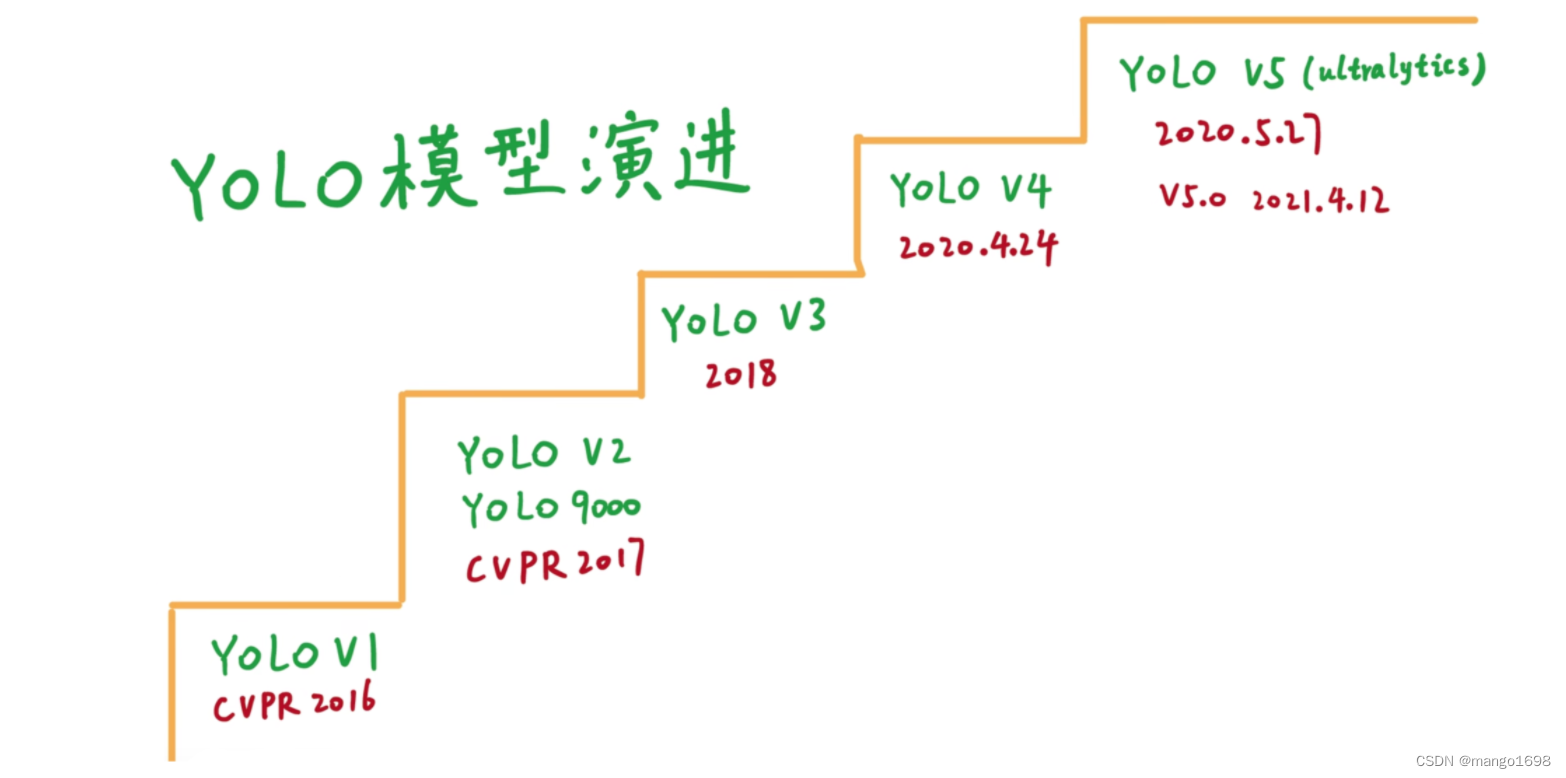
文章目录
- 1. 作者简介
- 2. 目标检测综述
- 3. YOLOv1算法
- 3.1 预测阶段
- 3.2 预测阶段后处理
- 3.3 训练阶段
YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
YOLO是目标检测模型。目标检测是计算机视觉中比较简单的任务,用来在一张图篇中找到某些 特定的物体,目标检测不仅要求我们识别这些物体的种类,同时要求我们标出这些物体的位置。
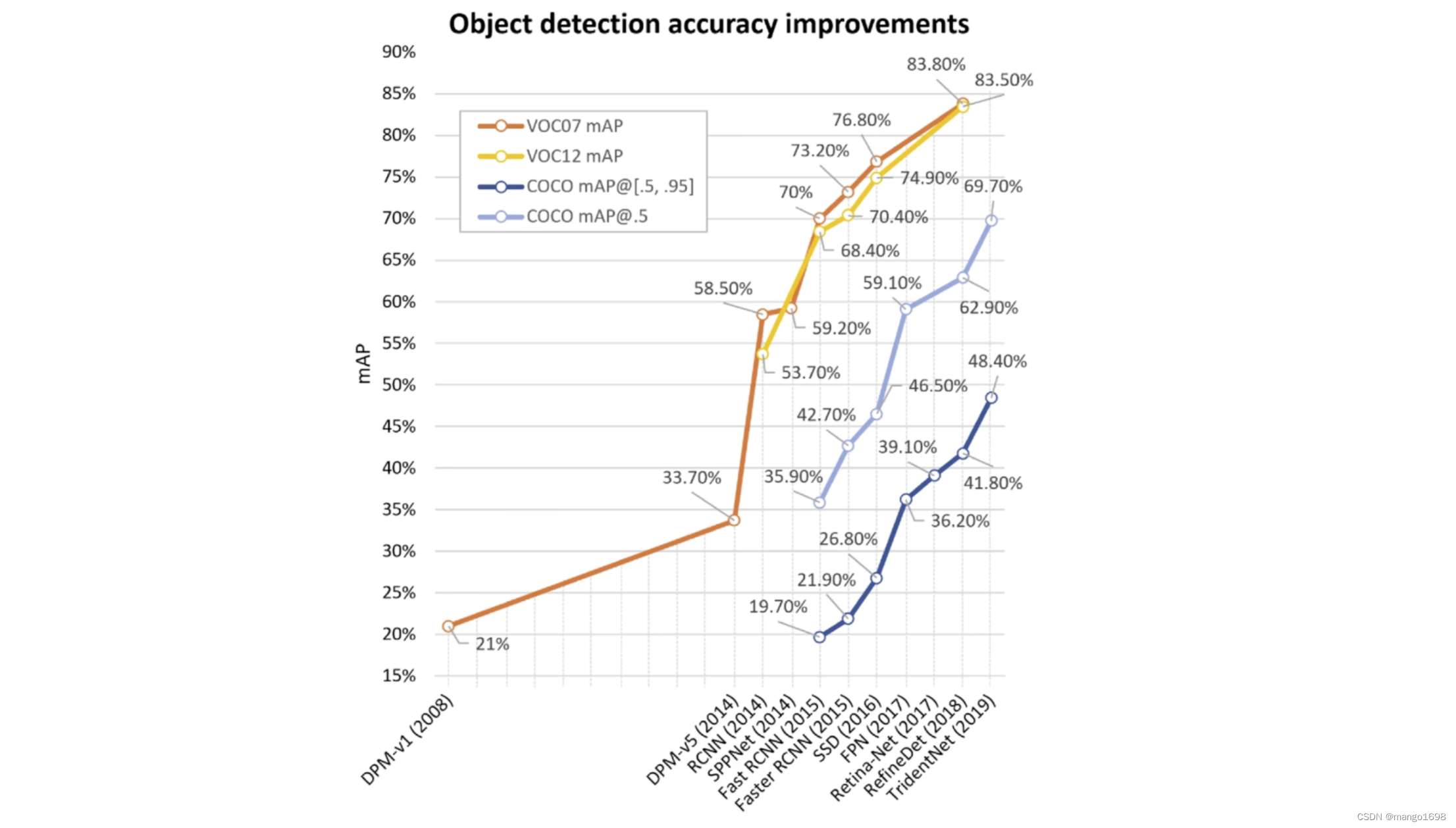
YOLO能实现图像或视频中物体的快速识别,在相同的识别类别范围和识别准确率条件下,YOLO识别速度最快。YOLO有多种模型,其中最新的为V5,V5的特点是速度更快,识别准确率更高,权重文件更小,可以搭载在配置更低的移动设备上。
1. 作者简介

作者:Joseph Redmon,华盛顿大学博士,YOLO目标检测算法主要作者,YOLO是Joseph Redmon和Ali Farhadi等人于2015年提出的第一个基于单个神经网络的目标检测系统。
作者个人网站:https://pjreddie.com/
2. 目标检测综述
