一、说明
卷积神经网络,有很多种类,这不仅仅是各种试验或尝试。而且是已经设计好的网络存在若干不尽人意之处,需要弥补和改进。因此,本文就是记录这些网络的优缺点,从新意上说,本文全无,但是从启发初学者还是有点意义。

二、基础操作
2.1 实验使用的数据集
我开始学习神经网络和 CNN 中的不同模型架构。在这里,我写了关于 4 个模型架构的文章,以及我在这 4 个模型上训练图像集时的发现。撰写本文仅用于学习目的,并更好地了解我们在这些模型中看到的改进。
这里的所有观察结果都与一个图像集相关,不能作为模型性能的衡量标准。哪种模型最适合取决于每个用例。例如,如果您了解我的金属铸造项目,就会发现简单的 CNN 模型往往比 ResNet 模型表现得更好,而 ResNet 模型在此表现出色。
我在实验中使用了[非洲野生动物]( https://www.kaggle.com/biancaferreira/african-wildlife )数据集。
该数据集中有 4 个类:
- 水牛
- 大象
- 犀牛
- 斑马
2.1 本文内容
- 什么是卷积神经网络
- 在上述数据集上实现 4 个不同的 CNN 模型,并根据我的实验得出的推论简要介绍每个模型。
- 结论
2.3 什么是卷积神经网络?
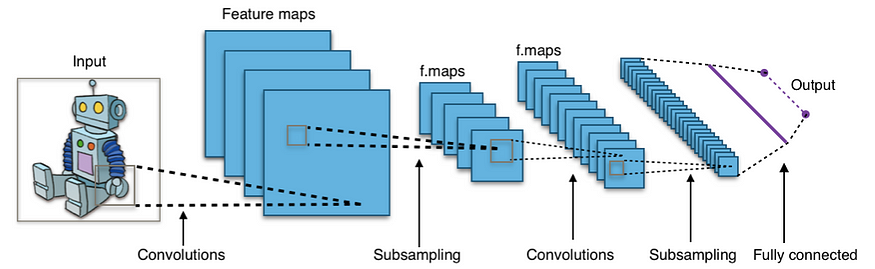
典型的CNN网络
- 卷积神经网络是一种人工神经网络,主要用于图像识别应用。它由称为感知器的多层组成,用于以最详细的方式学习图像中存在的特征。
- 这里的“卷积”代表了对图像内特征的理解。提取这些特征需要整个卷积过程。
- 为了提取这些特征,我们使用过滤器并提及要使用的过滤器的数量(内核)。
- 池化是 CNN 中的另一个概念。它用于减少对图像运行过滤器后获得的特征数量。与图像本身相比,过滤器使我们获得大量特征。因此,池化用于获得相同的更好的概括表示。例如,由于过滤器(内核)的数量及其形状,25x25 的图像最终可能具有 100x100 的特征。池化可以使用最大池化或均值池化来减少这些特征。我不会深入研究什么是池化。
- 填充是另一个 CNN 概念,我们在图像的边缘添加零。这样做有两个原因。为了更好地读取边缘特征并获得与输入图像相似的输出。
- 最后,CNN 的输出被展平并发送到全连接层。这是 CNN 的神经网络部分。它将使机器能够从提取的特征中学习并创建通用模型。
要了解有关卷积神经网络的更多信息,我将从这个[视频]( https://youtu.be/aircAruvnKk )开始。
三、LeNet网
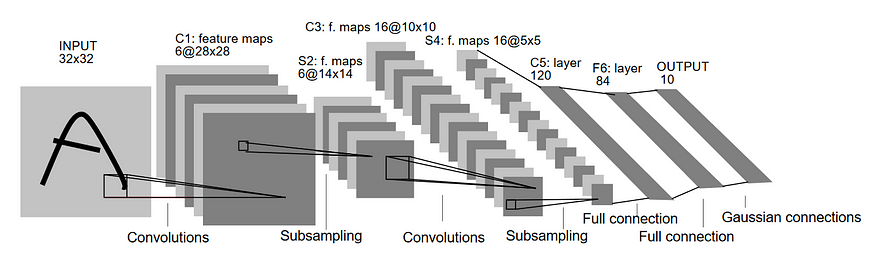
- LeNet 架构由 Yann Lecun 于 1998 年发明,旨在能够执行光学字符识别 (OCR)。与其他架构相比,该架构非常小且简单。该图像集由 0-9 的黑白数字图像组成。
- 它由3个卷积层和3个池化层组成。在这些层之后,输出被展平,数据被发送到全连接层。神经网络的最后一个密集层可以是用于预测输出的任何激活函数。
- 根据 LeNet 发表的论文,在整个网络中,所有层的激活函数都是 tanh。我对该网络使用了相同的激活函数。我们必须记住,今天使用的常用激活函数在 1998 年还不存在。
2.1 在您的示例和发现中实施
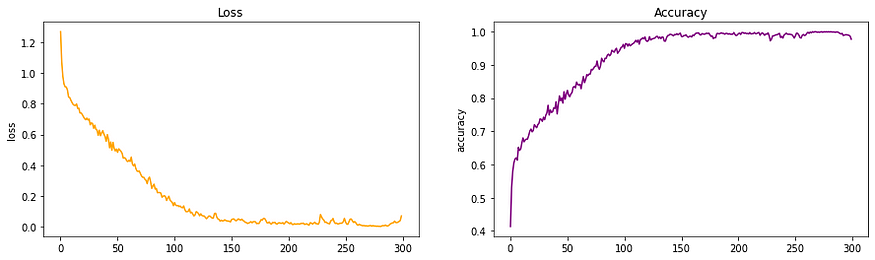
LeNet 架构的损失和准确率图
- 从上面的准确率图中可以看出,我们可以清楚地看到该模型显示的学习速度很慢。
- 该网络缺乏深度是原因之一。
- 另一个原因可能是使用了激活函数 tanh。
2.2 优点
- 这个网络很好地介绍了神经网络的世界,而且非常容易理解。它非常适合字符识别图像。
2.3 缺点
- 该模型是专门针对特定用例构建的。虽然这是 1998 年的一项重大突破,但它在处理彩色图像方面的表现却不佳。大多数图像识别问题都需要 RGB 图像才能更好地识别。
- 由于模型不是很深,它很难扫描所有特征,从而产生性能较差的模型。如果神经网络没有从训练图像中获得足够的特征,那么模型将很难概括并创建准确的模型。
四、AlexNet 网
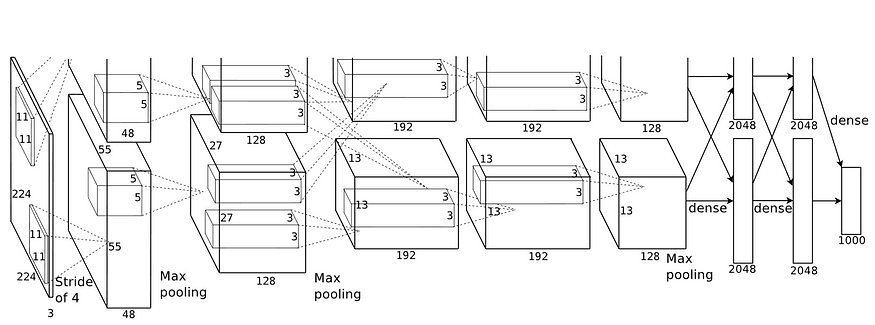
发表的论文中看到的 Alexnet 架构图像
- AlexNet 架构于 2012 年在 ImageNet 大规模视觉识别挑战赛上推出。
- 它由 Alex Krizhevsky 设计,并与 Illya Sutskever 和 Krizhevsky 的博士生导师 Geoffrey Hinton 博士一起出版。
- AlexNet由8层组成,并使用了ReLu激活函数,这是深度学习的重大发现。它摆脱了梯度消失的问题,因为现在梯度值不再限制在一定范围内。
- 它是第一个基于 GPU 的 CNN 模型,比以前的模型快 4 倍。
4.1 在您的示例和发现中实施
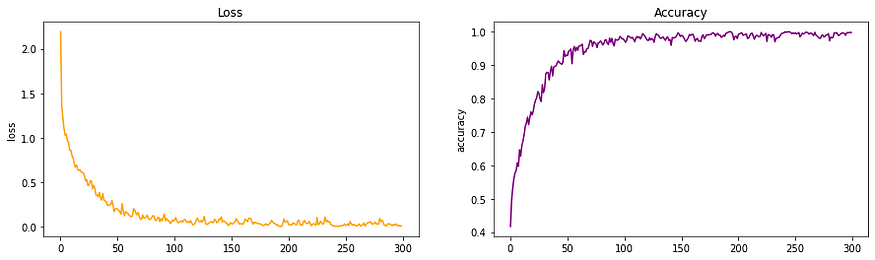
损失和准确度 AlexNet 架构
- 我观察到,与 LeNet 相比,训练速度有所提高。我们在图中可以清楚地看到,该模型更快地实现了更好的精度。
- 与 LeNet 相比,损失也以更快的速度减少。
- 网络深度的增加和 ReLu 的引入对神经网络产生了重大影响。这个模型启发了未来模型的研究。
