0. 简介
由于点云的不规则数据形式以及散点的稀疏性,当前的方法难以从点云中提取高判别性的特征,在大规模环境中使用激光雷达进行全局定位仍是一个难以解决的问题。《BVMatch: Lidar-Based Place Recognition Using Bird’s-Eye View Images》一文中将点云表示为鸟瞰(Bird’s eye View, BEV)图像,从图像特征构建的角度设计了一个二阶段全局定位方法 BVMatch。BVMatch 基于地面区域可近似为平面的假设,把地面区域均匀离散为网格,将三维激光点云投影到 BEV 图像中。在特征提取结阶段,使用 Log-Gabor 滤波器组对图像结构的方向信息进行编码,构建了对图像强度失真不敏感的最大索引图像(Maximum Index Map,MIM)。通过分析 MIM 的方向特性,设计了一种同时对 BEV 图像的旋转和强度变化不敏感的局部描述子鸟瞰图特征变换 (Bird’s eye View Feature Transform,BVFT)。基于 BVFT 描述子,使用词袋模型构建了统一激光点云地点识别任务和位姿估计任务的完整全局定位框架,实现了激光点云的帧到帧地点识别和姿态估计。
1. 主要贡献
- 提出了一种称为 BVFT 的新型局部描述子,它对 BEV 图像的强度和旋转变化不敏感,基于此设计的 BVMatch框架统一了激光雷达位置识别和姿态估计任务,实现了全局定位。
- 从理论上分析了BVFT可以通过改变MIM图像块中的方向来实现旋转不变性。
- 在三个大型数据集上进行了实验,验证了BVMatch 在地点识别和位姿估计方面的性能均优于最先进的技术。
2. 主要方法
BVMatch方法包括图1所示的地点识别步骤和姿态估计步骤。在地点识别步骤中,BVMatch生成BV图像,并使用BoW方法进行帧检索。在姿态估计步骤中,BVMatch使用RANSAC匹配BV图像对,并使用类似的变换重建Lidar对的粗略2D姿态。最后,BVMatch使用迭代最近点(ICP)细化,以2D姿态作为初始猜测来准确对齐Lidar对。 接下来,我们首先介绍BV图像生成机制,然后介绍Lidar扫描对的粗略2D姿态重建。最后,我们展示离线字典和关键帧数据库的创建。
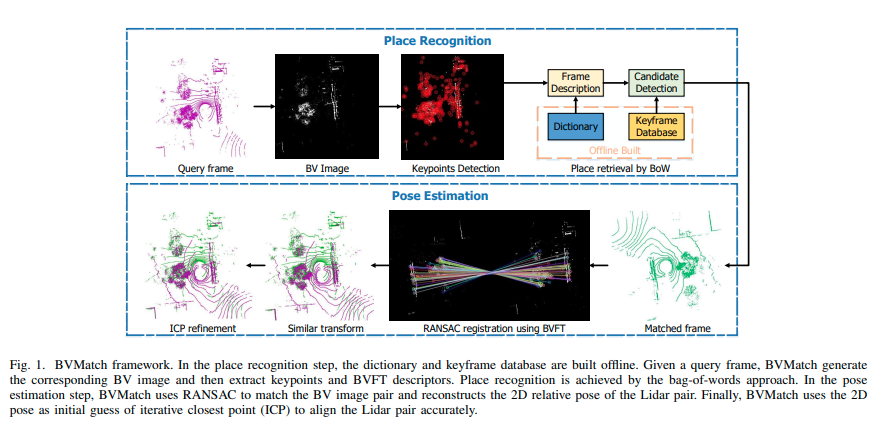
图1. BVMatch框架。在地点识别步骤中,字典和关键帧数据库是离线构建的。给定一个查询帧,BVMatch生成相应的BV图像,然后提取关键点和BVFT描述符。通过词袋模型方法实现地点识别。在姿态估计步骤中,BVMatch使用RANSAC算法匹配BV图像对,并重建激光雷达对的2D相对姿态。最后,BVMatch使用2D姿态作为迭代最近点(ICP)的初始猜测,以精确对齐激光雷达对。
2.1 BV图像生成
BV图像有几种类型,例如用于位置识别的最大高度图[22]和用于物体检测的密度图[29]。这两种图像都总结了周围结构的垂直形状。最大高度图使用具有最大高度的点的坐标值,而密度图利用点云密度。最大高度图对姿态敏感,因为机器人移动时点的坐标值可能会严重变化。相比之下,密度图更加稳健,因为点云的密度不依赖于特定的点。因此,在这项工作中,我们使用后者作为我们的BV图像表示。
设 P = { P i ∣ i = 1 , … , N p } P = \{P_i | i = 1, …, N_p\} P={Pi∣i=1,…,Np}为由点 P i = ( x i , y i , z i ) P_i = (x_i, y_i, z_i) Pi=(xi,yi,zi)组成的点云, N p N_p Np为点云中的点数。假设点云是在道路场景中收集的。 x x x轴指向右侧, y y y轴指向前方, z z z轴指向上方。在这个坐标系中, x − y x-y x−y平面是地面平面。给定一个点云 P P P,我们首先使用leaf大小为 g g g米的体素网格滤波器均匀分布点。然后,我们将地面空间离散化为分辨率为 g g g米的网格。点云密度是每个网格中的点数。我们考虑一个以坐标原点为中心的 [ − C m , C m ] [−C m, C m] [−Cm,Cm]立方窗口。然后,BV图像 B ( u , v ) B(u, v) B(u,v)是一个大小为 [ 2 C g ] × [ 2 C g ] [\frac{2C}{g}] × [\frac{2C}{g}] [g2C]×[g2C]的矩阵。BV强度 B ( u , v ) B(u, v) B(u,v)定义为
