一、介绍
在不断发展的人工智能和机器学习领域,深度学习技术因其处理复杂和高维数据的能力而广受欢迎。在各种深度学习模型中,堆叠式自动编码器是一种多功能且功能强大的工具,可用于特征学习、降维和数据表示。本文探讨了堆叠式自动编码器在深度学习领域的架构、工作原理、应用和意义。
揭开堆叠式自动编码器的威力,就像剥开数据层,揭示其中隐藏的宝藏,一次一个神经连接。
二、自动编码器:简要概述
自动编码器的核心是用于编码和解码数据的神经网络模型,本质上是模拟数据压缩和重建的过程。它们由一个编码器网络组成,前者将输入数据映射到较低维的潜在空间表示,后者从该表示中重建输入数据。自动编码器背后的核心思想是学习输入数据的压缩表示,以保留最显着的特征。这使得它们可用于降维、去噪和特征学习等任务。
三、单层自动编码器与堆叠式自动编码器
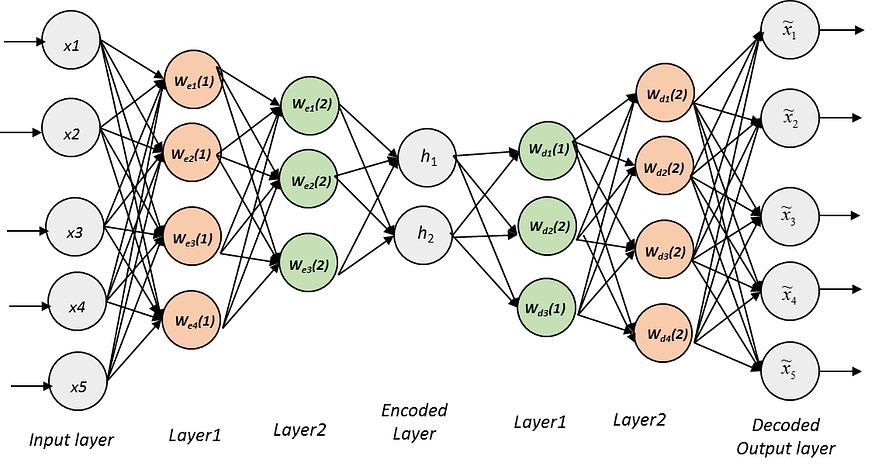
单层自动编码器虽然对简单任务有效,但在捕获许多真实数据集中存在的复杂和分层特征方面存在局限性。堆叠式自动编码器通过将多层自动编码器级联在一起以形成深度架构来解决此限制。这些层从数据中学习越来越抽象和复杂的特征,从而创建分层表示。从本质上讲,堆叠自动编码器是多层神经网络,旨在捕获数据中的复杂模式和表示。
四、堆叠式自动编码器的工作原理
- 培训前:堆叠式自动编码器的训练过程通常包括两个阶段。在预训练阶段,每一层都作为单层自动编码器单独训练。此阶段初始化权重和偏差,使网络能够学习有用的特征表示。
- 微调:预训练后,将各层组合在一起以创建堆叠自动编码器。然后使用反向传播和梯度下降对网络进行微调,以最大限度地减少重建误差,确保有效地学习分层特征。
五、堆叠式自动编码器的应用
- 降维:堆叠自动编码器在降低高维数据集的维度方面非常有效,使其在各个领域(包括图像和文本数据)中都具有价值。
- 异常检测:它们可以通过重建数据并将其与原始数据进行比较来用于异常检测;差异表明存在异常。
- 图像和语音识别:堆叠式自动编码器已用于图像和语音识别任务,以学习鲁棒的特征表示,从而提高这些系统的性能。
- 自然语言处理: 在 NLP 中,这些模型可以学习文本的分布式表示,从而实现更好的语言理解和生成。
- 协同过滤:堆叠式自动编码器可以应用于推荐系统,通过学习用户和项目嵌入来提高推荐质量。
六、意义与挑战
堆叠式自动编码器为深度学习做出了重大贡献,并在推动该领域发展方面发挥了至关重要的作用。它们学习分层特征和处理高维数据的能力在各种应用中取得了重大突破。然而,挑战也存在,例如需要大量的标记数据和计算资源来训练深度架构。
七、代码
使用数据集和绘图为堆叠自动编码器创建完整的 Python 代码需要多个库,并且可能因您选择的数据集而异。在此示例中,我们将使用 MNIST 数据集,这是图像相关任务的常见选择。在此示例中,我们将使用 Keras 和 Matplotlib。
# Import necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
# Load and preprocess the MNIST dataset
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
# Flatten the data
x_train = x_train.reshape(x_train.shape[0], -1)
x_test = x_test.reshape(x_test.shape[0], -1)
# Define a Stacked Autoencoder model
autoencoder = Sequential()
# Encoder
autoencoder.add(Dense(128, input_shape=(784,), activation='relu'))
autoencoder.add(Dense(64, activation='relu'))
# Decoder
autoencoder.add(Dense(128, activation='relu'))
autoencoder.add(Dense(784, activation='sigmoid'))
# Compile the model
autoencoder.compile(optimizer=Adam(), loss='mean_squared_error')
# Train the autoencoder
autoencoder.fit(x_train, x_train, epochs=10, batch_size=128, shuffle=True, validation_data=(x_test, x_test))
# Plot the original and reconstructed images
decoded_imgs = autoencoder.predict(x_test)
n = 10 # Number of images to display
plt.figure(figsize=(20, 4))
for i in range(n):