YOLO就是解决目标检测问题的计算机视觉算法。
计算机视觉能够解决很多问题:分类、检测、分割、关键点检测。
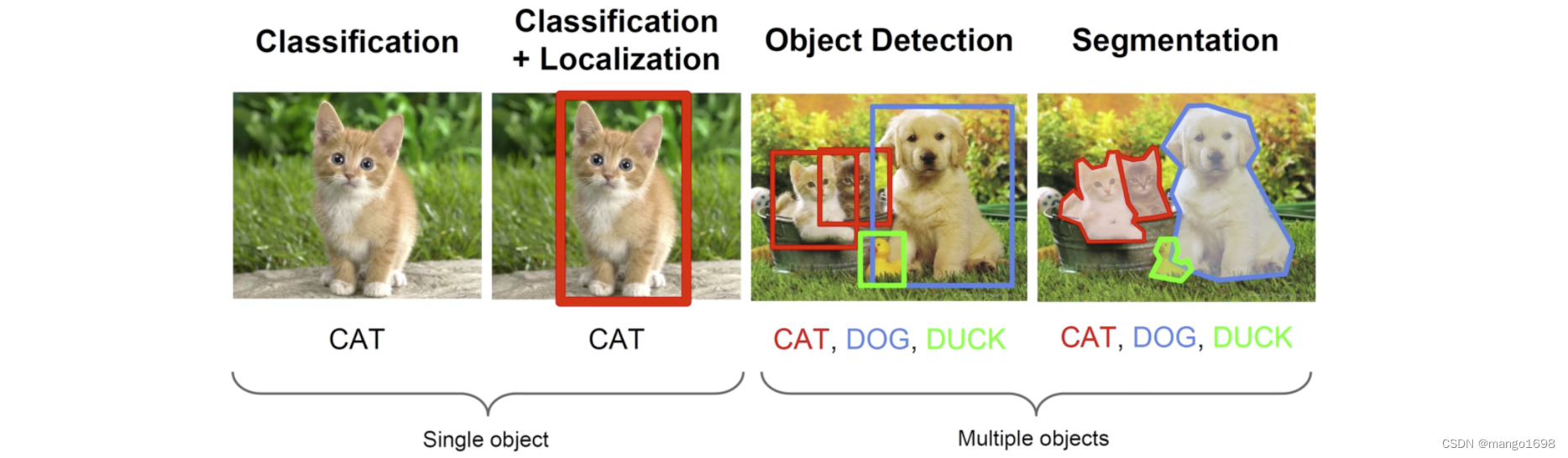
图像分割分为两种:语义分割(Semantic Segmentation)、示例分割(Instance Segmentation)
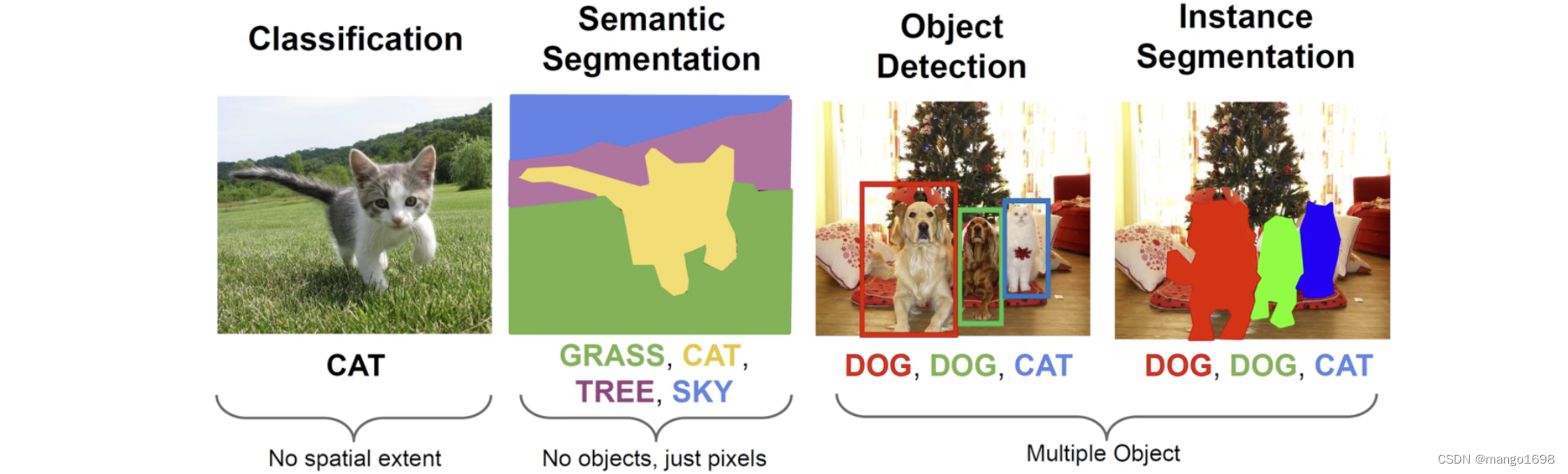
目标检测,综述文章推荐:

目标检测领域著名数据集:PASCAL-VOC、ILSVRC、MS-COCO、OID。
yolo是在pascal voc和ms-coco数据集上进行评测的。
目标检测发展历程:
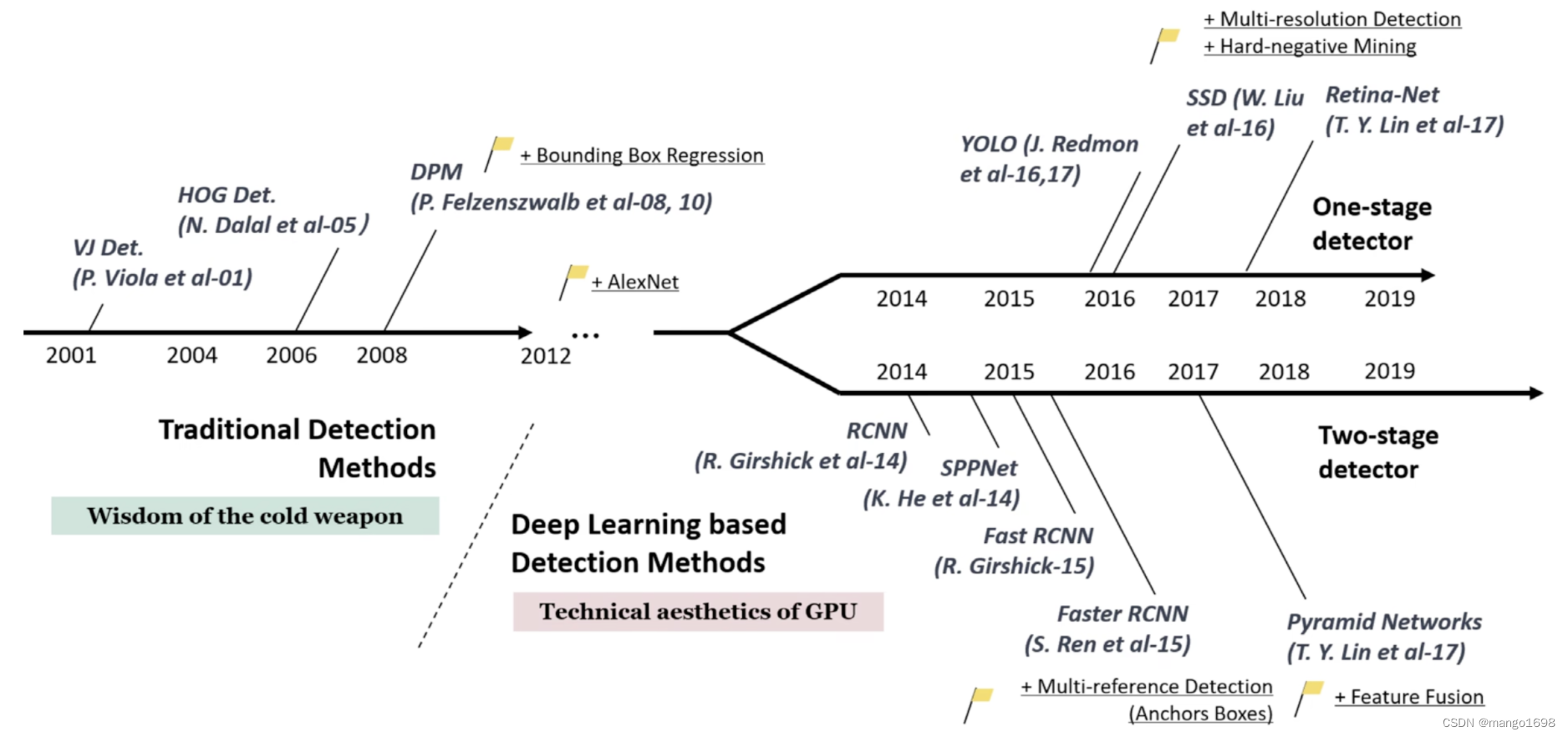
目标检测主要分为两个流派:one-stage detector和two-stage detector。
yolo属于one-stage detector。
two-stage(两阶段模型):先从图像中提取若干候选框,再逐一对这些候选框进行分类、甄别和调整坐标,最后得出结果。
one-stage(单阶段模型):不仅提取候选框,而且直接将全图输入到模型中,算法直接输出最终结果。是一个统一的端到端的系统。
one-stage代表模型:YOLO,SSD,Retina-Net。
two-stage代表模型:RCNN,SPPNet,Fast RCNN,Faster RCNN。
两阶段模型比较准确,但是比较耗时。而单阶段模型虽然较快,但是准确率不是太高,尤其是对于小目标,密集目标识别不太好。单目前yolo在识别率和速度上都已经非常好了。
3. YOLOv1算法
理解yolov1算法的关键在于,分开理解训练阶段和预测阶段。
3.1 预测阶段
预测阶段(测试阶段)就是,在模型已经训练成功后,输入未知图片,来对未知图片进行预测。此时不再需要反向传播,而是只需要前向推断。
这个模型训练出来之后是一个深度卷积神经网络。
YOLOv1网络结构:
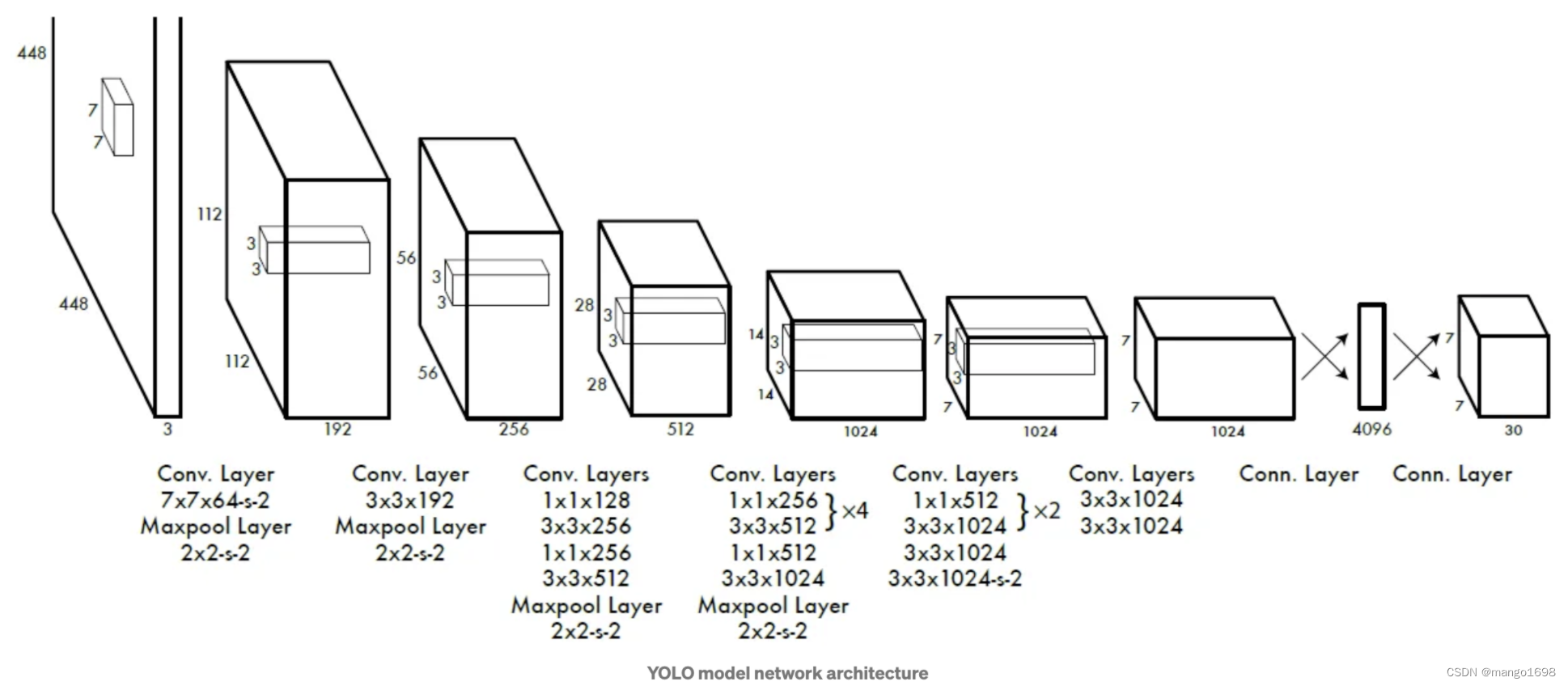
输入为 448 × 448 × 3 448\times 448\times 3 448×448×3,输出为 7 × 7 × 30 7\times 7\times 30 7×7×30。
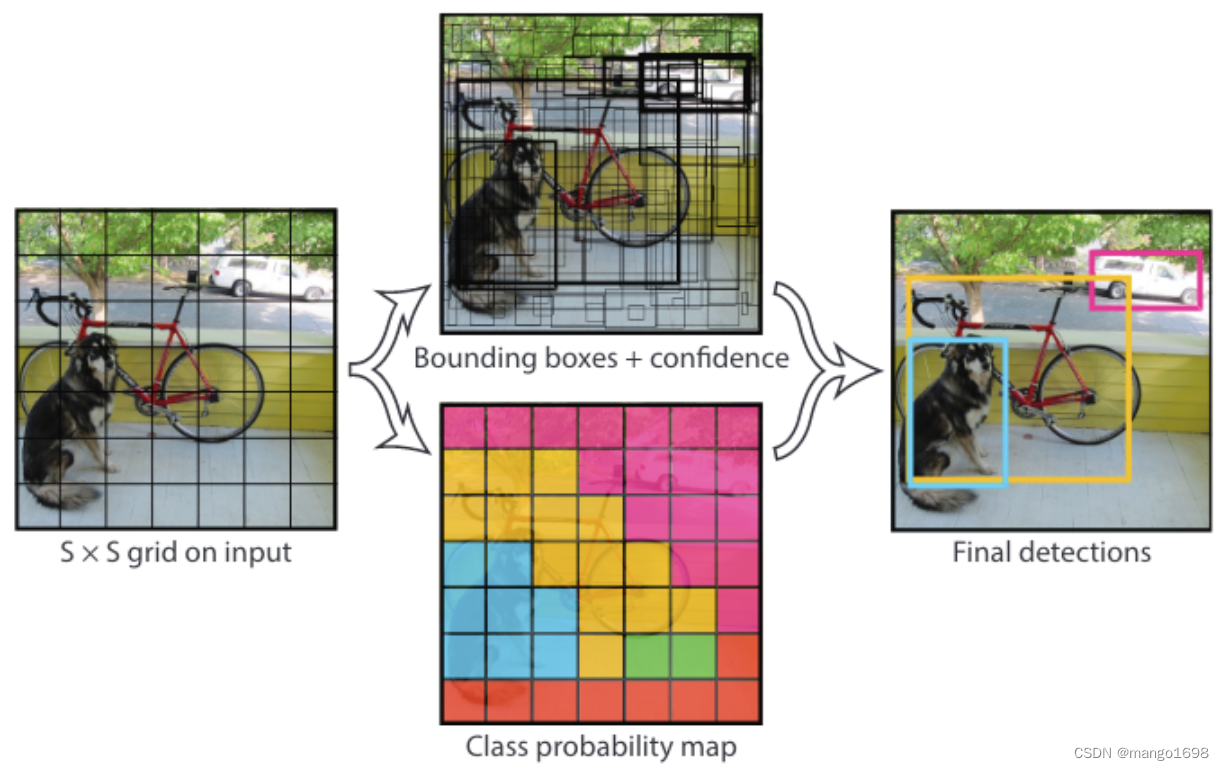
首先网络将图像划分为了 S × S S\times S S×S个网格(在YOLOv1中 S = 7 S=7 S=7),所以为 7 × 7 7\times 7 7×7个网格,即49个。
