如何用devtools快速开发一个R语言包?
- 1. 准备工作
- 2. 如何完整开发一个R包
- 3. 初始化新包
- 4. 启用Git仓库
- 5. 按照目标实现一个函数
- 6. 在.R文件夹下创建文件并保存代码
- 7. 函数测试
- 8. 阶段性总结
- 9. 时不时地检查完整工作状态
- 10. 编辑DESCRIPTION文件
- 11. 配置许可证
- 12. 配置帮助文档
- 12.1 更新NAMESPACE
- 13. 再次检查
- 14. 安装并手动测试
- 15. 单元测试
- 16. 配置依赖包以及修改的流程
- 17. 同步到github
- 18. 配置readme
- 19. 收尾
- 20. 总览回顾

资源在这https://r-pkgs.org/,标记自取。
以下内容中黄色字体是关键流程和注意要点。
1. 准备工作
library(devtools) 可以从任何活动的R会话初始化新包。你不需要担心你是否在一个现有的或新的项目中。
> library(devtools)
载入需要的程辑包:usethis
Warning messages:
1: 程辑包‘devtools’是用R版本4.2.3 来建造的
2: 程辑包‘usethis’是用R版本4.2.3 来建造的
为了避免版本不同而导致和本教程有所出入,请检查版本:
> packageVersion("devtools")
[1] ‘2.4.5’
2. 如何完整开发一个R包
为了完成开发包的整个过程,我们将使用devtools中的各种功能从头开始构建一个小的玩具包,其中包含了已发布包中常见的功能:
- 用于满足特定需求的函数,在本例中是用于处理正则表达式。
- 版本控制和开放的开发过程。
- 这在您的工作中是完全可选的,但强烈推荐。您将看到Git和GitHub如何帮助我们公开玩具包的所有中间阶段。
- 访问已建立的工作流程,以进行安装、获取帮助和检查质量。
- 单个功能的文档通过roxygen2。
- 使用testthat进行单元测试。
- 通过可执行文件README.Rmd获得整个包的文档。
我们这里创建的包并没有多大用处,只是用来演示使用devtools进行包开发的典型工作流。
3. 初始化新包
调用 create_package() 初始化计算机上目录中的新包。如果该目录还不存在(通常是这种情况),Create_package()将自动创建该目录。
- 慎重选择在计算机上的什么位置创建这个包。
- 它应该在您的主目录中,与其他R项目放在一起。
