❤️前言
大家好!这里是好久没有营业的大懒虫lion,今天要和大家聊的内容是我最近新学习的关于进程地址空间的相关知识。
正文
当我们使用C/C++语言进行内存管理时,经常会接触到这样的一张图片:
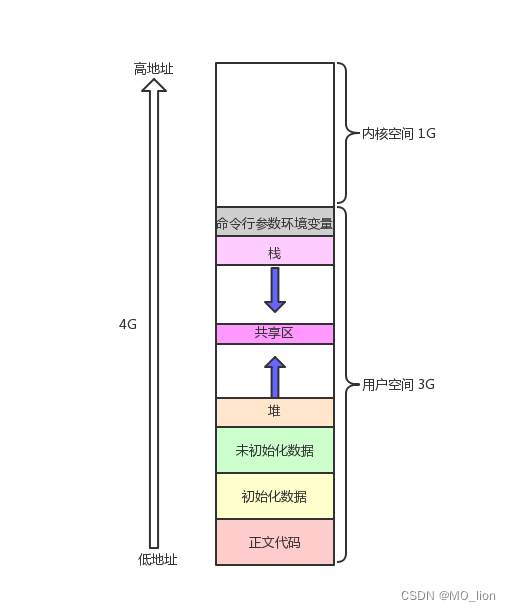
它常常被我们称作程序地址空间,在我们编写自己的代码时,都是在这样的内存布局的基础上进行思考,我们访问内存中定义的变量,访问内存中存储的代码数据……在我们的眼中,这样的空间布局似乎是真实存在于物理空间中,但是事实真的如此吗?
首先让我们来看看下面的这一段代码:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { //child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { //parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
//输出结果:
//与环境相关,观察现象即可
//parent[2995]: 0 : 0x80497d8
//child[2996]: 0 : 0x80497d8我们很容易就可以推断出这段代码的结果:当我们调用fork()函数产生一个子进程,这个子进程以父进程为模版,并且子进程并没有对全局变量进行修改。
那么让我们将这段代码稍加改动:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { //child,子进程肯定先跑完,也就是子进程先修改,完成之后,父进程再读取
g_val = 100;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { //parent
sleep(3);
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
//输出结果:
//与环境相关,观察现象即可
//child[3046]: 100 : 0x80497e8
//parent[3045]: 0 : 0x80497e8我们发现在子进程和父进程中,全局变量g_val的值不相同,但是地址却是一样的,这就和我们当初在语言层面上看待内存空间的视角有较大出入了(既然这个变量用的是同一个地址值进行存储,那么为什么在子进程和父进程中这个变量的值却会变得不同呢?)。
我们以之前的观念无法解释这样的问题,那么我们不妨做出这样的推论:这里的地址并不是真的物理地址,而是操作系统用某种方式将物理地址转化成的虚拟地址,事实也确实是这样,并且我们平时在使用C/C++编写代码时使用的地址也全部不是物理地址,而是操作系统所修饰出的虚拟/线性地址。
引入进程地址空间
当我们发现了这样的一种现象,单凭现有的知识概念已经无法对虚拟/线性地址有更详细的了解,也不能对这种现象进行更加深入的解释,那么我们便可以引入新的概念——进程地址空间,通过研究进程地址空间,从而初步理解这种现象。
我们所说的进程地址空间,其实就是上面所说的“程序地址空间”,但是相较来说,前者的描述更加准确。前者则是当我们学习了进程相关知识,在操作系统的层面上看待地址空间的描述方式,而后者是当我们在语言层面上编写代码、看待地址空间的描述方式。
我们都知道,当我们创建出一个进程,他们都会带有自己的内核数据结构,那么今天我们研究的进程地址空间,也便是进程自带的内核数据结构中的一种。当我们要对它进行管理,就需要对应的指针,对应的指针存于哪里呢?自然是存在于描述Linux进程信息的进程控制块——task_struct中。
当我们使用语言编写程序时是以统一的视角来看待内存空间,但是每个进程的task_struct不相同,进程地址空间也便是相互独立的,那么独立的每一个进程是如何做到以统一的视角看待内存的呢?
引入页表
这里我们又必须要提出一个新的内核数据结构——页表,通过页表,我们便可以完成上述的设计,那么上述的问题具体是如何解决的呢?
页表的主要作用是与对应进程的地址空间相配合,从而建立起线性地址与物理地址之间的映射关系,同时这种映射是由系统内核自己完成的。上述问题的解决方式简单来说就是:我们通过页表在线性地址与物理地址之间加上了一层映射关系,而且这种映射是由操作系统自己分配的,那么独立的每个进程在物理地址中存储的数据在正常情况下便不会发生冲突,这时每个进程便只需要看好自己的地址空间即可。
于是我们便了解到了线性地址与物理地址之间的相互关系,每个进程需要管理自己进程地址空间中的线性地址,而操作系统通过页表进行从线性地址到物理地址的映射对应操作。
现在我们可以反到上面去研究和解释父子进程中的全局变量问题。我们上面得出推论:全局变量g_val使用的并不是直接的物理地址,而是虚拟地址(线性地址),那么其中发生了哪些变化,最后的结果又是如何产生的呢?
