让线性回归在非线性数据上表现提升的核心方法之一是对数据进行分箱,也就是离散化。与线性回归相比,我们常用的一种回归是决策树的回归。为了对比不同分类器和分箱前后拟合效果的差异,我们设置对照实验。
生成一个非线性数据集前,先导入相应的模块和类:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor设置X的值:
rnd = np.random.RandomState(42) #设置随机数种子
X = rnd.uniform(-3, 3, size=100) #random.uniform,从输入的任意两个整数中取出size个随机数设置Y值:
#生成y的思路:先使用NumPy中的函数生成一个sin函数图像,然后再人为添加噪音
y = np.sin(X) + rnd.normal(size=len(X)) / 3 #random.normal,生成size个服从正态分布的随机数画图:
#使用散点图观察建立的数据集是什么样子
plt.scatter(X, y,marker='o',c='k',s=20)
plt.show()
通过在正弦曲线周围添加噪声,我们生成了上图。将数据转为二维后再训练数据:
X = X.reshape(-1, 1)用不同的分类器训练数据,建立模型:
#使用原始数据进行建模
LinearR = LinearRegression().fit(X, y)
TreeR = DecisionTreeRegressor(random_state=0).fit(X, y)接下来做对比实验:
#放置画布
fig, ax1 = plt.subplots(1)
#创建测试数据:一系列分布在横坐标上的点
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
plt.tight_layout()
plt.show()
#从这个图像来看,可以得出什么结果?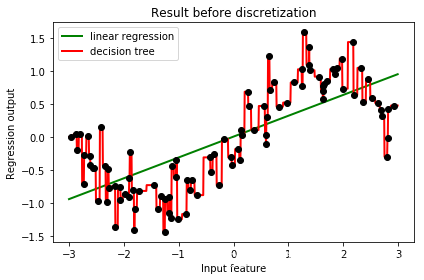
结果分析:从图像上可以看出,线性回归无法拟合出这条带噪音的正弦曲线的真实面貌,只能够模拟出大概的趋势,而决策树却通过建立复杂的模型将几乎每个点都拟合出来了。此时此刻,决策树处于过拟合的状态,对数据的学习过于细致, 而线性回归处于拟合不足的状态,这是由于模型本身只能够在线性关系间进行拟合的性质决定的。为了让线性回归在类似的数据上变得更加强大,我们可以使用分箱,也就是离散化连续型变量的方法来处理原始数据,以此来提升线性回归的表现。在应用分箱之前,我们先来讲解什么是分箱:
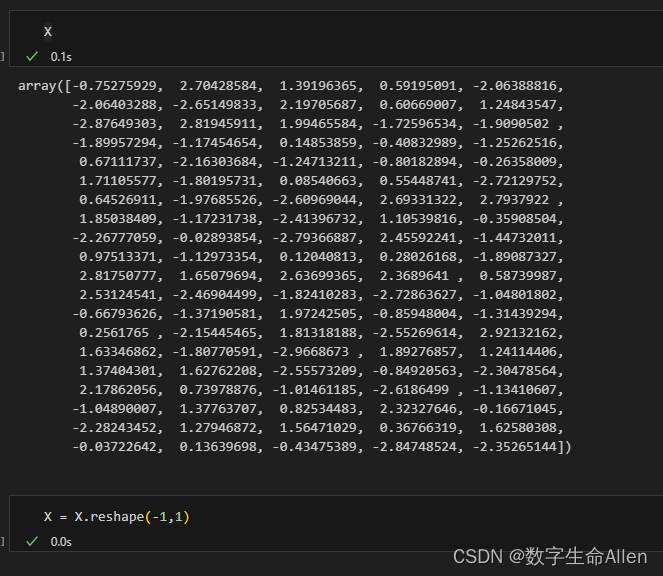
假设现在的X有100条数据,我们把它转换成二维矩阵:
然后导入分箱的类,实例化后对X进行分箱后将值赋给X_binned:
from sklearn.preprocessing import KBinsDiscretizer
#将数据分箱
enc = KBinsDiscretizer(n_bins=10 #分几类?