- 它不应该嵌套在另一个RStudio项目、R包或Git仓库中。
- 它也不应该在R包库中,其中包含已经构建和安装的包。
- 将我们在这里创建的源包转换为已安装的包是devtools的一部分。不要试图做devtools的工作!
一旦你选择了在哪里创建这个包,将你选择的路径替换为create_package()调用,如下所示:
> create_package("~/regexcite")
✔ Creating 'C:/Users/bailo/regexcite/'
✔ Setting active project to 'C:/Users/bailo/regexcite'
✔ Creating 'R/'
✔ Writing 'DESCRIPTION'
Package: regexcite
Title: What the Package Does (One Line, Title Case)
Version: 0.0.0.9000
Authors@R (parsed):
* First Last <first.last@example.com> [aut, cre] (YOUR-ORCID-ID)
Description: What the package does (one paragraph).
License: `use_mit_license()`, `use_gpl3_license()` or friends to
pick a license
Encoding: UTF-8
Roxygen: list(markdown = TRUE)
RoxygenNote: 7.2.3
✔ Writing 'NAMESPACE'
✔ Writing 'regexcite.Rproj'
✔ Adding '^regexcite\\.Rproj$' to '.Rbuildignore'
✔ Adding '.Rproj.user' to '.gitignore'
✔ Adding '^\\.Rproj\\.user$' to '.Rbuildignore'
✔ Opening 'C:/Users/bailo/regexcite/' in new RStudio session
✔ Setting active project to '<no active project>'
如果你在RStudio中工作,你会发现自己在一个新的RStudio实例中,打开你的新regexcite包(和Project)。如果您需要手动执行此操作,请导航到该目录并双击regexcite.Rproj。
