目录
一、非类型模板参数
二、array容器
三、模板特化
为什么要对模板进行特化
函数模板特化
补充一个问题
类模板特化
全特化与偏特化
全特化
偏特化
四、模板为什么不能分离编译
为什么
怎么办
五、总结模板的优缺点
一、非类型模板参数
模板参数分两类:类型形参 与 非类型形参。
类型形参:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参:用一个常量作为类 (函数) 模板的一个参数,在类 (函数) 模板中可将该参数当成常量来使用。
为什么需要非类型模板参数呢?我们先来看这样一个场景。
我定义了一个静态栈MyStack:
#define N 100
template<class T>
class MyStack
{
private:
int arr[N];
int top;
};
int main() {
MyStack<int> st;
return 0;
}这样实例化出的栈,大小都是100。那假如我想要两个栈,一个大小为100,一个为200,要怎么办呢?
这就是#define所解决不了的问题了。
为此,我们引入了非类型模板参数,来看看它是怎么处理这个问题的:
template<class T,int N> //非类型模板参数N
class MyStack
{
private:
int arr[N];
int top;
};
int main() {
MyStack<int, 100> st1;
MyStack<int, 200> st2;
return 0;
}这样实例化出的st1,大小为100;st2,大小为200。
注意:
1.整形家族可以作为非类型模板参数,包括char、short、int、long、longlong。最常见的是int。
浮点数、类对象以及字符串是不允许作为非类型模板参数的。
2.非类型的模板参数必须在编译期就能确认结果。
3.非类型模板参数是是常量,是不能修改的。
不信来修改下试试:
template<class T,int N> class MyStack { public: void func() { N = 200; //修改N } private: int arr[N]; int top; }; int main() { MyStack<int, 100> st1; st1.func(); return 0; }
二、array容器
学习了非类型模板参数,我们就可以了解下array容器。这个容器很少用,了解即可。
array,大小固定的数组。
相比之前学过的动态数组vector,array的功能就显得有些鸡肋:array有的功能,vector也有;而vector有的功能,array未必有。
一方面,vector是开在堆上的,大小可以变化;而array开在栈上,大小固定。但这也是array的优势,正因为是栈上分配内存,所以比vector的效率更高。
但总的来说,用array的地方,我们往往也能用vector,vector还更好用。所以这个容器很少用。
三、模板特化
模板特化的概念:
在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。
当模板被使用时,编译器会针对特定的类型使用特定的实现,而非使用通用的实现,从而提高代码的效率。
为什么要对模板进行特化
假如我们想要对9和2进行大小比较,现用两种方式比,然而,比较结果却出现了分歧:
template<class T>
bool IfLess(const T& x, const T& y) {
return x < y;
}
int main() {
int a = 2, b = 9;
int* pa = &a, * pb = &b;
cout << IfLess(a, b) << endl;
cout << IfLess(pa, pb) << endl;
return 0;
}
存进a、b变量里,得到的是正确的结果。而通过传指针的方式,得到的是错误的结果。
这是因为,这里直接比较了指针的大小,而无法对指针先解引用 再比较。
此时,就需要对模板进行特化。我们希望达到的效果是:传指针也能比大小。
模板特化中分为函数模板特化与类模板特化。
函数模板特化
函数模板的特化步骤:
1.必须要先有一个基础的函数模板
2.关键字template后面接一对空的尖括号<>
3.函数名后跟一对尖括号,尖括号中指定需要特化的类型
4.函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
如,这里就没有做到完全相同,所以报错了:
应改为:
template<class T> bool IfLess(T& x,T& y) { return x < y; } template<> bool IfLess<int*>(int*& x, int*& y) { //注意形参要和基础参数完全相同! return *x < *y; }

函数模板特化的示例:
#include<iostream>
using namespace std;
template<class T>
bool IfLess(T& x,T& y) {
return x < y;
}
template<>
bool IfLess<int*>(int*& x, int*& y) {
return *x < *y;
}
int main() {
int a = 2, b = 9;
int* pa = &a, * pb = &b;
cout << IfLess(a, b) << endl;
cout << IfLess(pa, pb) << endl;
return 0;
}
在调用时,函数会根据实参类型,调用对应的函数模板:

补充一个问题
思考:为什么这样写不对?
