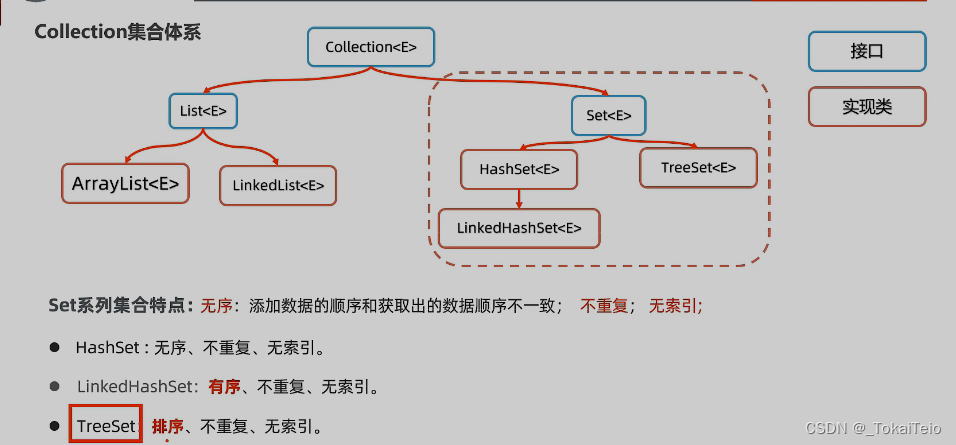
Set集合的特点
Set(集合)是一种无序的、不重复的数据结构,它的特点如下:
1. 集合中的元素是无序的:Set 中的元素没有顺序,无法通过索引来访问。
2. 集合中的元素是唯一的:Set 中不允许有重复的元素,每个元素在集合中只能出现一次。
3. 内部实现采用哈希表或树形结构:Set 内部通常是基于哈希表或平衡树等数据结构实现的。
4. 可以用于去重和快速查找:因为 Set 中的元素是唯一的,所以可以很方便地用来做去重操作。同时,由于内部实现采用哈希表或树形结构,所以查找某个元素的时间复杂度为 O(1) 或 O(log n)。
5. Set 中的元素必须是可哈希的:由于 Set 中的元素是基于哈希表实现的,所以集合中的元素必须是可哈希的,即元素必须有一个明确的哈希值。如果一个元素没有哈希值,那么它就不能被用作 Set 的元素。
注意:
Set要用到的常用方法,基本上就是Collection提供的!自己几乎没有额外新增一些常用方法!
练习代码
import java.util.Set;
import java.util.TreeSet;
public class Test_set {
public static void main(String[] args) {
//1.创建一个set集合对象
//HashSet:无序,不重复,无索引
//Set<Integer> set = new HashSet<>(); //创建了一个HashSet的集合对象 一行经典代码
//LinkedHashSet:有序,不重复,无索引
//Set<Integer> set = new LinkedHashSet<>(); //创建了一个LinkedHashSet的集合对象
//TreeSet:可排序(默认升序),不重复,无索引
Set<Integer> set = new TreeSet<>(); //创建了一个TreeSet的集合对象
set.add(666);
set.add(555);
set.add(555);
set.add(888);
set.add(888);
set.add(777);
set.add(777);
System.out.println(set);
}
}哈希值
在学习HashSet集合的底层原理之前,我们先来了解一下什么是哈希值↓↓↓
概念
哈希值(Hash Value)是指将任意长度的数据映射为固定长度的值,通常用一个整数或固定长度的字节数组表示。哈希值也被称为散列值(Hash Code)或摘要(Digest)。
特点
在计算机领域,哈希值经常用于数据的存储、索引和加密等操作。它具有以下特点:
1. 哈希值是固定长度的:无论输入数据的长度是多少,哈希函数都会生成固定长度的哈希值。例如,常见的哈希算法 MD5 生成的哈希值为 128 位,SHA-1 的哈希值为 160 位。
2. 输入数据的微小改变会导致哈希值的巨大变化:只需改变输入数据的微小部分,哈希值就会发生巨大的变化。这种特性称为"雪崩效应",使得哈希值在校验数据的完整性时非常有用。
3. 哈希值一般是不可逆的:通常情况下,根据哈希值无法推导出原始数据的内容。哈希函数设计成使得产生相同哈希值的原始数据非常困难。
4. 相同的输入数据生成相同的哈希值:哈希函数对于相同的输入数据总是生成相同的哈希值,这方便进行数据的存储和比较。
5. 哈希值的分布应该均匀:良好的哈希函数应该能够将输入数据均匀地映射到哈希值空间,尽量避免碰撞(多个不同的输入数据生成相同的哈希值)。

