一.SSM整合Redis
1.pom配置
用于解决运行时没有将数据库配置信息jdbc.properites加载到target文件中
<resource>
<directory>src/main/resources</directory>
<includes>
<include>*.properties</include>
<include>*.xml</include>
</includes>
</resource>2.配置spring-redis.xml
2.1 注册redis.properties
redis.hostName=localhost
redis.port=6379
redis.password=123456
redis.timeout=10000
redis.maxIdle=300
redis.maxTotal=1000
redis.maxWaitMillis=1000
redis.minEvictableIdleTimeMillis=300000
redis.numTestsPerEvictionRun=1024
redis.timeBetweenEvictionRunsMillis=30000
redis.testOnBorrow=true
redis.testWhileIdle=true
redis.expiration=36002.2 配置redis连接池
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!--最大空闲数-->
<property name="maxIdle" value="${redis.maxIdle}"/>
<!--连接池的最大数据库连接数 -->
<property name="maxTotal" value="${redis.maxTotal}"/>
<!--最大建立连接等待时间-->
<property name="maxWaitMillis" value="${redis.maxWaitMillis}"/>
<!--逐出连接的最小空闲时间 默认1800000毫秒(30分钟)-->
<property name="minEvictableIdleTimeMillis" value="${redis.minEvictableIdleTimeMillis}"/>
<!--每次逐出检查时 逐出的最大数目 如果为负数就是 : 1/abs(n), 默认3-->
<property name="numTestsPerEvictionRun" value="${redis.numTestsPerEvictionRun}"/>
<!--逐出扫描的时间间隔(毫秒) 如果为负数,则不运行逐出线程, 默认-1-->
<property name="timeBetweenEvictionRunsMillis" value="${redis.timeBetweenEvictionRunsMillis}"/>
<!--是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个-->
<property name="testOnBorrow" value="${redis.testOnBorrow}"/>
<!--在空闲时检查有效性, 默认false -->
<property name="testWhileIdle" value="${redis.testWhileIdle}"/>
</bean>2.3 配置连接工厂
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory"
destroy-method="destroy">
<property name="poolConfig" ref="poolConfig"/>
<!--IP地址 -->
<property name="hostName" value="${redis.hostName}"/>
<!--端口号 -->
<property name="port" value="${redis.port}"/>
<!--如果Redis设置有密码 -->