每个网格可以预测出 b b b个预测框(在YOLOv1中 b = 2 b=2 b=2),即每个网格生成2个预测框,即共98个预测框。预测框可能很大,也可能很小。每个预测框包含(x,y,w,h,c)四个定位坐标和置信度c,即中心点的坐标和框的宽高,以及包含它是不是一个目标的置信度c。在上图中,使用框的粗细来表示置信度,粗的就表示置信度较高。
每个网格还能生成所有类别的条件概率。假设在它已经包含物体的情况下,它是某一个物体的概率,即生成了下面彩色的图。
把每一个预测框的置信度乘以类别的条件概率,就可以获得每一个预测框各类别的概率。
结合预测框的信息和网格类别信息,就可以获得最后的预测结果。这些信息都是从 7 × 7 × 30 7\times 7\times 30 7×7×30的张量中获取的。
那么为什么输出是 7 × 7 × 30 7\times 7\times 30 7×7×30呢?
包含两个预测框,每个预测框有5个参数(x,y,w,h,c)。两个框便是10个参数。在pascal voc中包含20个类别,那么5+5+20,那么就是30,这个30维的向量就是一个网格的信息,共有
7
×
7
7\times 7
7×7个网格,所以输出是
7
×
7
×
30
7\times 7\times 30
7×7×30。
3.2 预测阶段后处理
预测阶段后处理需要进行置信度过滤和非极大值抑制。