,encode="onehot") #ordinal
X_binned = enc.fit_transform(X)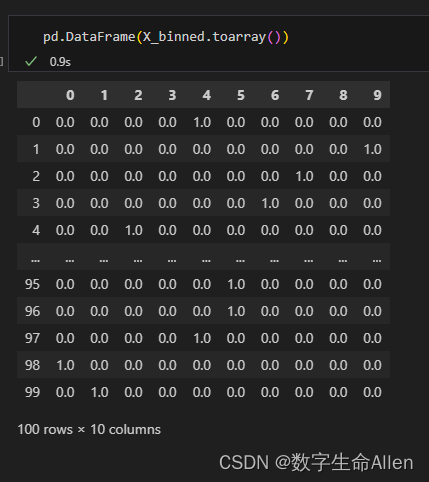
可以看到分箱后的结果是生成了一个100行,10列的列表。我们可以这样来理解分箱的过程:
在这个过程中,每个观察值都被分配到一个"箱子"中,通过创建一个新的二进制特征来表示这个观察值是否在这个箱子中。例如,一个连续的特征,我们创建10个"箱子",每个箱子代表一个范围。然后,对于每个观察值,你会创建一个10维的向量,其中9个元素为0,只有一个元素为1,表示这个观察值落在哪个箱子中。在这个列表中,行索引代表数据点,列索引代表哪个箱子,数据点在哪个箱子,哪个箱子的值就为1,。
接下来,我们做一个对比实验,来判断分箱前后的拟合效果差异,图一是分箱前,图二是分箱后:
#准备数据
enc = KBinsDiscretizer(n_bins=10,encode="onehot")
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)通常在训练数据上使用fit_transform,在测试数据上使用transform
#将两张图像绘制在一起,布置画布
fig, (ax1, ax2) = plt.subplots(ncols=2
, sharey=True #让两张图共享y轴上的刻度
, figsize=(10, 4))
#在图1中布置在原始数据上建模的结果
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
ax1.plot(X[:, 0], y, 'o', c='k')
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
#使用分箱数据进行建模
LinearR_ = LinearRegression().fit(X_binned, y)
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)
#进行预测,在图2中布置在分箱数据上进行预测的结果
ax2.plot(line #横坐标
, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果
, linewidth=2
, color='green'
, linestyle='-'
, label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
#绘制和箱宽一致的竖线
ax2.vlines(enc.bin_edges_[0] #x轴
, *plt.gca().get_ylim() #y轴的上限和下限
, linewidth=1
, alpha=.2)
#将原始数据分布放置在图像上
ax2.plot(X[:, 0], y, 'o', c='k')
#其他绘图设定
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()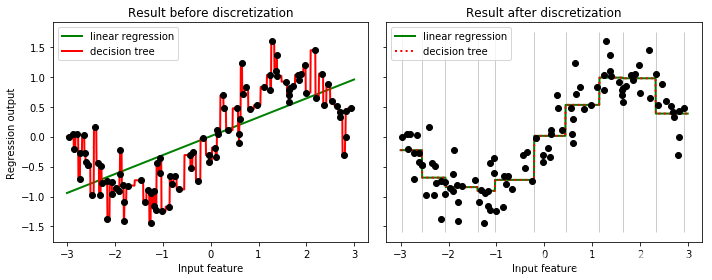
从图像上可以看出,离散化后线性回归和决策树上的预测结果完全相同——线性回归比较成功地拟合了数据的分布,而决策树的过拟合效应也减轻了。由于特征矩阵被分箱,因此特征矩阵在每个区域内获得的值是恒定的,因此所有模型对同一个箱中所有的样本都会获得相同的预测值。与分箱前的结果相比,线性回归明显变得更加灵活,而决策树的过拟合问题也得到了改善。但注意,一般来说我们不使用分箱来改善决策树的过拟合问题,因为树模型带有丰富而有效的剪枝功能来防止过拟合。




![[Linux] ssh远程访问及控制](https://img-blog.csdnimg.cn/4a2e4ebfc4ce4f4691698fcd442a9f75.png)