目录
IGMP
多播路由选择协议
组播协议包括组成员管理协议和组播路由协议:
组成员管理协议用于管理组播组成员的加入和离开(IGMP)
组播路由协议负责在路由器之间交互信息来建立组播树(多播路由选择协议)
IGMP
图中标有 IP 地址的四台主机都参加了一个多播组,其组地址是 226.15.37.123。显然,多播数据报应当传送到路由器R1,R2和R3,而不应当传送到路由器R4,因为与R4连接的局域网上现在没有这个多播组的成员。但这些路由器又怎样知道多播组的成员信息呢?这就要利用网际组管理协议IGMP(Internet Group Management Protocol)。

注:本例强调了IGMP的本地使用范围。请注意,IGMP并非在互联网范围内对所有多播组成员进行管理的协议。IGMP 不知道 IP 多播组包含的成员数,也不知道这些成员都分布在哪些网络上。IGMP 协议是让连接在本地局域网上的多播路由器知道本局域网上是否有主机(严格讲,是主机上的某个进程)参加或退出了某个多播组。
对于IGMP,我们还需要注意:
和网际控制报文协议 ICMP相似,IGMP 使用 IP 数据报传递其报文(即IGMP报文加上IP首部构成 IP数据报),但它也向 IP 提供服务。因此,我们不把 IGMP 看成是一个。的协议,而是属于整个网际协议IP的一个组成部分。
IGMP的工作可分为两个阶段:
第一阶段:当某台主机加入新的多播组时,该主机应向多播组的多播地址发送一IGMP 报文,声明自己要成为该组的成员。本地的多播路由器收到IGMP 报文后,还要利用多播路由选择协议把这种组成员关系转发给互联网上的其他多播路由器。
第二阶段:组成员关系是动态的。本地多播路由器要周期性地探询本地局域网上的主机,以便知道这些主机是否还继续是组的成员。只要有一台主机对某个组响应,那么多播路由器就认为这个组是活跃的。但一个组在经过几次的探询后仍然没有一台主机响应,多播路由器就认为本网络上的主机已经都离开了这个组,因此也就不再把这个组的成员关系转发给其他的多播路由器。
IGMP 设计得很仔细,避免了多播控制信息给网络增加大量的开销。IGMP 采用的一些具体措施如下:
(1)在主机和多播路由器之间的所有通信都使用 IP 多播。只要有可能,携带 IGMP报文的数据报都用硬件多播来传送。因此在支持硬件多播的网络上,没有参加 IP多播的主机不会收到IGMP报文。
(2)多播路由器在探询组成员关系时,只需要对所有的组发送一个请求信息的询问报文,而不需要对每一个组发送一个询问报文(虽然也允许对一个特定组发送询问报文)。默认的询问速率是每 125秒发送一次 (通信量并不太大)。
(3)当同一个网络上连接有几个多播路由器时,它们能够迅速和有效地选择其中的一个来探询主机的成员关系。因此,网络上多个多播路由器并不会引起IGMP通信量的增大。
(4)在IGMP的询问报文中有一个数值N,它指明一个最长响应时间(默认值为 10秒)当收到询问时,主机在 0到 N 之间随机选择发送响应所需经过的时延。因此,若一台主机同时参加了几个多播组,则主机对每一个多播组选择不同的随机数。对应于最小时延的响应
数据报时扫器 R则把名是多播组及转发到中的目的地
最先发送。
(5)同一个组内的每一台主机都要监听响应,只要有本组的其他主机先发送了响应,自己就可以不再发送响应了。这样就抑制了不必要的通信量。
多播路由器并不需要保留组成员关系的准确记录,因为向局域网上的组成员转发数据报是使用硬件多播。多播路由器只需要知道网络上是否至少还有一台主机是本组成员即可。实际上,对询问报文每一个组只需有一台主机发送响应。
如果一台主机上有多个进程都加入了某个多播组,那么这台主机对发给这个多播组的每个多播数据报只接收一个副本,然后给主机中的每一个进程发送一个本地复制的副本。
最后我们还要强调指出,多播数据报的发送者和接收者都不知道(也无法找出)一个多播组的成员有多少,以及这些成员是哪些主机。互联网中的路由器和主机都不知道哪个应用进程将要向哪个多播组发送多播数据报,因为任何应用进程都可以在任何时候向任何一个多播组发送多播数据报,而这个应用进程并不需要加入这个多播组。
这篇对IGMPv1,IGMPv2,IGMPv3介绍得很详细:
http://t.csdnimg.cn/BUloD
多播路由选择协议
