目录
- Redis系列-Redis过期策略以及内存淘汰机制【6】
- redis过期策略
- 内存淘汰机制
- 算法
- LRU算法
- LFU
- 其他场景对过期key的处理
- FAQ
- 为什么不用定时删除策略?
- Ref
个人主页: 【⭐️个人主页】
需要您的【💖 点赞+关注】支持 💯
Redis系列-Redis过期策略以及内存淘汰机制【6】
redis主要是基于内存来进行高性能、高并发的读写操作的。但既然内存是有限的,例如redis就只能使用10G,你写入了20G。这个时候就需要清理掉10G数据,保留10G数据。那应该保留哪些数据,清除哪些数据,为什么有些数据明明过期了,怎么还占用着内存?这都是由redis的过期策略来决定的。
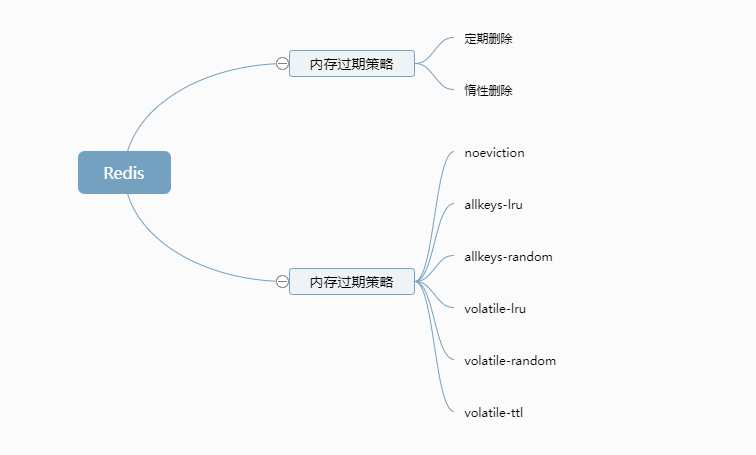
redis过期策略
redis的过期策略就是:定期删除 + 惰性删除。
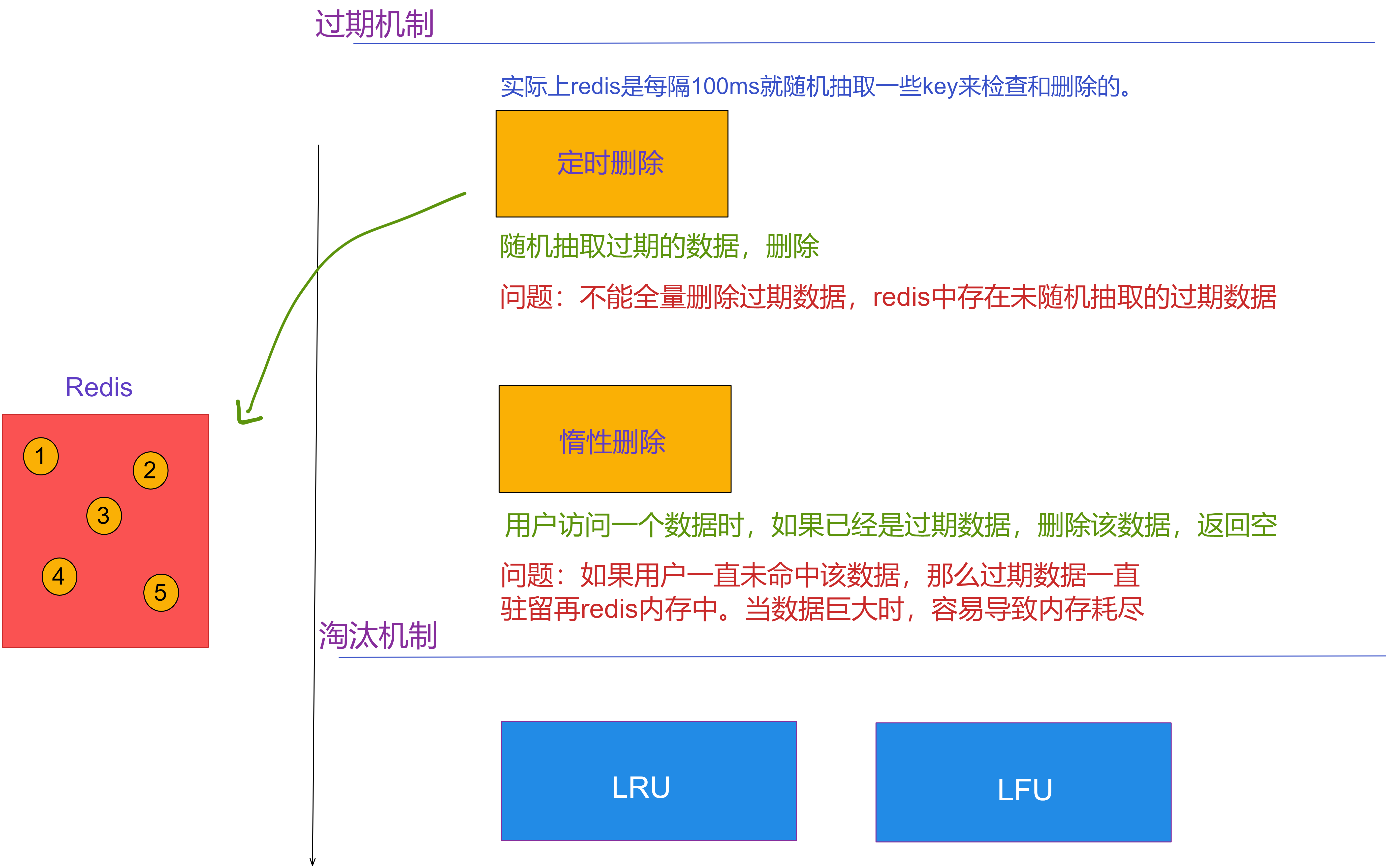
定期删除,指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查是否过期,如果过期就删除。
🅰️ 100ms怎么来的?
在Redis的配置文件redis.conf中有一个属性"hz",默认为10
表示1s执行10次定期删除,即每隔100ms执行一次,可以修改这个配置值。

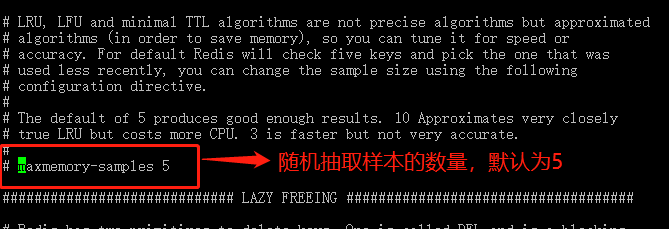
🅱️ 随机抽取一些检测,一些是多少?
同样是由redis.conf文件中的maxmemory-samples属性决定的,默认为5。
在Redis的配置文件redis.conf中有一个属性"hz",默认为10,表示1s执行10次定期删除,即每隔100ms执行一次,可以修改这个配置值。
假设redis里放了10W个key,都设置了过期时间,你每隔几百毫秒就检查全部的key,那redis很有可能就挂了,CPU负载会很高,都消耗在检查过期的key上。注意,这里不是每隔100ms就遍历所有设置过期时间的key,那样就是一场性能灾难。实际上redis是每隔100ms就随机抽取一些key来检查和删除的。
定期删除可能会导致很多过期的key到了时间并没有被删除掉。这个时候就可以用到惰性删除了。
惰性删除 是指在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间并且已经过期了,此时就会删除,不会给你返回任何东西。
但即使是这样,依旧有问题。如果定期删除漏掉了很多过期的key,然后你也没及时去查,也就没走惰性删除。此时依旧有可能大量过期的key堆积在内存里,导致内存耗尽。
这个时候就需要内存淘汰机制了。
内存淘汰机制
在redis.conf中有一行配置 ,该配置就是配内存淘汰策略的
# maxmemory-policy volatile-lru
redis·内存淘汰机制有以下几个:
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。这个一般很少用。allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key,这个是最常用的。allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。allkeys-lfu,淘汰整个键值中最少使用的键值,这也就是我们常说的LRU算法。 【Redis4.0】volatile-lfu,淘汰所有设置了过期时间的键值中最少使用的键值【Redis4.0】
而在Redis4.0版本中又新增了2种淘汰策略:
allkeys-lfu,淘汰整个键值中最少使用的键值,这也就是我们常说的LRU算法。
volatile-lfu,淘汰所有设置了过期时间的键值中最少使用的键值
通过上面的内存淘汰策略可以看出,以 allkeys- 开头的表示从所有key中进行数据淘汰,而以 volatile- 开头的会从设置了过期时间的key中进行数据淘汰。
算法
LRU(Least Recently Used,最近最少使用),根据最近被使用的时间,离当前最远的数据优先被淘汰;LFU(Least Frequently Used,最不经常使用),在一段时间内,缓存数据被使用次数最少的会被淘汰。
LRU算法
上面的内存淘汰机制中,用到的是LRU算法。什么是LRU算法?LRU算法其实就是上面说的最近最少使用策略。
实现LRU算法,大概的思路如下:
1. 维护一个有序单链表,越靠近链表尾部的节点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表:
2. 如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的节点,并将其从原来的位置删除,然后再插入到链表的头部。
3. 如果此数据没有在缓存链表中,又可以分为两种情况:
- 如果此时缓存未满,则将此节点直接插入到链表的头部;
- 如果此时缓存已满,则链表尾节点删除,将新的数据节点插入链表的头部。
这就就实现了LRU算法。
当然我们也可以基于Java现有的数据结构LinkedHashMap手撸一个。LinkHashMap本质上是一个Map与双向链表的结合,比起上述的单链表,效率更高。代码如下:
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE;
/**
* 传递进来最多能缓存多少数据
*
* @param cacheSize 缓存大小
*/
public LRUCache(int cacheSize) {
// true 表示让 linkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部。
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当 map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
return size() > CACHE_SIZE;
}
}
LFU
