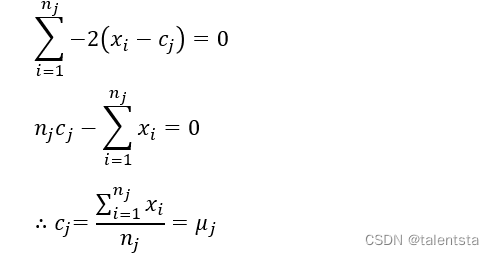K-means聚类的思想和原理
模型介绍
对于有监督的数据挖掘算法而言,数据集中需要包含标签变量(即因变量y的值)。但在有些场景下,并没有给定的y值,对于这类数据的建模,一般称为无监督的数据挖掘算法,最为典型的当属聚类算法。
K-means聚类算法利用距离远近的思想将目标数据聚为指定的k个簇,进而使样本呈现簇内差异小,簇间差异大的特征。但是具体分为几个类,分成类的标准都不同,没有准确的判定标准说分成哪个最好。
聚类过程
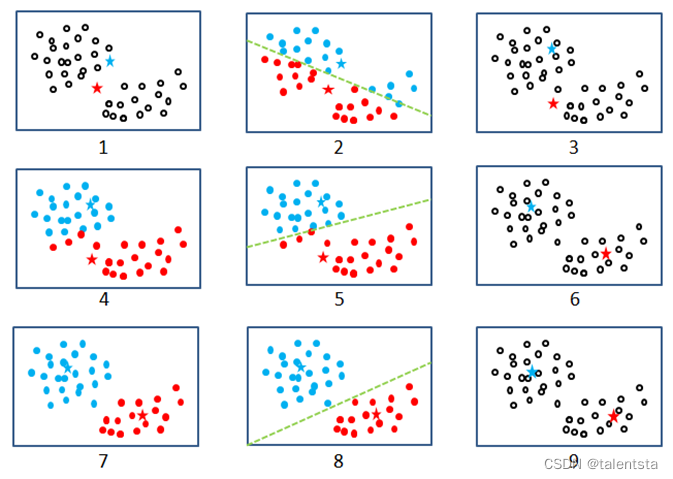
1.从数据中随机挑选k个样本点作为原始的簇中心
2.计算剩余样本与簇中心的距离,并把各样本标记为离k个簇中心最近的类别
3.不断重复第二步和第三步,直到簇中心的变化趋于稳定,形成最终的k个簇
4.重新计算各簇中样本点的均值,并以均值作为新的k个簇中心
原理介绍
在Kmeans聚类模型中,对于指定的𝑘k个簇,只有簇内样本越相似,聚类效果才越好。基于这个思想,可以理解为簇内样本的离差平方和之和达到最小即可。进而可以衍生出Kmeans聚类的目标函数:
Kmeans聚类的思想和原理eans 聚类的思想和原理
聚类的思想和原理
其中,cj 表示第 j 个簇的簇中心,xi 属于第j个簇的样本 i ,nj 表示第 j 个簇的样本总量。对于该目标函数而言,cj 是未知的参数,要想求得目标函数的最小值,得先知道参数 cj 的值。
对目标函数求偏导:
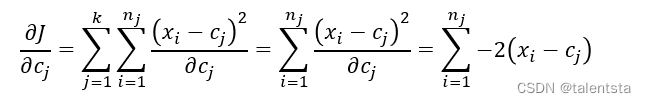
令导函数为0: