对于事务来说,是我们平时在基于业务逻辑编码过程中不可或缺的一部分,它对于保证业务及数据逻辑原子性立下了汗马功劳。那么,我们基于Spring的声明式事务,可以方便我们对事务逻辑代码进行编写,那么在开篇的第一部分,我们就来用一个示例,来演示一下Spring事务的编写方式。
一、事务使用示例
首先添加Maven依赖
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>创建用户的数据库表tb_user
CREATE TABLE `tb_user` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int NOT NULL DEFAULT '-1' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `index_name` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户信息表';创建用户的实体类User.java
@Data
public class User{
private Long id;
private String name;
private Integer age;
}创建User接口接实现类UserService.java和UserServiceImpl.java
@Transactional(propagation = Propagation.REQUIRED) // 配置事务传播机制
public interface UserService {
void save(User user);
}
public class UserServiceImpl implements UserService {
private JdbcTemplate jdbcTemplate;
public UserServiceImpl(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public void save(User user) {
Object[] userInfo = new Object[]{user.getName(), user.getAge()};
int[] types = new int[]{Types.VARCHAR, Types.INTEGER};
jdbcTemplate.update("insert into tb_user(name, age) values(?, ?)", userInfo, types);
// throw new RuntimeException("抛出异常!"); // 制造回滚现象
}
}添加事务配置及数据库配置
<!-- 事务 <tx:annotation-driven/> -->
<tx:annotation-driven transaction-manager="transactionManager"/>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 配置数据源 -->
<bean id="dataSource" class= "org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/muse" />
<property name="username" value="root" />
<property name="password" value="root" />
<property name="initialSize" value="1" />
<!-- 连接池的最大值 -->
<property name="maxActive" value="300" />
<!-- 最大空闲值。当经过一个高峰时间后,连接池可以慢慢将已经用不到的连接慢慢释放一部分,一直减 maxIdle 为止 -->
<property name="maxIdle" value="2" />
<!-- 最小空闲值。当空闲的连接数少于阀值时,连按池就会预申请去一些连接,以免洪峰来时来不及申请 -->
<property name="minIdle" value="1" />
</bean>
<bean id="userTxService" class="com.muse.springbootdemo.tx.UserServiceImpl">
<constructor-arg name="dataSource" ref="dataSource"/>
</bean>创建测试类TxTest.java
public class TxTest {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("oldbean.xml");
UserService userService = (UserService) context.getBean("userTxService");
User user = new User();
user.setName("muse");
user.setAge(10);
userService.save(user);
}
}在上面的例子中,如果我们放开
UserServiceImpl.save(...)方法中的RuntimeException异常,那么则会在执行过程中由于发生异常而导致整个事务的回滚操作。
二、事务自定义标签
2.1> 注册InfrastructureAdvisorAutoProxyCreator
当我们希望在Spring中开启事务的时候,我们需要在配置中增加<tx:annotation-driven/>
我们在Spring项目中搜索“annotation-driven”,可以发现与事务相关的处理类为TxNamespaceHandler,在该类中,注册了AnnotationDrivenBeanDefinitionParser解析器,代码如下所示:

在AnnotationDrivenBeanDefinitionParser类中我们需要关注的就是parse(...)方法,它负责执行BeanDefiniton的解析操作。这里会通过mode属性来确定是采用aspectj的方式进行解析还是采用AOP代理的方式进行解析,由于常用的就是采用AOP代理的方式进行解析操作,所以此处我们只需要关心AopAutoProxyConfigurer类的configureAutoProxyCreator(...)方法,在该方法中需要执行如下几步的操作:
【步骤1】注册InfrastructureAdvisorAutoProxyCreator类型的APC;
【步骤2】创建AnnotationTransactionAttributeSource类型的BeanDefinition;
【步骤3】创建TransactionInterceptor类型的BeanDefinition;
【步骤4】创建BeanFactoryTransactionAttributeSourceAdvisor类型的BeanDefinition;
【步骤5】将以上3种BeanDefinition聚合到CompositeComponentDefinition中;

在registerAutoProxyCreatorIfNecessary(...)方法中,我们试图将InfrastructureAdvisorAutoProxyCreator类型注册为APC(AutoProxyCreator),代码如下所示:
public static void registerAutoProxyCreatorIfNecessary(ParserContext parserContext, Element sourceElement) {
/** 注册InfrastructureAdvisorAutoProxyCreator类型的APC */
BeanDefinition beanDefinition = AopConfigUtils.registerAutoProxyCreatorIfNecessary(parserContext.getRegistry(), parserContext.extractSource(sourceElement));
/** 为名字为"org.springframework.aop.config.internalAutoProxyCreator"的BeanDefinition设置属性proxyTargetClass和属性exposeProxy的值 */
useClassProxyingIfNecessary(parserContext.getRegistry(), sourceElement);
// 将名称为"org.springframework.aop.config.internalAutoProxyCreator"的beanDefinition执行组件注册
registerComponentIfNecessary(beanDefinition, parserContext);
}AopConfigUtils类的registerAutoProxyCreatorIfNecessary(...)方法,实际作用就是注册InfrastructureAdvisorAutoProxyCreator类型的APC,源码如下所示:

2.2> InfrastructureAdvisorAutoProxyCreator获得代理对象
在上面的内容中,我们可以发现将InfrastructureAdvisorAutoProxyCreator类注册为APC,那么为了方便我们更加容易的理解这个类,我们先来看一下它的类图,有哪些继承关系。

在上面的类图中,我们发现它实现了BeanPostProcessor和InstantiationAwareBeanPostProcessor这两个类,这两个类分别提供了针对初始化的前置处理&后置处理的方法以及针对实例化的前置处理&后置处理的方法。

下面我们来看一下AbstractAutoProxyCreator类的postProcessAfterInitialization(...)方法,该方法实现了代理包装的逻辑,请见下面所示:
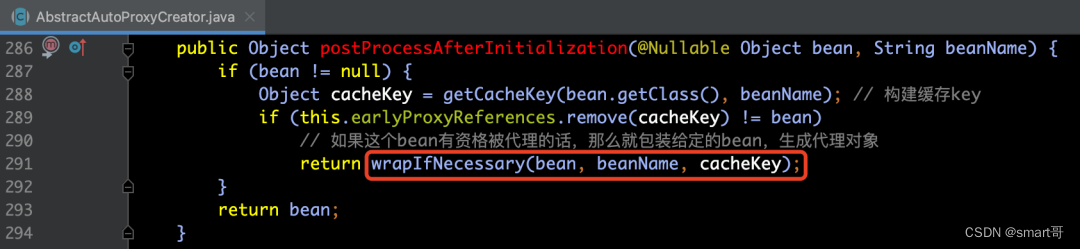
在wrapIfNecessary(...)方法中,主要的业务逻辑总共有两步:
【步骤1】找出指定bean对应的增强器;
【步骤2】根据找出的增强器创建代理;

AbstractAdvisorAutoProxyCreator类的getAdvicesAndAdvisorsForBean(...)方法,有如下3个主要步骤:首先,获得所有的Advisor增强器;其次,寻找匹配的增强器;最后,对增强器进行排序;此处我们只针对前两个步骤进行解析,代码如下所示:

2.2.1> findCandidateAdvisors() 获得所有增强器
findCandidateAdvisors()方法有两个子类实现,如下所示:
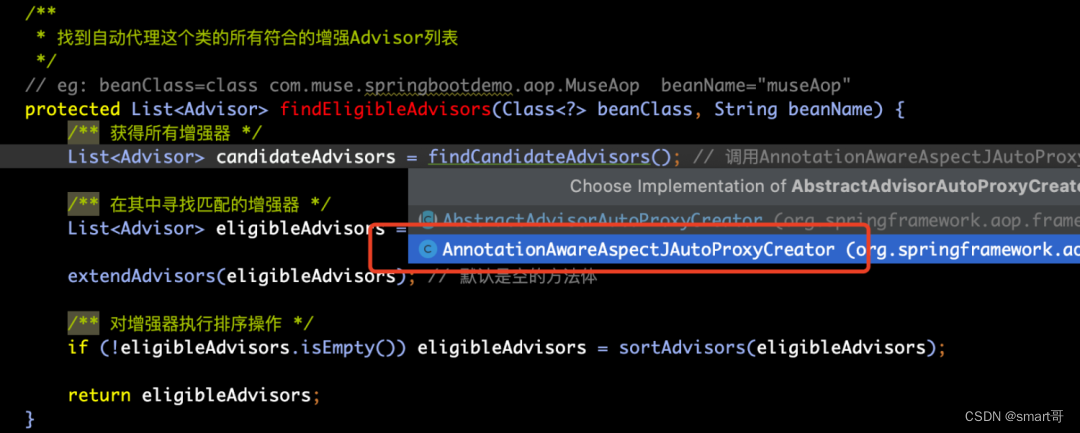
调用了AnnotationAwareAspectJAutoProxyCreator类中的findCandidateAdvisors()方法
protected List<Advisor> findCandidateAdvisors() {
/** 步骤1:寻找在IOC中注册过的Advisor接口的实现类 */
List<Advisor> advisors = super.findCandidateAdvisors(); // 调用了AbstractAdvisorAutoProxyCreator类中的findCandidateAdvisors()方法
if (this.aspectJAdvisorsBuilder != null)
/** 步骤2:寻找在IOC中注册过的使用@Aspect注解的类 */
advisors.addAll(this.aspectJAdvisorsBuilder.buildAspectJAdvisors());
return advisors;
}我们在SpringAOP源码解析时,解析过AnnotationAwareAspectJAutoProxyCreator类的这个方法实现,那么在本章Spring声明式事务中,我们需要解析的就是AbstractAdvisorAutoProxyCreator类的findCandidateAdvisors()方法了。源码如下所示:
protected List<Advisor> findCandidateAdvisors() {
return this.advisorRetrievalHelper.findAdvisorBeans();
}在findAdvisorBeans()方法中,才是真正获得所有Advisor增强器的处理逻辑,如下源码所示:
public List<Advisor> findAdvisorBeans() {
String[] advisorNames = this.cachedAdvisorBeanNames;
if (advisorNames == null) {
/** 获取IOC中实现了Advisor接口的所有bean的beanName列表 */
advisorNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(this.beanFactory, Advisor.class, true, false);
this.cachedAdvisorBeanNames = advisorNames; // eg: advisorNames="org.springframework.transaction.config.internalTransactionAdvisor"
}
if (advisorNames.length == 0) return new ArrayList<>();
List<Advisor> advisors = new ArrayList<>();
for (String name : advisorNames) {
if (isEligibleBean(name)) {
if (this.beanFactory.isCurrentlyInCreation(name))
if (logger.isTraceEnabled()) logger.trace("Skipping currently created advisor '" + name + "'");
else {
try {
/** 通过beanName获得实例对象,并放入到advisors中 */
advisors.add(this.beanFactory.getBean(name, Advisor.class)); // eg: BeanFactoryTransactionAttributeSourceAdvisor
} catch (BeanCreationException ex) {...}
}
}
}
return advisors; // eg: advisors=[BeanFactoryTransactionAttributeSourceAdvisor]
}在该方法中,大致执行了两个部分的操作:
【第1部分】如果缓存cachedAdvisorBeanNames中没有缓存任何Advisor名称,则获取IOC中实现了Advisor接口的所有bean的beanName列表;
【第2部分】如果beanName列表不为空,则通过beanFactory.getBean(name, Advisor.class)获得实例对象,然后保存到advisors中;
此处需要补充一点的就是,在IOC中,默认初始化了一个Advisor接口的实现类BeanFactoryTransactionAttributeSourceAdvisor,它的beanName就是"org.springframework.transaction.config.internalTransactionAdvisor",那么这个bean初始化的地方就是我们前面介绍的AopAutoProxyConfigurer类中的configureAutoProxyCreator(...)方法,如下所示:

2.2.2> findAdvisorsThatCanApply(...) 寻找匹配的增强器
在2.2.1中,我们已经分析完获取所有增强器的方法findCandidateAdvisors(),那么本节我们将在获取的所有增强(candidateAdvisors)基础上,再去寻找匹配的增强器,即:findAdvisorsThatCanApply(...)方法,相关源码如下图所示:

在findAdvisorsThatCanApply(...)方法中,其主要功能是获得所有增强器candidateAdvisors中,适用于当前clazz的增强器列表。而由于针对引介增强和普通增强的处理是不同的, 所以采用分开处理的方式,请见下图所示:
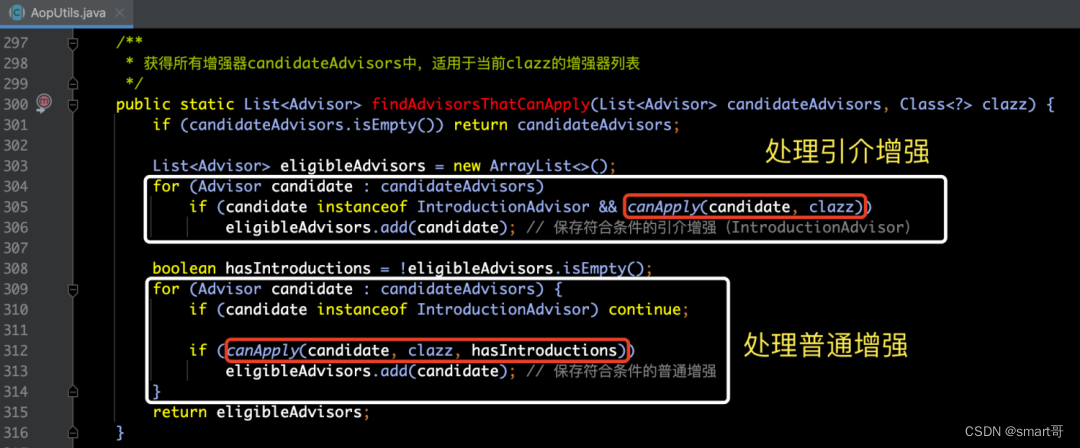
那么,什么是引介增强呢?引介增强是一种特殊的增强。其它的增强是方法级别的增强,即:只能在方法前或方法后添加增强。而引介增强则不是添加到方法上的增强, 而是添加到类级别的增强,即:可以为目标类动态实现某个接口,或者动态添加某些方法。具体实现请见下图所示:

那么,在上面的findAdvisorsThatCanApply(...)方法源码中,我们可以发现,canApply(...)方法是其中很重要的判断方法,那么它内部主要做了什么操作呢?在其方法内部,依然根据引介增强和普通增强两种增强形式分别进行的判断,其中,如果是引介增强的话,则判断该增强是否可以应用在targetClass上,如果可以则返回true,否则返回false。那么,如果是普通增强,则需要再调用canApply(...)方法继续进行逻辑判断。根据上文介绍,我们知道advisor的类型为BeanFactoryTransactionAttributeSourceAdvisor,我们通过类图的集成关系可以看到,它是属于PointcutAdvisor接口类型的,如下所示:

既然BeanFactoryTransactionAttributeSourceAdvisor是属于PointcutAdvisor接口类型的,那么就会执行下图中红框处代码。相关源码请见下图所示:

在canApply(...)方法中,主要的逻辑是获得targetClass类(非代理类) 及 targetClass类的相关所有接口 中的所有方法去匹配,是否满足对targetClass类的增强,如果找到了,则返回false;如果找不到,则返回true;相关源码,请见下图所示:

a> pc.getClassFilter().matches(targetClass) 判断类是否符合候选类
这里的pc.getClassFilter()获得的是TransactionAttributeSourcePointcut类,所以我们来看一下这个类中的matchs(Class<?> clazz)方法,该方法的逻辑也比较简单,首先,判断入参clazz如果是实现了TransactionProxy、TransactionManager或PersistenceExceptionTranslator这三个任意1个接口,则直接返回false;否则,再试图获得TransactionAttributeSource实例对象,此处获得的是AnnotationTransactionAttributeSource类型的实例对象,如果获得不到tas,则返回true;如果获得到了tas,则调用其tas.isCandidateClass(...)方法执行进一步的判断逻辑,代码如下所示:

在isCandidateClass(...)方法中,用于判断入参的targetClass是否是候选类,即:确定给定的类是否是携带指定注释的候选类。此处的核心方法parser.isCandidateClass(targetClass)内部调用的就是AnnotationUtils.isCandidateClass(...),此方法逻辑比较简单,此处不在赘述了。
// eg: targetClass=class com.muse.springbootdemo.tx.UserServiceImpl
/** 确定给定的类是否是携带指定注释的候选类(在类型、方法或字段级别)。 */
@Override
public boolean isCandidateClass(Class<?> targetClass) {
// eg: annotationParsers=[SpringTransactionAnnotationParser@2777, JtaTransactionAnnotationParser@2778]
for (TransactionAnnotationParser parser : this.annotationParsers)
/** isCandidateClass方法逻辑很简单,此处就不再赘述了 */
if (parser.isCandidateClass(targetClass)) // eg:true
return true;
return false;
}b> methodMatcher.matches(method, targetClass)判断是否匹配
那么,判断是否匹配是通过matches(...)方法来确定的,那么我们就来分析一下TransactionAttributeSourcePointcut类的该方法的处理逻辑,请见如下源码所示:
public boolean matches(Method method, Class<?> targetClass) {
TransactionAttributeSource tas = getTransactionAttributeSource();
return (tas == null || tas.getTransactionAttribute(method, targetClass) != null); // 进行匹配操作
}通过getTransactionAttributeSource()方法我们会获得AnnotationTransactionAttributeSource类型的实例对象,由于tas的类型为AnnotationTransactionAttributeSource类,该类的getTransactionAttribute(...)方法是由AbstractFallbackTransactionAttributeSource类实现的,在该方法中,首先会试图从缓存attributeCache中获得TransactionAttribute实例对象,如果有缓存,则返回即可;如果该缓存为空,则需要通过computeTransactionAttribute(method, targetClass)方法来获取TransactionAttribute实例对象。源码如下所示:
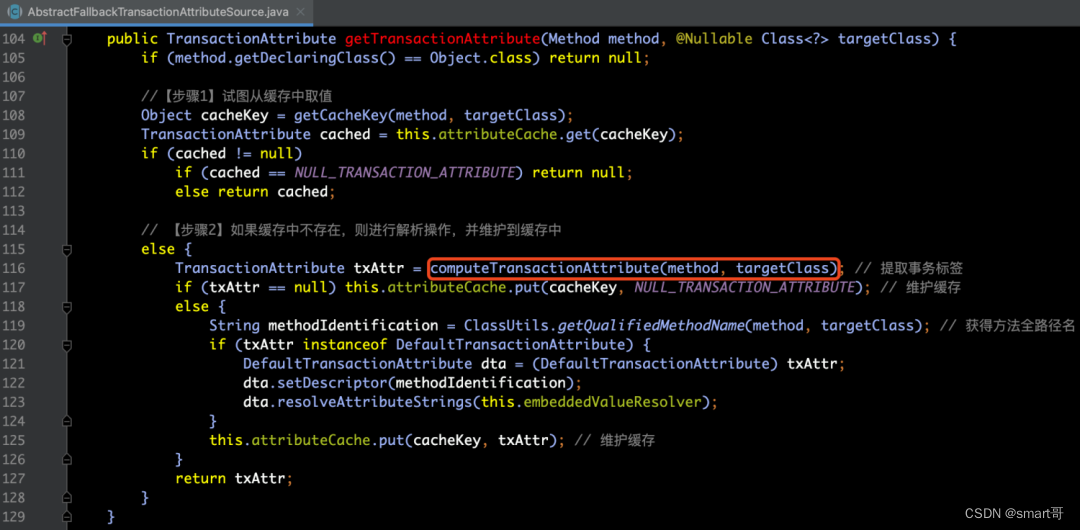
在上面的分析中,我们已经知道了如果缓存中没有缓存TransactionAttribute实例对象的话,则需要通过调用computeTransactionAttribute(method, targetClass)方法来获取,那么下面我们就来分析这个方法。在这个方法中,主要的逻辑如下所示:

【步骤1】查看specificMethod的
方法上是否存在声明式事务的注解,如果有则获取返回
【步骤2】查看specificMethod的类上是否存在声明式事务的注解,如果有则获取返回
【步骤3】查看method的方法上是否存在声明式事务的注解,如果有则获取返回
【步骤4】查看method的类上是否存在声明式事务的注解,如果有则获取返回
那么,在方法维度上查找就通过调用findTransactionAttribute(Method method)方法实现,在类的维度上查找就通过调用findTransactionAttribute(Class<?> clazz)来实现。请见下图所示:

但是无论入参是Method实例还是Class,最终调用的都是determineTransactionAttribute(AnnotatedElement element)方法,所以我们将视野聚焦到这个方法上。在这个方法中,就是用过事务注解解析器(TransactionAnnotationParser)调用parseTransactionAnnotation(AnnotatedElement element)方法来执行解析操作,请见如下红框所示:

那么,针对事务注解解析器TransactionAnnotationParser,Spring默认有3个实现类,分别是针对Spring、JTA和EJB的,具体实现类请见下图所示:

那么,同样他们分别针对的注解为 @TransactionAttriubte 和 @Transactional 进行解析,当发现类或者方法上存在这类事务注解时,则返回解析后的TransactionAttribute实例对象。此处我们以 SpringTransactionAnnotationParser 为例,看一下parseTransactionAnnotation(...)方法是如何处理的。在该方法中主要做的工作就是解析事务注解中的配置信息,然后存储到rbta实例对象中。
protected TransactionAttribute parseTransactionAnnotation(AnnotationAttributes attributes) {
RuleBasedTransactionAttribute rbta = new RuleBasedTransactionAttribute();
// 解析propagation属性并赋值
Propagation propagation = attributes.getEnum("propagation");
rbta.setPropagationBehavior(propagation.value());
// 解析isolation属性并赋值
Isolation isolation = attributes.getEnum("isolation");
rbta.setIsolationLevel(isolation.value());
// 解析timeout & timeoutString属性并赋值
rbta.setTimeout(attributes.getNumber("timeout").intValue());
String timeoutString = attributes.getString("timeoutString");
Assert.isTrue(!StringUtils.hasText(timeoutString) || rbta.getTimeout() < 0, "Specify 'timeout' or 'timeoutString', not both");
rbta.setTimeoutString(timeoutString);
// 解析readOnly & value & label属性并赋值
rbta.setReadOnly(attributes.getBoolean("readOnly"));
rbta.setQualifier(attributes.getString("value"));
rbta.setLabels(Arrays.asList(attributes.getStringArray("label")));
List<RollbackRuleAttribute> rollbackRules = new ArrayList<>();
for (Class<?> rbRule : attributes.getClassArray("rollbackFor"))
rollbackRules.add(new RollbackRuleAttribute(rbRule));
for (String rbRule : attributes.getStringArray("rollbackForClassName"))
rollbackRules.add(new RollbackRuleAttribute(rbRule));
for (Class<?> rbRule : attributes.getClassArray("noRollbackFor"))
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
for (String rbRule : attributes.getStringArray("noRollbackForClassName"))
rollbackRules.add(new NoRollbackRuleAttribute(rbRule));
// 解析rollbackFor & rollbackForClassName & noRollbackFor & noRollbackForClassName 属性并赋值
rbta.setRollbackRules(rollbackRules);
return rbta;
}介绍完findTransactionAttribute(...)方法后,我们再来补充介绍一下computeTransactionAttribute(method, targetClass)方法中使用的ClassUtils.isUserLevelMethod(method) 方法,该方法的作用是判断给定的方法method,是不是用户自己声明的或者指向用户声明的方法。代码如下所示:

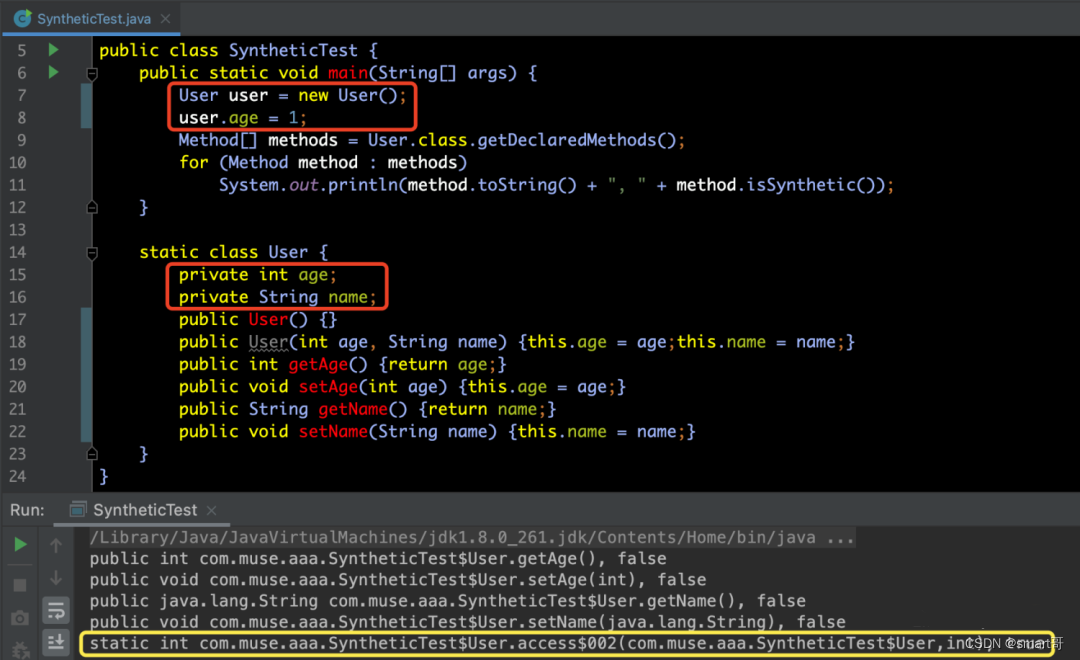
Method类中的isSynthetic()方法的作用是用于判断此方法是否是合成方法,如果是合成方法,则返回 true;否则返回 false。下面我们创建一个测试类SyntheticTest类,来看一下标准的User方法中,都是不是合成方法。从结果中我们可以看到4个方法的isSynthetic()都是false,即:都不是合成方法。请见如下代码所示:

那么,什么才是合成方法呢? 我们在main方法中添加两个操作,创建User以及为age赋值,因为age是私有private的,但是外部程序要去调用,所以编译器做了这个工作。而增加的这个方法是JVM动态增加的,并不属于User类本身,那么该方法就是合成方法(下图中黄框中的输出)。请见如下代码所示:
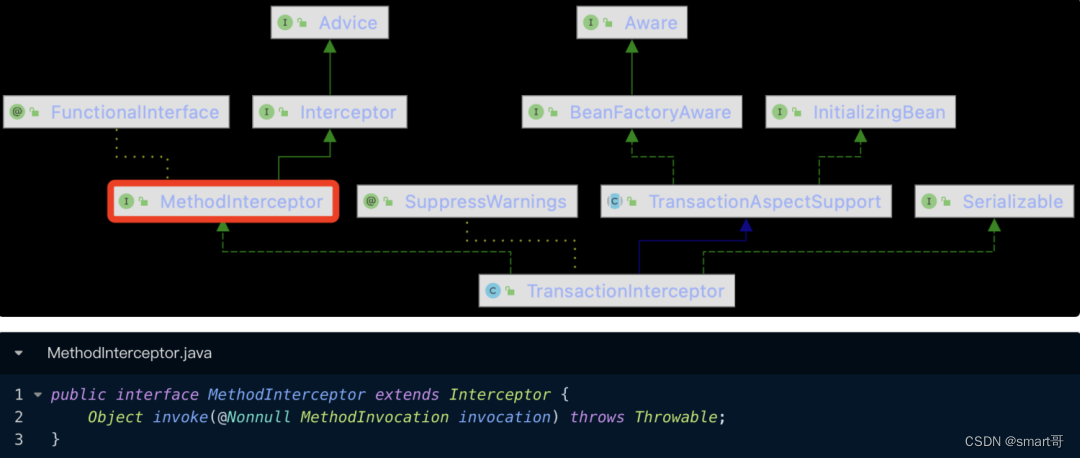
三、事务增强器
在AopAutoProxyConfigurer类的configureAutoProxyCreator(...)方法中,我们创建一个TransactionInterceptor类型的RootBeanDefinition。那么TransactionInterceptor其实支撑着整个事务功能的架构,这个章节,我们就来好好分析一下这个类,通过如下类图,我们可以发现,它实现了MethodInterceptor接口,而这个接口只有一个invoke(...)方法,那么我们就可以从该方法作为切入点,了解一下其具体的实现过程:
在TransactionInterceptor类的invoke(invocation)方法中,我们可以看到关键的处理方法是invokeWithinTransaction(...),其实也就是这个方法,包含了我们事务处理的最核心的处理流程:
public Object invoke(MethodInvocation invocation) throws Throwable {
Class<?> targetClass = (invocation.getThis() != null ?
AopUtils.getTargetClass(invocation.getThis()) : null);
return invokeWithinTransaction(invocation.getMethod(), targetClass, new CoroutinesInvocationCallback() {
public Object proceedWithInvocation() throws Throwable {
return invocation.proceed(); // 执行目标方法
}
public Object getTarget() {
return invocation.getThis(); // 获得目标对象
}
public Object[] getArguments() {
return invocation.getArguments(); // 获得目标方法入参
}
});
}在TransactionAspectSupport类的invokeWithinTransaction()方法中,代码量还是很大的,那么为了方便大家理解,我们在原有方法的基础上“隐藏”掉了并不常用的流程代码,只保留了声明式事务的处理代码,代码及注释如下所示:

对于声明式的事务处理主要有以下几个步骤:
【步骤1】获取事务的属性TransactionAttribute,对于事务处理来说,这是最基础的前置工作了,同时为后续的事务操作做好准备。
【步骤2】加载配置中配置的TransactionManager。
【步骤3】针对reactive进行特殊处理。
-------------对于声明式事务与编程式事务进行不同方式处理,此处只展示声明式事务的处理过程-------------
【步骤4】在目标方法执行前获取事务井收集事务信息TransactionInfo。
【步骤5】执行目标方法。
【步骤6】如果出现RuntimeException异常,则尝试事务回滚。
【步骤7】提交事务前,要清除事务信息TransactionInfo。
【步骤8】提交事务。
为了便于大家理解,我将上面的类和方法调用以图的方式进行展示,我们会针对步骤4、步骤6和步骤8这四个部分进行详细解析。请见如下所示:

3.1> createTransactionIfNecessary(...) 创建并收集事务信息
在介绍创建事务逻辑之前,我们先了解一下事务的传播机制,如下所示:

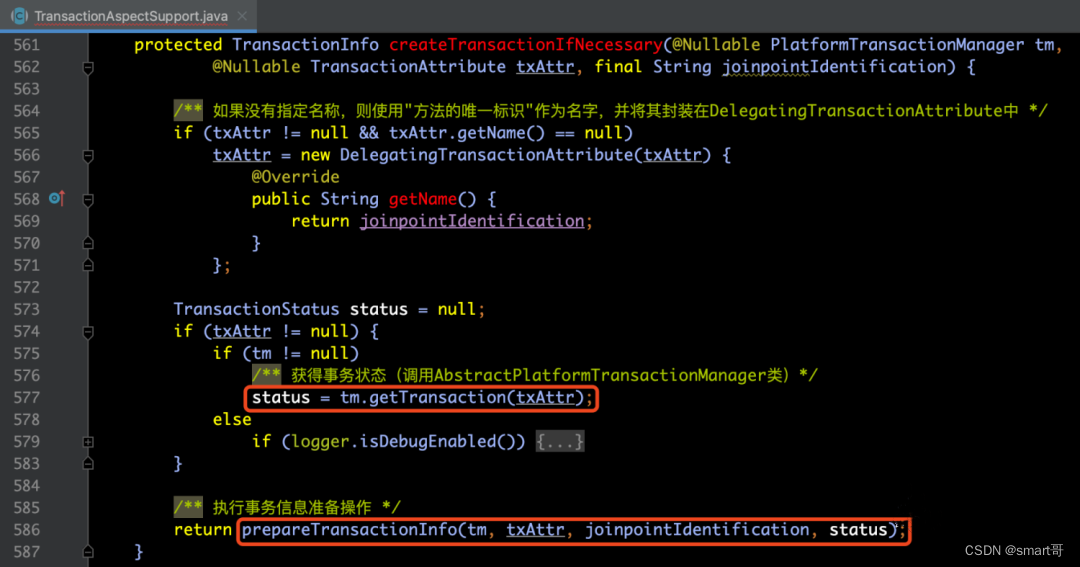
本小节要分析的内容就是上面中描述的【步骤4】在目标方法执行前获取事务井收集事务信息TransactionInfo,那么,让我们来看一下TransactionAspectSupport类的createTransactionIfNecessary(...)方法,在该方法中,主要做了3个步骤:
【步骤1】如果txAttr没有设置
name属性,则将方法的唯一标识(joinpointIdentification)赋值给name属性;
【步骤2】获得事务状态TransactionStatus;
【步骤3】执行事务信息准备操作;
其中,关键的两个步骤就是【步骤2】tm.getTransaction(txAttr)和【步骤3】prepareTransactionInfo(...)这两个方法,分别是用来获得事务状态以及执行事务信息的准备操作的,那么,下面我们就针对这两个方法做深入的解析。源码如下所示:
为了便于大家理解,我画出了createTransactionIfNecessary(...)方法的时序图,从该图中可以清晰的看到该方法的调用流程:

3.1.1> getTransaction(...) 获得事务状态
在getTransaction(...)方法中,主要的任务就是获得事务状态TransactionState,在处理过程中,主要分为如下几个步骤:
【步骤1】通过DataSourceTransactionManager的
doGetTransaction()方法来获得JDBC的事务实例;
【步骤2】如果当前线程已经存在事务,则进行嵌套事务处理。此处处理完毕之后,直接return返回,不继续向下执行;
【步骤3】对配置的事务超时时间进行验证,如果小于-1,则抛出异常;
【步骤4-1】如果配置的事务隔离级别是MANDATORY,则直接抛出异常(因为走到这个步骤,则说明步骤2不满足,当前线程无事务);
【步骤4-2】如果配置的事务隔离级别是REQUIRED、REQUIRES_NEW、NESTED,则执行startTransaction(...)开启新的事务;
【步骤4-3】如果配置的事务隔离级别是其他,则执行prepareTransactionStatus(...)方法创建事务状态并且初始化事务同步;
相关代码及注释如下所示:

a> doGetTransaction 获得数据库事务实例
在doGetTransaction)()方法中,主要就是创建DataSourceTransactionObject实例对象,然后并对其进行赋值。其中,通过obtainDataSource()方法获得JDBC的数据库数据源DataSource,然后将其传入到getResource()方法中,试图获取conHolder,一般来说我们获取的conHolder是为null的。这个方法逻辑比较简单,代码和注释如下所示:
protected Object doGetTransaction() {
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
/** 返回是否允许嵌套事务,默认为false */
txObject.setSavepointAllowed(isNestedTransactionAllowed());
/** 获得数据源DataSource,并由此试图获取ConnectionHolder实例对象 */
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(obtainDataSource());
txObject.setConnectionHolder(conHolder, false);
return txObject;
}我们可以从事务同步管理器中看到,因为事务与当前线程息息相关,所以事务相关的重要属性都被保存到了ThreadLocal中去了,

为了后续使用事务同步管理器(TransactionSynchronizationManager)而做准备,即:初始化事务所需参数,包括:是否活跃、隔离级别、是否只读、名称、激活事务同步。代码如下所示:
/** 根据给定的参数创建一个新的事务状态实例对象(TransactionStatus),与此同时,针对事务同步器进行初始化 */
protected final DefaultTransactionStatus prepareTransactionStatus(TransactionDefinition definition,
@Nullable Object transaction,
boolean newTransaction,
boolean newSynchronization,
boolean debug,
@Nullable Object suspendedResources) {
// 创建默认事务状态(DefaultTransactionStatus)实例对象
DefaultTransactionStatus status = newTransactionStatus(definition, transaction, newTransaction,
newSynchronization, debug, suspendedResources);
// 为了后续使用事务同步管理器(TransactionSynchronizationManager)而做准备
prepareSynchronization(status, definition);
return status;
}
/** 为了后续使用事务同步管理器(TransactionSynchronizationManager)而做准备,即:初始化所需参数 */
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
// 如果打开了新的事务同步
if (status.isNewSynchronization()) {
Integer level = definition.getIsolationLevel() != ISOLATION_DEFAULT ? definition.getIsolationLevel() : null;
// 配置当前事务是否是【活跃的】
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
// 配置当前事务的【隔离级别】
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(level);
// 配置当前事务是否是【只读的】
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
// 配置当前事务的【名称】
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
// 激活并初始化【事务同步】
TransactionSynchronizationManager.initSynchronization();
}
}b> handleExistingTransaction(...) 针对已存在事务进行处理
当发现当前线程中已经存在事务,那么则会执行handleExistingTransaction(...)方法,在该方法内部,主要是针对如下4种事务的传播机制进行处理:
【NEVER】无事务执行,如果当前有事务则抛出异常;
【NOT_SUPPORTED】无事务执行,如果当前事务存在,把当前事务挂起;
【REQUIRES_NEW】新建一个新事务;如果当前事务存在,把当前事务挂起;
【NESTED】嵌套事务,如果当前事务存在,那么在嵌套的事务中执行。如果当前事务不存在,则表现跟REQUIRED一样;
那么在该方法中,主要有3处重要的代码逻辑,suspend(...)用于对当前事务进行挂起操作;startTransaction(...)用于开启新的事务;这两个方法的解析,我们会在单独拉出来c和d两个部分来着重介绍。那么,还有一个方法是prepareTransactionStatus(...),该方法我们稍后就先来介绍一下。如下是handleExistingTransaction(...)方法的源码及注释:

在prepareTransactionStatus(...)方法中,主要做了两件事:其一,创建事务状态实例对象(TransactionStatus)。其二,为了后续使用事务同步管理器(TransactionSynchronizationManager)而做准备,即:为TransactionSynchronizationManager初始化所需参数。
protected final DefaultTransactionStatus prepareTransactionStatus(TransactionDefinition definition,
@Nullable Object transaction,
boolean newTransaction,
boolean newSynchronization,
boolean debug,
@Nullable Object suspendedResources) {
// 创建默认事务状态(DefaultTransactionStatus)实例对象
DefaultTransactionStatus status = newTransactionStatus(definition, transaction, newTransaction,
newSynchronization, debug, suspendedResources);
/** 为了后续使用事务同步管理器(TransactionSynchronizationManager)而做准备 */
prepareSynchronization(status, definition);
return status;
}
/**
* 为了后续使用事务同步管理器(TransactionSynchronizationManager)而做准备,即:初始化所需参数
*/
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
// 如果打开了新的事务同步
if (status.isNewSynchronization()) {
Integer level = definition.getIsolationLevel() != ISOLATION_DEFAULT ?
definition.getIsolationLevel() : null;
// 配置当前事务是否是【活跃】的
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
// 配置当前事务的【隔离级别】
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(level);
// 配置当前事务是否是【只读】的
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
// 配置当前事务的【名称】
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
// 激活并初始化【事务同步】
TransactionSynchronizationManager.initSynchronization();
}
}c> suspend() 挂起事务
suspend()的主要任务是:挂起给定的事务。首先暂停事务同步,然后委托给doSuspend(transaction)模板方法。其方法内部,主要执行如下3个模块逻辑:
【逻辑1】如果当前线程的事务同步处于活跃状态,则将所有的事务同步都停用,并且试图挂起给定的事务。然后,创建
SuspendedResourcesHolder对象,将事务名称、只读状态、隔离级别和活跃状态缓存进去。
【逻辑2】当前线程的事务同步处于非活跃状态并且入参事务不为空,则挂起给定的事务;
【逻辑3】否则,返回null;
protected final SuspendedResourcesHolder suspend(@Nullable Object transaction) throws TransactionException {
/** 当前线程的事务同步处于活动状态 */
if (TransactionSynchronizationManager.isSynchronizationActive()) {
// 将所有的事务同步都停用掉
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null)
suspendedResources = doSuspend(transaction); // 挂起给定的事务 DataSourceTransactionManager
// 获得当前事务名称(name),并将当前事务名称设置为null
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
// 获得当前事务的只读状态(readOnly),并将当前事务的只读状态设置为false
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
// 获得当前事务的隔离级别(isolationLevel),并将当前事务的隔离级别设置为null
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
// 获得当前事务活跃状态(wasActive),并将当前事务的活跃状态设置为false
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
// 将以上获取到的事务信息暂存到SuspendedResourcesHolder实例对象中
return new SuspendedResourcesHolder(suspendedResources, suspendedSynchronizations, name,
readOnly, isolationLevel, wasActive);
}
catch (RuntimeException | Error ex) {
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
}
/** 当前线程的事务同步处于非活动状态 并且 事务不为空 */
else if (transaction != null) {
Object suspendedResources = doSuspend(transaction); // 挂起给定的事务 DataSourceTransactionManager
return new SuspendedResourcesHolder(suspendedResources);
}
/** 当前线程的事务同步处于非活动状态 并且 事务为空 */
else return null;
}
/** 暂停当前线程的所有同步并停用事务同步 */
private List<TransactionSynchronization> doSuspendSynchronization() {
// 获得所有的事务同步器
List<TransactionSynchronization> suspendedSynchronizations = TransactionSynchronizationManager.
getSynchronizations();
for (TransactionSynchronization synchronization : suspendedSynchronizations)
synchronization.suspend(); // 执行挂起操作
TransactionSynchronizationManager.clearSynchronization(); // 清除时间同步器
return suspendedSynchronizations;
}通过getSynchronizations()方法来获得事务同步(TransactionSynchronization)集合,通过下面源码大家可以看到,这些信息都是保存在synchronizations中的:
public static List<TransactionSynchronization> getSynchronizations() throws IllegalStateException {
Set<TransactionSynchronization> synchs = synchronizations.get(); // 从synchronizations中获得事务同步集合
if (synchs == null) throw new IllegalStateException("Transaction synchronization is not active");
if (synchs.isEmpty()) return Collections.emptyList();
else {
List<TransactionSynchronization> sortedSynchs = new ArrayList<>(synchs);
OrderComparator.sort(sortedSynchs);
return Collections.unmodifiableList(sortedSynchs);
}
}d> startTransaction(...) 开启新事物
该方法的作用是在当前的线程上开启一个新的事务,方面里面除了创建一个DefaultTransactionStatus实例对象后,关键的两个方法就是doBegin(...)和prepareSynchronization(...),而prepareSynchronization方法我们刚刚已经在上面讲解suspend(...)挂起事务的时候讲解过了,那么我们此处只需要讲解doBegin(...)方法即可:
private TransactionStatus startTransaction(TransactionDefinition definition, Object transaction,
boolean debugEnabled, @Nullable SuspendedResourcesHolder suspendedResources) {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
// 创建DefaultTransactionStatus实例对象
DefaultTransactionStatus status = newTransactionStatus(definition, transaction, true, newSynchronization,
debugEnabled, suspendedResources);
/** 构造transaction,包括设置ConnectionHolder、隔离级别、timeout如果是新连接,绑定到当前线程 */
doBegin(transaction, definition); // eg: DataSourceTransactionManager
/** 新同步事务的设置,针对于当前线程的设置(这个方法在c部分解析过) */
prepareSynchronization(status, definition);
return status;
}在doBegin(...)方法中,首先从数据库中获得了数据库链接Connection,然后设置隔离级别和是否只读,然后关闭了自动提交配置,交由Spring框架来控制事务提交。最后,将当前获取到的连接绑定到当前线程即可。源码及注释如下所示:

3.2> completeTransactionAfterThrowing(...) 回滚处理
当事务中执行的逻辑出现异常的时候,就会在catch语句中执行completeTransactionAfterThrowing(...)方法,有一点需要注意的是,在该方法中并不是一定会执行回滚的,如果不满足某些条件,只会触发提交操作。代码如下所示:

那么哪些条件满足才能触发回滚操作呢?必须同时满足两个条件:
【条件1】txInfo.transactionAttribute 不为
null;
【条件2】txInfo.transactionAttribute.rollbackOn(ex) 等于true;
其中,条件2的rollbackOn(ex)方法默认是在DefaultTransactionAttribute类中实现的,只有满足异常是RuntimeException或者Error的异常实现类,才会执行事务回滚,代码如下所示:
public boolean rollbackOn(Throwable ex) {
return (ex instanceof RuntimeException || ex instanceof Error);
}由于现在我们介绍的是回滚流程,所以我们假设是符合上面回滚触发条件的,那么会执行txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus())这条语句,那么我们就将视野聚焦到AbstractPlatformTransactionManager类的rollback方法上。这个方法代码很少,也没什么逻辑,内部就是调用了processRollback(defStatus, false)来执行回滚操作,源码如下所示:

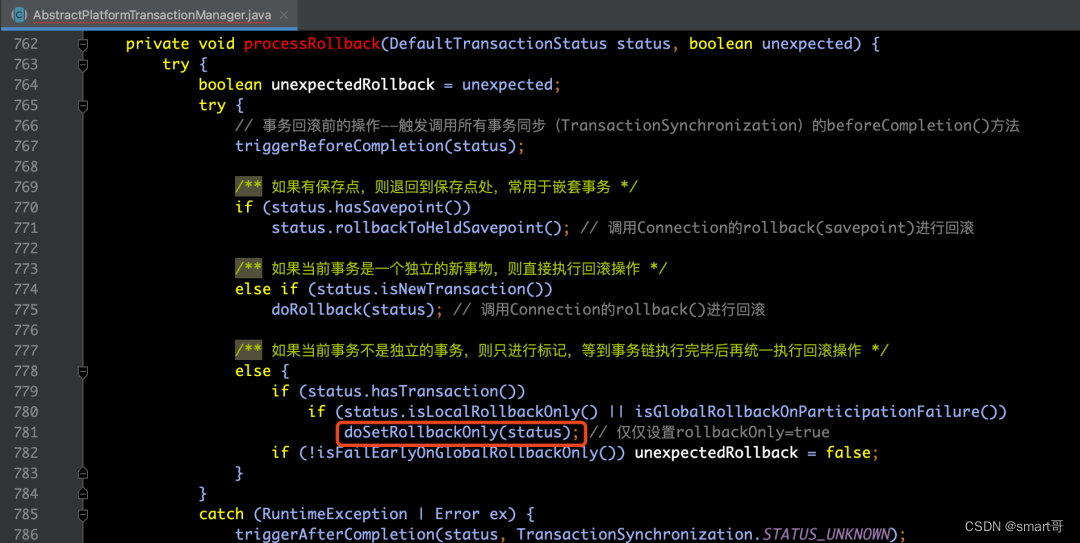
那么在processRollback(...)方法中,才是真正负责执行回滚操作的地方,在这个方法的前后,分别有负责触发回滚操作的前置操作(triggerBeforeCompletion)和后置操作(triggerAfterCompletion),本质上就是调用所有事务同步TransactionSynchronization实现类的beforeCompletion()和beforeCompletion()两个方法。
除了调用事务同步的方法之外,我们可以看到有3个判断,执行如下逻辑:
【判断1】如果有保存点(
savepoint),则退回到保存点处,常用于嵌套事务。
【判断2】如果当前事务是一个独立的新事物,则直接执行回滚操作。
【判断3】如果当前事务不是独立的事务,则只进行标记,等到事务链执行完毕后再统一执行回滚操作。
最后,不要忘记,在finally中我们还会执行一些“收尾”工作,即:清空记录的资源并对挂起的资源进行恢复。processRollback方法的源码和注释请见如下所示:

3.2.1> rollbackToHeldSavepoint() 回滚及释放保存点
如果savepoint存在的话,那么可以通过调用rollbackToHeldSavepoint()方法来实现回滚到为事务保存的保存点,然后立即释放保存点操作,如下的红框就是这两个操作所涉及的代码部分,请见下图所示:

由于我们是使用JDBC方式进行数据库连接的,所以上面的getSavepointManager()返回的就是JdbcTransactionObjectSupport实例对象,如下就是该类中针对“回滚到保存点”和“释放保存点”的详细处理代码,从源码中可以看到,这两个操作最终还是需要借由Connection类的rollback(savepoint)和releaseSavepoint(savepoint)来实现回滚到保存点和释放保存点操作的。相关源码如下所示:
/** 回滚到保存点 */
public void rollbackToSavepoint(Object savepoint) throws TransactionException {
ConnectionHolder conHolder = getConnectionHolderForSavepoint();
try {
// 调用Connection的rollback(savepoint)方法执行回滚
conHolder.getConnection().rollback((Savepoint) savepoint);
// 将rollbackOnly设置为false
conHolder.resetRollbackOnly();
}
catch (Throwable ex) {throw new TransactionSystemException(...);}
}
/** 释放保存点 */
public void releaseSavepoint(Object savepoint) throws TransactionException {
ConnectionHolder conHolder = getConnectionHolderForSavepoint();
try {
// 调用Connection的releaseSavepoint(savepoint)方法释放保存点
conHolder.getConnection().releaseSavepoint((Savepoint) savepoint);
}
catch (Throwable ex) {logger.debug(...);}
}3.2.2> doRollback(status) 回滚操作
在第二个if判断中,我们会执行回滚操作,此处调用的是DataSourceTransactionManager类的doRollback(...)方法,该方法非常简单,核心就是通过调用Connection的rollback()方法进行的回滚操作,代码如下所示:
protected void doRollback(DefaultTransactionStatus status) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
Connection con = txObject.getConnectionHolder().getConnection();
try {
con.rollback(); // 回滚操作
}
catch (SQLException ex) {throw translateException("JDBC rollback", ex);}
}3.2.3> cleanupAfterCompletion(status) 清空记录的资源并对挂起的资源进行恢复
当通过processRollback方法执行完回滚操作后,无论成功与否,都会执行finally中的cleanupAfterCompletion(status)方法,可以通过这个方法来执行一些“收尾”的工作,代码如下所示:

首先,判断如果当前事务是新的同步状态(status.isNewSynchronization()),需要调用clear() 方法将绑定到当前线程的事务信息清除,该方法很简单,就是执行ThreadLocal实例对象的remove()方法,代码如下所示:
public static void clear() {
synchronizations.remove();
currentTransactionName.remove();
currentTransactionReadOnly.remove();
currentTransactionIsolationLevel.remove();
actualTransactionActive.remove();
}其次,判断如果是新事务(status.isNewTransaction()),则需要调用doCleanupAfterCompletion(...) 方法来做些清除资源的工作,该方法的逻辑比较容易理解,我们直接来看源码和注释即可,请见下面所示:
protected void doCleanupAfterCompletion(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// 将数据库连接从当前线程中解除绑定
if (txObject.isNewConnectionHolder())
TransactionSynchronizationManager.unbindResource(obtainDataSource());
// 重置链接
Connection con = txObject.getConnectionHolder().getConnection();
try {
if (txObject.isMustRestoreAutoCommit()) con.setAutoCommit(true); // 恢复自动提交
// 重置数据库链接
DataSourceUtils.resetConnectionAfterTransaction(con, txObject.getPreviousIsolationLevel(), txObject.isReadOnly());
}
catch (Throwable ex) {logger.debug("Could not reset JDBC Connection after transaction", ex);}
// 如果当前事务是独立的新创建的事务,则在事务完成时释放数据库连接
if (txObject.isNewConnectionHolder())
DataSourceUtils.releaseConnection(con, this.dataSource);
txObject.getConnectionHolder().clear();
}最后,判断如果在事务执行前有事务挂起(status.getSuspendedResources() != null),那么通过调用resume(...) 方法,将当前事务执行结束后需要将挂起事务恢复,该方法的逻辑同样比较容易理解,我们直接来看源码和注释即可,请见下面所示:
/**
* 恢复给定的事务。首先委托给doResume模板方法,然后恢复事务同步。
*/
protected final void resume(Object transaction, SuspendedResourcesHolder resourcesHolder) throws TransactionException {
if (resourcesHolder != null) {
Object suspendedResources = resourcesHolder.suspendedResources;
if (suspendedResources != null)
doResume(transaction, suspendedResources); // 模版方法,具体行为下沉到子类去实现
List<TransactionSynchronization> suspendedSynchronizations = resourcesHolder.suspendedSynchronizations;
if (suspendedSynchronizations != null) {
TransactionSynchronizationManager.setActualTransactionActive(resourcesHolder.wasActive);
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(resourcesHolder.isolationLevel);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(resourcesHolder.readOnly);
TransactionSynchronizationManager.setCurrentTransactionName(resourcesHolder.name);
doResumeSynchronization(suspendedSynchronizations);
}
}
}3.3> commitTransactionAfterReturning(...) 事务提交
最后一部分,我们来了解一下事务提交逻辑,该部分是由commitTransactionAfterReturning(...)方法负责实现的,代码如下所示:
protected void commitTransactionAfterReturning(@Nullable TransactionInfo txInfo) {
if (txInfo != null && txInfo.getTransactionStatus() != null)
// 执行事务提交操作 AbstractPlatformTransactionManager
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}在commit方法的源码中,我们可以看到,并不仅仅执行了提交方法,而是如果满足一些条件,还会执行回滚操作,回滚操作由processRollback(...)方法负责处理,由于该方法的源码解析已经在3.2章节中介绍过了,那么此处就不赘述了。所以,从中我们可以看出,即使一个事务没有出现运行时异常,但是也不意味着事务一定会被提交。

还记得在3.2章节中,我们介绍过,如果某个事务是另一个事务的嵌入事务,但是,这些事务又不在Spring的管理范围内,或者无法设置保存点,那么Spring会通过设置回滚标识的方式来禁止提交(如下图所示)。首先当某个嵌入事务发生回滚的时候会设置回滚标识,而等到外部事务提交时, 一旦判断出当前事务被设置了回滚标识,则由外部事务来统一进行整体事务的回滚。所以,当事务没有被异常捕获的时候也并不意味着一定会执行提交的过程。
现在我们回过来,在继续分析事务提交的相关代码processCommit(...),分析该方法源码可知,在提交过程中也并不是直接提交的,如果如何如下任意两种情况,则无法执行提交操作:
【情况1】当事务状态中有保存点信息(
status.hasSavepoint()),则不会执行事务提交操作。
【情况2】当事务非新事务的时候,也不会去执行事务提交操作。
以上的这两个条件主要考虑的是内嵌事务的情况;对于内嵌事务,会在内嵌事务开始之前设置保存点,如果内嵌事务出现了异常,便会根据保存点信息进行回滚操作,但是,如果没有出现异常,内嵌事务也不会单独提交,而是根据事务流由最外层事务负责提交,所以如果当前存在保存点信息,那就说明本事务不是最外层事务,从而不用去执行保存操作,对于是否是新事务的判断也是基于此考虑。如果程序流通过了事务的层层把关,最后顺利地进入了提交流程,那么就可以通过Connection的commit()方法执行事务提交了。processCommit方法的代码及注释如下所示:
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
boolean unexpectedRollback = false;
prepareForCommit(status); // 空方法,无逻辑
triggerBeforeCommit(status); // 触发所有TransactionSynchronization实例对象的beforeCommit方法
triggerBeforeCompletion(status); // 触发所有TransactionSynchronization实例对象的beforeCompletion方法
beforeCompletionInvoked = true;
/** 如果有保存点savepoint */
if (status.hasSavepoint()) {
unexpectedRollback = status.isGlobalRollbackOnly();
status.releaseHeldSavepoint(); // 消除掉保存点信息
}
/** 如果是新的事务 */
else if (status.isNewTransaction()) {
unexpectedRollback = status.isGlobalRollbackOnly();
doCommit(status); // 如果是独立的事务则直接提交
}
/** 如果事务被全局标记为仅回滚,则返回是否尽早失败 */
else if (isFailEarlyOnGlobalRollbackOnly()) unexpectedRollback = status.isGlobalRollbackOnly();
if (unexpectedRollback) throw new UnexpectedRollbackException(...);
}
catch (UnexpectedRollbackException ex) {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
throw ex;
}
catch (TransactionException ex) {
if (isRollbackOnCommitFailure()) doRollbackOnCommitException(status, ex);
else triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
throw ex;
}
catch (RuntimeException | Error ex) {
if (!beforeCompletionInvoked) triggerBeforeCompletion(status);
doRollbackOnCommitException(status, ex); // 事务提交出现了异常,那么则执行回滚操作
throw ex;
}
try {
triggerAfterCommit(status);
}
finally {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_COMMITTED);
}
}
finally {
cleanupAfterCompletion(status);
}
}为了便于大家理解,此处将processCommit中的部分“相似方法”提取出来作个统一的说明:
triggerBeforeCommit(status):触发调用所有TransactionSynchronization实例对象的
beforeCommit方法
triggerBeforeCompletion(status):触发调用所有TransactionSynchronization实例对象的beforeCompletion方法
triggerAfterCommit(status):触发调用所有TransactionSynchronization实例对象的afterCommit方法
triggerAfterCompletion(status, completionStatus):触发调用所有TransactionSynchronization实例对象的afterCompletion方法
cleanupAfterCompletion(status) :在3.2.3章节介绍了,此处略;
doCommit方法是负责事务提交工作的,该方法逻辑非常简单,就是通过Connection的commit()方法执行事务提交即可:
protected void doCommit(DefaultTransactionStatus status) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();
Connection con = txObject.getConnectionHolder().getConnection();
try {
con.commit(); // 提交事务
}
catch (SQLException ex) {throw translateException("JDBC commit", ex);}
}当提交发生了异常的时候,我们会通过doRollbackOnCommitException方法来实现回滚操作,如果是新的事务,则执行回滚操作;如果是嵌套事务,并且是失败的,则进行回滚标记(设置rollbackOnly=true)。该方法的源码及注释如下所示:
private void doRollbackOnCommitException(DefaultTransactionStatus status, Throwable ex) throws TransactionException {
try {
if (status.isNewTransaction())
doRollback(status); // 调用Connection的rollback()方法
else if (status.hasTransaction() && isGlobalRollbackOnParticipationFailure())
doSetRollbackOnly(status); // 设置rollbackOnly=true
}
catch (RuntimeException | Error rbex) {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_UNKNOWN);
throw rbex;
}
triggerAfterCompletion(status, TransactionSynchronization.STATUS_ROLLED_BACK);
}今天的文章内容就这些了:
写作不易,笔者几个小时甚至数天完成的一篇文章,只愿换来您几秒钟的 点赞 & 分享 。