目录
- DenseNet
- DenseNet的优点:
- DenseNet的改进思路
- 总结
- DenseNet代码实现
DenseNet
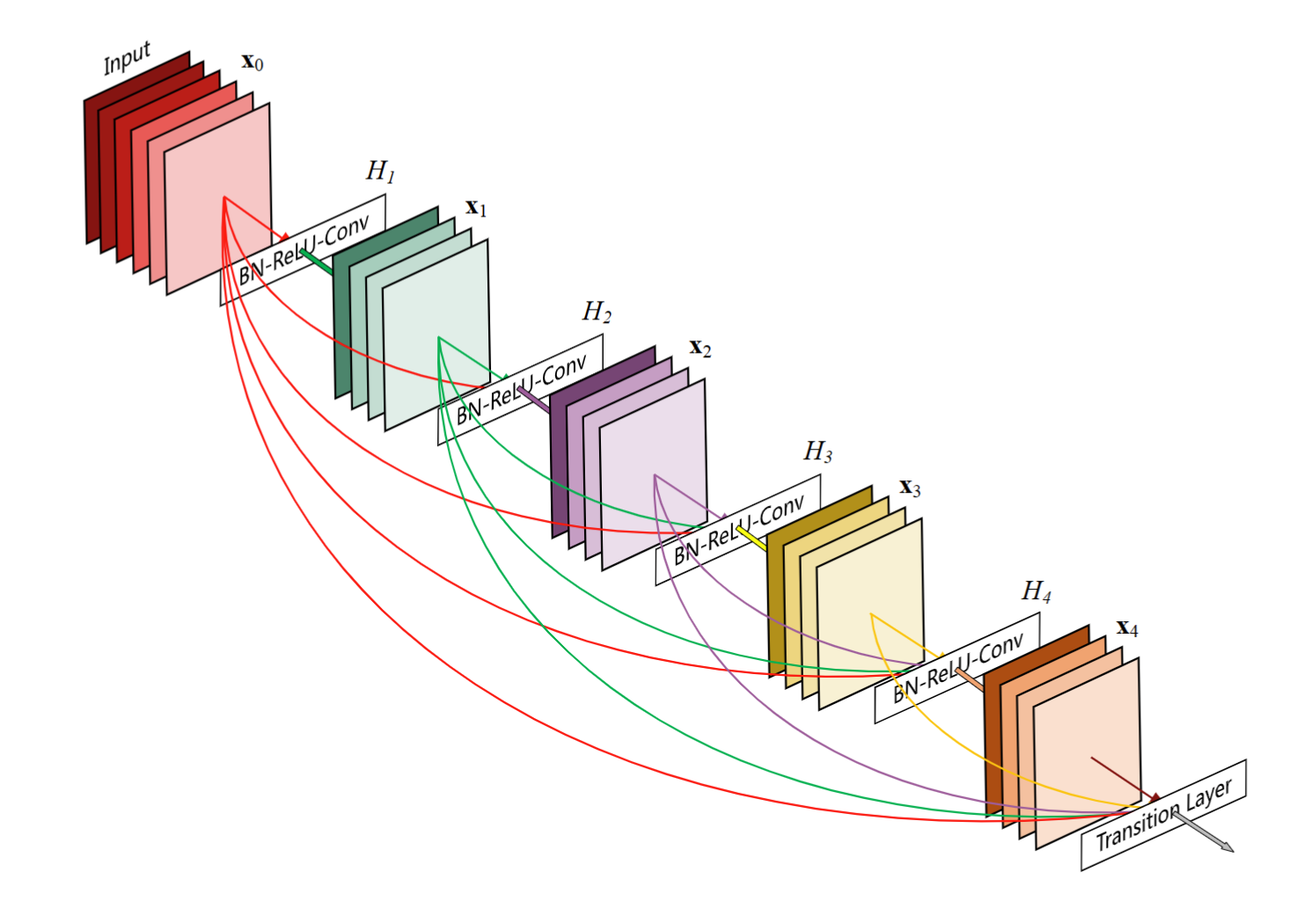

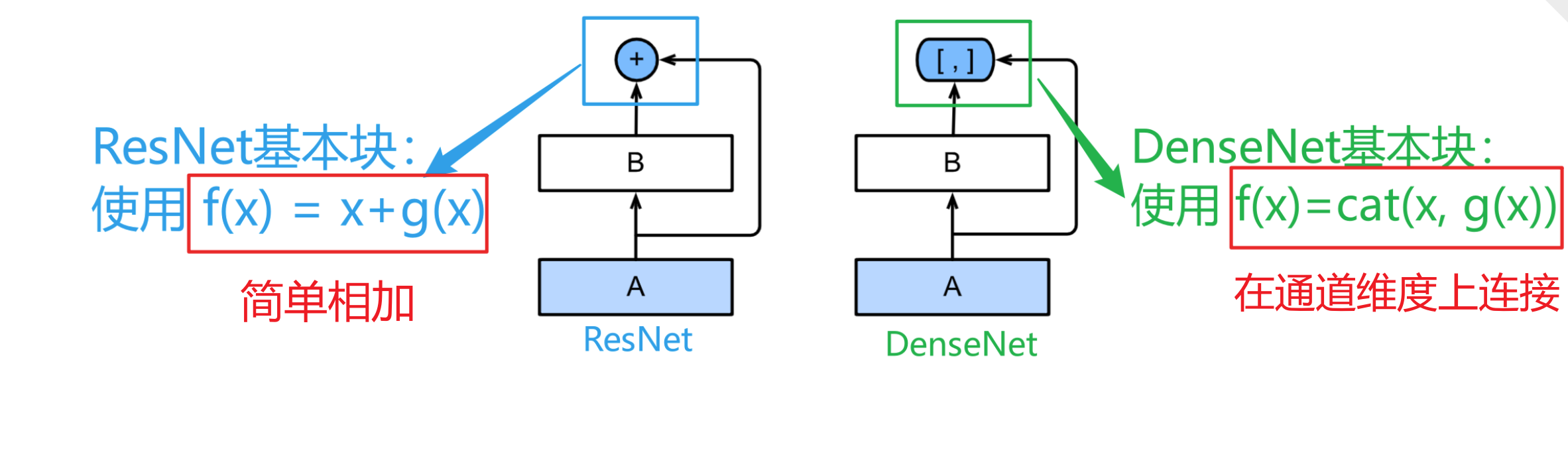

DenseNet的优点:
- 省参数。在 ImageNet 分类数据集上达到同样的准确率,DenseNet 所需的参数量不到 ResNet 的一半。对于工业界而言,小模型可以显著地节省带宽,降低存储开销。
- 省计算。达到与 ResNet 相当的精度,DenseNet 所需的计算量也只有 ResNet 的一半左右。计算效率在深度学习实际应用中的需求非常强烈,从本次 CVPR 会上大家对模型压缩以及 MobileNet 和 ShuffleNet 这些工作的关注就可以看得出来。最近我们也在搭建更高效的 DenseNet,初步结果表明 DenseNet 对于这类应用具有非常大的潜力,即使不用 Depth Separable Convolution 也能达到比现有方法更好的结果,预计在近期我们会公开相应的方法和模型。
- 抗过拟合。DenseNet 具有非常好的抗过拟合性能,尤其适合于训练数据相对匮乏的应用。对于 DenseNet 抗过拟合的原因有一个比较直观的解释:神经网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也逐渐增加(更多非线性函数的复合)。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet 可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数。实际上,DenseNet 的泛化性能优于其他网络是可以从理论上证明的:去年的一篇几乎与 DenseNet 同期发布在 arXiv 上的论文(AdaNet: Adaptive Structural Learning of Artificial Neural Networks)所证明的结论(见原文中 Theorem 1)表明类似于 DenseNet 的网络结构具有更小的泛化误差界。
