文章:Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation
代码:https://github.com/chenfengxu714/SqueezeSegV3
一、摘要
激光雷达点云分割是许多应用中的一个重要问题。对于大规模点云分割,一般是投射三维点云以获得二维激光雷达图像,然后使用卷积法对其进行处理。尽管普通 RGB 图像和激光雷达图像具有相似性,但我们发现,在不同的图像位置,激光雷达图像的特征分布会发生巨大变化。使用标准卷积来处理这类激光雷达图像会出现问题,因为卷积滤波器会捕捉到只在图像中特定区域活跃的局部特征。因此,网络的能力未得到充分利用,分割性能下降。为了解决这个问题,我们提出了空间自适应卷积(SAC),根据输入图像的不同位置采用不同的滤波器。由于 SAC 可以通过一系列元素乘法、im2col 和标准卷积来实现,因此可以高效计算。它是一个通用框架,以前的几种方法都可以看作是 SAC 的特例。利用SAC,我们构建了用于LiDAR点云分割的SqueezeSegV3,并在SemanticKITTI基准测试中以相当的推理速度超越了之前发布的所有方法,至少高出3.7% mIoU。
二、SqueezeSegV3网络架构概览

SqueezeSegV3是一个为点云数据设计的卷积神经网络。它通过球面投影技术将3D点云转换为2D图像,然后利用一系列卷积层和自适应卷积层对其进行处理。
三、球面投影的转换
通过球面投影,我们能够将点云数据投影到一个二维平面上,这使得标准的2D卷积网络能够进行处理。这种投影保留了重要的几何和距离信息,同时简化了数据的结构,为后续的特征提取和分类工作奠定了基础。
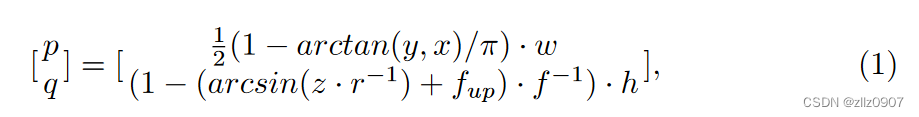
在这个过程中,3D点的 x 和 y 坐标通过 arctan 函数转换为水平角度,并且归一化到图像的宽度 w 范围内。z 坐标通过 arcsin 函数转换为垂直角度,并且归一化到图像的高度 h 范围内。这样,每个3D点都被映射到了2D图像上的一个特定位置,可以利用常规的卷积神经网络进行进一步处理。每个点被投影到 (p,q) 后,使用其测量的位置 (x,y,z) 和范围 r 以及强度作为特征,并沿通道维度堆叠。
四、空间自适应卷积(SAC)
SAC是SqueezeSegV3的核心,它使网络能够根据点云数据的空间分布自适应地调整卷积核。这种方法比传统的卷积操作更有效,因为它可以专注于点云中更重要的区域。四种SAC变种如下:

SAC-S
1. 使用Conv_attention7x7函数在坐标映射上生成注意力图(attention_map)。
2. 将注意力图与输入特征逐元素相乘(element-wise multiplication)。
3. 通过Conv_feature3x3在加权的输入特征上应用3x3卷积。
4. 将卷积的结果与输入特征逐元素相加,得到输出特征。
SAC-IS
与SAC-S类似,但在生成注意力图之后,会对其进行一次inflation操作,这意味着将注意力图在空间维度上复制多次,以匹配输入特征的通道数。
SAC-SK
1. 使用unfold函数,这通常意味着将输入特征展开为更大的维度,这个步骤通常用于提取局部区域。
2. 使用Conv_attention7x7在坐标映射上生成注意力图。
3. 将生成的注意力图在最后一个维度上复制,使其与展开的特征维度匹配。
4. 应用3x3卷积。
5. 将结果与输入特征逐元素相加
SAC-ISK
结合了SAC-IS和SAC-SK的特点,进行了unfold和inflation操作。
在所有这些函数中,输入特征(input_feature)和坐标映射(coordi_map)都是神经网络中的中间特征表示,分别表示前一层输出的特征和空间位置信息。注意力图(attention_map)是通过应用特定的卷积操作于坐标映射上生成的,它用来加权输入特征,这样网络就可以更加关注输入特征中重要的部分。这种类型的操作有助于网络更好地理解输入数据的空间结构,这对于点云数据来说是很关键的。最终,输出特征(output_feature)是经过空间自适应卷积处理后的新特征表示,将被传递到网络的下一层。
五、im2col/unfold介绍
im2col和unfold是相似的操作,实际上是相同的概念在不同上下文和框架中的实现。im2col/unfold操作将每个局部区域转换成一列,这允许使用高效的矩阵乘法来替代更多的逐点卷积运算。尽管这增加了内存的使用,但它显著提高了卷积的计算效率。
im2col的步骤通常包括:
1. 确定卷积核大小:假设卷积核的大小为K x K。
2. 滑动窗口:在输入图像上滑动一个K x K的窗口,通常情况下滑动的步长(stride)为1,这样可以覆盖图像的所有局部区域。
3. 提取和展平:在每个滑动窗口的位置,提取对应的图像区域并将其展平成一维列。
4. 创建矩阵:将所有的列向量堆叠起来形成一个矩阵,其中每一列代表一个局部区域。
六、SqueezeSegV3
SqueezeSegV3使用多个SAC层来逐步提取和细化特征。每个SAC层都专注于从数据中捕获不同的信息,并逐渐构建出足够的上下文来识别和分割点云中的各种对象。
SqueezeSegV3架构
SqueezeSegV3的骨干架构基于RangeNet,它包含五个卷积阶段,每个阶段都包含两个堆叠的卷积层,并在每个阶段的开始进行下采样。为了恢复分辨率,输出然后上采样。SqueezeSegV3用空间自适应卷积的一个变体(SAC-ISK)替换了RangeNet的第一个卷积。为了保持相同的浮点运算数(FLOPs),作者移除了最后两个阶段的下采样,并调整了输出通道的数量。具体来说,五个阶段的输出通道数分别为64、128、256、256和256,而移除了最后两个下采样操作后的输出通道数为64、128、256、512和1024。在最后两个下采样操作中,只使用了三个上采样块。
训练细节和损失函数
SqueezeSegV3通过使用多任务学习和深度监督来优化训练过程。通过在不同的网络层上计算损失,模型能够更好地学习复杂的特征表示。
SqueezeSegV3使用多层交叉熵损失来训练网络。在训练过程中,从stage1到stage5,每个阶段的输出都增加了一个预测层。对于每个输出,分别用1x、2x、4x、8x和8x的因子对真实标签地图进行下采样,并用这些采样过的标签来训练从stage1到stage5的输出。损失函数可以表示为:

相较于单层的交叉熵损失,这种多层损失能够提供更多的监督信号,从而改善网络的学习过程。这也有助于缓解梯度消失问题,因为它允许梯度直接从网络的较低层流向较高层。
七、实验结果和性能评估
在标准数据集上,SqueezeSegV3的表现优于先前的模型,这证明了其架构和SAC技术的有效性。特别是在识别小物体和边缘物体方面,SqueezeSegV3显示出显著的改进。
八、点云分割的未来方向
随着自动驾驶技术的发展,点云分割的需求日益增长。未来的研究可能会集中在进一步提升处理速度和准确性,以及将SqueezeSegV3的方法应用于更广泛的3D视觉任务上。