目录
1.样本(示例)
2.属性
3.属性值
4.属性空间
5.样本空间
6.学习(训练)
7.数据集
8.测试
9.假设
10.学习器
11.标记
12.样例
13.标记空间(样例空间)
14.分类与回归
15.有监督学习、无监督学习
16.真相
17.聚类
18.未见样本
19.未见分布
20.泛化能力
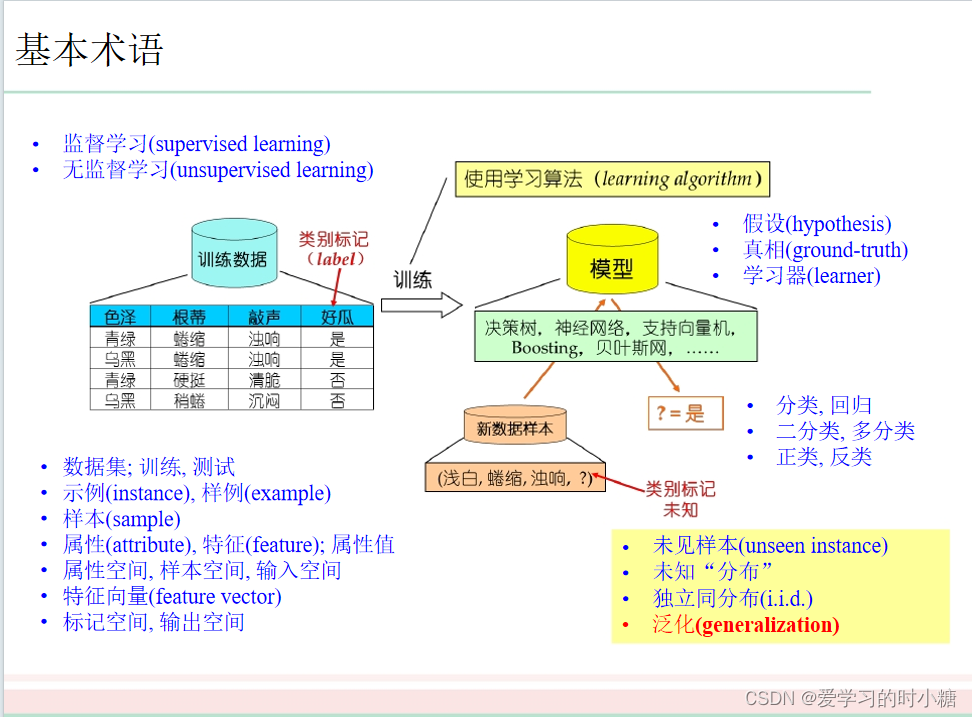
1.样本(示例)
描述一个事件或者对象的数据。例如我的设计一个洋娃娃的数据如下:
(肤色=白皮肤 ;眼睛颜色=蓝眼睛 ;头发颜色=金色)这条数据就是一个样本或者叫做示例。
特征向量:我们把肤色、眼睛颜色、头发颜色看成坐标轴,这一组值,对应一个坐标,因此我们也可以把样本示例叫做特征向量,一个样本对应的所有特征组成的向量称为特征向量。
2.属性
表示事件或者事物的特征,我们称为属性。例如:肤色、眼睛颜色、头发颜色。
3.属性值
属性的值我们称为属性值。例如:白皮肤、蓝眼睛、金色。
4.属性空间
是由所有属性组成的空间,通常每个维度对应一个属性。在属性空间中,每个样本都可以被表示为一个点。
5.样本空间
是所有样本组成的集合,每个样本在样本空间中是唯一的。样本空间的维度取决于属性的数量。
6.学习(训练)
我们根据数据生成模型的过程就可以称为训练或者是学习。在这个过程中,模型通过学习样本中的模式或规律来进行预测或分类。
7.数据集
所有数据组成的集合,数据集包括=70%训练集+20%验证集+10%测试集。训练过程中使用的数据称为训练数据,每一个样本称为训练样本。
8.测试
模型训练结束后测试模型效果的过程。
9.假设
学习的模型具有的某种潜在规律我们称为假设。假设通过调整模型参数进行表达。
假设你想训练一个模型来预测明天的天气。你有过去一年每天的天气数据,包括温度、湿度、风速等。为了让机器学习模型从这些数据中学到规律,你可能会做出一个假设,比如说:
天气的变化与温度和湿度有关。如果温度升高,湿度降低,那么明天可能是晴天。
在这个例子中,你的假设是一种对天气变化规律的猜测。你认为温度和湿度是影响天气的关键因素。机器学习模型在训练过程中会尝试调整参数,使得这个假设能够对过去的数据有很好的解释,并且在未见过的数据上能够进行准确的预测。
总的来说,假设是机器学习中用来表示我们对数据规律的一种猜测或假定。这个假设在训练模型时起着重要的作用,因为它指导模型学习数据中的模式和关系。
10.学习器
模型被称为学习器。因为模型就是通过学习经验从而对于新情况进行预测。
11.标记
样例的输出结果。例如:上述样例的中国人洋娃娃、美国人洋娃娃。
12.样例
有标记信息的样本称为样例。
13.标记空间(样例空间)
所有有标记信息的集合。
14.分类与回归
学习任务分为分类和回归问题。分类问题是由离散值组成的,eg:中国人洋娃娃、美国人洋娃娃,如果是输出的是连续的值eg:0.37、0.65这种就是回归问题。
分类问题又分为二分类和多分类,二分类又分为正类和负类(反类)。
15.有监督学习、无监督学习
根据数据有无标记信息,将模型的训练过程分为有监督学习和无监督学习。
16.真相
在进行模型训练时,你给模型提供的标准答案。它对新样本进行预测,并于标准答案进行比较,验证是否准确。
真相详解:机器学习里面的Ground Truth是什么意思-CSDN博客
17.聚类
根据数据的分布结构进行自动分组,一般用于无监督学习。
18.未见样本
模型在训练时没有见过的样本我们称为未见样本,我们在同时使用未见样本来测试模型的泛化能力。
19.未见分布
模型在训练过程中没有见过的分布被称为未见分布,通常出现未见分布会使得模型性能下降。
20.泛化能力
模型在训练时,模型对于未出现过的数据进行准确预测的能力。对于不同样本得预测结果都比较准确我们称为该模型泛化能力好。





![双写绕过 [极客大挑战 2019]BabySQL 1](https://img-blog.csdnimg.cn/a42a0dad94a04c189065108f2e0556e5.png)