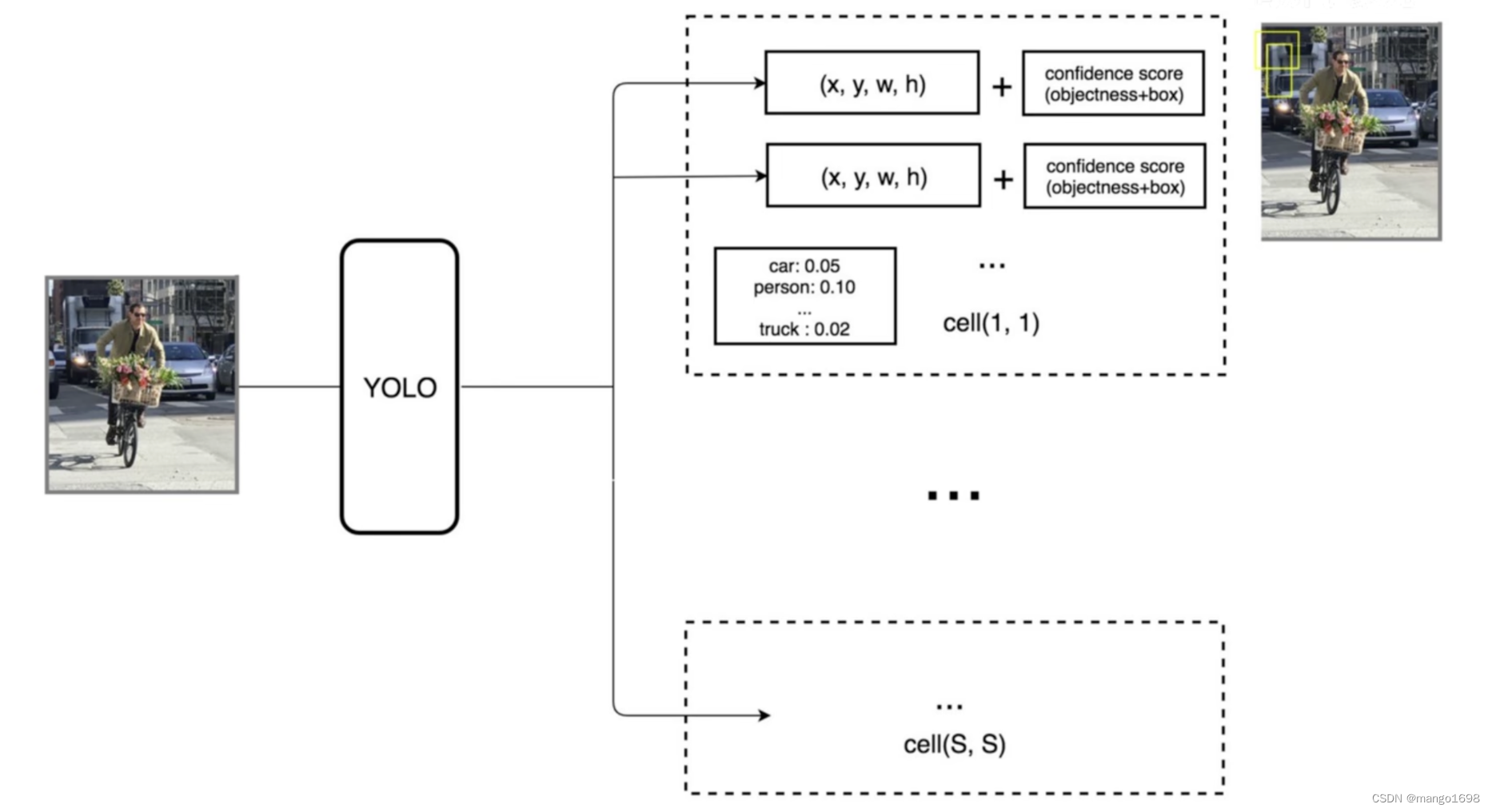
对于YOLO而言,后处理就是对纷繁复杂的预测出来的98个预测框进行筛选、过滤,把重复的预测框只保留一个,最终获得目标检测的结果。把低置信度的框过滤掉,把重复的预测框过滤掉。
下面参考deepsystems.io的slides,详细解读一下inference过程。
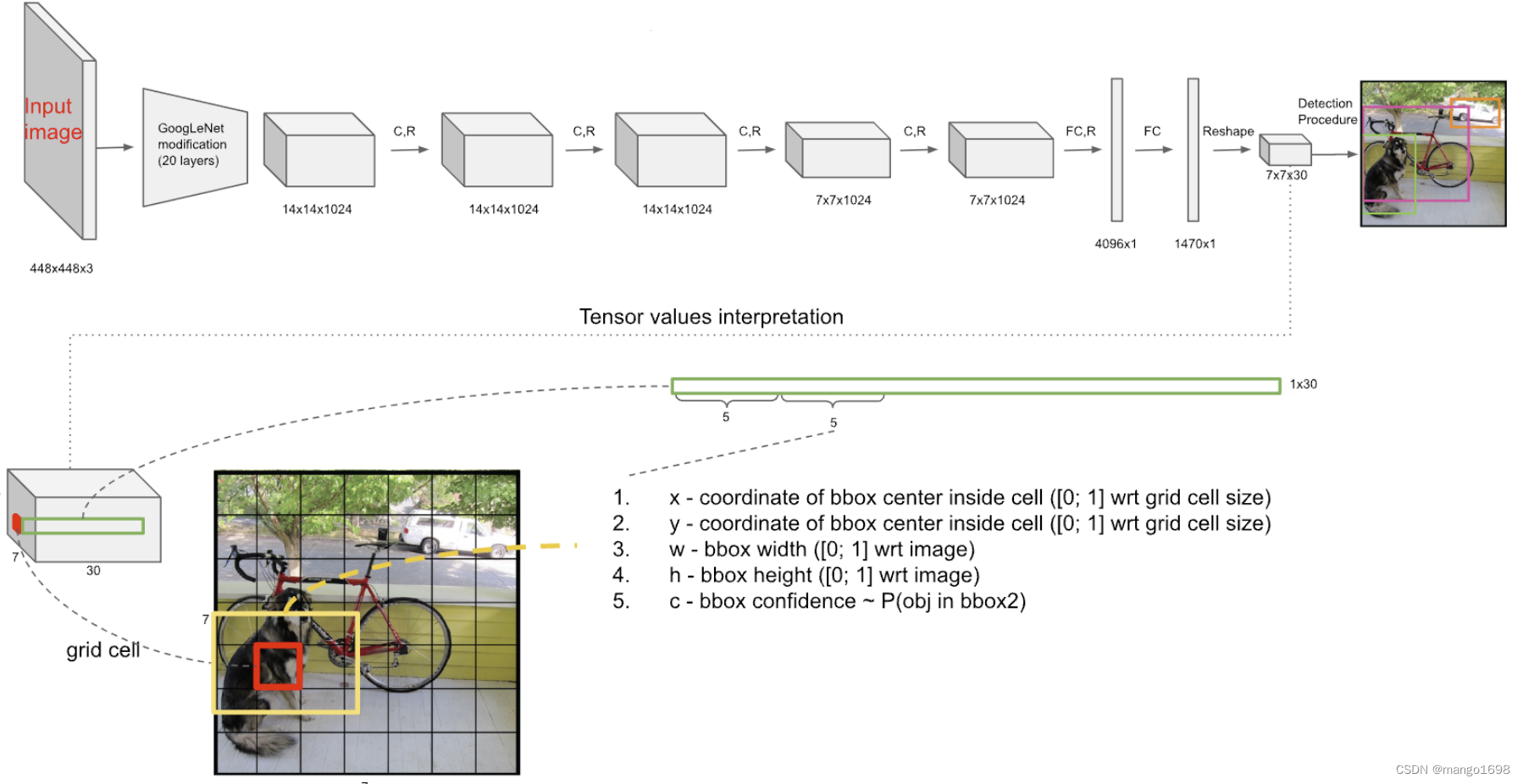
如上图,输出为 7 × 7 × 30 7\times 7\times 30 7×7×30。 7 × 7 7\times 7 7×7为 7 × 7 7\times 7 7×7个网格。对于每一个网格,对应30个数字,这30个数字是由5+5+20构成。两个5分别为:第一个和第二个预测框的四个位置坐标和一个置信度构成。20:是网格对20个类别的类别概率。
置信度:该预测框包含物体的概率。
将20个类别的条件概率与预测框的置信度相乘,即条件概率乘以条件本身发生的概率,则变成了它的全概率。
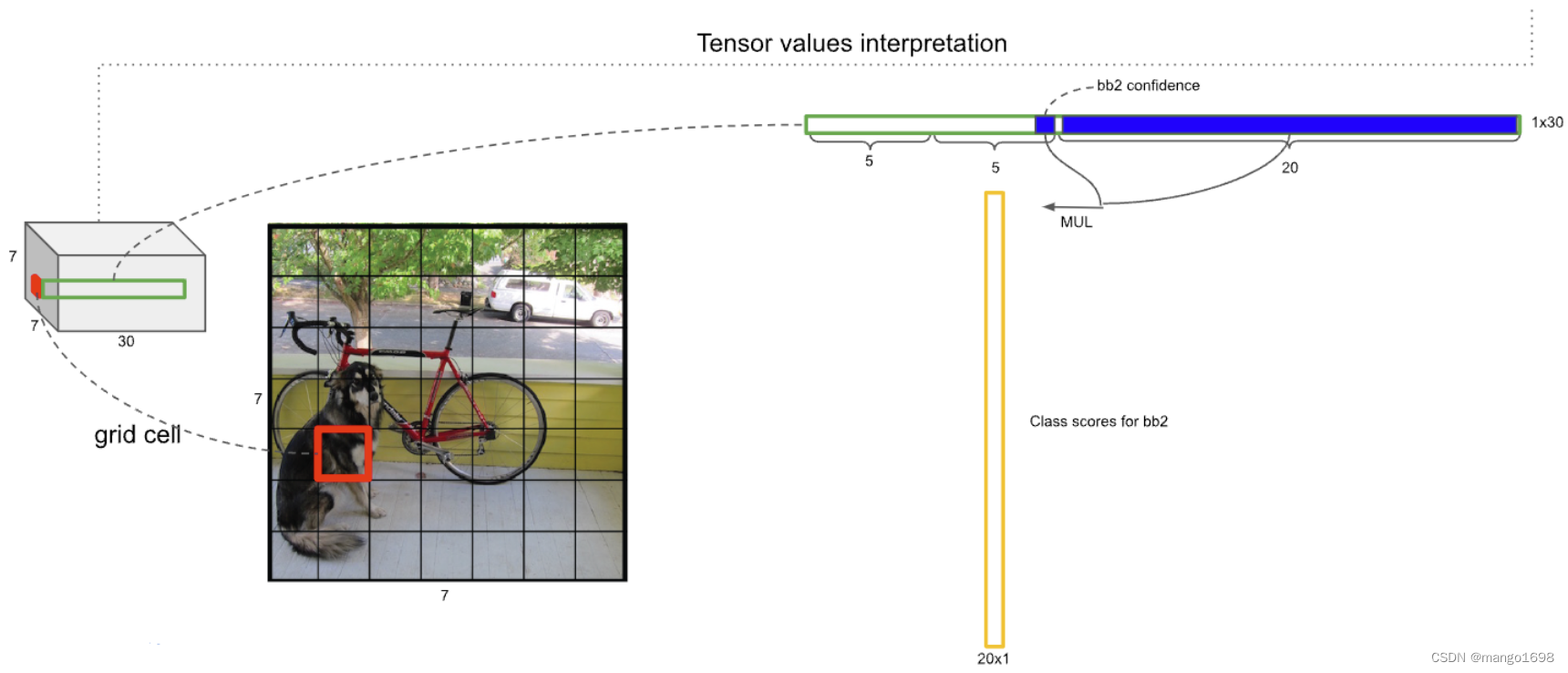