- 泛化性能更强。如果没有data augmention,CIFAR-100下,ResNet表现下降很多,DenseNet下降不多,说明DenseNet泛化性能更强。
DenseNet的改进思路
- 每层开始的瓶颈层(1x1 卷积)对于减少参数量和计算量非常有用。
- 像 VGG 和 ResNet 那样每做一次下采样(down-sampling)之后都把层宽度(growth rate) 增加一倍,可以提高 DenseNet 的计算效率(FLOPS efficiency)。
- 与其他网络一样,DenseNet 的深度和宽度应该均衡的变化,当然 DenseNet 每层的宽度要远小于其他模型。
- 每一层设计得较窄会降低 DenseNet 在 GPU 上的运算效率,但可能会提高在 CPU 上的运算效率。
总结
- 在跨层连接上,不同于ResNet中将输入与输出相加,稠密连接网络(DenseNet)在通道维度上连接(concat)输入和输出。
- DenseNet的主要构建模块是稠密块和过渡层。
- 在构建DenseNet时,我们需要通过添加过渡层来控制网络的维数,从而再次减少通道数。
DenseNet代码实现
- 导入相关库
import torch
from torch import nn
from d2l import torch as d2l
- 定义网络模型
- DenseNet Block由稠密块和过渡层构成:
- 稠密块:
- 由多个卷积块(BN+RelU+Conv)构成。
- 过渡层:
- 由卷积块(BN+Conv)和池化层构成。
# 定义卷积块(BN+RelU+Conv): 输入和输出的长和宽不变
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1)
)
# 定义稠密块
class DensBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
"""
:param num_convs: 卷积层个数
:param input_channels: 输入通道数
:param num_channels: 输出通道数
"""
super().__init__()