4.2 优点
- AlexNet 是第一个使用 GPU 进行训练的主要 CNN 模型。这可以加快模型的训练速度。
- AlexNet 是一种更深层次的 8 层架构,这意味着与 LeNet 相比,它能够更好地提取特征。它在当时的彩色图像上也很有效。
- 该网络中使用的 ReLu 激活函数有 2 个优点。与其他激活函数不同,它不限制输出。这意味着不会有太多功能损失。
- 它否定了梯度求和的负输出,而不是数据集本身。这意味着它将进一步提高模型训练速度,因为并非所有感知器都处于活动状态。
4.3 缺点
- 与本文进一步使用的模型相比,该模型的深度非常小,因此很难从图像集中学习特征。
- 我们可以看到,与未来的模型相比,需要更多的时间才能获得更高精度的结果。
五、VGG网
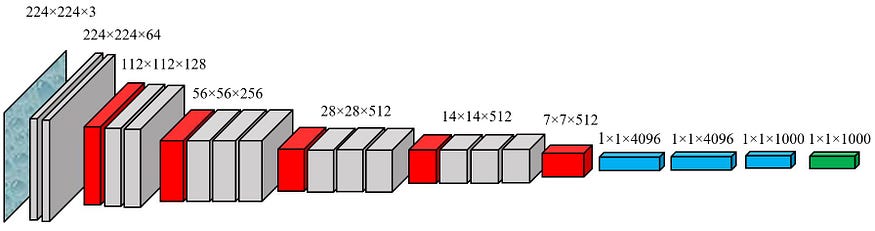
- Visual Geometric Group 或 VGG 是一种 CNN 架构,在 AlexNet 两年后于 2014 年推出。引入该模型的主要原因是为了在训练图像分类/识别模型时了解深度对准确性的影响。
- VGG 网络引入了将多个具有较小内核尺寸的卷积层分组的概念,而不是使用一个具有大内核尺寸的卷积层。这导致输出的特征数量减少,其次是包含 3 个 ReLu 层,而不是增加一个学习实例。从上图中可以看出,我们看到分层结构(灰色框),后面是池化层(红色框)。
5.1 在您的示例和发现中实施
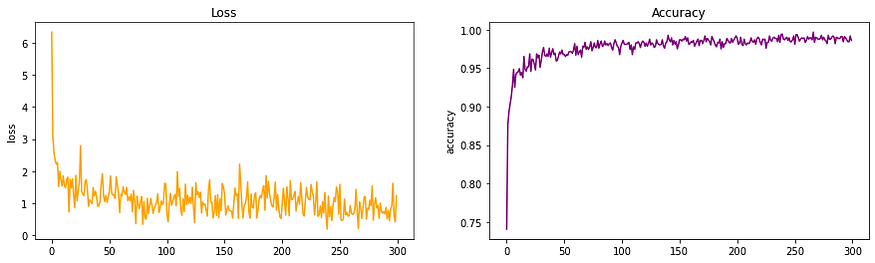
VGG-16 架构的损耗和精度
- 我在这里的观察是,虽然达到最大准确度所需的纪元数量有所减少,但损失需要更长的时间才能收敛到最小值。
- VGG 中引入更多层使模型能够更好地理解图像中的特征。
- 然而,不断学习和重新学习是 VGG 的一个问题,这就是为什么损失似乎如此不可预测(梯度爆炸)。
- 这个问题在 ResNet 架构中得到了解决,该架构引入了残差学习的概念。
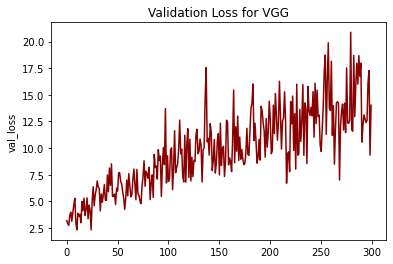
观察到 VGG-16 的验证损失
- 验证损失往往会随着时间的推移而增加,这告诉我随着时间的推移,这个模型过度拟合了数据集。对于其他图像集,情况可能并不总是如此。
5.2 优点
- VGG 带来了准确性的巨大提高和速度的提高。这主要是因为提高了模型的深度并引入了预训练模型。
- 较小内核的层数增加会导致非线性增加,这对于深度学习始终是积极的。
- VGG 带来了基于相似概念的各种架构。这为我们提供了更多选择,让我们可以选择哪种架构最适合我们的应用程序。
