1 Spark3.0 AQE
Spark 在 3.0 版本推出了 AQE(Adaptive Query Execution),即自适应查询执行。AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
1.1 动态合并分区
在Spark中运行查询处理非常大的数据时,shuffle通常会对查询性能产生非常重要的影响。shuffle是非常昂贵的操作,因为它需要进行网络传输移动数据,以便下游进行计算。
最好的分区取决于数据,但是每个查询的阶段之间的数据大小可能相差很大,这使得该数字难以调整:
(1)如果分区太少,则每个分区的数据量可能会很大,处理这些数据量非常大的分区,可能需要将数据溢写到磁盘(例如,排序和聚合),降低了查询。
(2)如果分区太多,则每个分区的数据量大小可能很小,读取大量小的网络数据块,这也会导致I/O效率低而降低了查询速度。拥有大量的task(一个分区一个task)也会给Spark任务计划程序带来更多负担。
为了解决这个问题,我们可以在任务开始时先设置较多的shuffle分区个数,然后在运行时通过查看shuffle文件统计信息将相邻的小分区合并成更大的分区。
例如,假设正在运行select max(i) from tbl group by j。输入tbl很小,在分组前只有2个分区。那么任务刚初始化时,我们将分区数设置为5,如果没有AQE,Spark将启动五个任务来进行最终聚合,但是其中会有三个非常小的分区,为每个分区启动单独的任务这样就很浪费。

取而代之的是,AQE将这三个小分区合并为一个,因此最终聚只需三个task而不是五个

spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AQEPartitionTunning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
结合动态申请资源:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 2g --class com.atguigu.sparktuning.aqe.DynamicAllocationTunning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
1.2 动态切换Join策略
Spark支持多种join策略,其中如果join的一张表可以很好的插入内存,那么broadcast shah join通常性能最高。因此,spark join中,如果小表小于广播大小阀值(默认10mb),Spark将计划进行broadcast hash join。但是,很多事情都会使这种大小估计出错(例如,存在选择性很高的过滤器),或者join关系是一系列的运算符而不是简单的扫描表操作。
为了解决此问题,AQE现在根据最准确的join大小运行时重新计划join策略。从下图实例中可以看出,发现连接的右侧表比左侧表小的多,并且足够小可以进行广播,那么AQE会重新优化,将sort merge join转换成为broadcast hash join。
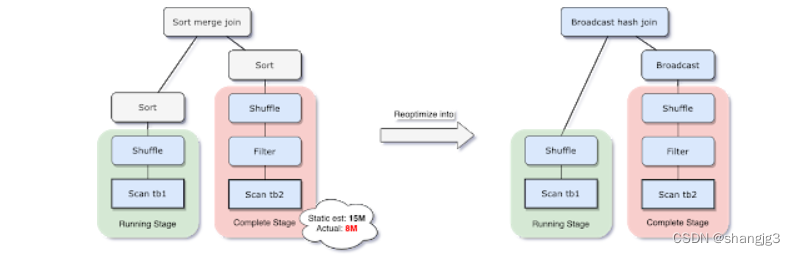
对于运行是的broadcast hash join,可以将shuffle优化成本地shuffle,优化掉stage 减少网络传输。Broadcast hash join可以规避shuffle阶段,相当于本地join。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeDynamicSwitchJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
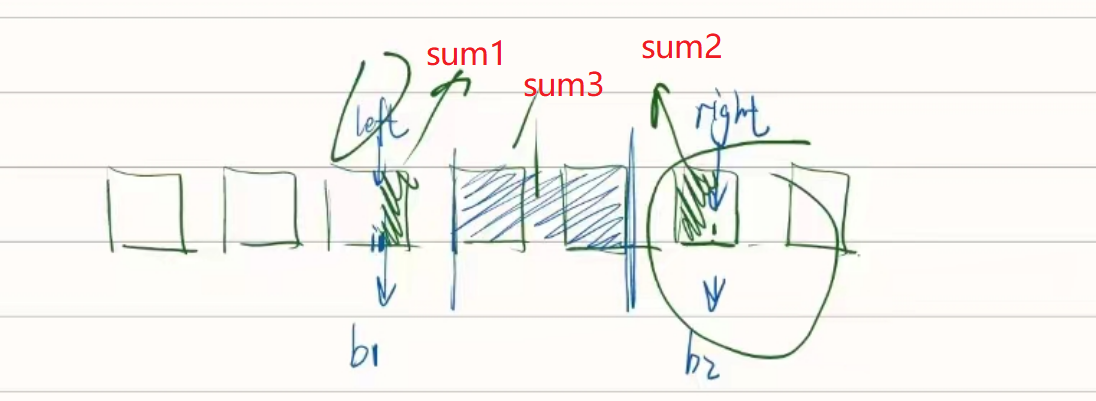
1.3 动态优化Join倾斜
当数据在群集中的分区之间分布不均匀时,就会发生数据倾斜。严重的倾斜会大大降低查询性能,尤其对于join。AQE skew join优化会从随机shuffle文件统计信息自动检测到这种倾斜。然后它将倾斜分区拆分成较小的子分区。
例如,下图 A join B,A表中分区A0明细大于其他分区