您可能需要再次调用库(devtools),因为create_package()可能已经将您放入新包中的新R会话中。
比如,运行create_package(“~/regexcite”)的RStudio中:
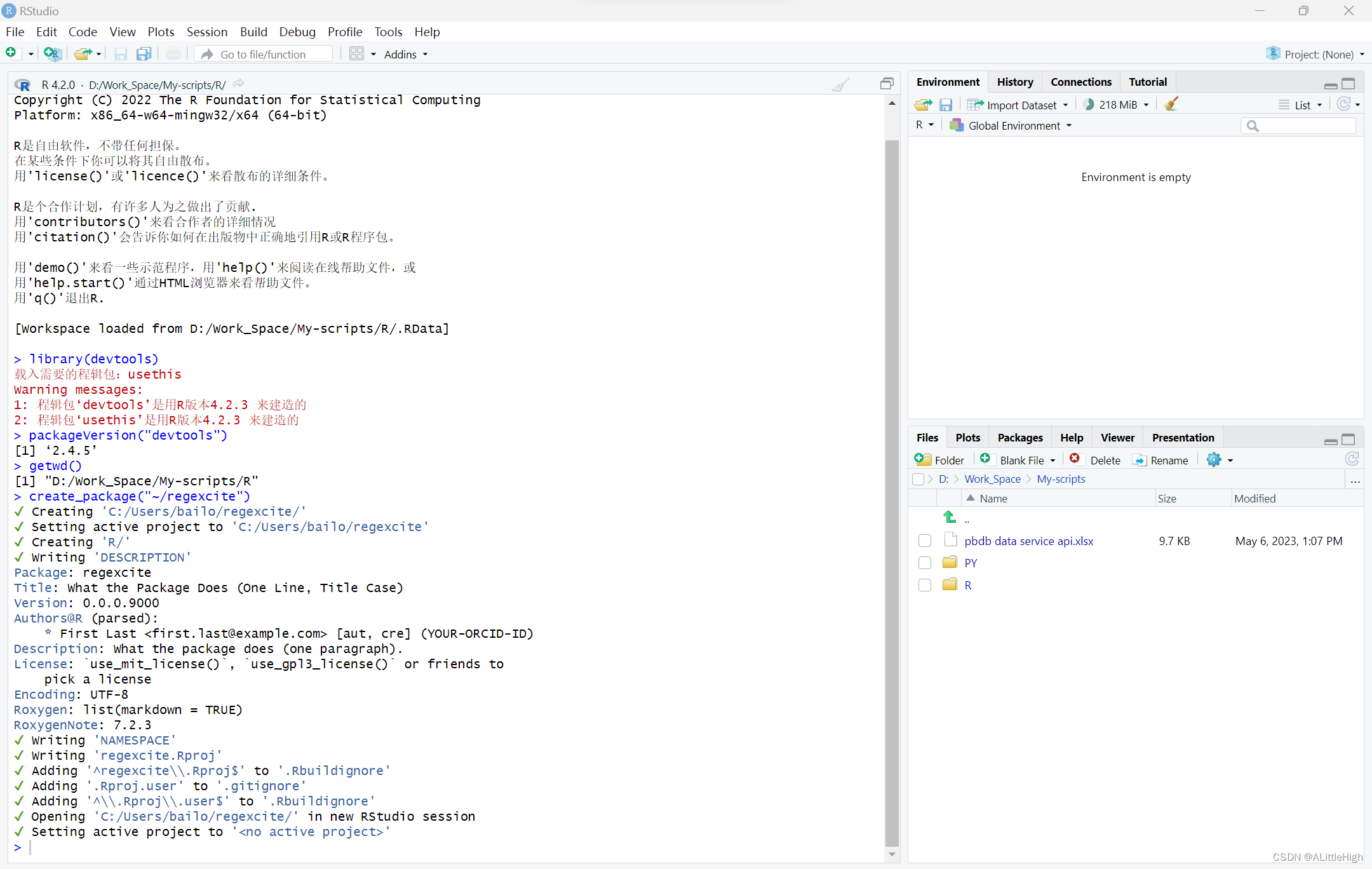
运行接受,除了在控制台显示结果外,还自动打开了新包的RStudio窗口:
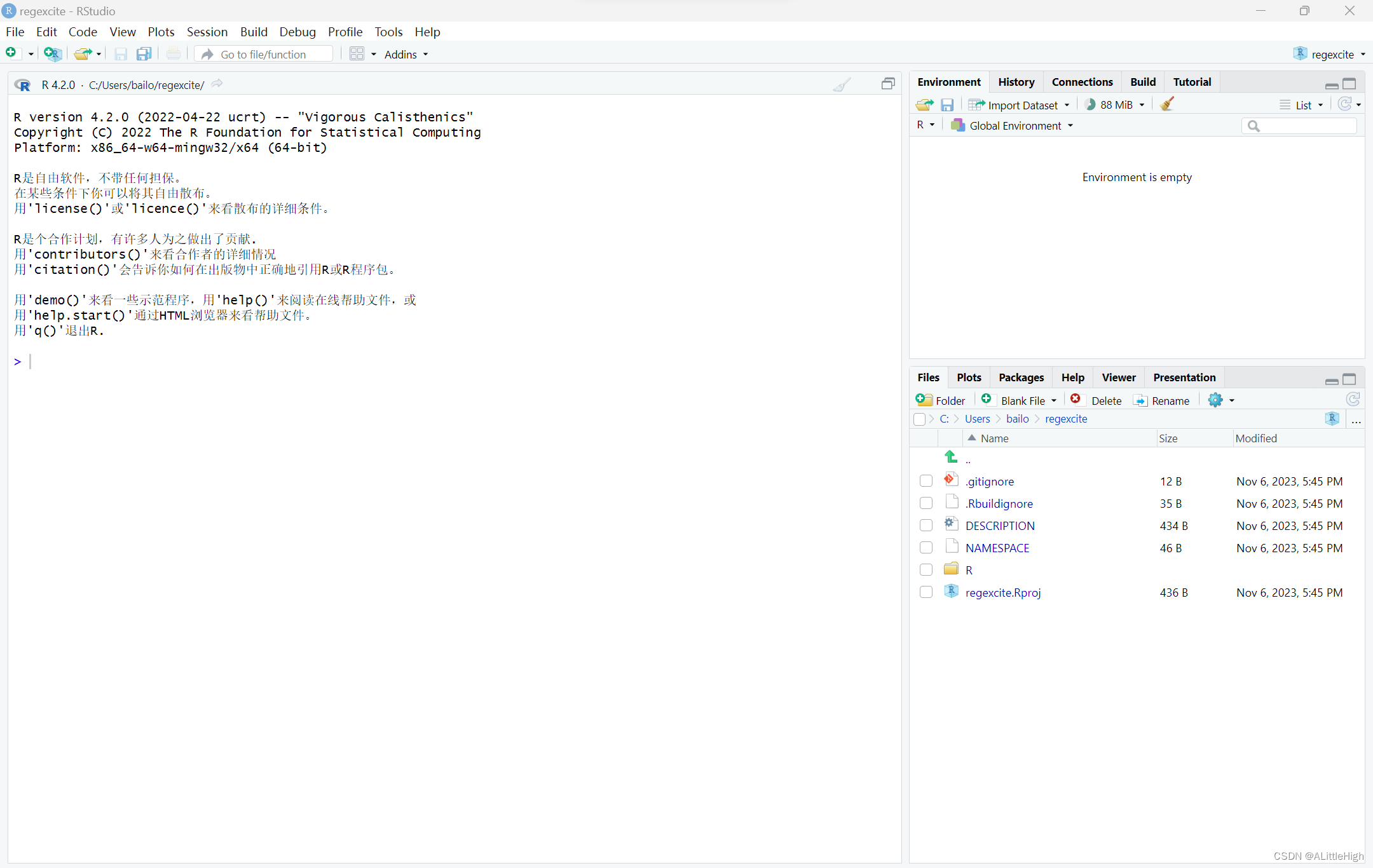
故此,在新包的RStudio窗口中,需要重新调用库(devtools)。
> library(devtools)
载入需要的程辑包:usethis
Warning messages:
1: 程辑包‘devtools’是用R版本4.2.3 来建造的
2: 程辑包‘usethis’是用R版本4.2.3 来建造的
新包目录里的内容如下:
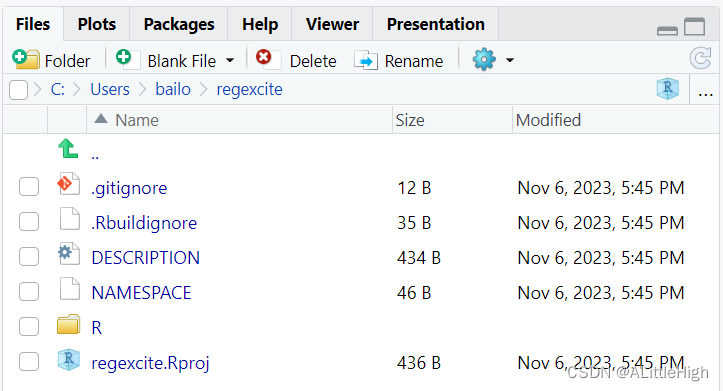
- .Rbuildignore列出了我们需要但在从源代码构建R包时不应该包含的文件。如果你没有使用RStudio, create_package()一开始可能不会创建这个文件(也不会创建.gitignore),因为没有RStudio相关的机制需要被忽略。然而,无论您使用的是什么编辑器,您都可能在某些时候开发出对. rbuildignore的需求。
- .Rproj.user(如果有的话)是RStudio内部使用的目录(我这里就没有)。
- .gitignore预测了Git的使用,并告诉Git忽略一些由R和RStudio创建的标准的幕后文件。即使您不打算使用Git,这也是无害的。
- DESCRIPTION提供有关包的元数据。
- NAMESPACE声明包导出供外部使用的函数,以及包从其他包导入的外部函数。在这一点上,它是空的,除了一个注释声明这是一个您不应该手工编辑的文件。
- R/目录是包的“业务端”。它将很快包含带有函数定义的. r文件。
- regexcite.Rproj是使该目录成为RStudio项目的文件。即使你不使用RStudio,这个文件也是无害的。或者你可以用create_package(…), rstudio = FALSE)。
4. 启用Git仓库
regexcite目录是一个R源码包和一个RStudio项目。现在我们使用 use_git() 将它变成一个Git存储库。
在交互式会话中,系统将询问您是否要在这里提交一些文件,以及您是否应该接受该提议。