<property name="password" value="${redis.password}"/>
<!--客户端超时时间单位是毫秒 -->
<property name="timeout" value="${redis.timeout}"/>
</bean>2.4 配置序列化器
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="connectionFactory"/>
<!--如果不配置Serializer,那么存储的时候缺省使用String,如果用User类型存储,那么会提示错误User can't cast to String!! -->
<property name="keySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
</property>
<property name="valueSerializer">
<bean class="org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer"/>
</property>
<property name="hashKeySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
</property>
<property name="hashValueSerializer">
<bean class="org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer"/>
</property>
<!--开启事务 -->
<property name="enableTransactionSupport" value="true"/>
</bean>2.5 配置缓存管理器
<bean id="redisCacheManager" class="org.springframework.data.redis.cache.RedisCacheManager">
<constructor-arg name="redisOperations" ref="redisTemplate"/>
<!--redis缓存数据过期时间单位秒-->
<property name="defaultExpiration" value="${redis.expiration}"/>
<!--是否使用缓存前缀,与cachePrefix相关-->
<property name="usePrefix" value="true"/>
<!--配置缓存前缀名称-->
<property name="cachePrefix">
<bean class="org.springframework.data.redis.cache.DefaultRedisCachePrefix">
<constructor-arg index="0" value="-cache-"/>
</bean>
</property>
</bean>2.6 配置redis的key生成策略
在Spring框架中,缓存键生成器用于生成缓存中存储的键,以便于识别和检索缓存数据
package com.YU.ssm.redis;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.util.ClassUtils;
import java.lang.reflect.Array;
import java.lang.reflect.Method;
@Slf4j
public class CacheKeyGenerator implements KeyGenerator {
// custom cache key
public static final int NO_PARAM_KEY = 0;
public static final int NULL_PARAM_KEY = 53;
