
大数据产业创新服务媒体
——聚焦数据 · 改变商业
近日,以“数智聚力,共赴新程”为主题的2023网易数字+大会在杭州召开。在这次大会上,数据猿采访了网易副总裁、网易数帆总经理汪源,网易数帆大数据产品线总经理余利华,对网易数帆的最新发展策略和数据技术产品体系有一个全面的了解。

网易副总裁、网易数帆总经理汪源
在这次大会上,网易数帆进一步阐述DataOps方法论,介绍了数据开发治理平台EasyData的新功能,发布了指标中台EasyMetrics,以及ChatBI的最新功能。接下来,我们就网易数帆的一系列新品进行分析,并探索他们隐藏的关系。
EasyData,降低数据开发治理门槛
数据开发治理的实践中,开发者常常需要面对一系列复杂且多维的挑战。具体来看:
随着数据源和格式的日益多样化,技术人员必须掌握各类系统和工具的特性,同时还要跟上数据库技术的迅猛发展步伐。数据质量的确保变成了一场与数据错误、重复和不完整性的持久战,且治理工作往往难以自动化,消耗了大量的人力资源。数据安全性与合规性的要求也在不断变化,为开发团队增添了合规性调整的压力。与此同时,系统的性能和扩展性受数据量激增的挑战,需要不断优化以支撑大数据时代的需求。
此外,SQL脚本和数据模型的持续维护是保持治理效率和质量的关键,但往往由于缺少标准化和自动化,使得新团队成员难以快速上手。技术债务的积累,可能导致在未来的开发和维护中需要支付更高的代价。
正是因为这些难点,提高了数据开发治理的门槛,让从业人员苦不堪言。
为了降低数据开发门槛,网易数帆EasyData数据开发治理平台进行了一系列的创新。比如,新增了可视化开发的新组件,可视化开发组件内置100+高性能算子,实现72%的数据开发覆盖率,能够使得数据开发成本降低25%;“SQL Scan”阻隔问题代码,旨在解决低质量代码导致线上数据故障时有发生的问题。
此外,尤其值得关注的是,为了解决SQL编写中存在的问题,网易数帆将大模型技术引入数据开发治理领域,推出SQL补全领域大模型,并在此基础上研发SQL Copilot。该产品的特点包括:

1、高质量训练数据集
高质量的训练数据集,是SQL Copilot大模型表现出色的关键因素之一。SQL Copilot所使用的数据集,覆盖了从开源社区到专业业务场景的各种SQL脚本。
这些数据集的多样性,确保了模型能够理解广泛的查询模式和结构,而特定业务场景的数据,则让模型更好地适应特定的应用需求。模型训练时引入的库表元数据,进一步增强了这种适应性,让SQL Copilot不仅仅是在语法层面上提供帮助,更能够在逻辑和语义层面上提供深入的支持。
2、优秀的SQL代码补全能力
在实际应用中,编写SQL语句不仅涉及对语法的理解,还需要对数据库的结构和业务逻辑有深刻的认识。传统的IDE和代码编辑器通常只提供了基础的语法提示和错误检查功能,而缺乏对于开发者意图的深层理解。
SQL Copilot通过大模型技术,理解和学习了SQL的语法结构。不同于Token级的补全,SQL Copilot还可以在行级甚至代码块级别提供建议,这意味着它能够理解更长的代码序列和更复杂的代码逻辑。
SQL Copilot的另一个显著特点,是对多种SQL语法的支持。在当前的大数据生态中,不同的技术栈可能会使用不同的SQL语法,如Hive、Spark、Impala等。SQL Copilot通过训练模型覆盖了这些语法,能够无缝切换并提供针对性的补全建议。
据网易数帆大数据产品线总经理余利华介绍,目前,SQL Copilot的代码采纳率已显著超过20%,并且还在持续提升。

