✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、代码参考
- 五、论文参考
- 六、系统视频
- 结语
一、前言
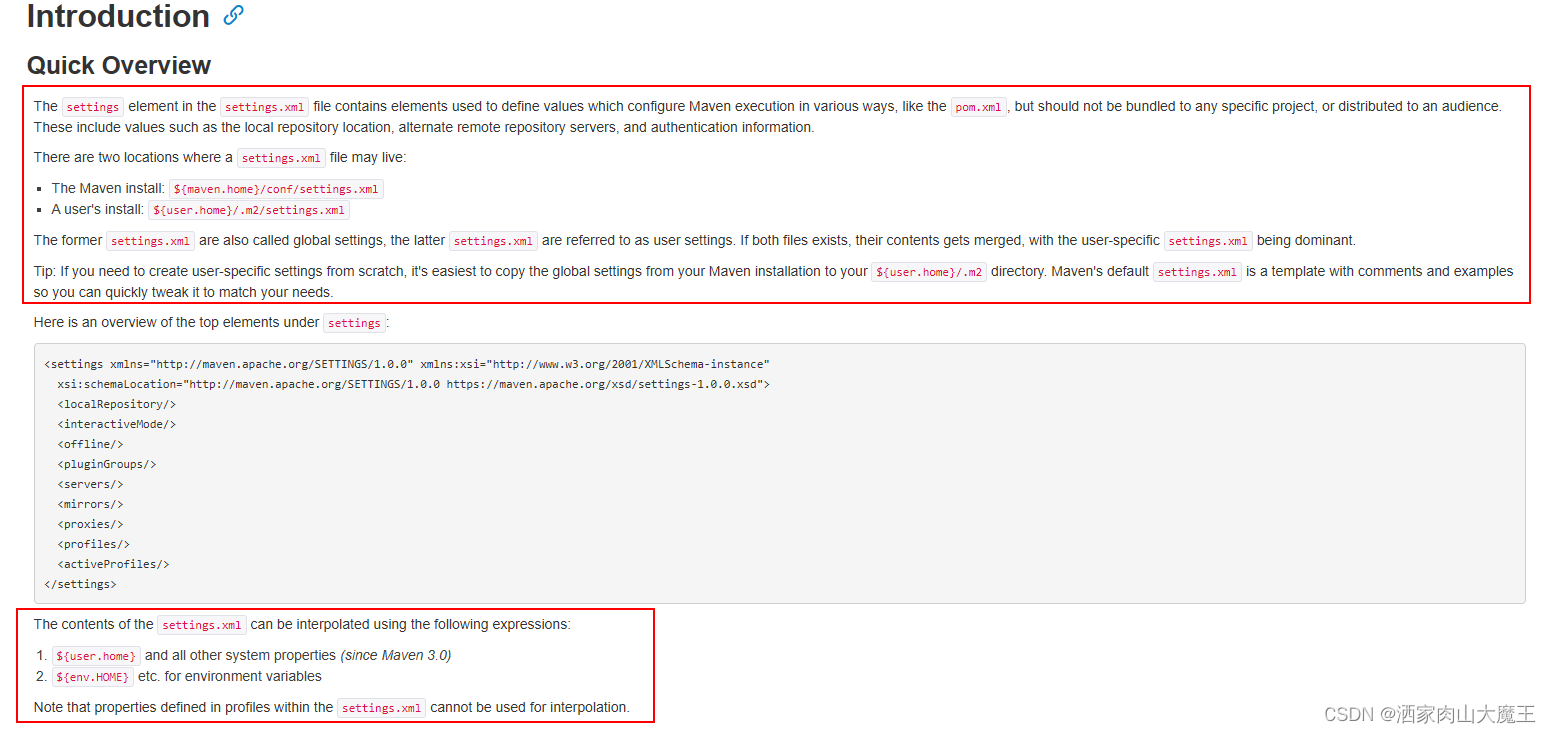
随着工业化和城市化的快速发展,污水排放问题日益严重。为了管理和治理污水问题,建立基于大数据的污水处理大数据平台显得尤为重要。此平台可帮助我们实现对排放总量、行业污水排放量、行业氧化亚氮排放量、各行业氯苯排放量等关键指标的统计和分析,进而为污水处理和环境治理提供科学依据。
尽管目前已经有一些污水处理和排放统计的方法和技术,但它们往往存在一些问题。首先,许多方法仅能提供单一的排放量或处理量数据,无法对数据进行多种维度的分析。其次,这些方法往往缺乏实时性,无法及时反映污水处理和排放的实时情况。再次,很多方法无法对数据进行挖掘,无法揭示出隐藏在数据背后的规律和趋势。
本课题旨在建立一个基于大数据的污水处理大数据平台,以解决现有方法存在的问题。平台将实现对各类数据的采集、整合和分析,提供多种数据可视化工具,帮助研究人员和决策者更好地理解和处理污水问题。同时,该平台还将提供实时数据监测和预警功能,以便及时发现和处理污水排放和处理的异常情况。
本课题的研究意义在于推动大数据技术在污水处理领域的应用,提升污水处理和管理的效率和效果。通过建立基于大数据的污水处理大数据平台,我们将能够更好地理解和利用数据,为污水处理和环境治理提供科学依据,从而增进环境保护和可持续发展。同时,此研究还将为其他领域提供一种新的数据管理和分析模式,推动各行业的智能化和绿色化发展。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
三、系统界面展示
- 污水处理大数据平台界面展示:






四、代码参考
- 大数据项目实战代码参考:
class EMSAS():
def __init__(self, window):
self.window = window
''' 菜单栏初始化'''
menu_root = tkinter.Menu(self.window) # 创建根菜单
self.window['menu'] = menu_root # 顶级菜单关联根窗体
menu1 = tkinter.Menu(menu_root, tearoff=False) # 创建子菜单
meun2 = tkinter.Menu(menu_root, tearoff=False)
meun3 = tkinter.Menu(menu_root, tearoff=False)
menu1.add_command(label='打开',command = self.openFileDialog) # 子菜单栏
menu1.add_command(label='保存')
meun2.add_command(label='地表水标准', command=self.openGB3838) # 子菜单栏
meun2.add_command(label='地下水标准', command=self.openGB14848)
meun3.add_command(label='地表水点位', command=self.openSites) # 子菜单栏
meun3.add_command(label='地下水点位', command=self.openSites)
menu_root.add_cascade(label='文件', menu = menu1) # 创建顶级菜单栏,并关联子菜单
menu_root.add_cascade(label='标准配置', menu=meun2)
menu_root.add_cascade(label='点位配置', menu=meun3)
menu_root.add_cascade(label='关于')
menu_root.add_command(label='退出', command = self.window.quit)
self.frame_u = Frame(width=706, height=100, relief=RAISED,borderwidth=1)
self.frame_l = Frame(width=350, height=300, relief=RAISED,borderwidth=1)
