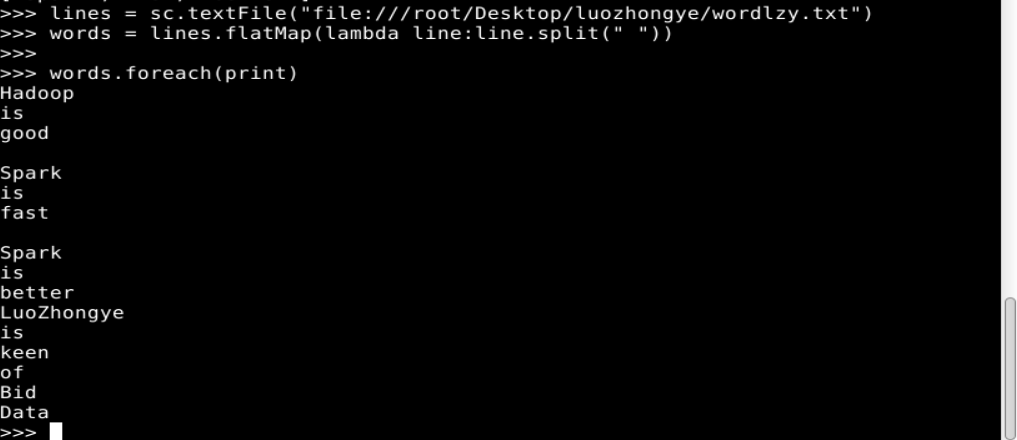
flatMap(func)与 map()相似,但每个输入元素都可以映射到 0 或多个输出结果。例如:
lines = sc.textFile("file:///root/Desktop/luozhongye/wordlzy.txt")
words = lines.flatMap(lambda line:line.split(" "))
words.foreach(print)
(4)groupByKey()
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集。下面给
出一个简单实例,代码如下:
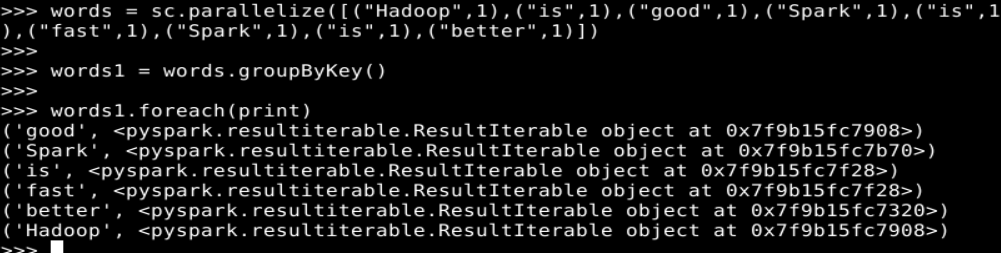
words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
words1 = words.groupByKey()
words1.foreach(print)
(5)reduceByKey(func)
reduceByKey(func)应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每
个值是将每个 key 传递到函数 func 中进行聚合后得到的结果。这里给出一个简单实例,代码如下:
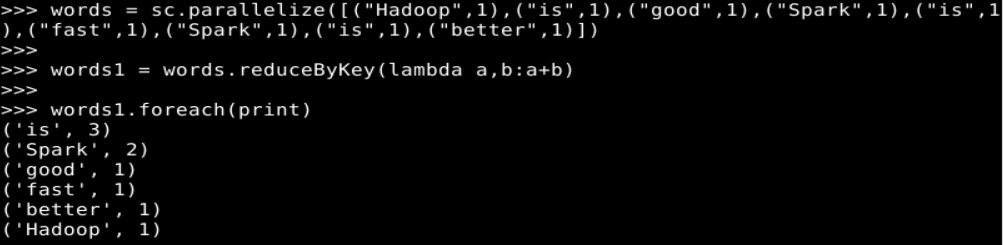
words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
words1 = words.reduceByKey(lambda a,b:a+b)
words1.foreach(print)
2.行动操作
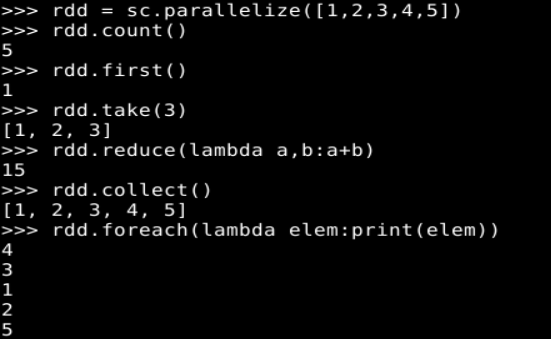
rdd = sc.parallelize([1,2,3,4,5])
rdd.count()
rdd.first()
rdd.take(3)
rdd.reduce(lambda a,b:a+b)
rdd.collect()
rdd.foreach(lambda elem:print(elem))
3.惰性机制
lineslzy = sc.textFile("file:///root/Desktop/luozhongye/wordlzy.txt")
