✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、代码参考
- 五、论文参考
- 六、系统视频
- 结语
一、前言
随着信息技术的飞速发展,机房在现代企业和组织中扮演着越来越重要的角色。机房不仅负责存储和管理大量关键数据,还为各种业务系统提供稳定运行的基础设施。然而,机房的运行和维护面临着诸多挑战,如设备故障、信号波动等。为了确保机房的正常运行,对机房信息的实时监控和分析显得尤为重要。因此,研究机房信息大数据平台具有显著的现实意义和紧迫性。
尽管目前已有一些解决方案用于机房信息的监控和管理,但它们往往存在一定的局限性。例如,部分系统可能无法实时处理大量数据,导致监控延迟;或者在数据分析方面,现有方案可能无法深入挖掘数据背后的关联和规律。这些问题使得现有解决方案在应对机房复杂环境和需求方面显得力不从心,进一步强调了开展机房信息大数据平台研究的必要性。
本课题旨在构建一个智能的机房信息大数据平台,实现对机房基本信息数据、设备信号波动数据、设备区域分析等方面的监控和管理。通过运用先进的数据挖掘和分析技术,本平台将能够实时捕捉和处理海量机房信息,为运维人员提供有力支持,确保机房的稳定运行。
机房信息大数据平台的研究具有重要的理论和实践意义。从理论层面,本课题将推动大数据技术在机房监控与管理领域的应用和发展,为相关领域的研究提供新的思路和方法。从实践层面,本课题的研究成果将有助于提高机房运维效率,降低设备故障风险,从而保障企业和组织关键数据的安全与稳定。总之,开展机房信息大数据平台研究对于推动信息化进程和提升组织运营效能具有重要价值。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
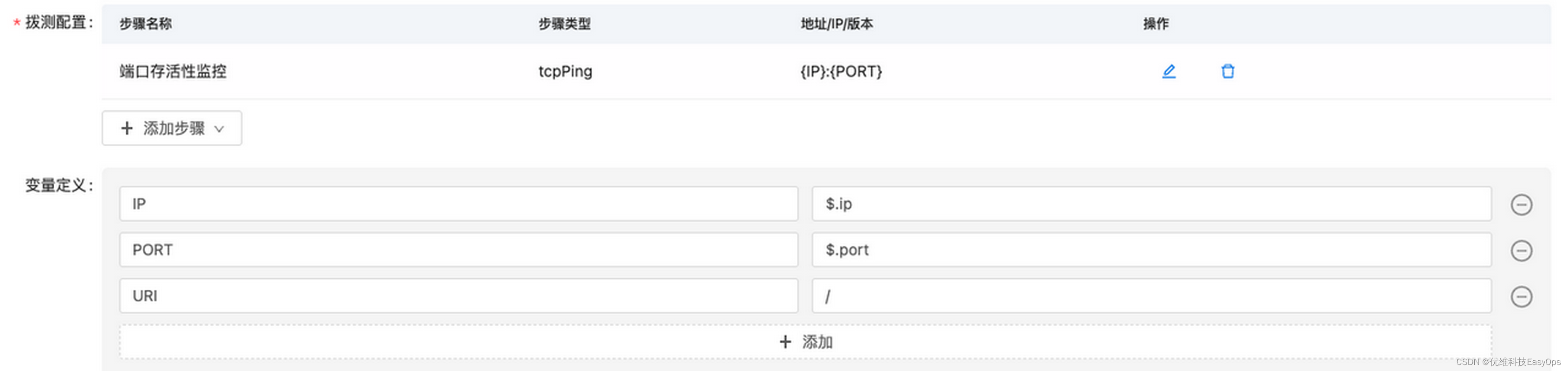
三、系统界面展示
- 机房信息大数据平台-界面展示:




四、代码参考
- 大数据项目实战代码参考:
class BTSearch:
def __init__(self, keyword, total_page_num, ck):
self.base_url = "http://sobt01.cc/"
self.keyword = keyword
self.total_page_num = total_page_num
self.root_url = f"{self.base_url}q/{self.keyword}.html"
self._gen_headers(ck)
self.data = {}
self.lock = threading.Lock()
def _gen_headers(self, ck):
row_headers = f"""Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: no-cache
Connection: keep-alive
Cookie: {ck}
Host: sobt01.cc
Pragma: no-cache
Referer: http://sobt01.cc/
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"""
self.headers = {k: v for row in row_headers.split("\n") for k, v in (row.strip().split(": "),)}
def parse_page(self, page):
params = {
"sort": "time",
"page": page
}
# 请求列表页面
try_count = 0
while True:
resp = requests.get(self.root_url, params=params, headers=self.headers)
if resp.status_code != 502:
break
try_count += 1
if try_count > 16:
logger.info(f"列表页:{self.root_url}重试15次失败,您可以手动尝试下载整页!")