self.frame_r = Frame(width=350, height=300, relief=RAISED,borderwidth=1) #relief=RAISED,
self.frame_b = Frame(width=706, height=270, relief=RAISED,bg='blue', borderwidth=1)
self.frame_u.grid(row=0, column=0, rowspan=1, columnspan=2, padx=2, pady=2)
self.frame_l.grid(row=1, column=0, rowspan=1, columnspan=1, padx=2, pady=2)
self.frame_r.grid(row=1, column=1, rowspan=1, columnspan=1, padx=2, pady=2)
self.frame_b.grid(row=2, column=0, rowspan=1, columnspan=2, padx=2, pady=2)
self.frame_u.grid_propagate(0) #固定容器大小
self.frame_l.grid_propagate(0)
self.frame_r.grid_propagate(0)
self.frame_b.grid_propagate(0)
self.openfile_button = Button(self.frame_u, text="打开Excel文件", # bg="lightblue",
command=self.openFileDialog, pady=2, bd=5,relief=RAISED,font=(fontType_Arial, fontsize_M)) # 调用内部方法 加()为直接调用
self.openfile_button.grid(row=0, column=0,columnspan = 2,sticky=W)
self.filename_label = Label(self.frame_u, pady=1, text="")
self.filename_label.grid(row=1, column=0,sticky=W)
self.filename_out_label = Label(self.frame_u,pady=1, text="")
self.filename_out_label.grid(row=2, column=0,sticky=W)
self.surfaceW_label = Label(self.frame_l, text="地表水水质类别与超标情况判断", font=(fontType_Arial, fontsize_M))
self.surfaceW_label.grid(row=1, column=1, rowspan=1, columnspan=5,pady=35)
self.surfaceW_v = IntVar()
self.surfaceW_site_rb = Radiobutton(self.frame_l, text='使用已配置点位信息', variable=self.surfaceW_v, value=1,font=(fontType_Arial, fontsize_M),
command=self.changeselect)
self.surfaceW_site_rb.grid(row=2, column=1, rowspan=1, columnspan=2,pady=5,sticky=E)
self.surfaceW_v.set(1) # 默认值为1,选中状态
self.surfaceW_site_rb = Radiobutton(self.frame_l, text='河 流', variable=self.surfaceW_v, value=2,font=(fontType_Arial, fontsize_M),
command=self.changeselect)
self.surfaceW_site_rb.grid(row=3, column=1, rowspan=1, columnspan=1,pady=5 ,sticky=E)
self.surfaceW_lk_rb = Radiobutton(self.frame_l, text='湖 库', variable=self.surfaceW_v, value=3,font=(fontType_Arial, fontsize_M),