lineLengths = lineslzy.map(lambda s:len(s))
totalLength = lineLengths.reduce(lambda a,b:a+b)
print(totalLength)

二、 参考书上例子,理解并完成键值对RDD常用操作(4.2.2节内容);
常用的键值对转换操作包括 reduceByKey(func)、groupByKey()、keys、values、sortByKey()、sortBy()、mapValues(func)、join()和 combineByKey 等。
1.reduceByKey(func)
pairRDD = sc.parallelize([("Hadoop",1),("Spark",1),("Hive",1),("Spark",1),("罗忠烨",1)])
pairRDD.reduceByKey(lambda a,b:a+b).foreach(print)

2.groupByKey()
list = [("spark",1),("spark",2),("hadoop",3),("hadoop",5)]
pairRDD = sc.parallelize(list)
pairRDD.groupByKey()
pairRDD.groupByKey().foreach(print)

对于一些操作,既可以通过 reduceByKey()得到结果,也可以通过组合使用 groupByKey()和 map()操作得到结果,二者是“殊途同归”,下面是一个实例:
words = ["one", "two", "two", "three", "three", "three"]
wordPairsRDD = sc.parallelize(words).map(lambda word:(word, 1))
wordCountsWithReduce = wordPairsRDD.reduceByKey(lambda a,b:a+b)
wordCountsWithReduce.foreach(print)
wordCountsWithGroup = wordPairsRDD.groupByKey().map(lambda t:(t[0],sum(t[1])))
wordCountsWithGroup.foreach(print)