再次接受立即重启RStudio。
那么一步对包有什么变化呢?只需要创建一个git目录,它在大多数上下文中是隐藏的,包括RStudio文件浏览器。它的存在证明我们确实在这里初始化了一个Git仓库。
上面可以看到RStudio里是看不到git目录的,而在电脑的文件浏览器中可以看到。

5. 按照目标实现一个函数
这里是开发R包的核心,但不管多复杂也只是开发流程的一步。这里用简单的一个函数示例。
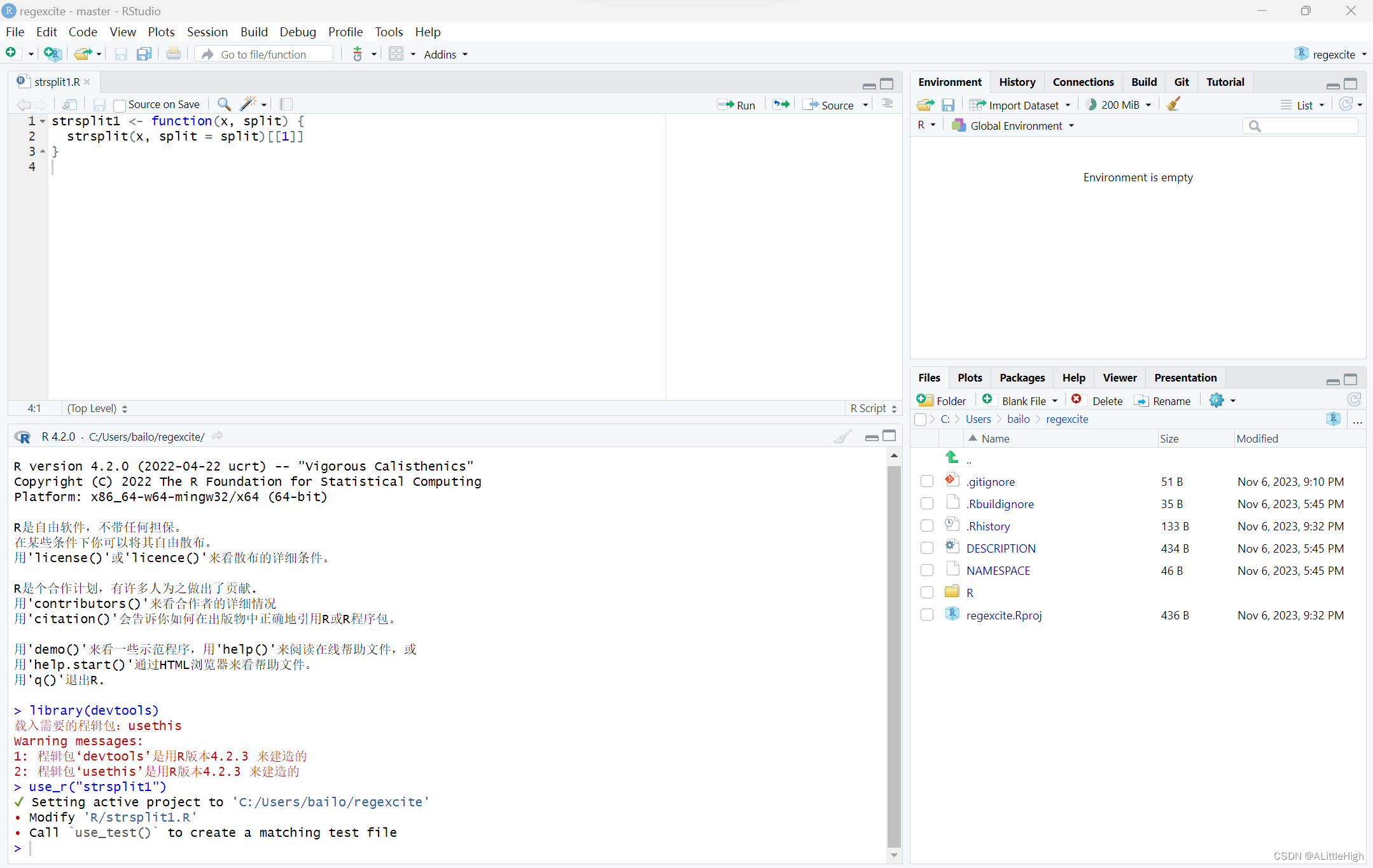
strsplit1 <- function(x, split) {
strsplit(x, split = split)[[1]]
}
6. 在.R文件夹下创建文件并保存代码
应该把strsplit1()的定义放在哪里?将它保存在包的R/子目录下的.R文件中。合理的起始位置是为包中每个面向用户的函数创建一个新的. r文件,并以该函数命名该文件。当您添加更多函数时,您将希望放松这一点,并开始将相关函数分组在一起。我们将strsplit1()的定义保存在文件R/strsplit1.R中。
帮助器 use_r() 在R/下创建和/或打开一个脚本。
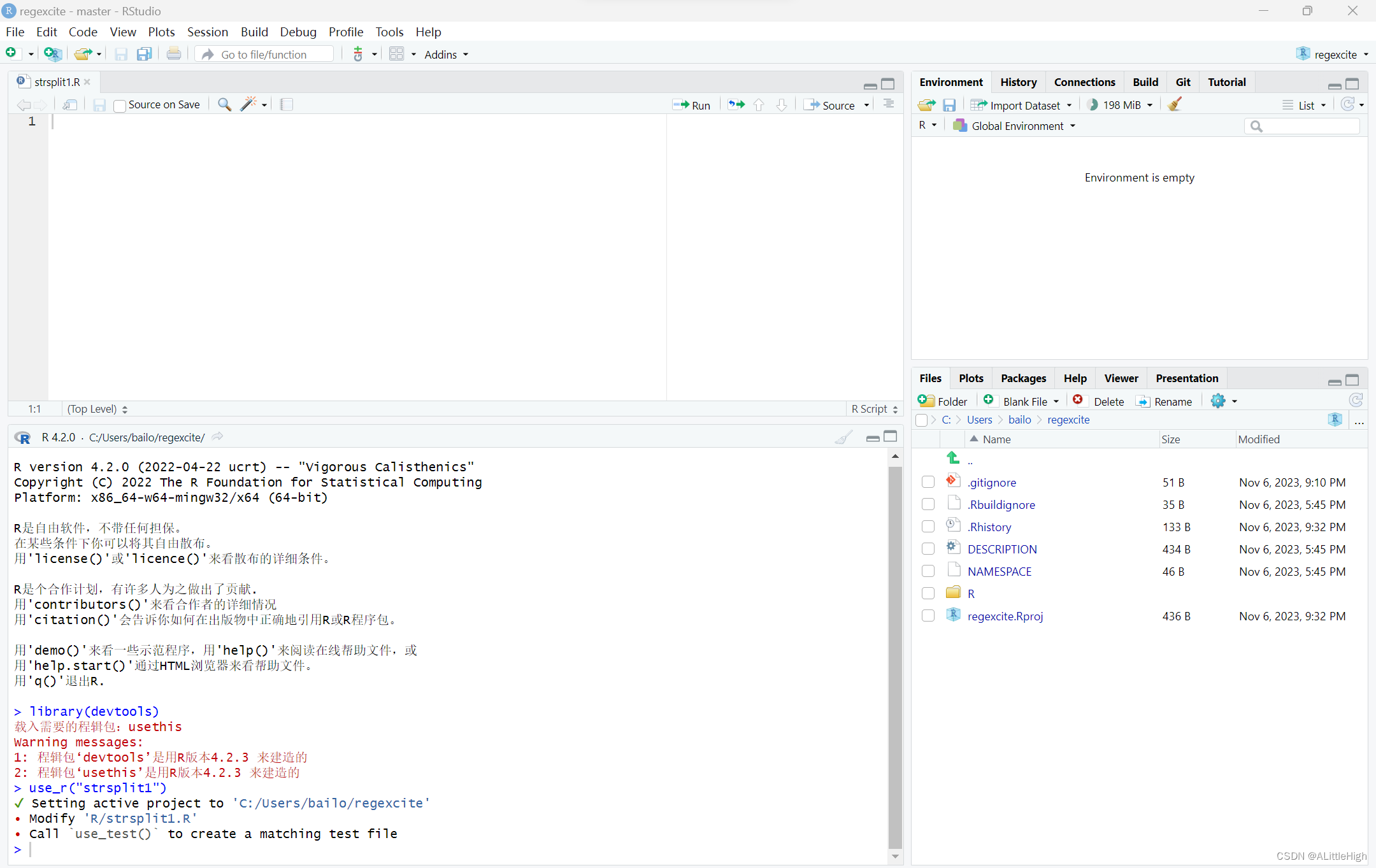
将上面的strsplit1()函数写入strsplit1文件中并保存。
7. 函数测试
我们如何测试驱动strsplit1()?如果这是一个普通的R脚本,我们可以使用RStudio将函数定义发送到R控制台,并在全局环境中定义strsplit1()。或者我们可以调用source(“R/strsplit1.R”)。然而,对于包开发,devtools提供了一种更健壮的方法。
调用 load_all() 使strsplit1()可用于测试。
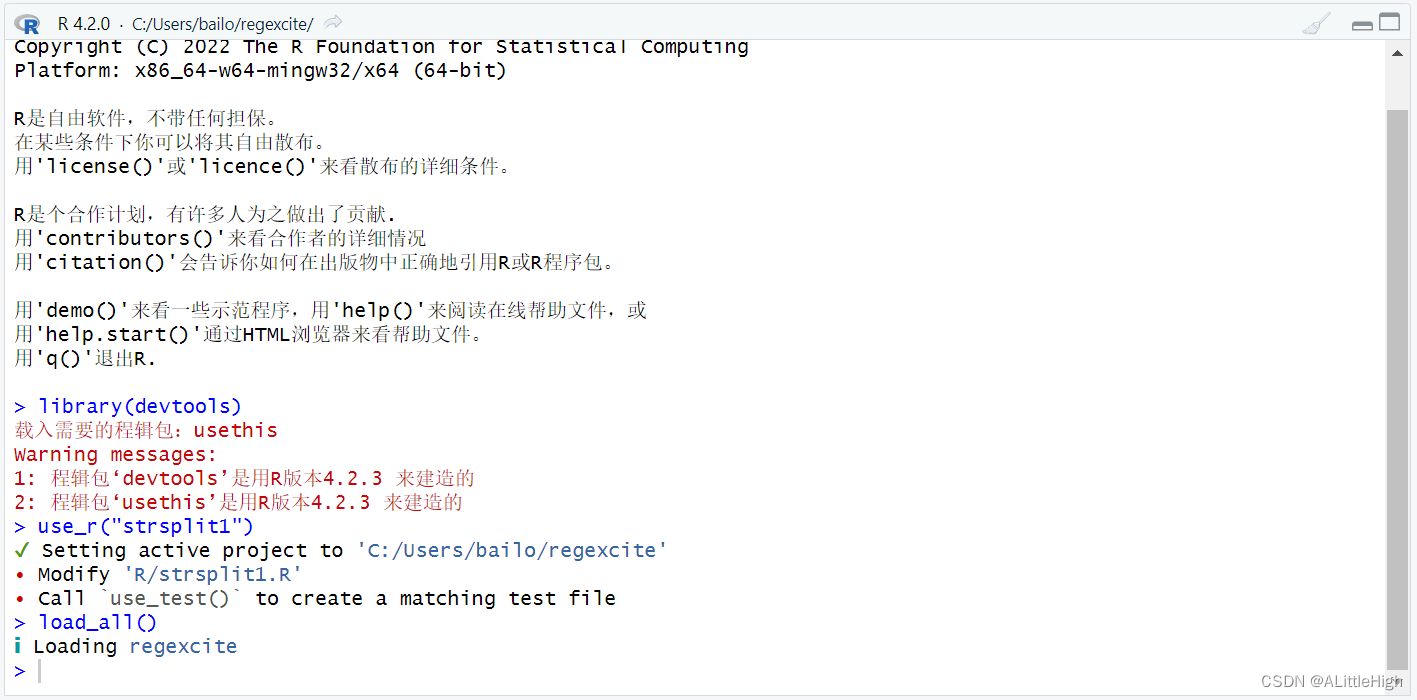
现在可以调用strsplit1()函数进行测试了。你可能会注意到strsplit1()函数虽然不在全局环境中,但此时仍可以调用它。
> (x <- "alfa,bravo,charlie,delta")
[1] "alfa,bravo,charlie,delta"
> strsplit1(x, split = ",")
[1] "alfa" "bravo" "charlie" "delta"