command=self.changeselect)
self.surfaceW_lk_rb.grid(row=3, column=2, rowspan=1, columnspan=1,pady=5,sticky=W)
self.SurEva_button = Button(self.frame_l, text=" GB3838判定类别与超标情况 ", font=(fontType_Arial, fontsize_M),
command=self.surfaceW_EVA, pady=1, bd=5) # 调用内部方法 加()为直接调用
self.SurEva_button.grid(row=4, column=1,rowspan=1, columnspan=5, pady=25)
''' frame right '''
self.underW_label = Label(self.frame_r, text="地下水水质类别与超标情况判断", font=(fontType_Arial, fontsize_M))
self.underW_label.grid(row=1, column=1, rowspan=1, columnspan=5,pady=35)
self.underW_v = IntVar()
self.underW_site_rb = Radiobutton(self.frame_r, text='使用已配置点位信息', variable=self.underW_v, value=1,
font=(fontType_Arial, fontsize_M),
command=self.changeselect)
self.underW_site_rb.grid(row=2, column=1, rowspan=1, columnspan=2,pady=5)
self.underW_v.set(1) # 默认值为1,选中状态
self.underW_site_rb = Radiobutton(self.frame_r, text='不使用已配置点位信息', variable=self.underW_v, value=2,
font=(fontType_Arial, fontsize_M),
command=self.changeselect)
self.underW_site_rb.grid(row=3, column=1, rowspan=1, columnspan=2,pady=5)
self.UnderEva_button = Button(self.frame_r, text=" GB/T14848判定类别与超标情况 ", font=(fontType_Arial, fontsize_M),
command=self.underW_EVA, pady=1, bd=5) # 调用内部方法 加()为直接调用
self.UnderEva_button.grid(row=4, column=1,rowspan=1, columnspan=5, pady=25)
''' frame bottom '''
self.log_data_Text = Text(self.frame_b,width=98,font=(fontType_Arial, fontsize_S))
self.log_data_Text.grid(row=6, column=1,columnspan=1,sticky=tkinter.E+tkinter.W) #, rowspan=1, columnspan=15, padx=1, pady=1)
scroll = tkinter.Scrollbar(self.frame_b,width=20)
# 放到窗口的右侧, 填充Y竖直方向
scroll.grid(row=6, column=2, sticky=tkinter.N+tkinter.S)
# 两个控件关联
scroll.config(command=self.log_data_Text.yview)
self.log_data_Text.config(yscrollcommand=scroll.set)
self.write_log_to_Text("----注意事项-------\n1.请确保打开的Excel首行为标题行,第二行始为数据行.\n2.如果使用配置好的点位信息,请确保点位列使用 '监测点位、断面名称、点位名称、所属断面'之一'.\n3.生成的文件位于打开的文件同一目录.")