java中Object类提供的public int hashCode()方法可以返回对象的哈希码值。
HashSet集合的底层原理
在 HashSet 中,元素被存储在一个 HashMap 的实例中,其中元素的值作为键(key),而键的哈希值(通过调用元素的 hashCode() 方法)则用来确定元素在哈希表中的位置。当要将一个元素加入 HashSet 时,HashSet 会首先计算该元素的哈希值,然后找到对应的存储位置。如果该位置上已经存在了元素,HashSet 会使用 equals() 方法来检查这两个元素是否相等,如果相等则认为是重复元素,不会将其加入集合。

简单来说,HashSet 的底层原理是基于哈希表实现的,使用哈希值来快速查找元素,并提供了高效的添加、删除和查找操作。
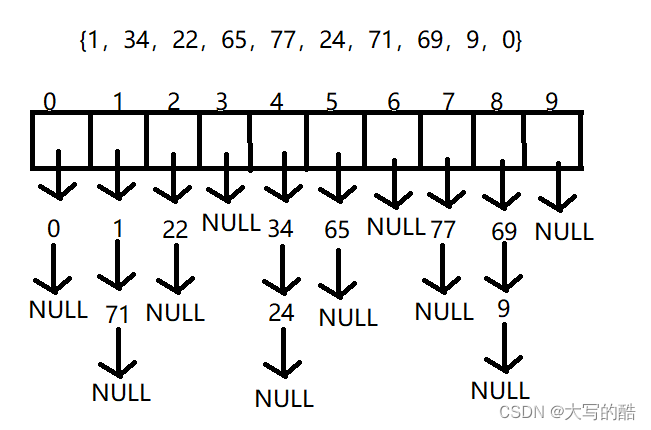
哈希表
既然HashSet集合是基于哈希表实现的,那么我们就来学习下哈希表↓↓↓
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。

实现去重复

先来看一段代码
import java.util.HashSet;
import java.util.Set;
public class Test {
public static void main(String[] args) {
//深入了解HashSet的去重复机制
Set<Student> students = new HashSet<>();
Student st1 = new Student("至尊宝",18,167.5);
Student st2 = new Student("蜘蛛精",22,169.8);
Student st3 = new Student("蜘蛛精",22,169.8);
Student st4 = new Student("牛魔王",19,183.5);
students.add(st1);
students.add(st2);
students.add(st3);
students.add(st4);
System.out.println(students);
}
}运行一下

这里面有两个内容相同的不同对象st1和st2,那么HashSet集合默认是不能去重复的。在实际操作中,我们希望只留下一个对象来表示,该怎么做呢?
//内容一样的两个对象,HashSet认为他们是不重复的 /* 如果希望Set集合认为两个内容一样的对象是重复的,必须重写对象的hashcode()和equals()方法 */
我们可以去Student类中重写hashcode()和equals()方法
import java.util.Objects;
public class Student {
private String name;
private int age;
private double height;
public Student() {
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(height, student.height) == 0 && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
}这样就只会有一个蜘蛛精留下了↓

篇幅问题,这篇博客到此结束了,下一篇文章我会详细介绍JDK8前后的两种哈希表,需要的朋友可以留意一下~



![11.把学生的信息 (学号,姓名,性别,住址) 放入结构体[???]](https://img-blog.csdnimg.cn/b9e89df01a31406398aa9fecaaa6cedb.png)