显然,仅有 IGMP协议是不能完成多播任务的。连接在局域网上的多播路由器还必须和互联网上的其他多播路由器协同工作,以便把多播数据报用最小代价传送给所有的组成员,这就需要使用多播路由选择协议。
然而多播路由选择协议要比单播路由选择协议复杂得多。我们可以通过一个简单的例子来说明。假定图中有两个多播组。多播组M1的成员有主机A,B和C,而多播组M2的成员有主机D,E和F。这些主机分布在三个网络上(N1,N2和N3)
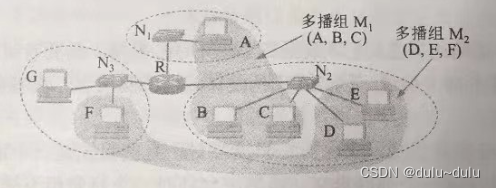
路由器 R 不应当向网络 N3转发多播组 M1 的分组,因为网络 N3上没有多播组 M1的成员。但是每一台主机可以随时加入或离开一个多播组。例如,如果主机 G 现在加入了多播组 M,那么从这时起,路由器 R 就必须也向网络 N3 转发多播组 M的分组。这就是说,多播转发必须动态地适应多播组成员的变化(这时网络拓扑并未发生变化)。请注意,单播路由选择通常在网络拓扑发生变化时才需要更新路由。
再看一种情况。主机E和F都是多播组 M2的成员。当E向F发送多播数据报时,路由器R把这个多播数据报转发到网络N3。但当F向E发送多播数据报时,路由器R则把多播数据报转发到网络 N2。如果路由器 R 收到来自主机 A 的多播数据报 (A 不是多播组 M2的成员,但也可向多播组发送多播数据报),那么路由器 R 就应当把多播数据报转发到 N2和N3。由此可见,多播路由器在转发多播数据报时,不能仅仅根据多播数据报中的目的地址,而是还要考虑这个多播数据报从什么地方来和要到什么地方去。
还有一种情况。主机 G 没有参加任何多播组,但 G 却可向任何多播组发送多播数据报。例如,G可向多播组 M1或M2发送多播数据报。主机G所在的局域网上可以没有任何多播组的成员。显然,多播数据报所经过的许多网络,也不一定非要有多播组成员。总之,多播数据报可以由没有加入多播组的主机发出,也可以通过没有组成员接入的网络。
对于多播路由选择协议,还需要注意:
虽然在TCP/IP 中IP 多播协议已成为建议标准,但多播路由选择协议(用来在多播路由器之间传播路由信息)则尚未标准化。
在多播过程中一个多播组中的成员是动态变化的。例如在收听网上某个广播节目时,随时会有主机加入或离开这个多播组。多播路由选择实际上就是要找出以源主机为根节点的多播转发树。在多播转发树上,每一个多播路由器向树的叶节点方向转发收到的多播数据报,但在多播转发树上的路由器不会收到重复的多播数据报(即多播数据报不应在互联网中兜圈子)。不难看出,对不同的多播组对应于不同的多播转发树。同一个多播组,对不同的源点也会有不同的多播转发树。
已有了多种实用的多播路由选择协议,它们在转发多播数据报时使用了以下的三种方法:
(1)洪泛与剪除
这种方法适合于较小的多播组,而所有的组成员接入的局域网也是相邻接的。一开始,路由器转发多播数据报使用洪泛的方法(这就是广播)。为了避免兜圈子,采用了叫作反向路径广播RPB(Reverse Path Broadcasting)的策略。
RPB(反向路径广播):
每一个路由器在收到一个多播数据报时,先检查数据报是否是从源点经最短路径传送来的。进行这种检查很容易,只要从本路由器寻找到源点的最短路径上(之所以叫作反向路径,因为在计算最短路径时是把源点当作终点的)的第一个路由器是否就是刚才把多播数据报送来的路由器。若是,就向所有其他方向转发刚才收到的多播数据报(但进入的方向除外),否则就丢弃而不转发。如果本路由器有好几个相邻路由器都处在到源点的最短路径上(也就是说,存在几条同样长度的最短路径),那么只能选择一条最短路径,选择的准则就是看这几条最短路径中的相邻路由器谁的IP 地址最小。下面的例子说明了这一概念:

为简单起见,在图中的网络用路由器之间的链路来表示。假定各路由器之间的距离都是 1。路由器 R1收到源点发来的多播数据报后,向 R2和R3转发。R2发现R1就在自己到源点的最短路径上,因此向 R3和R4转发收到的数据报。R3发现R2不在自己到源点的最短路径上,因此丢弃 R2 发来的数据报。其他路由器也这样转发。R7到源点有两条最短路径:R7->R4->R2->R1->源点; R7->R5->R3->R1->源点。我们再假定 R4 的 IP 地址比 R5 的IP 地址小,所以我们只使用前一条最短路径。因此 R7只转发 R4传过来的数据报,而丢弃R5传过来的数据报。最后就得出了用来转发多播数据报的多播转发树(图中用粗线表示),以后就按这个多播转发树来转发多播数据报。这样就避免了多播数据报兜圈子,同时每一个路由器也不会接收重复的多播数据报。