self.write_log_to_Text(loadSiteGB)
old = sys.stdout # 将当前系统输出储存到一个临时变量中
if log_to_file == '1':
print(log_to_file)
menu_root = open('.\\logs\\' + self.get_current_time2() + '.log', 'w')
sys.stdout = menu_root # 输出重定向到文件
else:
sys.stdout = old
# 设置窗口
def set_window(self):
self.window.title("水环境质量评价软件(WEQAS)V1.0") # 窗口名
# self.window.geometry('320x160+10+10') #290 160为窗口大小,+10 +10 定义窗口弹出时的默认展示位置
self.window.geometry('715x688+200+200') # w*h+/-x+/-y
# self.window.resizable(0, 0)
# self.window["bg"] = "yellow" # 窗口背景色,其他背景色见:blog.csdn.net/chl0000/article/details/7657887
self.window.attributes("-alpha", 0.995) # 虚化,值越小虚化程度越高
# 功能函数
def changeselect(self):
pass
def surfaceW_EVA(self):
global filefrom_df,sitesInfo_df,GB3838_reg_df, GB3838_df,filenamefrom
panit_surf = []
if filenamefrom == '':
return
if (self.surfaceW_v.get() == 1): # 用已配置点位信息表
colNames = filefrom_df.columns.tolist()
if '断面名称' in colNames:
siteCol = '断面名称'
elif '监测点位' in colNames:
siteCol = '监测点位'
elif '点位名称' in colNames:
siteCol = '点位名称'
elif '所属断面' in colNames:
siteCol = '所属断面'
else:
self.write_log_to_Text('Error:' + "在您输入的Excel中未找到点位列,请确保点位列使用 '监测点位、断面名称、点位名称、所属断面'之一,并确保首行为标题行! ")
return
print('点位数量:'+str(filefrom_df.shape[0]))
for i in range(filefrom_df.shape[0]):
df_m_1l = filefrom_df.iloc[i, :] # pd.Series
siteName = df_m_1l[siteCol]
# print('sitesInfo_df=',sitesInfo_df)
if siteName in sitesInfo_df.index.tolist():
targetClass = sitesInfo_df.loc[siteName, '考核级别'] # one行,a列
siteType = sitesInfo_df.loc[siteName, '断面类型'] # one行,a列
if siteType == '湖库':
lake = 1
else:
lake = 0
cls, overtimessites , cls_of_item, sucessedReg = siteEval(GB3838_reg_df, GB3838_df, siteName, 0, df_m_1l, int(typeCover(targetClass)), lake)
print('cls, overtimessites ', cls, overtimessites)
# print(df_sur_city.columns)
filefrom_df.loc[i, '水质类别'] = typeCover(cls)
filefrom_df.loc[i, '超标情况'] = overtimessites
[ClassPerIteminRow.append(i) for ClassPerIteminRow in cls_of_item]
panit_surf.extend(cls_of_item)
print(sucessedReg)
if len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) > 0:
self.write_log_to_Text('Warning' + sucessedReg)
elif len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) == 0:
self.write_log_to_Text('INFO' + sucessedReg)
elif (self.surfaceW_v.get() == 2): # 不用已配置点位信息表,全部点位都是河流断面
for i in range(filefrom_df.shape[0]):
df_m_1l = filefrom_df.iloc[i, :] # pd.Series
cls, overtimessites, cls_of_item, sucessedReg = siteEval(GB3838_reg_df, GB3838_df, '', 0,df_m_1l,3, 0) # 默认类别为 targetClass = 3
filefrom_df.loc[i, '水质类别'] = typeCover(cls)
filefrom_df.loc[i, '超标情况'] = overtimessites
[ClassPerIteminRow.append(i) for ClassPerIteminRow in cls_of_item]
panit_surf.extend(cls_of_item)
if len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) > 0:
self.write_log_to_Text('Warning' + sucessedReg)
elif len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) == 0:
self.write_log_to_Text('INFO' + sucessedReg)
elif (self.surfaceW_v.get() == 3): # 不用已配置点位信息表,全部点位都是湖库
for i in range(filefrom_df.shape[0]):
df_m_1l = filefrom_df.iloc[i, :] # pd.Series
cls, overtimessites, cls_of_item, sucessedReg = siteEval(GB3838_reg_df, GB3838_df, '', 0, df_m_1l, 3,