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder key = new StringBuilder();
key.append(target.getClass().getSimpleName()).append(".").append(method.getName()).append(":");
if (params.length == 0) {
key.append(NO_PARAM_KEY);
} else {
int count = 0;
for (Object param : params) {
if (0 != count) {//参数之间用,进行分隔
key.append(',');
}
if (param == null) {
key.append(NULL_PARAM_KEY);
} else if (ClassUtils.isPrimitiveArray(param.getClass())) {
int length = Array.getLength(param);
for (int i = 0; i < length; i++) {
key.append(Array.get(param, i));
key.append(',');
}
} else if (ClassUtils.isPrimitiveOrWrapper(param.getClass()) || param instanceof String) {
key.append(param);
} else {//Java一定要重写hashCode和eqauls
key.append(param.hashCode());
}
count++;
}
}
String finalKey = key.toString();
// IEDA要安装lombok插件
log.debug("using cache key={}", finalKey);
return finalKey;
}
}
生成逻辑:
- 如果方法没有参数,缓存键被设置为类名 + 方法名 + ":0"(
NO_PARAM_KEY)。 - 如果方法有参数,缓存键由类名 + 方法名 + ":" + 参数的组合构成。参数之间用逗号分隔。具体的参数值会被加入到缓存键中,如果参数为
null,则用NULL_PARAM_KEY(53)表示;如果参数是基本数据类型、包装类或字符串,则直接将参数值加入缓存键;如果参数是其他对象类型,则将其hashCode()的返回值加入缓存键。
这样生成的缓存键具有类似以下的形式:
com.example.SomeClass.someMethod:parameter1,parameter2,53,parameter4这个缓存键生成器的实现允许在方法参数不同的情况下生成不同的缓存键,以便于确保缓存的正确性
3.Springcontext.xml中添加spring-redis.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd">
<!--1. 引入外部多文件方式 -->
<bean id="propertyConfigurer"
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="systemPropertiesModeName" value="SYSTEM_PROPERTIES_MODE_OVERRIDE" />
<property name="ignoreResourceNotFound" value="true" />
<property name="locations">
<list>
<value>classpath:jdbc.properties</value>
<value>classpath:redis.properties</value>
</list>
</property>
</bean>
<import resource="applicationContext-mybatis.xml"></import>
<import resource="spring-redis.xml"></import>