如果在多播转发树上的某个路由器发现它的下游树枝(即叶节点方向) 已没有该多播组的成员,就应把它和下游的树枝一起剪除。例如,在图中虚线椭圆表示剪除的部分。当某个树枝有新增加的组成员时,可以再接入到多播转发树上。

(2)隧道技术(tunneling)
隧道技术适用于多播组的位置在地理上很分散的情况。例如在下图中,网N1和网N2都支持多播。现在N1中的主机向 N2 中的一些主机进行多播。但路由器 R和 R之间的网络并不支持多播,因而 R1和R2不能按多播地址转发数据报。为此,路由器 R1就对多播数据报进行再次封装,即再加上普通数据报首部,使之成为向单一目的站发送的单播(unicast)数据报,然后通过“隧道”(tunnel)从R1发送到R2。
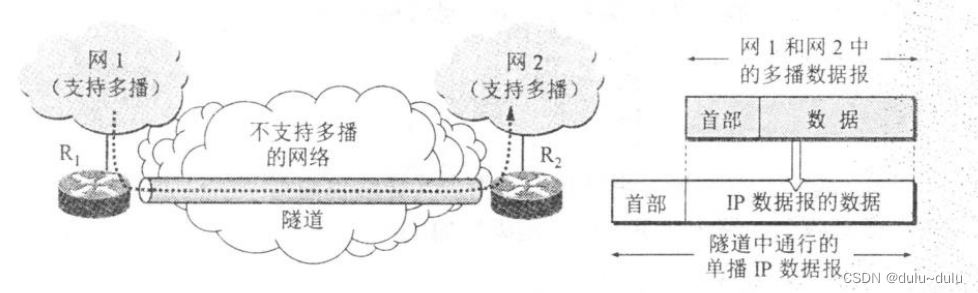
单播数据报到达路由器 R2 后,再由路由器 R2 剥去其首部,使它又恢复成原来的多播数据报,继续向多个目的站转发。这一点和英吉利海峡隧道运送汽车的情况相似。英吉利海峡隧道不允许汽车在隧道中行驶。但是,可以把汽车放置在隧道中行驶的电气火车上来通过隧道。过了隧道后,汽车又可以继续在公路上行驶。这种使用隧道技术传送数据报又叫作 IP中的IP(IP-in-IP)
(3)基于核心的发现技术
这种方法对于多播组的大小在较大范围内变化时都适合。这种方法是对每一个多播组 G 指定一个核心(core)路由器,给出它的IP 单播地址。核心路由器按照前面讲过的方法创建出对应于多播组 G 的转发树。如果有一个路由器 R1向这个核心路由器发送数据报,那么它在途中经过的每一个路由器都要检查其内容。当数据报到达参加了多播组G 的路由器 R2时,R2就处理这个数据报。如果 R1发出的是一个多播数据报,其目的地址是 G 的组地址,R2就向多播组 G 的成员转发这个多播数据报。如果 R1 发出的数据报是一个请求加入多播组 G 的数据报,R2就把这个信息加到它的路由中,并用隧道技术向R1转发每一个多播数据报的一个副本。这样,参加到多播组 G的路由器就从核心向外增多了,扩大了多播转发树的覆盖范围。
目前还没有在整个互联网范围使用的多播路由选择协议。下面是一些建议使用的多播路由选择协议
距离向量多播路由选择协议 DVMRP(Distance Vector Multicast Routing Protocol)是在互联网上使用的第一个多播路由选择协议。由于在UNIX 系统中实现 RIP 的程序叫作routed,所以在 routed 的前面加表示多播的字母 m,叫作 mrouted,它使用 DVMRP 在路由器之间传播路由信息。
基于核心的转发树CBT(Core Based Tree)。这个协议使用核心路由器作为转发树的根节点。一个大的自治系统 AS 可划分为几个区域,每一个区域选择一个核心路由器(也叫作中心路由器 center router,或汇聚点路由器 rendezvous router)。
开放最短通路优先的多播扩展MOSPF(Multicast extensions to OSPF)。这个协议是单播路由选择协议 OSPF 的扩充,使用于一个机构内。MOSPF 使用多播链路状态路由选择创建出基于源点的多播转发树。
协议无关多播-稀疏方式 PIM-SM(ProtocolIndependent Multicast-Sparse Mode)。这是唯一成为互联网标准的一个协议,它使用和 CBT 同样的方法构成多播转发树。采用“协议无关”这个名词是强调:虽然在建立多播转发树时是使用单播数据报来和远程路由器联系的,但这并不要求使用特定的单播路由选择协议。这个协议适用于组成员的分布非常分散的情况。
协议无关多播-密集方式 PIM-DM (Protocol Independent Multicast-Dense Mode)。这个协议适用于组成员的分布非常集中的情况,例如组成员都在一个机构之内。PIM-DM 不使用核心路由器,而是使用洪泛方式转发数据报。




![[.NET]启明星电子文档管理系统edoc v33.0](https://img-blog.csdnimg.cn/8ab998cae3c84a039cc72b109e58bdbb.png)