break
time.sleep(0.3)
if "\"act\":\"challenge\"" in resp.text:
raise Exception("需要重新配置headers")
if resp.status_code >= 300:
logger.info(f"列表页错误。第{page}页,url:{resp.url},响应码:{resp.status_code}")
return None
res = self.get_detail_url(html=resp.text, page=page)
self.lock.acquire()
self.data.update(res)
self.lock.release()
def get_detail_url(self, html, page):
html_tree = etree.HTML(html)
search_items = html_tree.xpath("//div[@class='search-list col-md-8']/div[@class='search-item']")
res = {f"第{page}页": []}
# 解析详情页的标签
for one_item in search_items:
size_span = one_item.find("./div[@class='item-bar']/span[3]")
size = size_span.find("./b")
if not size.get("class"):
if float(size.text[0:-3]) < 500:
logger.info(f"{float(size.text[0:-3])}太小了")
continue
jump_to_element = one_item.find("./div[@class='item-title']/h3/a")
detail_uri = jump_to_element.get("href")
detail_page = self.base_url + detail_uri
href = self.parse_detail(url=detail_page, page=page)
res[f"第{page}页"].append(href)
return res
def parse_detail(self, url, page):
try_count = 0
while True:
resp = requests.get(url, headers=self.headers)
if resp.status_code != 502:
break
try_count += 1
if try_count > 9:
logger.info(f"详情页:{url}重试8次失败,您可以手动尝试下载")
break
time.sleep(0.3)
# 解析详情页
if resp.status_code < 300:
html_tree = etree.HTML(resp.text)
title = html_tree.xpath("//div[@id='wall']/h1/text()")[0]
target_magnet_link = html_tree.xpath("//div[@id='wall']//input/@value")[0]
logger.info(f"page -> [{page}], href -> [{target_magnet_link}]")
return {
"title": title,
"href": target_magnet_link
}
else:
logger.error(f"not found source")
return None
def run(self):
tp = ThreadPoolExecutor(10)
try:
for page in range(1, self.total_page_num + 1):
tp.submit(self.parse_page, page)
except Exception as e:
logger.error(e)
logger.error(traceback.print_exc())
finally:
tp.shutdown(wait=True)
self.save_data()
def save_data(self):
cur_dir = os.path.dirname(os.path.abspath(__name__))
res_path = os.path.join(cur_dir, "data")
if not os.path.exists(res_path):
os.makedirs(res_path)
filename = f"data_{time.strftime('%Y%m%d%H%M%S', time.localtime())}.json"
file_path = os.path.join(res_path, filename)
with open(file_path, "w", encoding="utf-8")as f:
json.dump(self.data, f, indent=4, ensure_ascii=False)
if __name__ == '__main__':
ck = "PHPSESSID=1735hrtkd0gnds3an9bgmk00bh; test=2e1e17ad6a1688993418"
keyword = "流浪地球"
total_page_num = 5
bt = BTSearch(
keyword=keyword,
total_page_num=total_page_num,
ck=ck,
)
bt.run()
五、论文参考
- 计算机毕业设计选题推荐-机房信息大数据平台-论文参考:

六、系统视频
机房信息大数据平台-项目视频:
大数据毕业设计选题推荐-机房信息大数据平台-Hadoop
结语
大数据毕业设计选题推荐-机房信息大数据平台-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目