Load_all()模拟构建、安装和附加regexcite包的过程。随着您的包积累了更多的函数(有些导出,有些不导出),其中一些相互调用,其中一些调用您所依赖的包中的函数,load_all()使您能够比在全局环境中定义的测试驱动函数更准确地了解包的开发情况。此外,load_all()允许比实际构建、安装和附加包更快的迭代。
8. 阶段性总结
- 我们编写了第一个函数strsplit1(),并保存在对应的文件中。
- 我们使用load_all()快速地使这个函数可用于交互使用,就好像我们已经构建并安装了regexcite并通过library(regexcite)导入了一样。
9. 时不时地检查完整工作状态
我们有非正式的经验证据表明strsplit1()是有效的。但是,我们如何确保regexcite包的所有活动部分仍然工作呢?在这么小的增加之后,检查这个似乎很愚蠢,但养成经常检查这个的习惯是很好的。
在shell中执行的R CMD check是检查R包是否处于完全工作状态的黄金标准。check() 是在不离开R会话的情况下运行它的一种方便的方法。
注意,check()产生相当大的输出,并针对交互消费进行了优化。
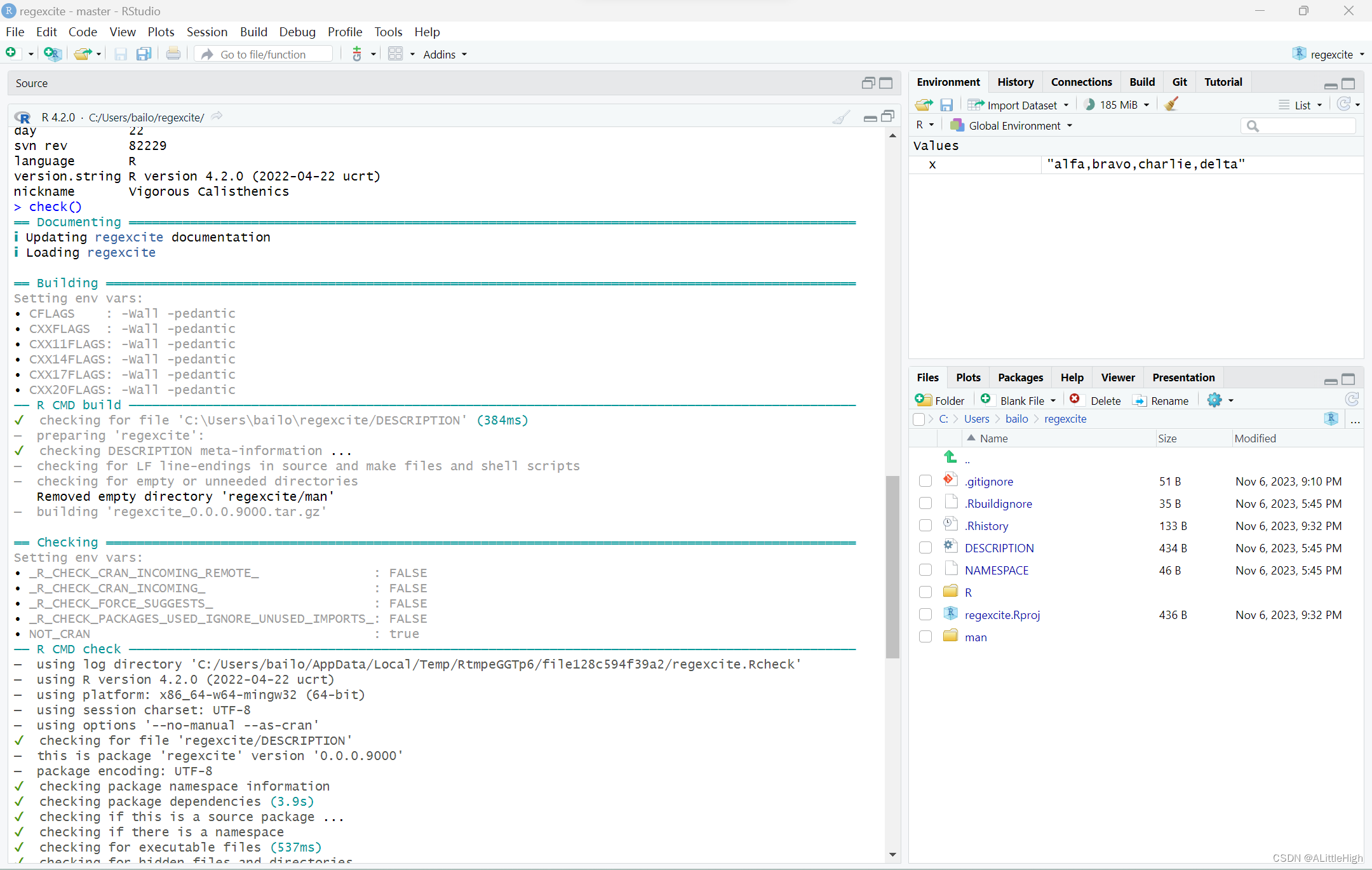
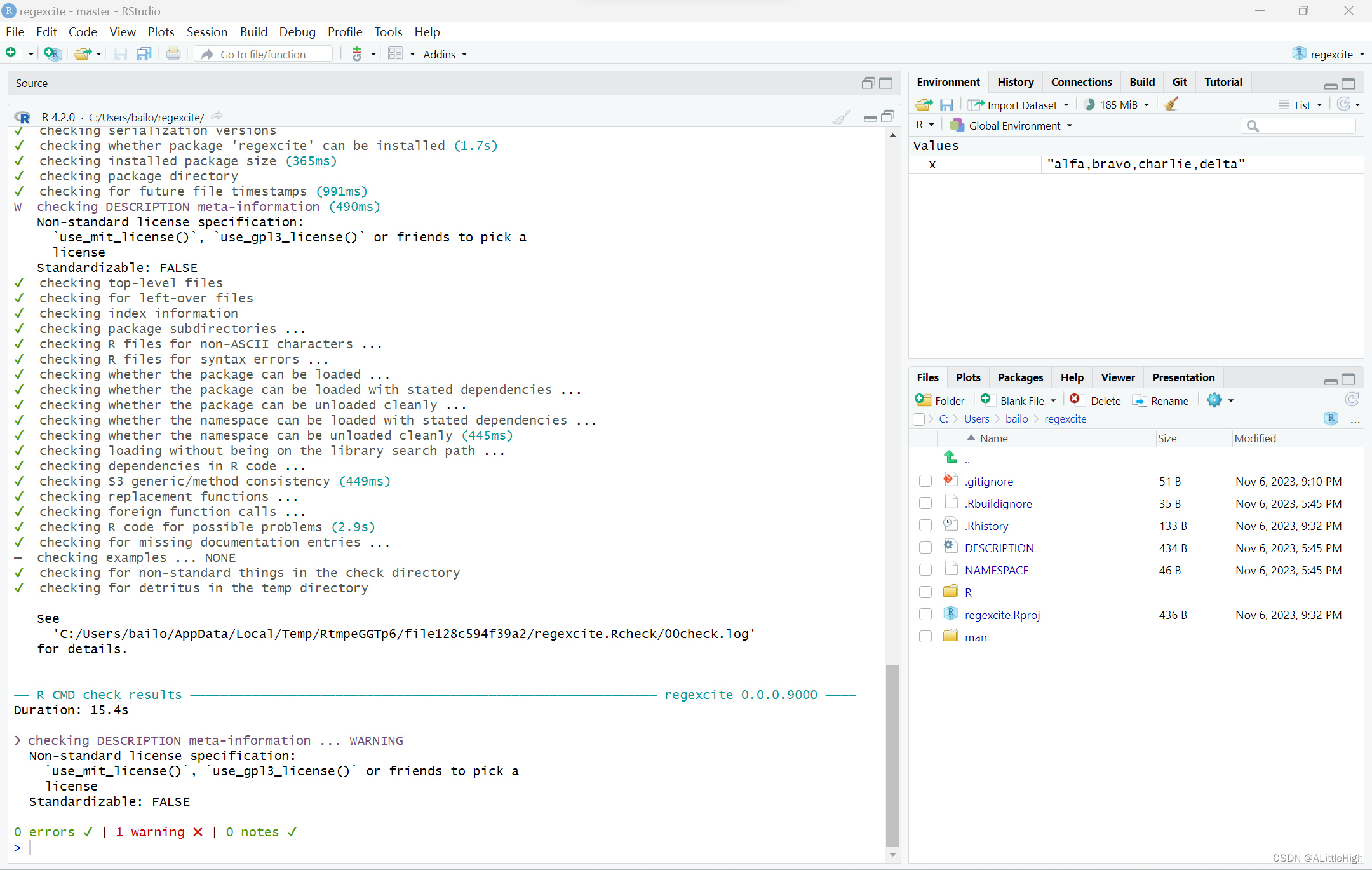
实际读取检查的输出是必要的!尽早、经常地处理问题。这就像是.R和.Rmd文件的增量开发。你检查每件事是否正常的时间间隔越长,就越难找到问题所在并解决问题。
10. 编辑DESCRIPTION文件
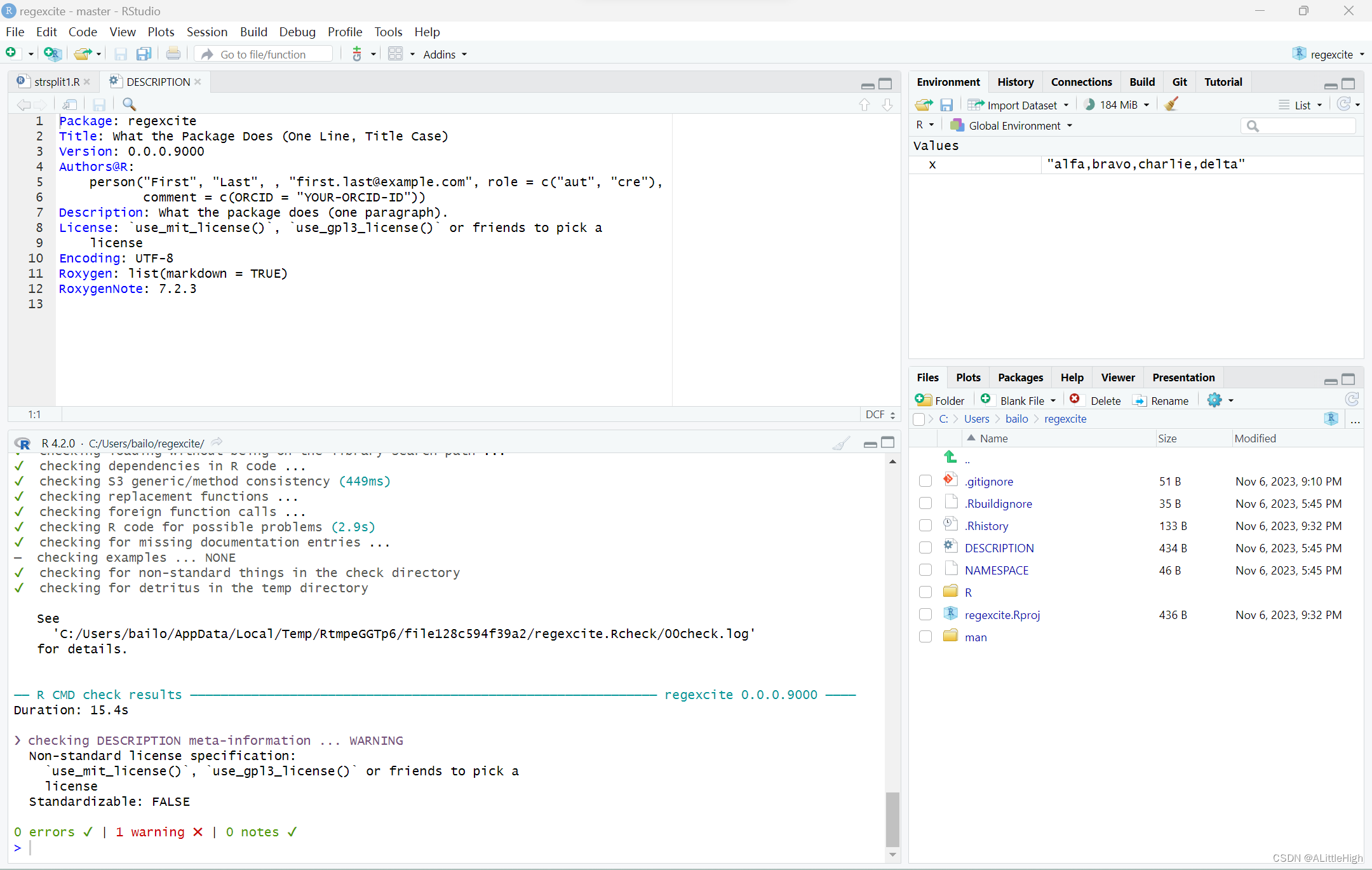
DESCRIPTION文件提供了关于你的包的元数据,现在是查看regexcite当前DESCRIPTION的好时机。您将看到它被填充了样板内容,这些内容需要替换。
要添加您自己的元数据,请进行以下编辑:
- 写上作者信息。如果没有ORCID,可以省略commit=…部分。
- 在Title和Description字段中写一些描述性的文字。
使用Ctrl + . 在RStudio中输入“DESCRIPTION”来激活一个帮助器,它可以很容易地打开一个文件进行编辑。除了文件名之外,提示还可以是函数名。当一个包有很多文件时,这是非常方便的。
DESCRIPTION文件打开后有模板,将信息对号入座即可:
11. 配置许可证
我们目前在DESCRIPTION的License字段中有一个占位符,它是故意无效的,并建议一个解决方案。
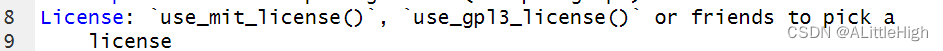
要为包配置有效的许可证,请调用 use_mit_license()。