5.3 缺点
- 我发现该模型的一个主要缺点是存在梯度消失问题。如果我们查看我的验证损失图,我们可以清楚地看到它呈增长趋势。其他任何型号都没有出现这种情况。ResNet 架构解决了梯度消失问题。
- VGG 比新的 ResNet 架构慢,后者引入了残差学习的概念,这是另一个重大突破。
六、ResNet 残差网络
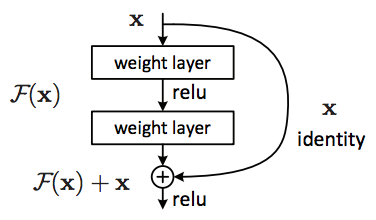
ResNet 中的残差学习
- ResNet 于 2015 年推出,带来了准确性的大幅提升和速度的大幅提升。
- VGG引入了增加层数的概念来提高精度,但是发现当我们将层数增加到超过20时,模型无法收敛到最小误差%。造成这种情况的一个主要原因是梯度消失问题。学习率变得如此之低,以至于模型的权重没有发生变化。
- 另一个问题是梯度爆炸。这在我的 VGG 图中也可见,我的损失波动不规律。当引入批量归一化后,这个问题得到了解决,但它仍然在较小的范围内波动。
- 为了解决这个问题,引入了残余学习的概念,该概念的灵感来自于人脑横向抑制的概念。它只是意味着大脑中的神经元能够控制其邻近神经元是否放电。
- 残差学习可以用一个非常简单的例子来解释。最初,当我们学习骑自行车时,我们会犯错误,但我们会学习。一旦我们能够骑自行车,我们的大脑就会停止发射负责学习技能的神经元,使我们能够专注于与骑自行车有关的其他事情。
6.1 在您的示例和发现中实施
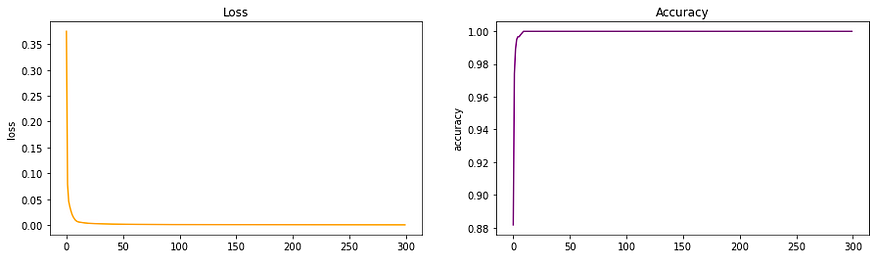
ResNet50 架构的损失和准确性
- 我们看到在实现高精度和低损耗方面取得了巨大进步。残差学习的概念堪称神经网络的重大突破。
- 从 ResNet 架构创建的模型还具有较低的验证损失,这意味着训练时不会发生过度拟合。
6.2 优点
- ResNet 架构不需要在每个 epoch 中激发所有神经元。这大大减少了训练时间并提高了准确性。一旦学习了某个功能,它就不会尝试再次学习它,而是专注于学习新的功能。一种非常聪明的方法,极大地提高了模型训练性能。
- 相同的 VGG 网络的复杂性导致了退化问题,可以通过残差学习来解决。
七、结论
我进行此实验是为了更好地了解不同类型的 CNN 模型以及它们对图像分类模型的训练有何实际影响。您可以在我的合作笔记本上进一步探索这个实验。使用的图像来自本次kaggle比赛。
谢谢阅读!


![[RK3568][Android12.0]--- 系统自带预置第三方APK方法](https://img-blog.csdnimg.cn/6f3cae0cf875407c8e13facb712b5f4d.png)