1) # 默认类别为 targetClass = 3
filefrom_df.loc[i, '水质类别'] = typeCover(cls)
filefrom_df.loc[i, '超标情况'] = overtimessites
[ClassPerIteminRow.append(i) for ClassPerIteminRow in cls_of_item]
panit_surf.extend(cls_of_item)
if len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) > 0:
self.write_log_to_Text('Warning' + sucessedReg)
elif len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) == 0:
self.write_log_to_Text('INFO' + sucessedReg)
filefrom_df.to_excel(filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx', index=False)
book = openpyxl.load_workbook(filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx')
sheets = book.sheetnames # 获取全部sheet
ws = book[sheets[0]]
for item in panit_surf: # openpyxl 读写单元格时,单元格的坐标位置起始值是(1,1),并且第一行为标题,故第一行数据加2
ws.cell(item[2] + 2, item[0] + 1).fill = PatternFill(fill_type='solid', fgColor=getFgColor(item[1]))
book.save(filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx')
self.filename_out_label.config(text="输出的文件:" + filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx')
try:
os.startfile(r''+filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx') # windows下成功打开excel
except:
print('系统没有自动打开文件的工具')
return
def underW_EVA(self):
global filefrom_df, sitesInfo_df, GBT14848_df, filenamefrom
panit_surf = []
if filenamefrom == '':
return
if (self.underW_v.get() == 1): # 用已配置点位信息表
colNames = filefrom_df.columns.tolist()
if '断面名称' in colNames:
siteCol = '断面名称'
elif '监测点位' in colNames:
siteCol = '监测点位'
elif '点位名称' in colNames:
siteCol = '点位名称'
else:
self.write_log_to_Text('Error:' + "在您输入的Excel中未找到点位列,请确保点位列使用 '断面名称'或'监测点位'或'点位名称'之一 ")
return
for i in range(filefrom_df.shape[0]):
df_m_1l = filefrom_df.iloc[i, :] # pd.Series
siteName = df_m_1l[siteCol] # 或者叫监测点位、点位名称
# print('sitesInfo_df=', sitesInfo_df)
if siteName in sitesInfo_df.index.tolist():
targetClass = sitesInfo_df.loc[siteName, '考核级别'] # one行,a列
cls, overtimessites, cls_of_item,sucessedReg = siteEval_underwater(GBT14848_df[GBT14848_df['是否评价'] == 1], GBT14848_df, siteName, 0,
df_m_1l, int(typeCover(targetClass)))
filefrom_df.loc[i, '水质类别'] = typeCover(cls)
filefrom_df.loc[i, '超标情况'] = overtimessites
[ClassPerIteminRow.append(i) for ClassPerIteminRow in cls_of_item]
panit_surf.extend(cls_of_item)
if len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) > 0:
self.write_log_to_Text('Warning' + sucessedReg)
elif len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']') + 1])) == 0:
self.write_log_to_Text('INFO' + sucessedReg)
elif (self.underW_v.get() == 2): # 不用已配置点位信息表
for i in range(filefrom_df.shape[0]):
df_m_1l = filefrom_df.iloc[i, :] # pd.Series
cls, overtimessites, cls_of_item, sucessedReg = siteEval_underwater(GBT14848_df[GBT14848_df['是否评价'] == 1], GBT14848_df, '', 0,
df_m_1l, 3) # 默认类别为 targetClass = 3
filefrom_df.loc[i, '水质类别'] = typeCover(cls)
filefrom_df.loc[i, '超标情况'] = overtimessites
[ClassPerIteminRow.append(i) for ClassPerIteminRow in cls_of_item]
panit_surf.extend(cls_of_item)
if len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']')+1]))>0:
self.write_log_to_Text('Warning' + sucessedReg)
