文章目录
- 前言
- 什么是向量数据库?
- 向量数据库的机制
- 向量数据库的优点
- 查询向量数据库
- 什么是向量Embedding?
- Amazon OpenSearch Service
- 总结
前言
向量数据库擅长处理复杂的高维数据,正在彻底改变商业世界的数据检索和分析。它们执行相似性搜索的效率使其对于推荐系统、语义搜索、个性化营销等应用至关重要,为数据驱动的决策开辟了新的途径。
2023年8月1日,亚马逊云科技推出了Amazon OpenSearch Serverless向量引擎预览版,为用户提供了一种简单、可扩展且高性能的相似性搜索功能,使用户能够轻松地创建现代化机器学习(ML)增强的搜索体验和生成式AI应用程序,同时无需管理底层的向量数据库基础设施。
什么是向量数据库?
首先,我们首先了解向量数据库的概念。它们代表一种数据库管理系统 (DBMS),旨在有效地存储、管理和检索向量化数据。与处理标量值的传统数据库不同,向量数据库处理多维数据或向量。向量数据库在大规模机器学习应用中找到了自己的位置,特别是在推荐系统、语义搜索和异常检测等处理高维向量的领域。
向量数据库的机制
向量数据库的强大之处在于其独特的数据索引和查询技术。为了减少检索相似向量所需的时间,向量数据库不会迭代数据库中的每个向量。相反,它们使用特定的索引技术,例如 KD 树、分层可导航小世界图 (HNSW) 或倒排多索引 (IMI),以在查询期间显着减少搜索空间的方式组织向量。
在查询期间,这些数据库识别向量空间中可能存在相似向量的区域,并且仅在该区域内进行搜索。这种方法极大地减少了检索相似向量所需的计算时间,使向量数据库对于相似性搜索任务非常有效。
向量数据库的优点
向量数据库旨在在海量数据集中执行高速相似性搜索。它们在向量化数据方面表现出色,因为它们利用独特的数据索引和查询技术,可以显着减少搜索空间,加快检索过程。向量数据库可以高效地处理复杂的数据结构,使其成为高级机器学习应用程序的理想选择。
查询向量数据库
现在让我们深入研究查询向量数据库。尽管一开始看起来可能令人畏惧,但一旦掌握了窍门,它就会变得非常简单。查询向量数据库的主要方法是通过相似性搜索,使用欧几里德距离或余弦相似性。
以下是如何使用伪代码添加向量并执行相似性搜索的简单示例:
# 导入向量数据库库
import vector_database_library as vdb
# 初始化向量数据库
db = vdb.VectorDatabase(dimensions= 128 )
# 添加向量
for i in range ( 1000 ):
vector =generate_random_vector( 128 ) #generate_random_vector 是一个生成随机数的函数随机128维向量
db.add_vector(vector, label= f"vector_ {i} " )
# 进行相似度搜索
query_vector =generate_random_vector( 128 )
相似向量 = db.search(query_vector, top_k= 10 )
上面的代码中,db.add_vector(vector, label=f”vector_{i}”)方法用于向数据库中添加向量,db.search (query_vector, top_k=10)方法用于执行相似性搜索。