3.keys
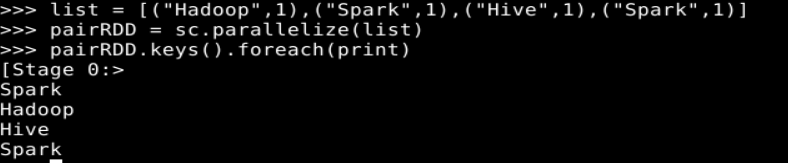
list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
pairRDD = sc.parallelize(list)
pairRDD.keys().foreach(print)
4.values
list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1),("luozhongyeTop1",1)]
pairRDD = sc.parallelize(list)
pairRDD.values().foreach(print)

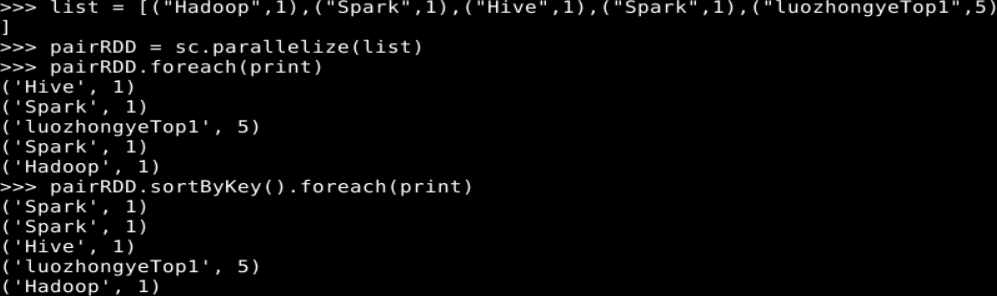
5.sortByKey()
list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
pairRDD = sc.parallelize(list)
pairRDD.foreach(print)
pairRDD.sortByKey().foreach(print)
6.sortBy()
d1 = sc.parallelize([("c",8),("b",25),("c",17),("a",42),("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9),("luozhongye",1)])
d1.reduceByKey(lambda a,b:a+b).sortByKey(False).collect()

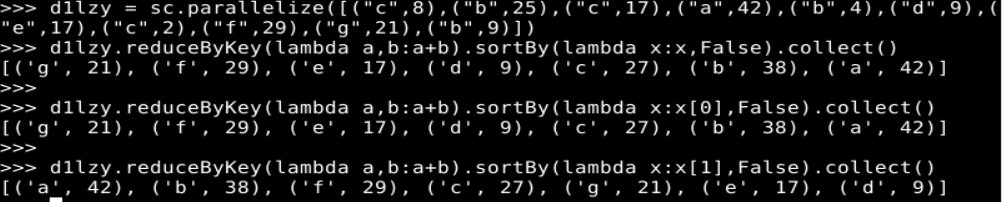
sortByKey(False)括号中的参数 False 表示按照降序排序,如果没有提供参数 False,则默认采用升序排序(即参数取值为 True)。从排序后的效果可以看出,所有键值对都按照 key 的降序进行了排序,因此输出[(‘g’, 21), (‘f’, 29), (‘e’, 17), (‘d’, 9), (‘c’, 27), (‘b’, 38), (‘a’, 42)]。但是,如果要根据 21、29、17 等数值进行排序,就无法直接使用 sortByKey()来实现,这时可以使用 sortBy(),代码如下:
d1 = sc.parallelize([("c",8),("b",25),("c",17),("a",42),("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)])
d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x,False).collect()
d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[0],False).collect()
d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],False).collect()
7.mapValues(func)
list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
pairRDD = sc.parallelize(list)
pairRDD1 = pairRDD.mapValues(lambda x:x+1)
pairRDD1.foreach(print)

8.join()
pairRDD1 = sc.parallelize([("spark",1),("spark",2),("hadoop",3),("hadoop",5)])
pairRDD2 = sc.parallelize([("spark","fast")])
pairRDD3 = pairRDD1.join(pairRDD2)
pairRDD3.foreach(print)

9.combineByKey
(1)createCombiner:在第一次遇到 key 时创建组合器函数,将 RDD 数据集中的 V 类型值转换成 C 类型值(V => C);
(2)mergeValue:合并值函数,再次遇到相同的 key 时,将 createCombiner 的 C 类型值与这次传入的 V 类型值合并成一个 C 类型值(C,V)=>C;
(3)mergeCombiners:合并组合器函数,将 C 类型值两两合并成一个 C 类型值;
(4)partitioner:使用已有的或自定义的分区函数,默认是 HashPartitioner;
(5)mapSideCombine:是否在 map 端进行 Combine 操作,默认为 true。
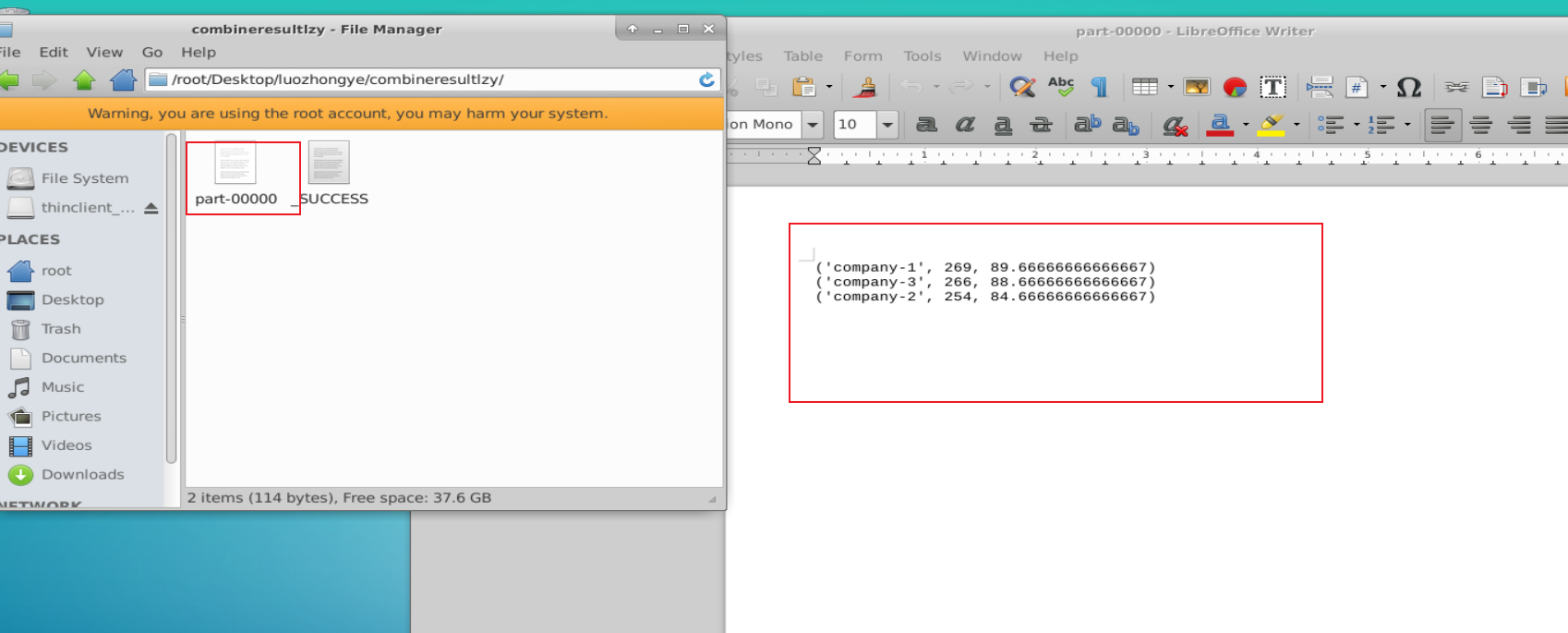
下面通过一个实例来解释如何使用 combineByKey 操作。假设有一些销售数据,数据采用键值对的形式,即<公司,当月收入>,要求使用 combineByKey 操作求出每个公司的总收入和每月平均收入,并保存在本地文件中。
为了实现该功能,可以创建一个代码文件“/root/Desktop/luozhongye/Combinelzy.py”,并输入如下代码:
#!/usr/bin/env python3
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("Combine ")
sc = SparkContext(conf = conf)
data = sc.parallelize([("company-1",88),("company-1",96),("company-1",85),("company-2",94),("company-2",86),("company-2",74),("company-3",86),("company-3",88),("company-3",92)],3)
res = data.combineByKey(lambda income:(income,1),lambda acc,income:(acc[0]+income, acc[1]+1),lambda acc1,acc2:(acc1[0]+acc2[0],acc1[1]+acc2[1])).map(lambda x:(x[0],x[1][0],x[1][0]/float(x[1][1])))
res.repartition(1).saveAsTextFile("file:///root/Desktop/luozhongye/combineresultlzy")
执行如下命令运行该程序:
cd /root/Desktop/luozhongye
/usr/local/spark/bin/spark-submit Combinelzy.py
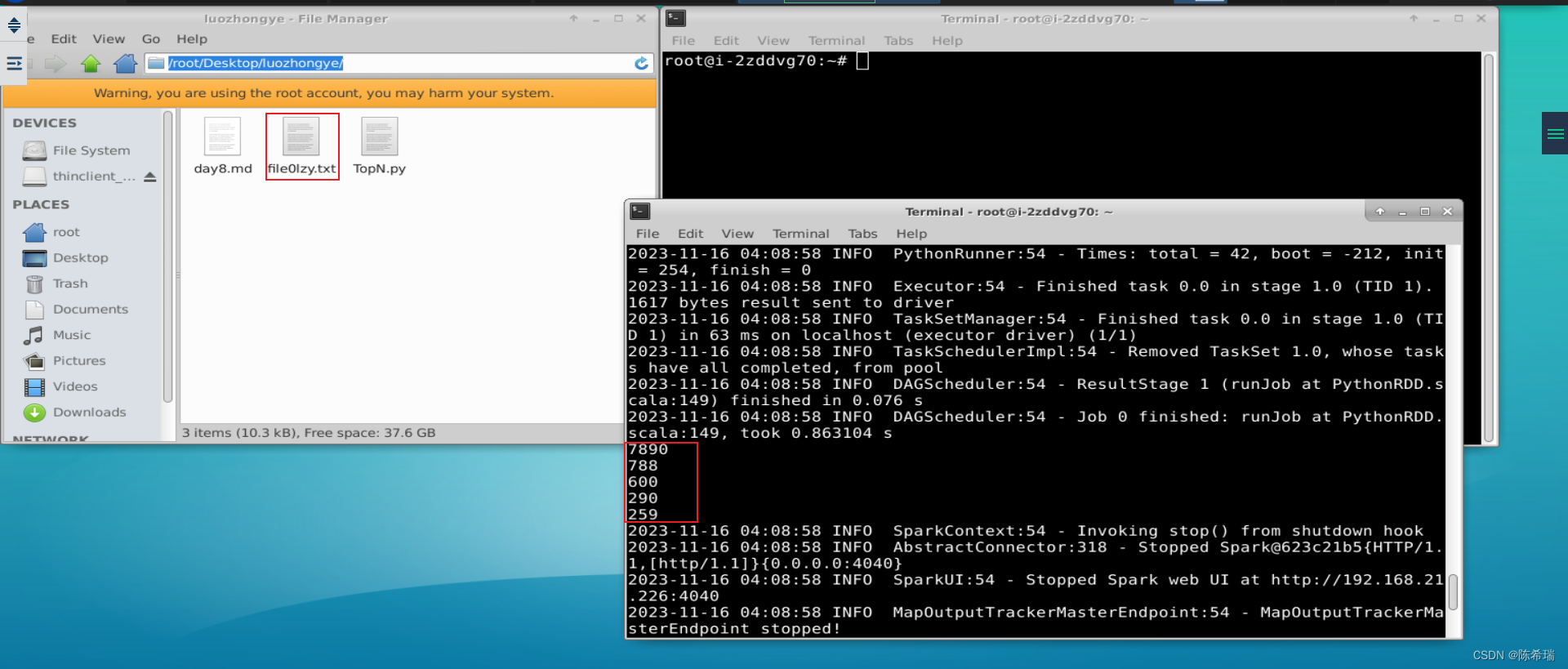
三、 逐行理解并运行4.4.1实例“求TOP值”。
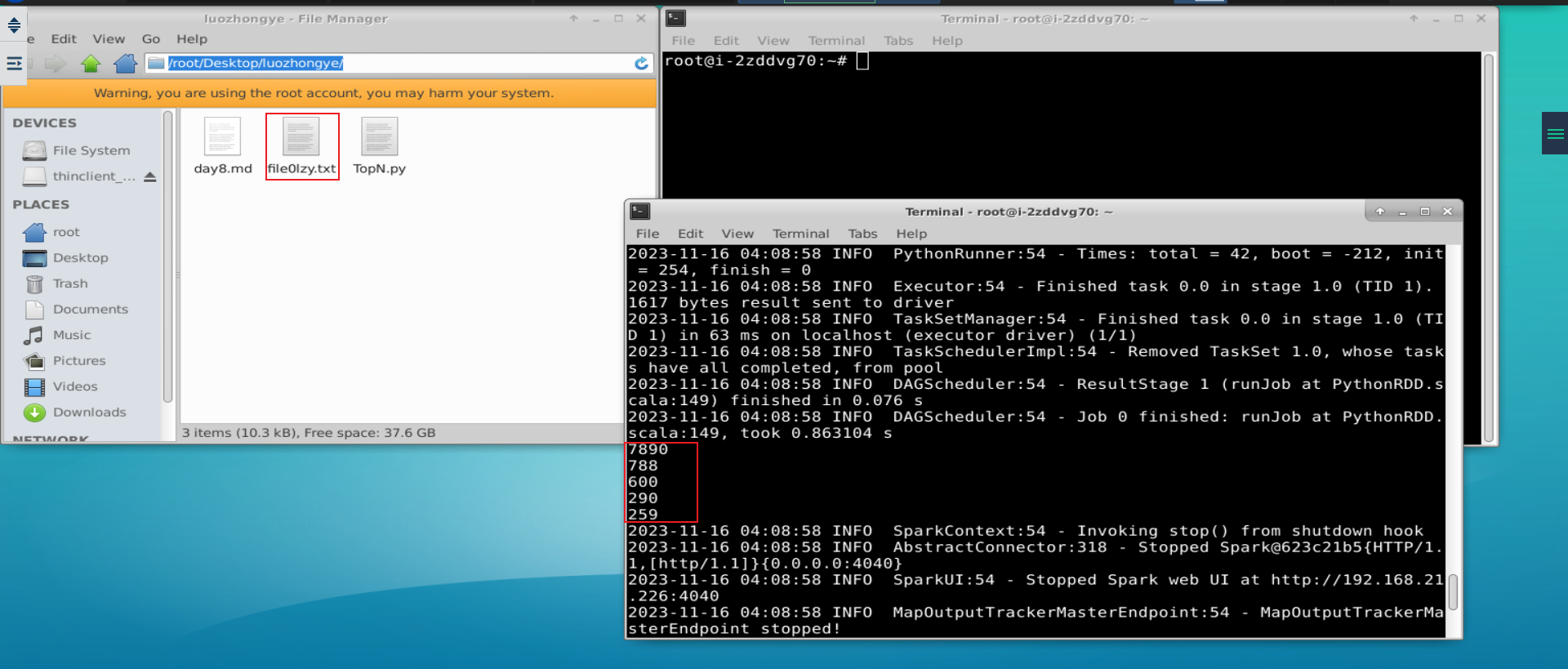