每个网格因为对应两个预测框,所以每个网格都可以获得两个全概率。 如下图。即每个网格预测两个bounding box,则共有 7 × 7 × 2 = 98 7\times 7\times 2 = 98 7×7×2=98个预测框。98个预测框的置信度分别乘以每个类别的条件概率,共有20个类别,所以最终得到98个20维的向量。
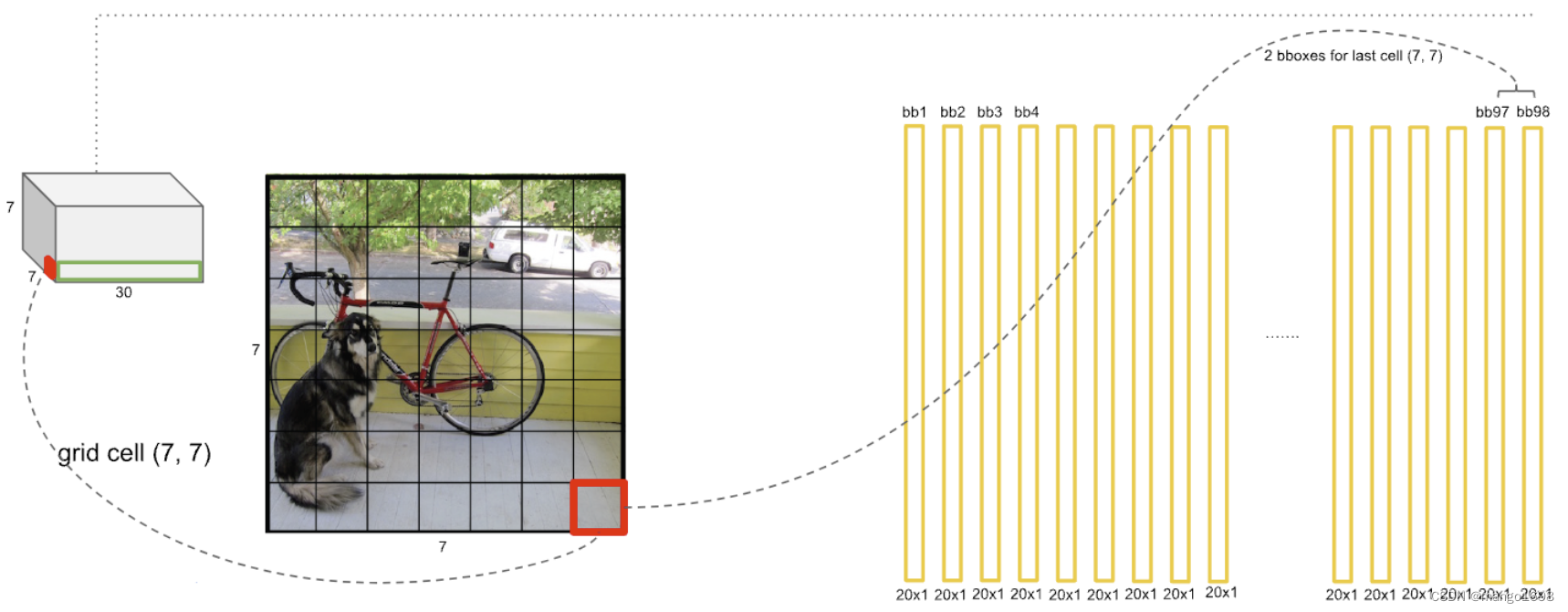
这98个20维的向量,可视化出来就是下图。

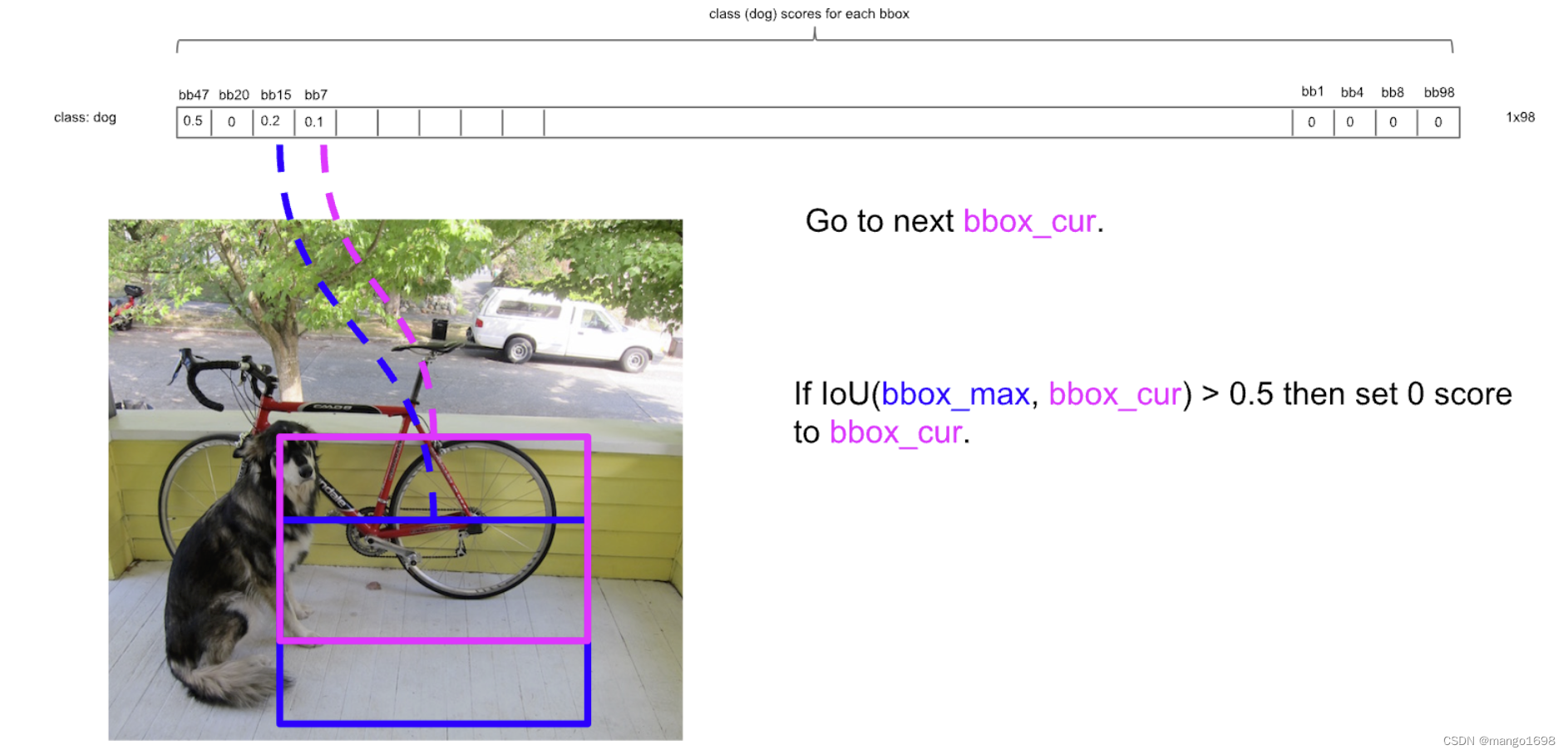
我们先只看狗这一个类别,假如狗是这20个类别中的第一个类别。我们设置一个阀值 k k k,假设 k = 0.2 k=0.2 k=0.2,那么我们将这98个向量中狗的概率小于0.2的值全部设置为0。我们再按照狗的概率的大小进行排序,将概率大的放置在前面,将概率小的放置在后面。再对排序后的值进行非极大值抑制操作(NMS)。
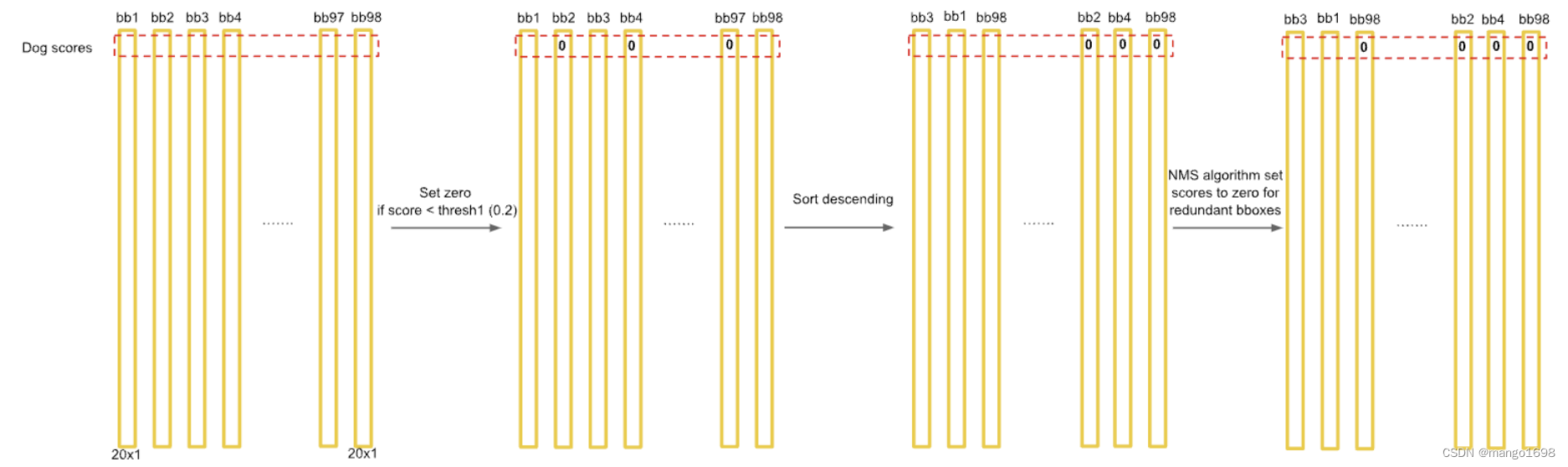
非极大值抑制(NMS)
仍然只看狗的概率。对于98个向量,我们只看狗的概率这一行。上面我们已经对狗的概率进行了从高到低的排序。
对于非极大值抑制,先把最大的概率拿出来,然后将每一个概率都与这个最大的概率进行比较。如果它们的IoU大于某个预值(假设为 p p p),那么我们则认为这两个预选框重复识别了同一个物体,那我们则把这个低置信度、第概率的过滤掉,将其狗的概率值这是为0 。如果IoU的值小于我们设置的阀值 p p p,那么则保留。重复以上过程,直到最低概率值与最大概率值进行比对完成。