layer = []
for i in range(num_convs):
layer.append(
conv_block(num_channels * i + input_channels, num_channels)
)
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X
查看稠密块
blk = DensBlock(2, 3 ,10)
X = torch.randn(4, 3, 8, 8)
Y = blk(X)
Y.shape # [4, 23, 8, 8] 23 = 3 + 2*10

- DenseNet Block由稠密块和过渡层构成
- 稠密块:
- 由多个卷积块(BN+RelU+Conv)构成。
- 过渡层:
- 由卷积块(BN+Conv)和池化层构成。
# 定义过渡层(卷积块(BN+Conv)和池化层)
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2)
)
查看过渡层
blk = transition_block(23, 10)
X = torch.randn(4, 23, 8, 8)
Y = blk(X)
Y.shape # [4, 23, 8, 8] ---> [3, 10, 8, 8]

- DenseNet Block由稠密块和过渡层构成
- 稠密块:
- 由多个卷积块(BN+RelU+Conv)构成。
- 过渡层:
- 由卷积块(BN+Conv)和池化层构成。
# 首先使用同ResNet一样的单卷积层和最大汇聚层
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 接下来,类似于ResNet使用的4个残差块,DenseNet使用的是4个稠密块。
# 稠密块里的卷积层通道数(即增长率)设为32,所以每个稠密块将增加128个通道。
# 在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数
num_channels, growth_rate = 64, 32 # 当前的通道数, 增长率