elif len(eval(sucessedReg[sucessedReg.find('['):sucessedReg.find(']')+1]))==0:
self.write_log_to_Text('INFO' + sucessedReg)
filefrom_df.to_excel(filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx', index=False)
book = openpyxl.load_workbook(filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx')
sheets = book.sheetnames # 获取全部sheet
ws = book[sheets[0]]
for item in panit_surf: # openpyxl 读写单元格时,单元格的坐标位置起始值是(1,1),并且第一行为标题,故第一行数据加2
ws.cell(item[2] + 2, item[0] + 1).fill = PatternFill(fill_type='solid', fgColor=getFgColor(item[1]))
book.save(filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx')
self.filename_out_label.config(text="输出的文件:" + filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx')
try:
os.startfile(r'' + filenamefrom[0:filenamefrom.find('.')] + '_Evaluated.xlsx') # windows下成功打开excel
except:
print('----系统没有自动打开文件的工具----')
return
# 获取当前时间
def get_current_time(self):
current_time = time.strftime('%y-%m-%d %H:%M:%S', time.localtime(time.time()))
return current_time
def get_current_time2(self):
current_time = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
return current_time
# 日志动态打印
def write_log_to_Text(self, logmsg):
global LOG_LINE_NUM
current_time = self.get_current_time()
if LOG_LINE_NUM == 0:
logmsg_in = " " + str(logmsg) + "\n" # 换行
else: logmsg_in = str(current_time) + " " + str(logmsg) + "\n" # 换行
if LOG_LINE_NUM <= 50:
self.log_data_Text.insert(END, logmsg_in)
LOG_LINE_NUM = LOG_LINE_NUM + 1
else:
self.log_data_Text.delete(1.0, 2.0)
self.log_data_Text.insert(END, logmsg_in)
if logmsg.find('Error')>-1:
messagebox.showerror('出错了',logmsg)
elif logmsg.find('Warning')>-1:
messagebox.showwarning('请注意', logmsg)
def openFileDialog(self):
"打开对话框,参数与保存对话框相同.略"
global filefrom_df,filenamefrom
self.filename = askopenfilename(filetypes=filetype)
self.filename_label.config(text="打开的文件:" + self.filename)
if self.filename:
filefrom_df = pd.read_excel(self.filename, keep_default_na=False, header=0)
filenamefrom = self.filename
else:
pass
# print(self.filename)
def openGB3838(self):
try:
filepath = os.path.join('./staticData', 'GB3838-2002-t1.xls')
os.startfile(filepath) # windows下打开地表水标准配置文件
except:
print('----未找到关于地表水标准的配置文件,请确认已经正确创建----')
self.log_data_Text.insert(END, '未找到关于地表水标准的配置文件,请确认已经正确创建')
return
def openGB14848(self):
try:
filepath = os.path.join('./staticData', 'GBT14848-2017-t1.xls')
os.startfile(filepath) # windows下打开地下水标准配置文件
except:
print('----未找到关于地下水标准的配置文件,请确认已经正确创建----')
self.log_data_Text.insert(END, '未找到关于地下水标准的配置文件,请确认已经正确创建')
return
def openSites(self):
try:
filepath = os.path.join('./staticData', 'sitesInfo.xls')
os.startfile(filepath) # windows下打开地表水标准配置文件
except:
print('----未找到关于地下水标准的配置文件,请确认已经正确创建----')
self.log_data_Text.insert(END, '未找到关于地下水标准的配置文件,请确认已经正确创建')
return
def gui_start():
window = Tk() # 实例化出一个父窗口
ZMJ_PORTAL = EMSAS(window)
# 设置根窗口默认属性
ZMJ_PORTAL.set_window()
window.mainloop() # 父窗口进入事件循环,可以理解为保持窗口运行,否则界面不展示
if __name__ == "__main__":
gui_start()
五、论文参考
- 计算机毕业设计选题推荐-污水处理大数据平台论文参考:

六、系统视频
污水处理大数据平台项目视频:
大数据毕业设计选题推荐-污水处理大数据平台-Hadoop
结语
大数据毕业设计选题推荐-污水处理大数据平台-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目