易数帆大数据产品线总经理余利华
3、低成本
从部署角度看,SQL Copilot的高效性也体现在其低成本上。相对于需要大规模计算资源的某些大模型,SQL Copilot的运行仅需要两张消费级显卡,大幅降低了对硬件的需求。这使得即便是资源有限的小型企业或个人开发者,也能够享受到AI增强的编程辅助。
4、低时延
在实时编程辅助方面,SQL Copilot同样表现出色。其推理速度优于一般的自然语言处理模型如ChatGPT,为用户提供快速响应的同时,确保了SQL编写的流畅性和实时性。低延迟的特性,对于开发者在构建复杂查询和进行问题排查时尤为关键。
SQL Copilot的出现,不仅是技术上的突破,也预示着数据开发治理方式的变革。通过降低学习门槛和提升开发效率,它为数据开发治理的一体化和自动化提供了强大的技术支持。在推动DataOps创新实践的过程中,SQL Copilot成为了一个不可或缺的工具,它不仅提高了数据开发治理的智能水平,也为企业提供了更加灵活、高效的数据处理能力。
EasyMetrics,一次定义、多次复用的指标中台
在企业数据管理中,指标是评价业务性能和决策支持的关键。但多数企业在指标管理方面存在一些普遍问题,尤其是业务口径不一致、指标入口不统一和需求响应慢,这些问题严重影响了企业的决策效率和数据管理的准确性。
业务口径不一致的问题,常常源于企业内部多个部门或团队独立定义和计算指标,缺乏统一的标准和平台。当同一个指标在不同团队中有不同的定义和计算方法时,会导致数据解读的混乱和决策的错误。
指标入口不统一则表现在数据来源分散,缺乏一个集中的查询和管理平台。用户需要从不同的系统收集和整理数据,进行多次转换和对比,才能得到所需的指标,这无疑增加了工作量,也增加了出错的概率。
需求响应慢则是在快速变化的商业环境中,数据需求变化迅速,但传统的数据处理流程往往冗长,从需求提出到数据处理完成,往往需要数周甚至数月的时间,这使得数据无法在关键时刻为决策提供支持。
针对这些问题,网易数帆发布的EasyMetrics指标中台,提供了创新的解决方案。EasyMetrics通过建立一个统一的指标定义平台,解决了业务口径不一致的问题。它允许用户在中台定义指标,并自动同步到所有数据系统中,确保了各部门和团队使用的是统一口径的数据。这不仅提高了数据的一致性,也节省了大量之前用于沟通协调的时间和精力。
对于指标入口不统一的问题,EasyMetrics提供了一个集中的指标库,用户可以在一个统一的界面查询所有指标,无需切换不同的系统和工具。这大大提高了工作效率,也降低了错误发生的风险。
至于需求响应速度慢的问题,EasyMetrics通过自动化的数据流程和智能化的指标计算,大大加快了从需求提出到完成的周期,使企业能够更快速地做出基于数据的决策。
此外,EasyMetrics通过引入指标查询语言,为用户提供了一种更为高效和直观的数据查询方式。而引擎解耦设计确保了系统的高性能和可扩展性,可以快速适应不同数据源和计算需求的变化。与ChatBI智能问答系统的结合,更是让数据的查询和分析变得像聊天一样简单。
根据网易数帆的客户实践案例,指标中台EasyMetrics可以更好地解决了指标口径不一致的问题,实现了数据开发平均周期缩短3-5天,开发人力消耗减少30%。随着数据管理需求的日益复杂化和细化,EasyMetrics的这种创新性解决方案,无疑将为更多企业在数据治理的道路上提供重要的助力。
数据开发治理平台和指标中台,有效提升了数据质量,为上层的数据分析应用奠定了坚实的基础。在此之上,网易数帆的ChatBI,则通过对话式数据分析方式,进一步降低数据消费的门槛。对于网易数帆的ChatBI产品,数据猿发布的《对话即数据分析,网易数帆ChatBI做到了》,进行了更深入的分析。
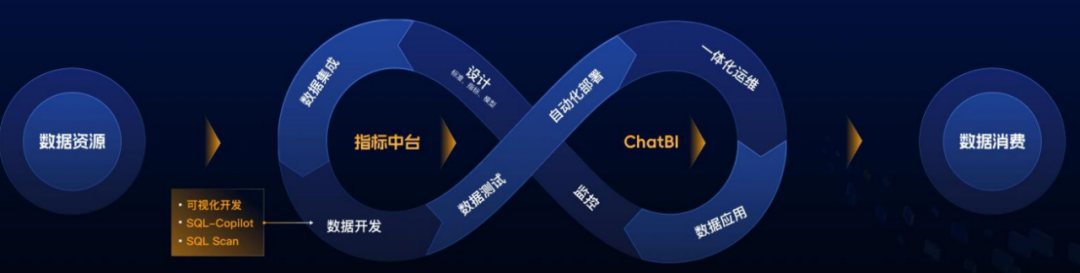
需要指出的是,网易数帆的数据开发治理平台EasyData、指标中台EasyMetrics、对话式分析平台ChatBI并不是孤立的,而是相互配合,构成一个推动数据消费的闭环。
首先,数据开发治理平台为企业提供了一个强大而灵活的工具,它可以帮助企业高效管理和维护数据。通过标准化流程和自动化工具,它能确保数据的质量和完整性,同时减少了人为错误和不必要的重复劳动。企业能够通过这个平台快速准确地提取和处理数据,确保数据的实时性和可靠性。
接下来,指标中台的建立,进一步强化了数据治理。通过中台定义和管理所有业务指标,企业能够实现指标的标准化和一致性,也保证了不同团队和部门的数据口径一致。此外,中台还能够跟踪指标的变化和使用情况,为企业提供数据治理的可视化,增强了决策支持系统的透明度。
网易数帆的ChatBI产品,是这一数据治理体系的前端应用。通过大模型技术,ChatBI允许用户通过对话来查询数据和生成报告,降低了数据分析的专业门槛。即使是非技术背景的用户也能轻松获取和理解数据,这使得数据分析和决策支持不再是少数数据专家的专利,而是整个组织的共同实践。
这三个产品的紧密配合,不仅仅实践了网易数帆DataOps的理念,也为企业数智化转型提供了一整套解决方案。通过更加精准和高效的数据治理,企业能够获得更深入的业务洞察,优化产品和服务,提高运营效率,创造新的商业价值。在这个基础上,企业能够更好地推动数据消费和数字经济的建设。

我们正站在一个新时代的门槛上,预示着大模型和大数据技术相互赋能、共同进步的广阔前景。企业和组织可以期待通过这种深度融合,实现数据资产的最大化利用。随着技术的迭代与创新,我们有理由相信,这一融合将赋予每个组织以前所未有的能力,帮助他们真正释放蕴藏在数据中的巨大价值。
文:一蓑烟雨 / 数据猿