> use_mit_license()
✔ Setting License field in DESCRIPTION to 'MIT + file LICENSE'
✔ Writing 'LICENSE'
✔ Writing 'LICENSE.md'
✔ Adding '^LICENSE\\.md$' to '.Rbuildignore'
这将为MIT许可证正确配置许可证字段,它承诺在许可证文件中命名版权所有者和年份。打开新创建的LICENSE文件,确认如下所示:
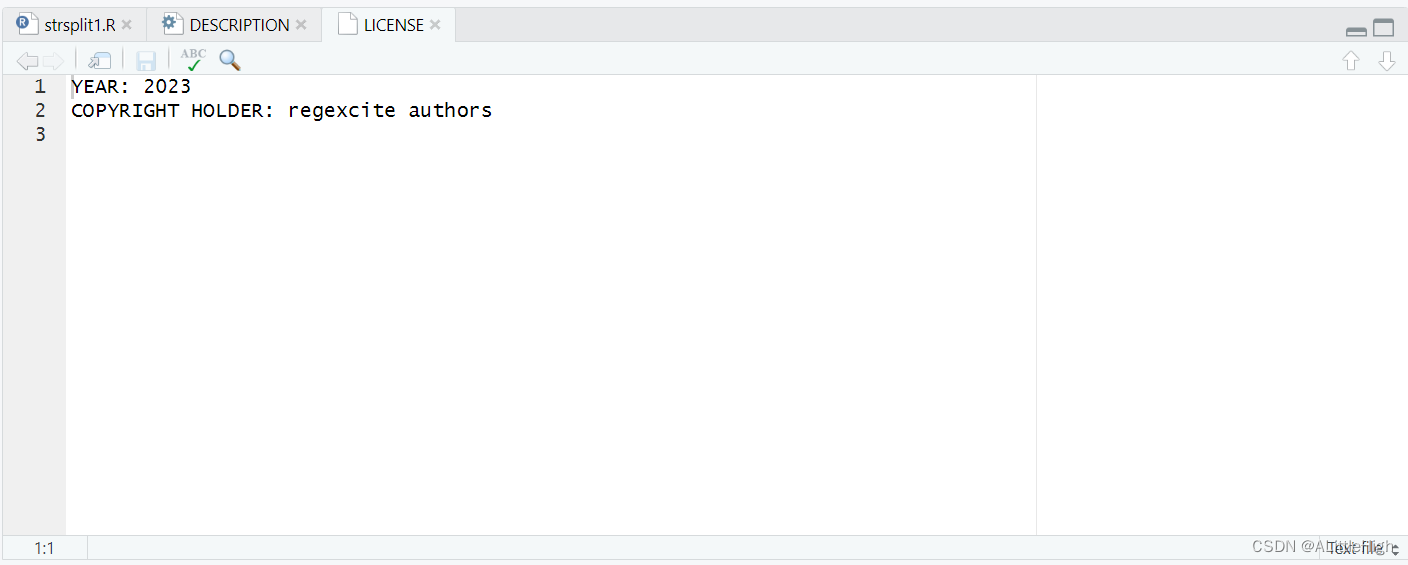
与其他许可证帮助程序一样,use_mit_license()也将完整许可证的副本放在LICENSE.md中,并将此文件添加到.Rbuildignore。在包的源代码(比如GitHub)中包含完整的许可证被认为是最佳实践,但CRAN不允许在包的tarball中包含该文件。
12. 配置帮助文档
在strsplit1()上获得帮助文档不是很好吗,就像我们对其他R函数所做的那样?这需要你的包有一个特殊的R文档文件,man/strsplit1。用特定于R的标记语言编写,有点像LaTeX。幸运的是,我们不一定要直接写出来。
我们在源文件strsplit1()的上方写了一条特殊格式的注释,然后让一个名为roxygen2的包处理man/strsplit1.Rd的创建。
如果你使用RStudio,打开R/strsplit1.R中的源代码编辑器,并把光标放在strsplit1()函数定义的某个地方。之后点击菜单栏中的Code,在下拉选项栏中选择Insert roxygen skeleton。
函数上方应该出现一个非常特殊的注释,其中每行都以#'开头。RStudio只插入一个基本模板,所以你需要按自己所想进行编辑。
#' Title
#'
#' @param x
#' @param split
#'
#' @return
#' @export
#'
#' @examples
strsplit1 <- function(x, split) {
strsplit(x, split = split)[[1]]
}
参照示例做出的修改:
#' Split a string
#'
#' @param x A character vector with one element.
#' @param split What to split on.
#'
#' @return A character vector.