然后,我们再选择第二大的概率值,让其他每一个比这个第二大概率低的概率都与这个第二大的概率进行比较。重复上述操作。
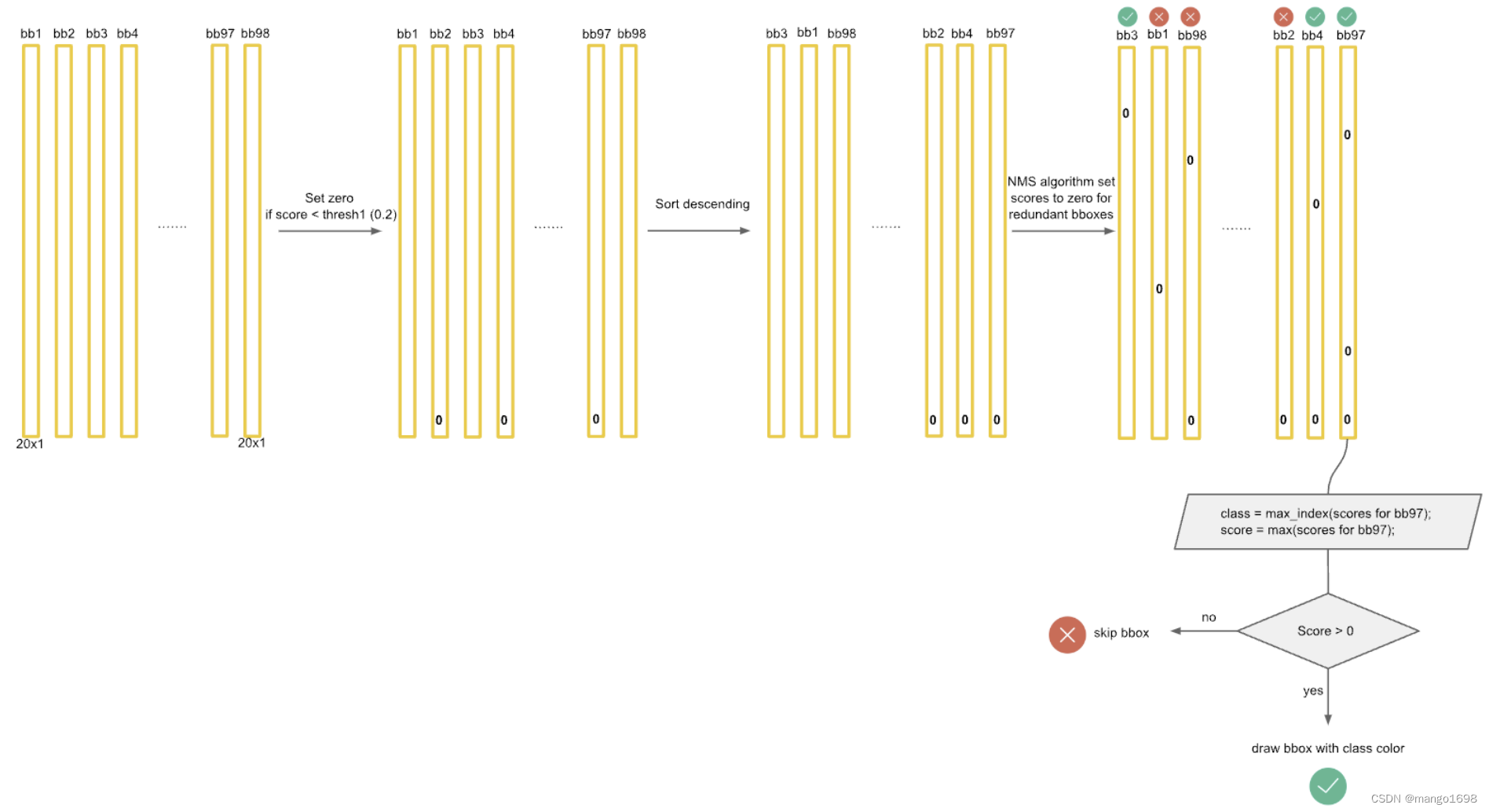
上述只是对狗这一个类别进行了操作,其他类别也按上述进行操作,最终就会得到检测结果。
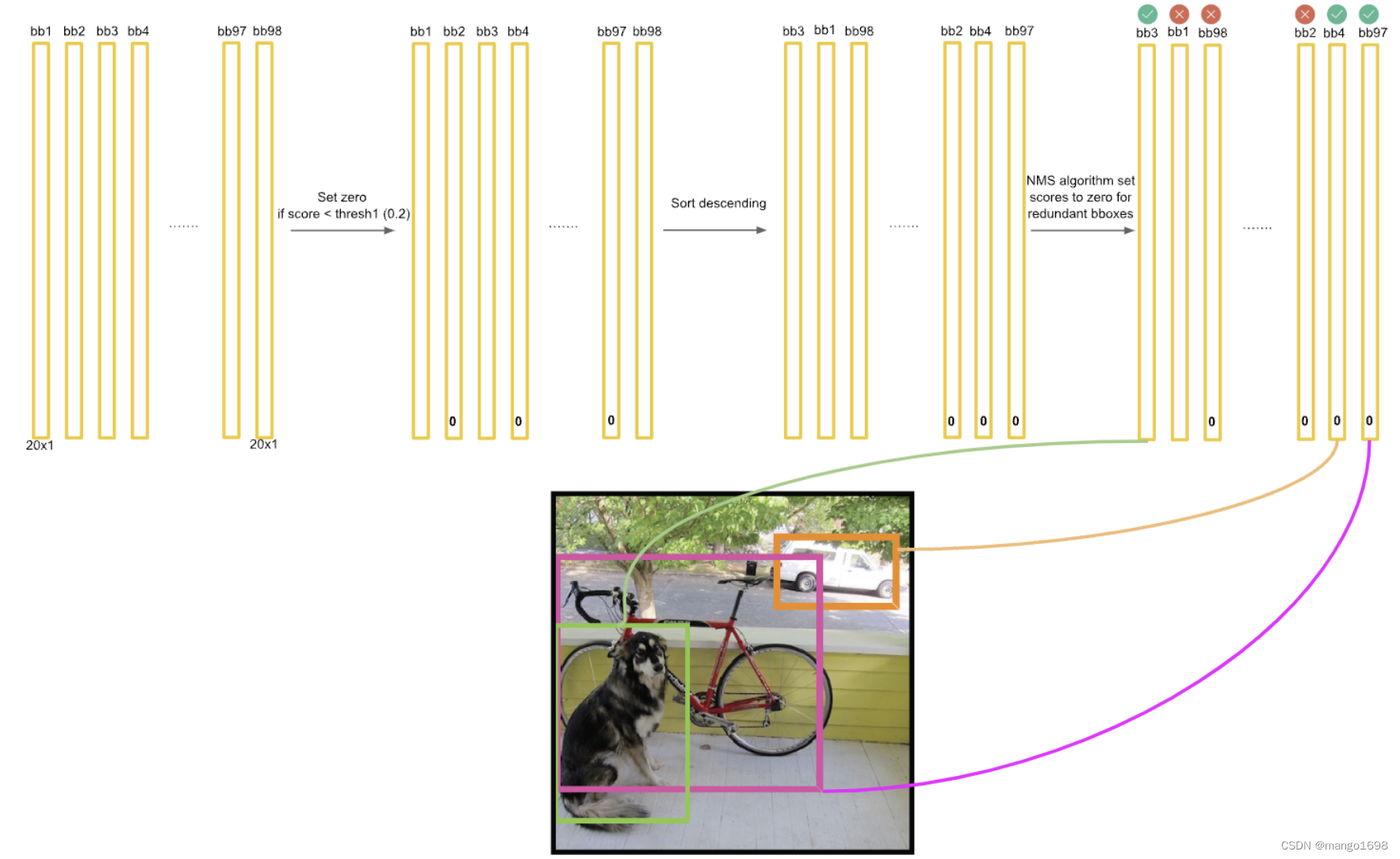
将不为0的bounding box找出来,最后进行可视化。
注意:
- 后处理只是用于预测阶段,在训练阶段不需要进行NMS。
3.3 训练阶段
训练阶段,即反向传播阶段。
深度学习或监督学习的训练是通过梯度下降和反向传播方法迭代的去微调神经元中的权重,使得损失函数最小化。
目标检测是一个典型的监督学习问题。

在训练集上,一定有人已经用labelme或者labelimg这样的标注工具画出了ground-truth,如上图的绿色框,这是人工标注出来的。
我们的算法就是要让预测结果尽量的去拟合这个ground-truth,使得损失函数最小化。