我们可以画出如下的图像:
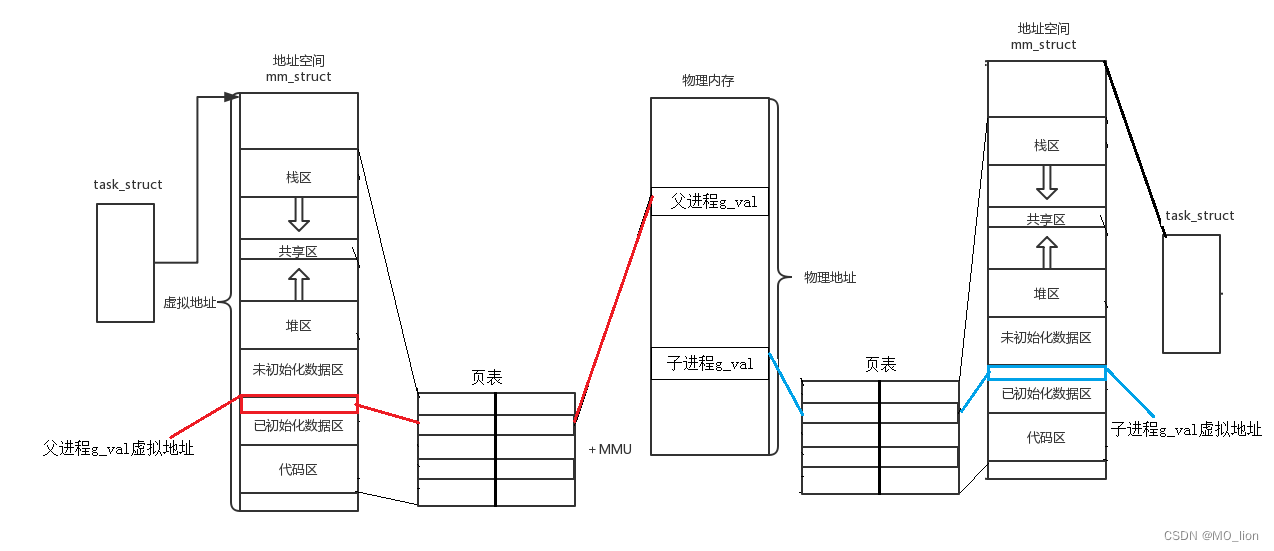
我们从代码进行到fork()后开始分析,父进程创建了一个新的子进程,这个子进程继承了父进程在创建它之前的所有代码操作,也就是地址空间和页表中存储的数据是一致的,也就是这两者目前的代码、变量在物理空间中其实是占用着相同的空间的。这里又新引入一个页表的行为:当子进程对先前的线性地址中的数据进行修改,那么此时就会发生写时拷贝,将另一块物理地址映射给当前的线性地址,但是不会将线性地址的值进行改变(也没有必要)。这样我们便可以理解这段代码的运行结果,这两个进程中的g_val其实不是同一个变量,它们所占的相同线性地址以页表对应映射出的物理地址是不同的,不同的物理地址中存储着不同的数据,于是最后打印出的结果便是相同的线性地址中存储着不同的值。
深入进程地址空间
进程地址空间究竟是什么?这可以通过我们早期对C语言指针的研究进行解释:以32位机器举例,简单来说就是将内存地址以32根数据总线的01信号进行二进制的编址,32根总线可以表示出2^32个不同的数字,对应着这么多单位的地址(一个单位即为一个字节),他们分别管理着对应的"内存",[0,2^32)也就是地址空间的地址范围。
那么如何理解进程地址空间中的区域划分呢?
地址空间中有许多不同的分区,这些区域的划分其实就是在一大块线性地址中划出一些分界线,以此就可以分出小块的具有不同数据和功能的区域。在进程地址空间对应的内核数据结构中其实就存储了许多不同的用于分界的数据,其中包括这个区域的起始地址和结尾地址等。
当我们需要调整修改地址空间中的区域划分,也就是只要对涉及的各个结构对象中的数据进行修改。
// 各个分区的结构体对象就类似如下结构:
struct area
{
int start;
int end;
// ...
};深入页表
进程地址空间中的不同区域往往含有不同的属性,存储着不同性质的数据(只读、读写),这样的情况显然不是简单的区域划分就可以做到的,那么我们现在来探讨操作系统如何做到这点。
进程地址空间需要页表与物理地址相勾连,那么操作系统便可以在这中间的操作中加以限制,从而进行不同分区数据的管理。
事实上,页表中除了线性地址和物理地址的映射关系以外,还存有对应线性地址的数据读写权限,这样当进程想要修改某个内存中的数据时便可以进行先一步的识别,如果这一块内存不能修改,那就会进行报错。也就是说物理内存本身其实是没有所谓的分区、读写权限的概念的,所有的这些都是在上层进行设计的,都是由操作系统内核限定和操作的。
使用地址空间和页表的好处
- 让进程以统一的视角看待内存。
- 使用进程地址空间和页表可以让我们在访问内存的时候增加一个过程,在这个过程中我们可以对访问内存的行为做检查,错误的访问将不会到达物理内存,这样就保护了物理内存。
- 有了进程地址空间和页表,我们可以做到将进程管理模块和内存管理模块进行解耦合。
🍀结语
以上就是最近接触到的关于进程地址空间和页表的一些知识,希望能帮助到阅读此篇博客的读者。