什么是向量Embedding?
向量Embedding,也称为向量表示或词Embedding,是高维向量空间中单词、短语或文档的数字表示。它们捕获单词之间的语义和句法关系,使机器能够更有效地理解和处理自然语言。

向量Embedding通常是使用机器学习技术(例如神经网络)生成的,该技术学习将单词或文本输入映射到密集向量。基本思想是将具有相似含义或上下文的单词表示为向量空间中靠近的向量。
生成向量Embedding的一种流行方法是Word2vec,它根据大型文本语料库中单词的分布属性来学习表示。它可以通过两种方式进行训练:连续词袋(CBOW)模型或skip-gram模型。CBOW 根据上下文单词预测目标单词,而skip-gram 在给定目标单词的情况下预测上下文单词。两种模型都学习将单词映射到对其语义关系进行编码的向量表示。
另一种广泛使用的技术是GloVe(词表示的全局向量),它利用共现统计来生成词Embedding。GloVe 根据语料库中单词一起出现的频率构建单词共现矩阵,然后应用矩阵分解来获得Embedding。
向量Embedding在自然语言处理 (NLP) 任务中具有多种应用,例如语言建模、机器翻译、情感分析和文档分类。
通过将单词表示为密集向量,模型可以对这些向量执行数学运算以捕获语义关系,例如单词类比(例如,“国王”-“男人”+“女人”≈“女王”)。向量Embedding使机器能够捕获单词的上下文含义并增强其处理和理解人类语言的能力。
Amazon OpenSearch Service
OpenSearch的 是一个可扩展、灵活且可扩展的开源软件套件,用于搜索、分析、安全监控和可观察性应用程序,并根据 Apache 2.0 许可证获得许可。 它包括一个搜索引擎 OpenSearch(提供低延迟搜索和聚合)、OpenSearch 仪表板(可视化和仪表板工具)以及一套插件,提供警报、细粒度访问控制、可观察性、安全监控等高级功能。矢量存储和处理。 亚马逊开放搜索服务 是一项完全托管的服务,可让您在 AWS 云中轻松部署、扩展和操作 OpenSearch。
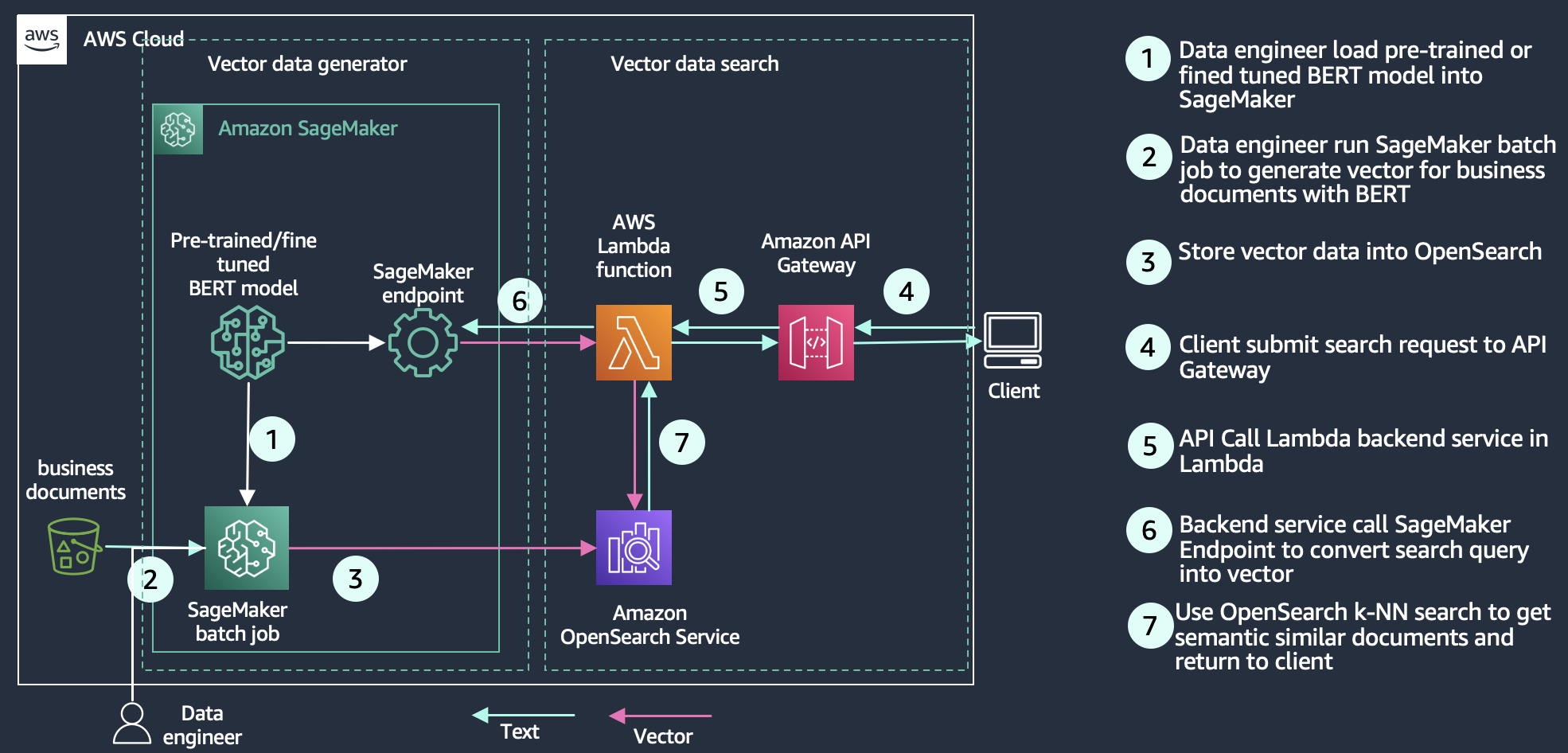
借助 OpenSearch Service 的矢量数据库功能,您可以实施语义搜索、使用 LLM 的检索增强生成 (RAG)、推荐引擎和搜索富媒体。
Amazon OpenSearch Serverless向量引擎有以下优势:
1、构建于 Amazon OpenSearch Serverless 的向量引擎天然具备鲁棒性。
2、Amazon OpenSearch Serverless 向量引擎由开源 OpenSearch 项目中的 k 近邻搜索功能提供支持,该功能能够提供可靠而精确的结果。
3、向量引擎支持不同领域的广泛用例,包括图像搜索、文档搜索、音乐检索、产品推荐、视频搜索、基于位置的搜索、欺诈检测以及异常检测。
总结
数据驱动决策的未来取决于我们从高维数据空间中导航和提取见解的能力。在这方面,向量数据库正在为数据检索和分析的新时代铺平道路。凭借对向量数据库的深入了解,数据工程师有能力应对管理高维数据带来的挑战和机遇,推动跨行业和应用程序的创新。
总的来说,亚马逊云科技的向量引擎具有强大的性能和可扩展性,可以满足各种应用程序的需求。如果您想要了解或使用向量数据库,亚马逊云科技最近还提供向量数据库的免费试用服务,值得一看。