因此,skew join 会将A0分区拆分成两个子分区,并且对应连接B0分区

没有这种优化,会导致其中一个分区特别耗时拖慢整个stage,有了这个优化之后每个task耗时都会大致相同,从而总体上获得更好的性能。
可以采取第4章提到的解决方式,3.0有了AQE机制就可以交给Spark自行解决。Spark3.0增加了以下参数。
1)spark.sql.adaptive.skewJoin.enabled :是否开启倾斜join检测,如果开启了,那么会将倾斜的分区数据拆成多个分区,默认是开启的,但是得打开aqe。
2)spark.sql.adaptive.skewJoin.skewedPartitionFactor :默认值5,此参数用来判断分区数据量是否数据倾斜,当任务中最大数据量分区对应的数据量大于的分区中位数乘以此参数,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数,那么此任务是数据倾斜。
3)spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes :默认值256mb,用于判断是否数据倾斜
4)spark.sql.adaptive.advisoryPartitionSizeInBytes :此参数用来告诉spark进行拆分后推荐分区大小是多少。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeOptimizingSkewJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
如果同时开启了spark.sql.adaptive.coalescePartitions.enabled动态合并分区功能,那么会先合并分区,再去判断倾斜,将动态合并分区打开后,重新执行:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeOptimizingSkewJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
修改中位数的倍数为2,重新执行:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeOptimizingSkewJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
2 Spark3.0 DPP
Spark3.0支持动态分区裁剪Dynamic Partition Pruning,简称DPP,核心思路就是先将join一侧作为子查询计算出来,再将其所有分区用到join另一侧作为表过滤条件,从而实现对分区的动态修剪。如下图所示
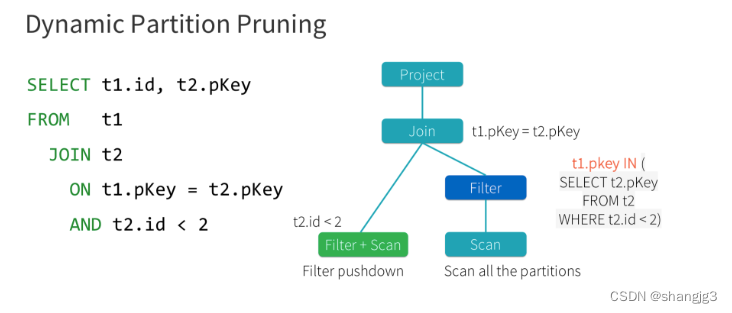
将select t1.id,t2.pkey from t1 join t2 on t1.pkey =t2.pkey and t2.id<2 优化成了select t1.id,t2.pkey from t1 join t2 on t1.pkey=t2.pkey and t1.pkey in(select t2.pkey from t2 where t2.id<2)
触发条件:
(1)待裁剪的表join的时候,join条件里必须有分区字段
(2)如果是需要修剪左表,那么join必须是inner join ,left semi join或right join,反之亦然。但如果是left out join,无论右边有没有这个分区,左边的值都存在,就不需要被裁剪
(3)另一张表需要存在至少一个过滤条件,比如a join b on a.key=b.key and a.id<2
参数spark.sql.optimizer.dynamicPartitionPruning.enabled 默认开启。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.dpp.DPPTest spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
3 Spark3.0 Hint增强
在spark2.4的时候就有了hint功能,不过只有broadcasthash join的hint,这次3.0又增加了sort merge join,shuffle_hash join,shuffle_replicate nested loop join。
Spark的5种Join策略:https://www.cnblogs.com/jmx-bigdata/p/14021183.html
3.1 broadcasthast join
sparkSession.sql("select /*+ BROADCAST(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ BROADCASTJOIN(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MAPJOIN(school) */ * from test_student student left join test_school school on student.id=school.id").show()
3.2 sort merge join
sparkSession.sql("select /*+ SHUFFLE_MERGE(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MERGEJOIN(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MERGE(school) */ * from test_student student left join test_school school on student.id=school.id").show()
3.3 shuffle_hash join
sparkSession.sql("select /*+ SHUFFLE_HASH(school) */ * from test_student student left join test_school school on student.id=school.id").show()
3.4 shuffle_replicate_nl join
使用条件非常苛刻,驱动表(school表)必须小,且很容易被spark执行成sort merge join。
sparkSession.sql("select /*+ SHUFFLE_REPLICATE_NL(school) */ * from test_student student inner join test_school school on student.id=school.id").show()
![[工业自动化-19]:西门子S7-15xxx编程 - 软件编程 - PLC程序块、组织块OB与PLC多线程原理、OB、FC、FB、DB](https://img-blog.csdnimg.cn/6af0e1ae7b2b4c1ba5e5b12d4d5e24bf.png)