# Original Images
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Reconstructed Images
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()此代码演示了使用 MNIST 数据集的堆叠自动编码器。在运行此代码之前,应安装所需的库(Keras、Matplotlib)。调整模型架构和参数以适合您的特定数据集和任务。
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 [==============================] - 0s 0us/step
Epoch 1/10
469/469 [==============================] - 10s 17ms/step - loss: 0.0405 - val_loss: 0.0185
Epoch 2/10
469/469 [==============================] - 10s 21ms/step - loss: 0.0154 - val_loss: 0.0124
Epoch 3/10
469/469 [==============================] - 9s 19ms/step - loss: 0.0115 - val_loss: 0.0101
Epoch 4/10
469/469 [==============================] - 9s 19ms/step - loss: 0.0097 - val_loss: 0.0088
Epoch 5/10
469/469 [==============================] - 9s 19ms/step - loss: 0.0085 - val_loss: 0.0078
Epoch 6/10
469/469 [==============================] - 9s 19ms/step - loss: 0.0076 - val_loss: 0.0071
Epoch 7/10
469/469 [==============================] - 8s 17ms/step - loss: 0.0071 - val_loss: 0.0066
Epoch 8/10
469/469 [==============================] - 9s 19ms/step - loss: 0.0066 - val_loss: 0.0062
Epoch 9/10
469/469 [==============================] - 9s 19ms/step - loss: 0.0063 - val_loss: 0.0059
Epoch 10/10
469/469 [==============================] - 8s 17ms/step - loss: 0.0060 - val_loss: 0.0058
313/313 [==============================] - 3s 8ms/step
八、结论
堆叠自动编码器是一类强大的神经网络,它彻底改变了深度学习领域。它们在特征学习、降维和数据表示方面表现出色,使其在广泛的应用中具有不可估量的价值。随着深度学习领域的不断发展,堆叠式自动编码器在释放复杂数据潜力方面的重要性怎么强调都不为过。
引用
以下是一些与堆叠式自动编码器及其应用相关的开创性和值得注意的论文:
- Vincent,P.,Larochelle,H.,Lajoie,I.,Bengio,Y.和Manzagol,PA(2010)。堆叠去噪自动编码器:使用局部去噪标准在深度网络中学习有用的表示。机器学习研究杂志, 11, 3371–3408.
- Bengio,Y.,Lamblin,P.,Popovici,D.和Larochelle,H.(2007)。深度网络的贪婪分层训练。在神经信息处理系统进展中(第 153-160 页)。
- Ranzato,M.,Huang,FJ,Boureau,Y.L.和LeCun,Y.(2007)。不变特征层次结构的无监督学习及其在对象识别中的应用。在 2007 年 IEEE 计算机视觉和模式识别会议论文集(第 1-8 页)中。
- Hinton,GE和Salakhutdinov,R.R.(2006)。使用神经网络降低数据的维数。科学,313(5786),504-507。
- Vincent,P.,Lajoie,I.,Bengio,Y.,Manzagol,PA和Paquet,D.(2010)。堆叠去噪自动编码器:使用局部去噪标准在深度网络中学习有用的表示。机器学习研究杂志, 11(Dec), 3371–3408.
请注意,这些论文的可用性可能会有所不同,有些可能需要访问学术数据库或期刊。您可以在 Google Scholar、arXiv 或学术图书馆网站等平台上搜索这些论文。
参考资料:
埃弗顿·戈梅德