#' @export
#'
#' @examples
#' x <- "alfa,bravo,charlie,delta"
#' strsplit1(x, split = ",")
但这还没完!我们仍然需要通过 document() 将这个新的oxygen注释转换为man/strsplit1.Rd:
> document()
ℹ Updating regexcite documentation
ℹ Loading regexcite
Writing NAMESPACE
Writing strsplit1.Rd
现在你应该可以预览你的帮助文件,如下所示:
> ?strsplit1
ℹ Rendering development documentation for "strsplit1"
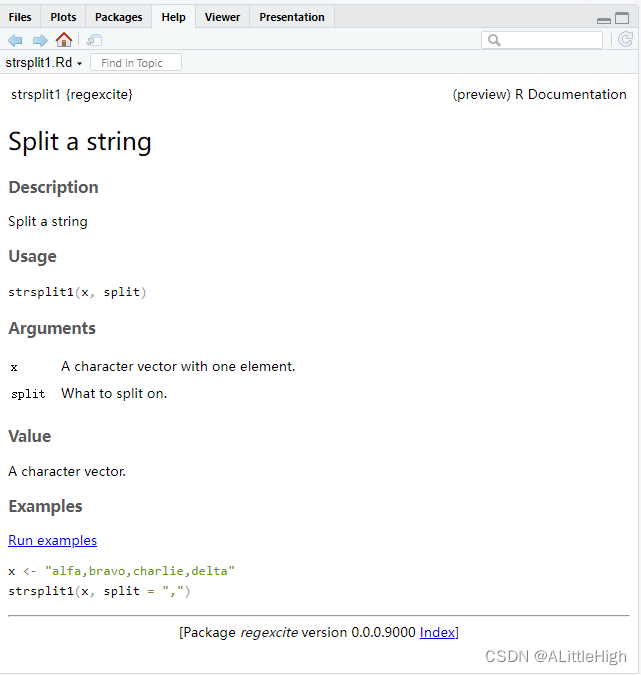
您将看到类似“渲染’ strsplit1 '的开发文档”的消息,它提醒您基本上正在预览草稿文档。也就是说,该文档存在于包的源代码中,但尚未存在于已安装的包中。事实上,我们还没有安装regexcite,但很快就会安装了。如果strsplit1不起作用,您可能需要先调用load_all(),然后再试一次。
还要注意,在正式构建和安装之前,软件包的文档不会正确地连接起来。这样就省去了一些细节,比如帮助文件之间的链接和包索引的创建。
12.1 更新NAMESPACE
除了将strsplit1()的特殊注释转换为man/strsplit1。然后,对 document() 的调用根据在roxygen注释中找到的@export标记更新命名空间文件。打开NAMESPACE进行检查。内容应为:
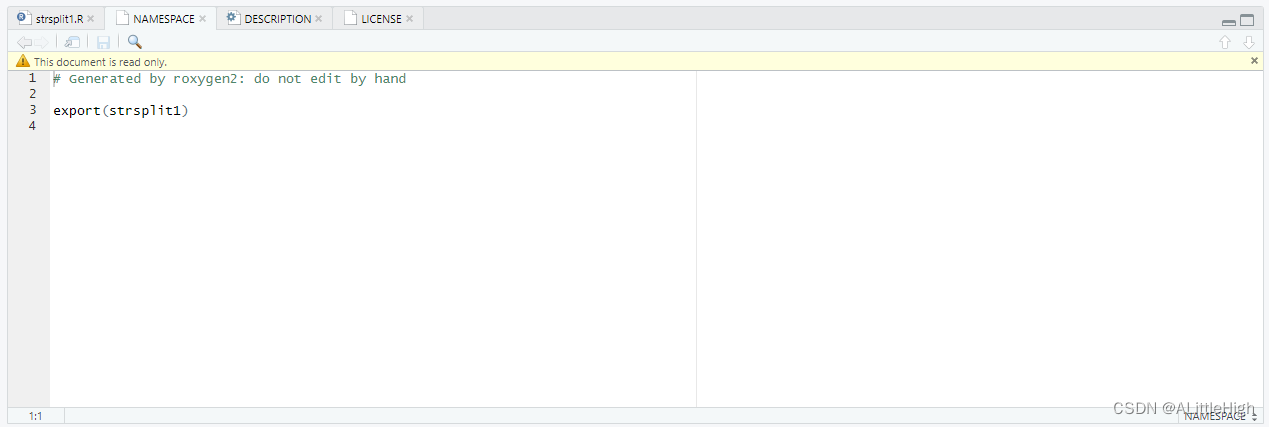
在通过library(regexcite)导入regexcite后,NAMESPACE中的export指令使strsplit1()对用户可用。正如完全可以“手工”编写. rd文件一样,您可以自己显式地管理NAMESPACE。但我们选择将此委托给devtools(和roxygen2)。
13. 再次检查
这次检查应该没有任何问题了。
14. 安装并手动测试
现在我们知道我们有了一个最小可行的产品,让我们通过 install() 将regexcite包安装到库中:
> install()
── R CMD build ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
✔ checking for file 'C:\Users\bailo\regexcite/DESCRIPTION'
─ preparing 'regexcite':
✔ checking DESCRIPTION meta-information ...
─ checking for LF line-endings in source and make files and shell scripts
─ checking for empty or unneeded directories
─ building 'regexcite_0.0.0.9000.tar.gz'
Running "D:/ALL_Softwares/R-4.2.0/bin/x64/Rcmd.exe" INSTALL "C:\Users\bailo\AppData\Local\Temp\RtmpeGGTp6/regexcite_0.0.0.9000.tar.gz" \
--install-tests
* installing to library 'D:/ALL_Softwares/R-4.2.0/library'
* installing *source* package 'regexcite' ...
** using staged installation
** R
** byte-compile and prepare package for lazy loading
** help
*** installing help indices
** building package indices
** testing if installed package can be loaded from temporary location
** testing if installed package can be loaded from final location
** testing if installed package keeps a record of temporary installation path
* DONE (regexcite)
安装完成后,我们可以像其他包一样导入和使用regexcite。同时最好打开一个新的RStudio会话窗口进行测试:
> library(regexcite)
> x <- "alfa,bravo,charlie,delta"
> strsplit1(x, split = ",")
[1] "alfa" "bravo" "charlie" "delta"
15. 单元测试
我们在一个示例中非正式地测试了strsplit1()。我们可以将其形式化为单元测试。这意味着我们表达了对特定输入的正确strsplit1()结果的具体期望。
首先,我们声明编写单元测试的意图,并通过testthat包 use_testthat() 进行:
> use_testthat()
✔ Creating 'tests/testthat/'
✔ Writing 'tests/testthat.R'
• Call `use_test()` to initialize a basic test file and open it for editing.
这将初始化包的单元测试机制。将“Suggests: testthat”添加到“DESCRIPTION”中,创建目录“tests/testthat/”,并添加脚本“tests/testthat.R”。你会注意到testthat可能添加了3.0.0的最小版本和第二个DESCRIPTION字段,Config/testthat/edition: 3。
帮助器 use_test() 打开和/或创建一个测试文件。您可以提供文件的基本名称,或者,如果您在RStudio中编辑相关的源文件,它将自动生成。对于你们中的许多人来说,如果是R/strsplit1.R是RStudio中的活动文件,你可以调用use_test()。然而,由于本书是非交互式构建的,我们必须显式地提供basename:
> use_test("strsplit1")
✔ Writing 'tests/testthat/test-strsplit1.R'
• Modify 'tests/testthat/test-strsplit1.R'
这将创建文件tests/testthat/test-strsplit1.R。如果它已经存在,use_test()只会打开它。你会注意到在新创建的文件中有一个示例测试:

-删除该代码并用以下内容替换它:
test_that("strsplit1() splits a string", {
expect_equal(strsplit1("a,b,c", split = ","), c("a", "b", "c"))
})
这将测试strsplit1()在分割字符串时是否给出预期的结果。
交互式地运行这个测试,就像您编写自己的测试一样。如果test_that()或strsplit1()找不到,这表明您可能需要调用load_all()。
接下来,您的测试将通过 test() 主要集中运行:
> test()
ℹ Testing regexcite
载入程辑包:‘testthat’
The following object is masked from ‘package:devtools’:
test_file
✔ | F W S OK | Context
✔ | 1 | strsplit1
══ Results ══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════
Duration: 0.2 s
[ FAIL 0 | WARN 0 | SKIP 0 | PASS 1 ]
16. 配置依赖包以及修改的流程
您将不可避免地希望在自己的包中使用来自另一个包的函数。我们需要使用特定于包的方法来声明我们需要的其他包(即我们的依赖),并在我们的包中使用这些包。如果您计划向CRAN提交一个包,请注意,这甚至适用于包中您认为“始终可用”的函数,例如stats::median()或utils::head()。
stringr包“提供了一组内聚的函数,旨在使处理字符串尽可能简单”。特别是,stringr在任何地方都使用一个正则表达式系统(ICU正则表达式),并在每个函数中使用相同的接口来控制匹配行为,例如大小写敏感性。有些人发现这更容易内化和编程。假设您决定基于string(和stringi)构建regexcite,而不是base R的正则表达式函数。
首先,使用 use_package() 声明使用stringr命名空间中的某些函数的一般意图:
> use_package("stringr")
✔ Adding 'stringr' to Imports field in DESCRIPTION
• Refer to functions with `stringr::fun()`
这会将stringr包添加到DESCRIPTION的Imports字段中。这就是它的全部功能。
让我们重新审视strsplit1(),使其更像具stringr风格。暂且不论改写后的函数功能:
str_split_one <- function(string, pattern, n = Inf) {
stopifnot(is.character(string), length(string) <= 1)
if (length(string) == 1) {
stringr::str_split(string = string, pattern = pattern, n = n)[[1]]
} else {
character()
}
}
我们应该在哪里写这个新的函数定义?如果我们希望继续遵循约定,在. r文件定义的函数之后命名它,我们现在需要进行一些繁琐的文件排序。因为这在现实生活中经常出现,所以我们使用了 rename_files() 函数,它在R/中编排文件的重命名以及test/下面的相关伴生文件。
> rename_files("strsplit1", "str_split_one")
✔ Moving 'R/strsplit1.R' to 'R/str_split_one.R'
✔ Moving 'tests/testthat/test-strsplit1.R' to 'tests/testthat/test-str_split_one.R'
请记住:文件名工作纯粹是理想的。我们还需要更新这些文件的内容!