假设在某个目录下有若干个文本文件,每个文本文件里面包含了很多行数据,每行数据由 4 个字段的值构成,不同字段值之间用逗号隔开,4 个字段分别为 orderid、userid、payment 和 productid,要求求出 Top N 个 payment 值。如下为一个样例文件 file0lzy.txt:
1,1768,50,155
2,1218,600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
实现上述功能的代码文件“/root/Desktop/luozhongye/TopN.py”的内容如下:
# !/usr/bin/env python3
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf=conf)
lines = sc.textFile("file:///root/Desktop/luozhongye/file0.txt")
result1 = lines.filter(lambda line: (len(line.strip()) > 0) and (len(line.split(",")) ==
4))
result2 = result1.map(lambda x: x.split(",")[2])
result3 = result2.map(lambda x: (int(x), ""))
result4 = result3.repartition(1)
result5 = result4.sortByKey(False)
result6 = result5.map(lambda x: x[0])
result7 = result6.take(5)
for a in result7:
print(a)
= result1.map(lambda x: x.split(“,”)[2])
result3 = result2.map(lambda x: (int(x), “”))
result4 = result3.repartition(1)
result5 = result4.sortByKey(False)
result6 = result5.map(lambda x: x[0])
result7 = result6.take(5)
for a in result7:
print(a)