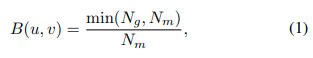
其中, N g N_g Ng表示在位置 ( u , v ) (u,v) (u,v)处网格中的点数, N m N_m Nm表示归一化因子。 N m N_m Nm被设置为点云密度的第99个百分位数。 BV图像是点云的压缩表示,描述了自我中心环境的2.5D结构信息。它忽略了沿z轴的点分布,同时保留了x-y平面上的刚性结构。我们发现,在道路场景中,杆、立面和路标通常在BV图像中形成边缘。这些特征具有良好的重复性,并且在机器人移动时保持稳定。我们采用FAST [30]进行特征检测,并在BVMatch流程中使用关键点进行配准。
2.2 姿态重建
由于BV图像均匀离散化了地面空间,激光雷达扫描对的变换 ( P i , P j ) (P_i,P_j) (Pi,Pj)与BV图像对 ( B i ( u , v ) , B j ( u , v ) ) (B_i(u,v),B_j(u,v)) (Bi(u,v),Bj(u,v))的变换类似。在获得 ( B i ( u , v ) , B j ( u , v ) ) (B_i(u,v),B_j(u,v)) (Bi(u,v),Bj(u,v))的变换之后,我们有 B i ( u , v ) = B j ( u 0 , v 0 ) B_i(u,v)= B_j(u0,v0) Bi(u,v)=Bj(u0,v0),其中坐标
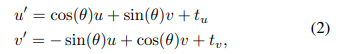
其中 ( t u , t v , θ ) (t_u,t_v,θ) (tu,tv,θ)是变换参数。对于 ( P i , P j ) (P_i,P_j) (Pi,Pj)对的变换矩阵 T i j T_{ij} Tij是
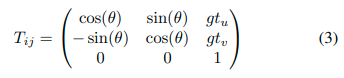
g表示体素网格滤波器的leaf大小。
2.3 字典和关键帧数据库
BVMatch利用词袋模型方法提取全局描述符,并使用关键帧数据库来检测查询激光雷达扫描的最佳匹配帧。 词袋模型方法假设环境中的相似结构会产生相似的特征分布。为了学习我们场景中的这种分布,我们从训练BV图像中提取了丰富的BVFT描述符。然后,我们应用K-means聚类算法获得了总共b个聚类。每个聚类是一个词,这些词的中心形成了一个词袋字典。我们使用该字典通过将点云的BVFT描述符分类为哪些词来将点云编码为词的形式。为了加权那些频繁且不具有区分性的词,我们使用了频率逆文档频率(TF-IDF)[4]。最后,我们为每个点云得到了一个大小为b的全局描述符。
关键帧数据库存储了带有全局位姿和描述符的BV图像。机器人在特定地点行进并收集沿途的激光雷达扫描。通过使用SLAM或GPS信息构建地点的地图,该遍历中收集的每个激光雷达扫描都被标记了全局位姿。我们每隔S米提取一个关键帧激光雷达扫描,并为每个关键帧生成一个全局描述符。关键帧数据库使用所有这些全局描述符、位姿和BV图像构建。
3. 提议的BVFT描述符(重点内容)
虽然BV图像保留了场景中稳定的垂直结构,但由于激光雷达扫描的稀疏性,它会遭受严重的强度失真。为了提取出独特的局部描述符,我们首先利用Log-Gabor滤波器计算BV图像的局部响应。然后,我们构建了一个最大索引图(MIM)[12],最初用于多模态图像匹配。最后,我们构建了一种对BV图像的强度和旋转变化不敏感的鸟瞰图特征变换(BVFT)。