#include<iostream>
using namespace std;
template<class T>
bool IfLess(const T& x, const T& y) {
return x < y;
}
template<>
bool IfLess<int*>(const int*& x,const int*& y) { //明明基础参数类型完全一致,为啥报错?
return *x < *y;
}
int main() {
……
}编译不通过:
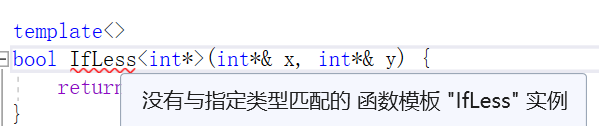
这里看似 和基础参数类型完全一致,实际上只是做到了形式上的一致,内涵上却大相径庭。
在基础函数参数中,const修饰形参x、y,保证它们不被改变;那迁移到 特化的参数中,对应的是:const修饰两个指针x、y,使之不被改变。
而const int*& x,const修饰的是指针x指向的内容不受改变,即const修饰 *x。
正确的写法是:int* const& x,让const直接修饰指针x。
📖如果你还是一头雾水,那说明“指针常量and常量指针”的知识点你没掌握好,现在我予以补充。
指针常量:int* const p。const直接修饰指针p,p自身的值不能改变,即p的指向是不能变的,而*p可以改变。
p就相当于一个常量了,此常量的类型为指针,因而叫指针常量。
常量指针:const int* p或int const* p,const修饰的是*p,即指针指向的内容是不能变的,而指针的指向可以改变。
因为指向的内容不能变,就相当于指向了一个常量,所以叫常量指针。
类模板特化
当我们需要针对某些特定类型进行特殊处理时,就需要对类模板进行特化。
如,我们定义了一个类模板 用于计算两个数的和:
#include <iostream>
using namespace std;
template<class T1,class T2>
class Adder
{
public:
T1 add(T1 x, T2 y) {
return x + y;
}
};
int main() {
Adder<int,double> a;
int ret1 = a.add(1, 1.1); //我想要ret1是整形,ret2是浮点型
double ret2 = a.add(1, 1.1);
cout << ret1 << endl;
cout << ret2 << endl;
return 0;
}我想要1+1.1的结果,一个取整为2,一个保留小数为2.1。然而,结果却:
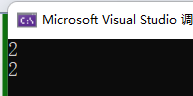
结果都是整形。因为返回类型T1是int,这会直接把2.1截断,返回2,存进ret2里。
来看看 当引入类模板特化,是怎么解决这个问题的吧:
#include <iostream>
using namespace std;
template<class T1,class T2>
class Adder
{
public:
T1 add(T1 x, T2 y) {
return x + y;
}
};
template<>
class Adder<int,double>
{
public:
double add(int x, double y) {
return x + y;
}
};
int main() {
Adder<int,double> a;
int ret1 = a.add(1, 1.1);
double ret2 = a.add(1, 1.1);
cout << ret1 << endl;
cout << ret2 << endl;
return 0;
}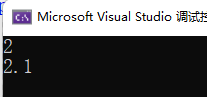
所以说,当需要针对特殊情况做特殊处理时,可以考虑使用类模板特化。
全特化与偏特化
全特化
将所有的模板参数都确定化。(我们刚刚给出的那几个例子,都是全特化的)
例:
template<class T1,class T2>
class Adder
{
public:
T1 add(T1 x, T2 y) {
return x + y;
}
};
template<>
class Adder<int,double>
{
public:
double add(int x, double y) {
return x + y;
}
};注意看,全特化时,template<>尖括号里一定是空的。在尖括号内不添加类型,表示完全特化。
(但不能凭<>是否为空,来区分是全or偏特化。偏特化的<>也可以为空)
偏特化
偏特化又叫半特化。下面这2种情况都属于偏特化:
1.将参数表中一部分参数进行特化。
例:
template<class T1,class T2>
class Adder
{
public:
T1 add(T1 x, T2 y) {
return x + y;
}
};
template<class T1> //只特化了T2,T1还得保留
class Adder<T1,double>
{
public:
double add(T1 x, double y) {
return x + y;
}
};2.对参数进行更进一步的限制。
例:如果我们想要 传参时,确保是引用传参,该怎么做呢?
template<class T1, class T2>
class Adder
{
public:
T1 add(T1 x, T2 y) {
cout << "调用了普通类模板" << endl;
return x + y;
}
};
template<class T1,class T2>
class Adder<T1& ,T2&> //限制两个参数是引用
{
public:
double add(const T1& x, const T2& y) {
cout << "调用了特化类模板" << endl;
return x + y;
}
};
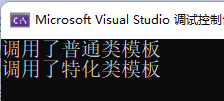
int main() {
Adder<int,double> a;
a.add(1, 1.1);
Adder<int&, double&> b; //调用特化的类模板,这样的话,就一定是传引用传参
b.add(1, 1.1);
return 0;
}
四、模板为什么不能分离编译
为什么
最开始接触模板时,就说过:模板不能分离编译。那为什么呢?我们要知其然,还要知其所以然。现在,我通过一个例子来说明这个原因。
我现在在一个project里创建了三个文件:Add.h、Add.cpp、main.cpp,分别用于声明、定义和测试。
//Add.h
#include<iostream>
using namespace std;
template<class T1,class T2>
T1 Add(T1 x,T2 y);
//Add.cpp
#include"Add.h"
template<class T1, class T2>
T1 Add(T1 x, T2 y) {
return x + y;
}
//main.cpp
#include"Add.h"
int main() {
cout << Add(1, 2.0) << endl;
return 0;
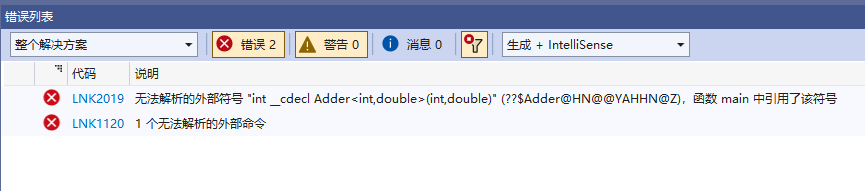
}运行报错:
原因说明:
我们先来回顾下,程序是怎么运行的。
程序在运行时,要经历四个阶段:预处理、编译、汇编、链接。
a.在预处理阶段,头文件被展开、宏被替换、注释被删除;
b.在编译阶段,编译器对各个源文件分别进行语法检查,然后将其转化成汇编代码。(注意:此阶段已经没有头文件了)
c.由于机器只能识别0、1串,所以我们的代码要经过汇编,从给人看的字符,变成给机器看的01。在汇编阶段,会形成符号表(用于存放变量、函数的地址)。
d.链接时,计算机遇到不认识的变量、函数,就会去符号表里找它的地址。通过链接,一个项目里的多个文件,才能合成一个关联的整体。
模板之所以不能分离编译,就是在链接阶段出岔子了。
我们说过,模板就像一张图纸。Add.cpp里的函数模板,因为没有确定的类型,所以并未实例化出具体的函数,自然无法在符号表中生成对应的地址。
在mian.cpp中,模板隐式实例化出 函数Add<int,double>,想要调用,却在符号表里找不到地址。所以报错:Add<int,double>为无法解析的外部符号。
怎么办
既然不能分离编译,那一般怎样处理模板呢?这里提供两种方法。
1.(推荐!)用到模板的地方,就不要分离编译~
将声明和定义放到同一个文件 "xxx.hpp" (或者"xxx.h")。
2.(不推荐)模板定义的位置显式实例化。
你要调用的函数,都显式实例化放在Add.cpp中:
template<class T1, class T2>
T1 Add(T1 x, T2 y) {
return x + y;
}
//显示实例化
template
int Add(int x, double y);这样写不好,因为如果你要调用好几种不同参数类型的Add,你就都要显式实例化,这就造成了代码的冗余。
五、总结模板的优缺点
优点:
1.模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
2.增强了代码的灵活性
缺点:
1.模板会导致代码膨胀问题,也会导致编译时间变长
2.出现模板编译错误时,错误信息非常凌乱,不易定位错误