num_convs_in_dense_blocks = [4, 4, 4, 4] # 4个稠密块内卷积层的个数
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(
DensBlock(num_convs, num_channels, growth_rate)
)
num_channels +=num_convs * growth_rate # 上一个稠密块的输出通道数
if i != len(num_convs_in_dense_blocks) -1 :
# 在稠密块之间添加一个过渡层,使通道数减半。
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
net = nn.Sequential(
b1,
*blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10)
)
- 查看网络模型
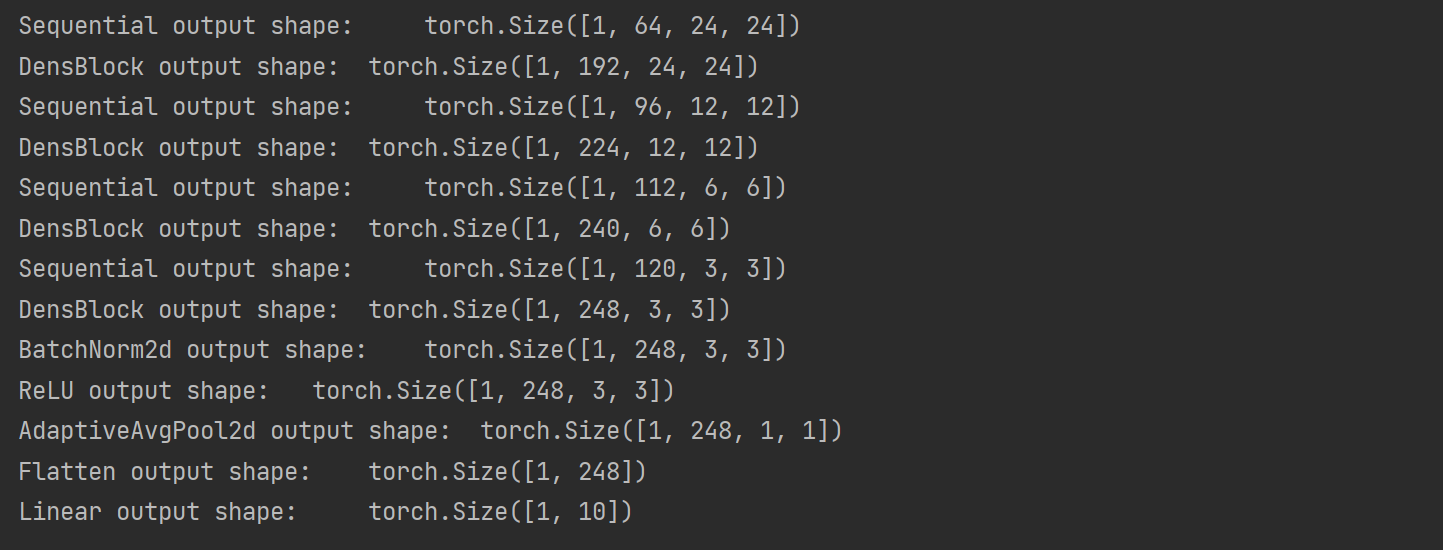
X = torch.randn(1, 1, 96, 96)
for layer in net :
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
- 加载数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
- 训练模型
import time
lr, num_epochs = 0.1, 10
start = time.perf_counter()
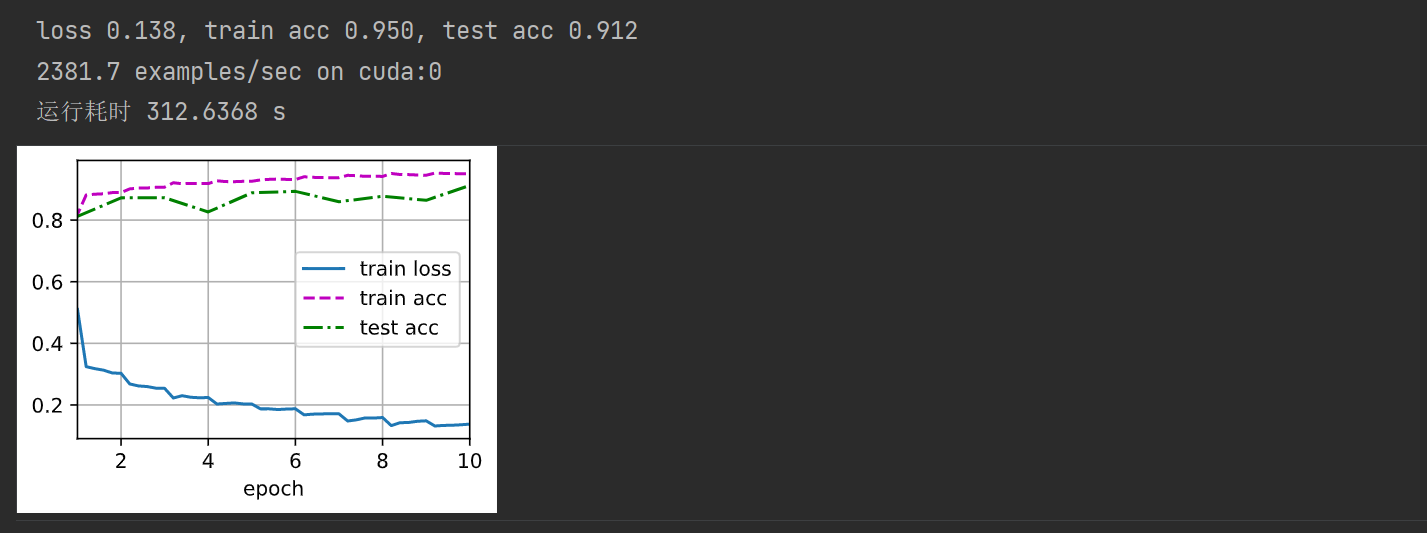
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
end = time.perf_counter()
print("运行耗时 %.4f s" % (end-start))

![[量化投资-学习笔记009]Python+TDengine从零开始搭建量化分析平台-KDJ](https://img-blog.csdnimg.cn/b3e33794423a4d36a07800969dcdd997.png#pic_center)