这个绿色框的中心点落在哪个grid cell内就应该由哪个grid cell预测出的bounding box去负责拟合ground-truth。每个grid cell生成两个bounding box,那么就应该由这两个bounding box中的一个去负责拟合这个ground-truth。并且,这个grid cell输出的类别也应该是这个ground-truth的类别。所以每个grid cell只能预测出一个物体。49个grid cell最多只能预测49个物体,这也是yolov1检测密集目标和小目标性能比较差的原因。
每个网格都预测出两个预测框,那么该由哪一个预测框去负责拟合ground-truth呢?
应该由和ground-truth的IoU比较大的那个预测框去负责拟合。那么另外一个预测框则什么都不需要做。
如果没有预测框中心点落在这个网格中,则这个网格所预测的两个预测框都不再去拟合ground-truth,即不需要做什么事情。
YOLOv1损失函数
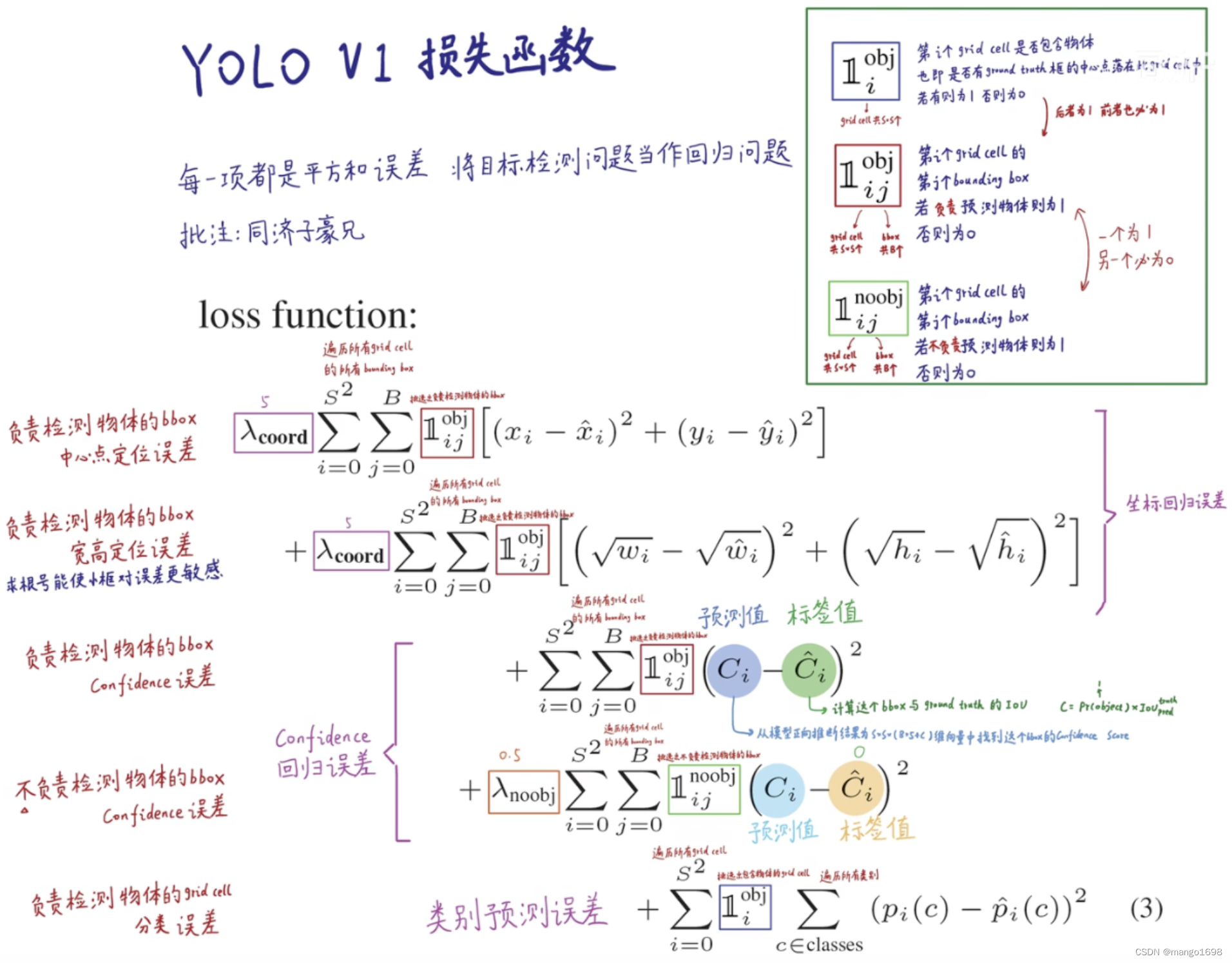
损失函数包含5项:
- 负责检测物体的bbox中心点定位误差
- 负责检测物体的bbox宽高定位误差
- 负责检测物体的bbox confidence误差
- 不负责检测物体的bbox confidence误差
- 负责检测物体的grid cell分类误差