在Redis LFU算法中,为每个key维护了一个计数器,每次key被访问的时候,计数器增大,计数器越大,则认为访问越频繁。但其实这样会有问题,
1、因为访问频率是动态变化的,前段时间频繁访问的key,之后也可能很少再访问(如微博热搜)。为了解决这个问题,Redis记录了每个key最后一次被访问的时间,随着时间的推移,如果某个key再没有被访问过,计数器的值也会逐渐降低。
2、新生key问题,对于新加入缓存的key,因为还没有被访问过,计数器的值如果为0,就算这个key是热点key,因为计数器值太小,也会被淘汰机制淘汰掉。为了解决这个问题,Redis会为新生key的计数器设置一个初始值。
上面说过在Redis LRU算法中,会给每个key维护一个大小为24bit的属性字段,代表最后一次被访问的时间戳。在LFU中也维护了这个24bit的字段,不过被分成了16 bits与8 bits两部分:
16 bits 8 bits
±-------------------±-----------+
- Last decr time | LOG_C |
±-------------------±----------+
其中高16 bits用来记录计数器的上次缩减时间,时间戳,单位精确到分钟。低8 bits用来记录计数器的当前数值。
在redis.conf配置文件中还有2个属性可以调整LFU算法的执行参数:lfu-log-factor、lfu-decay-time。其中lfu-log-factor用来调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。lfu-decay-time是一个以分钟为单位的数值,用来调整counter的缩减速度。
其他场景对过期key的处理
1、快照生成RDB文件时
过期的key不会被保存在RDB文件中。
2、服务重启载入RDB文件时
Master载入RDB时,文件中的未过期的键会被正常载入,过期键则会被忽略。Slave 载入RDB 时,文件中的所有键都会被载入,当主从同步时,再和Master保持一致。
3、AOF 文件写入时
因为AOF保存的是执行过的Redis命令,所以如果redis还没有执行del,AOF文件中也不会保存del操作,当过期key被删除时,DEL 命令也会被同步到 AOF 文件中去。
4、重写AOF文件时
执行 BGREWRITEAOF 时 ,过期的key不会被记录到 AOF 文件中。
5、主从同步时
Master 删除 过期 Key 之后,会向所有 Slave 服务器发送一个 DEL命令,Slave 收到通知之后,会删除这些 Key。
Slave 在读取过期键时,不会做判断删除操作,而是继续返回该键对应的值,只有当Master 发送 DEL 通知,Slave才会删除过期键,这是统一、中心化的键删除策略,保证主从服务器的数据一致性。
FAQ
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
Ref
https://blog.csdn.net/yuanlong122716/article/details/104420880