以下是R/str_split_one.R的更新内容。除了更改函数定义之外,我们还更新了roxygen以反映新的参数,并包含展示stringr特性的示例。
不要忘记更新测试文件!
以下是tests/testthat/test-str_split_one.R的更新内容。除了更改函数的名称和参数之外,我们还添加了几个测试。
test_that("str_split_one() splits a string", {
expect_equal(str_split_one("a,b,c", ","), c("a", "b", "c"))
})
test_that("str_split_one() errors if input length > 1", {
expect_error(str_split_one(c("a,b","c,d"), ","))
})
test_that("str_split_one() exposes features of stringr::str_split()", {
expect_equal(str_split_one("a,b,c", ",", n = 2), c("a", "b,c"))
expect_equal(str_split_one("a.b", stringr::fixed(".")), c("a", "b"))
})
在新的str_split_one()进行测试驱动之前,需要调用document()。为什么?记住,document()主要做两项工作:
- 将我们的roxygen注释转换为适当的R文档。
- (重新)生成NAMESPACE。
第二项任务在这里尤为重要,因为我们将不再导出strsplit1(),而是导出str_split_one()。不要对“对象被列为导出,但不要因为"Objects listed as exports, but not present in namespace: strsplit1"的警告感到沮丧。当您从名称空间中删除某些内容时,总是会发生这种情况。
> document()
ℹ Updating regexcite documentation
ℹ Loading regexcite
Writing NAMESPACE
Writing str_split_one.Rd
Deleting strsplit1.Rd
Warning message:
Objects listed as exports, but not present in namespace:
• strsplit1
通过load_all()模拟软件包安装,试试新的str_split_one()函数:
> load_all()
ℹ Loading regexcite
Warning message:
── Conflicts ───────────────────────────────────────────────────────────────────────────────────────────────────────────────── regexcite conflicts
──
✖ `str_split_one` masks `regexcite::str_split_one()`.
ℹ Did you accidentally source a file rather than using `load_all()`?
Run `rm(list = c("str_split_one"))` to remove the conflicts.
> regexcite::str_split_one("a, b, c", pattern = ", ")
[1] "a" "b" "c"
17. 同步到github
如何将本地的regexcite包和Git存储库连接到GitHub上的配套存储库?这里有三种方法:
- Use_github()是我们推荐长期使用的一个帮助器。我们不会在这里演示它,因为它需要在您的终端上进行一些凭据设置。
- 首先设置GitHub仓库!这听起来有点违反直觉,但是把你的工作放到GitHub上最简单的方法就是在那里初始化,然后使用RStudio在同步的本地副本中开始工作。
- 命令行Git总是可以用来添加远程存储库。
这些方法都可以将本地的regexcite项目连接到GitHub的公共或私有仓库,你可以使用RStudio内置的Git客户端将其推送或拉出。在第20章中,我们详细说明了为什么版本控制(例如Git),特别是托管版本控制(例如GitHub)值得合并到包开发过程中。
18. 配置readme
现在你的包已经在GitHub上了,README.md文件很重要。
use_readme_rmd() 函数初始化一个基本的、可执行的README.Rmd准备好供您编辑:
> use_readme_rmd()
✔ Writing 'README.Rmd'
✔ Adding '^README\\.Rmd$' to '.Rbuildignore'
• Modify 'README.Rmd'
• Update 'README.Rmd' to include installation instructions.
✔ Writing '.git/hooks/pre-commit'
除了创建README.Rmd之外,这将在.Rbuildignore中添加一些行,并创建一个Git预提交钩子来帮助您保存README.Rmd和README.md同步。
README.Rmd已经有部分提示您:
- 描述包的用途。
- 提供安装说明。如果在调用use_readme_rmd()时检测到GitHub远程,本节将预先提供如何从GitHub安装的说明。
- 显示一点用法。
如何填充这个骨架?从DESCRIPTION和任何正式和非正式的测试或例子中大量复制内容。有总比没有好。这很有帮助,因为人们可能不会安装您的包并仔细检查各个帮助文件来弄清楚如何使用它。
我们喜欢在R Markdown中编写README,这样它就可以实际使用。包含活动代码还可以减少README变得陈旧和与实际包不同步的可能性。
如果RStudio还没有这样做,请打开README.Rmd用于编辑。确保它显示了str_split_one()的一些用法。
不要忘记渲染它来生成README.md!如果您尝试提交README.Rmd,而不是README.md,当README.md似乎过时了,预提交钩子应该会提醒您。
呈现README.Rmd 的最佳方式是使用 build_readme(),因为它会使用最新版本的包进行渲染,也就是说,它会从当前源安装临时副本。
> build_readme()
ℹ Installing regexcite in temporary library
ℹ Building C:/Users/bailo/regexcite/README.Rmd
最后,不要忘记做最后一次提交。push,如果你用的是GitHub。
19. 收尾
让我们再次运行 check() 以确保一切正常。
── R CMD check results ──────────────────────────────────────────────────────────────────────────────────────────────────── regexcite 0.0.0.9000 ────
Duration: 18s
0 errors ✔ | 0 warnings ✔ | 0 notes ✔
Regexcite不应该有错误、警告或注释。这将是重新构建并正确安装它的好时机。
install()
── R CMD build ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
✔ checking for file 'C:\Users\bailo\regexcite/DESCRIPTION'
─ preparing 'regexcite':
✔ checking DESCRIPTION meta-information ...
─ checking for LF line-endings in source and make files and shell scripts
─ checking for empty or unneeded directories
─ building 'regexcite_0.0.0.9000.tar.gz'
Running "D:/ALL_Softwares/R-4.2.0/bin/x64/Rcmd.exe" INSTALL "C:\Users\bailo\AppData\Local\Temp\RtmpeGGTp6/regexcite_0.0.0.9000.tar.gz" \
--install-tests
* installing to library 'D:/ALL_Softwares/R-4.2.0/library'
* installing *source* package 'regexcite' ...
** using staged installation
** R
** tests
** byte-compile and prepare package for lazy loading
** help
*** installing help indices
*** copying figures
** building package indices
** testing if installed package can be loaded from temporary location
** testing if installed package can be loaded from final location
** testing if installed package keeps a record of temporary installation path
* DONE (regexcite)
20. 总览回顾
本章的目的是让您了解典型的包开发工作流程,总结为图1.1中的图表。除了GitHub Actions之外,你在这里看到的所有内容都已经在本章中提到过了,GitHub Actions将在第20.2.1节中了解更多。