<import resource="applicationContext-shiro.xml"></import>
</beans>
注意点:
1.当spring上下文中的注册信息文件出现两个及以上,不能在单独的配置文件信息中进行配置,要全部整合到spring上下文的配置文件中进行配置
2.当有*.properties文件需要编译时要到pom文件中进行配置


二.Redis的注解式开发
1.简介
-
简化代码:注解式开发可以显著减少与Redis相关的样板代码。通过使用注解,你可以在方法上直接标记缓存操作,而不必在每个方法中手动编写缓存逻辑。
-
提高开发效率:通过使用注解,开发者可以更容易地实现缓存功能,减少了手动处理缓存的复杂性。这使得开发者可以专注于业务逻辑的实现,而不必花费过多时间在缓存的管理和维护上。
-
降低错误风险:手动管理缓存可能会导致错误,例如忘记在适当的时机清除缓存,或者在更新数据时没有及时更新缓存。使用注解可以减少这些潜在的错误,提高了代码的可靠性。
-
提升性能:通过缓存常用数据,可以显著提升应用程序的性能和响应速度。注解式开发使得缓存的使用变得更加便捷,可以更灵活地选择何时以及如何使用缓存。
-
减少重复劳动:在传统的手动缓存管理中,你可能会在每个方法中都编写类似的缓存逻辑。通过使用注解,可以将缓存逻辑抽象到通用的注解中,从而减少了重复的劳动。
-
提升可维护性:通过使用注解,缓存的管理变得更加集中和清晰。开发者可以在方法上直接看到哪些操作会涉及到缓存,从而使得代码更易于理解和维护。
总的来说,使用Redis的注解式开发可以简化缓存管理,提高开发效率,降低错误风险,提升应用程序的性能,减少重复劳动,同时也提升了代码的可维护性
2.实际开发应用
2.1 测试方法
@CachePut(value = "xx",key = "'cid:'+#cid",condition = "#cid > 6")
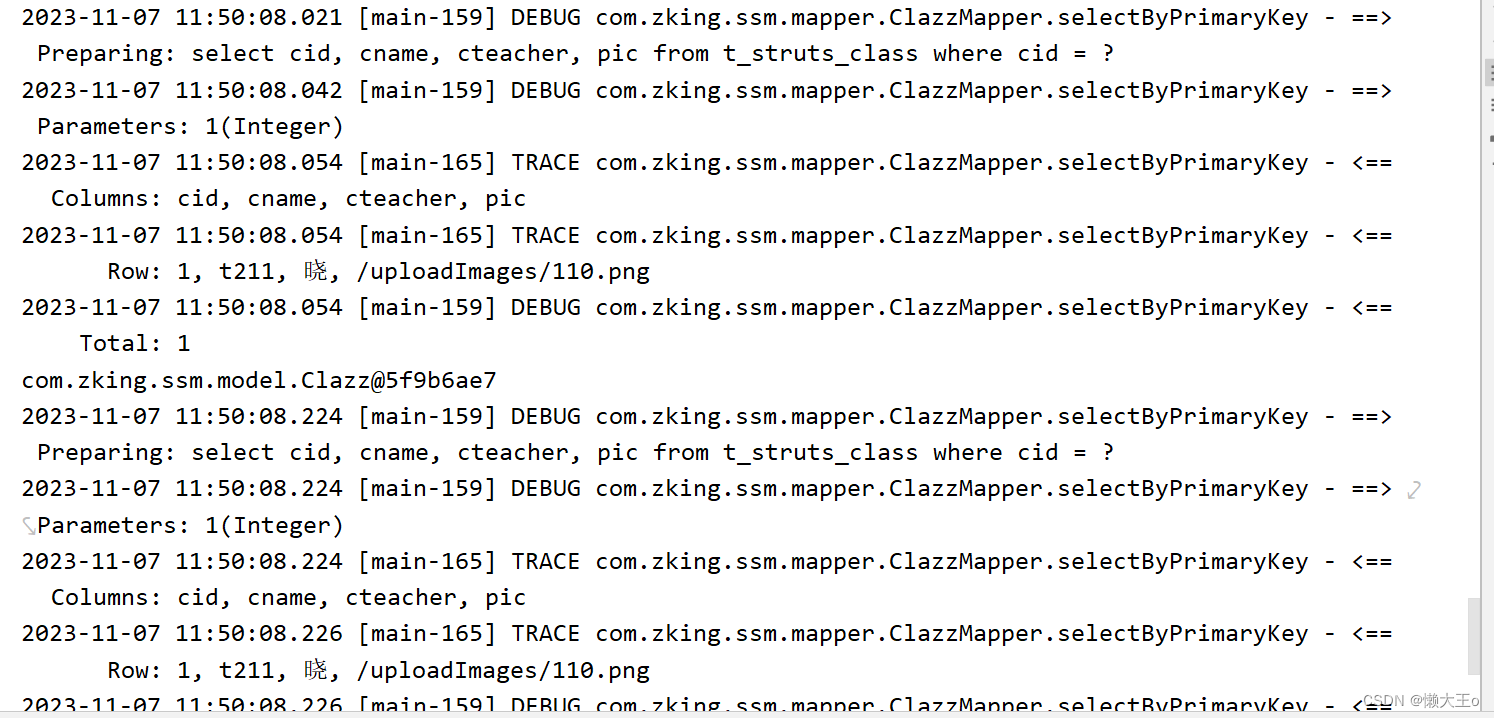
Clazz selectByPrimaryKey(Integer cid);测试类
@Test
public void test1(){
System.out.println(clazzBiz.selectByPrimaryKey(10));
System.out.println(clazzBiz.selectByPrimaryKey(10));
}测试结果
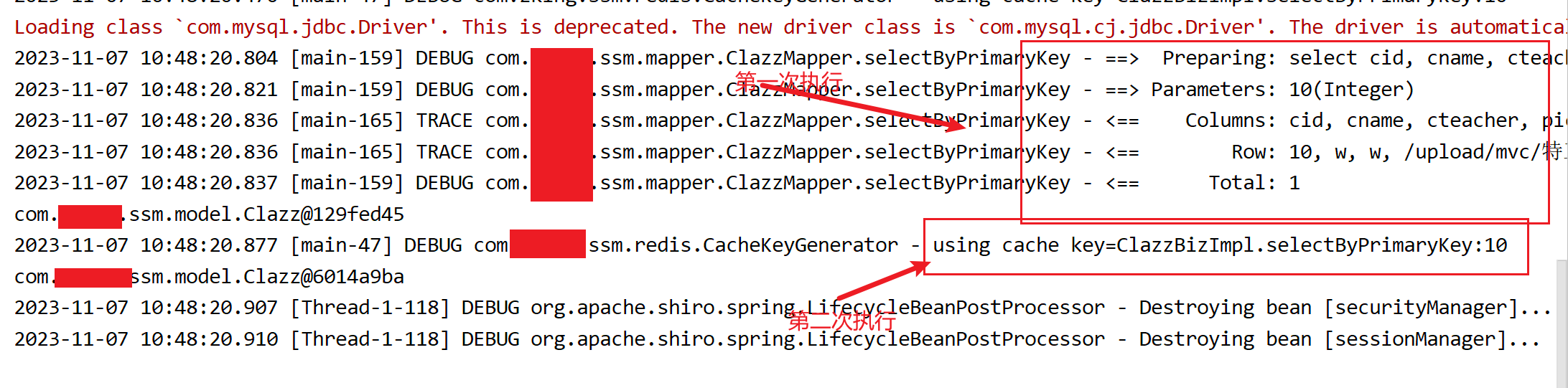
结论:当我们使用redis注解式开发时,第一次执行会查询我们的关系型数据库,但是在执行完成后会加入我们的缓存中,在第二次进行查询时,会查询我们的缓存,也就是查询我们的redis,这样做大大提高了我们查询的效率,而且还可以减轻我们数据库的压力
2.2 @Cacheable和Cacheput的区别
(1)@Cacheable
@Cacheable 注解用于标记一个方法的结果应该被缓存,以便下次相同的方法调用可以直接返回缓存的结果,而不必再次执行方法体。它有以下主要属性:
-
value:指定缓存的名称,通常用于区分不同的缓存。 -
key:用于指定缓存的键值,可以是 SpEL 表达式,根据方法的参数动态生成缓存的键。 -
condition:指定一个 SpEL 表达式,如果为true,则进行缓存,否则不进行缓存。 -
unless:与condition相反,如果为true,则不进行缓存。
(2)@CachePut:
@CachePut 注解用于标记一个方法的结果应该被存储到缓存中,通常在创建或更新操作后使用。与 @Cacheable 不同,它不检查缓存中是否已存在相同的键,而是强制将方法的结果存储到缓存中。它的主要属性包括:
value:指定缓存的名称。key:用于指定缓存的键值,通常也可以使用 SpEL 表达式。condition:指定一个 SpEL 表达式,如果为true,则进行缓存,否则不进行缓存。unless:与condition相反,如果为true,则不进行缓存。
小结:
@Cacheable用于从缓存中获取数据,如果数据已存在于缓存中,将直接返回缓存数据,否则执行方法体并将结果存储到缓存中。@CachePut用于强制将方法的结果存储到缓存中,无论之前是否存在相同的缓存键。- 两者都可以使用
value属性来指定缓存的名称,以及key属性来指定缓存的键。条件判断可以使用condition和unless属性来控制是否执行缓存操作。这些注解通常与缓存管理器(如EhCache、Redis等)一起使用,以配置和管理应用程序中的缓存
2.3 @CacheEvict
主要作用:在方法执行之后从缓存中移除特定的条目,以保持缓存的一致性。下面是 @CacheEvict 的一些主要特点和用法:
-
清除缓存条目:
@CacheEvict主要用于清除指定缓存中的某个或某些缓存条目。
-
注解属性:
value:用于指定要清除的缓存的名称。key:用于指定要清除的缓存条目的键,支持使用 SpEL 表达式动态生成。allEntries:如果设置为 true,表示清除指定缓存中的所有条目。beforeInvocation:指定是否在方法执行之前执行缓存清除操作。默认情况下,在方法执行之后清除缓存,但如果设置为 true,将在方法执行之前清除缓存。
-
条件清除:
- 可以使用
condition和unless属性来进行条件清除,类似于@Cacheable和@CachePut。
- 可以使用
@CacheEvict(value = "myCache", key = "#userId")
public void deleteUserFromCache(String userId) {
}
三.解决Redis缓存问题
Redis的击穿、穿透、雪崩是三种与缓存相关的常见问题,它们通常被统称为"缓存问题三兄弟"
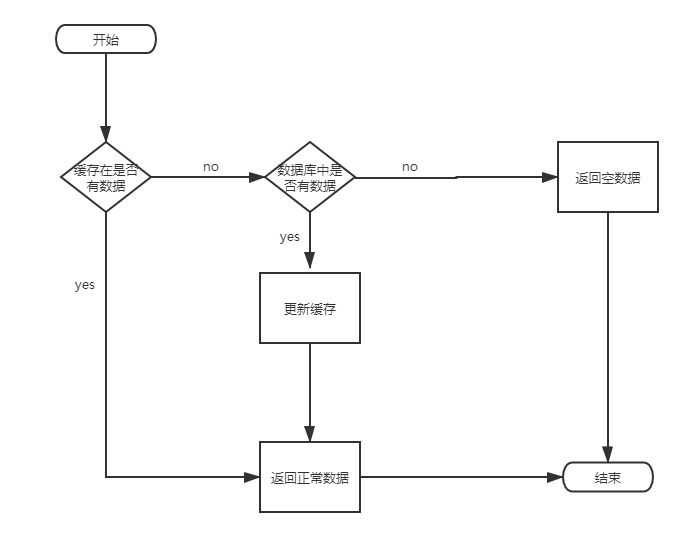
1.缓存查询
要理解缓存击穿,首先要理解redis的缓存查询

Redis 缓存查询是指在使用 Redis 作为缓存时,应用程序首先尝试从 Redis 缓存中获取数据,如果缓存中存在数据,那么可以直接返回,从而减轻后端数据库的负担。这是缓存的正常使用场景,它可以大大提高应用程序的性能和响应时间。
常见的 Redis 缓存查询流程如下:
- 应用程序检查 Redis 缓存中是否存在所需数据。
- 如果数据存在,应用程序直接从 Redis 中获取并返回数据。
- 如果数据不存在,应用程序从后端数据库中获取数据,并将其存储到 Redis 缓存中,以供后续查询使用。
2.Redis击穿
Redis 缓存击穿是指在大并发情况下,有大量的请求同时查询某个不存在于缓存中的数据,导致这些请求都穿透 Redis 缓存,直接访问后端数据库。这会导致数据库负载急剧增加,降低了性能,甚至可能导致数据库宕机。
主要原因是某个热点数据失效,然后有大量请求同时尝试获取相同的数据,而这个数据不在缓存中。解决 Redis 缓存击穿问题的方法包括:
- 使用互斥锁:在缓存失效时,使用互斥锁来阻止多个线程同时访问后端数据库,只有一个线程去加载数据,其他线程等待加载完成后再从缓存中获取。
- 设置短暂的缓存过期时间:即使数据失效,也不至于在短时间内导致大量请求穿透缓存。
- 预热缓存:在启动应用程序时,加载一些热门数据到缓存中,以减少冷启动时的击穿问题。
小结:
Redis 缓存查询是一种有效的性能优化手段,但在高并发情况下可能会出现缓存击穿问题。为了解决击穿问题,可以采取锁、合理的缓存设置以及预热等策略,以保护后端数据库免受不必要的负担
3.Redis穿透
3.1 简介
Redis 缓存穿透是指恶意或异常请求,通常是查询一个不存在于缓存中的键,导致大量请求穿透 Redis 缓存,直接访问后端数据存储系统(通常是数据库)。这种情况会增加后端数据库的负担,降低性能,甚至导致数据库崩溃
-
恶意请求:攻击者故意发送不存在于缓存中的键来进行恶意攻击,例如通过构造恶意的查询参数。
-
异常查询:当应用程序中没有足够的保护来处理异常情况时,可能会导致查询非常频繁的不存在的键,例如使用无效的用户标识。
3.2 解决措施
-
缓存空对象或哨兵值:当一个请求查询到不存在的数据时,可以将一个特殊的哨兵值(如null)存储在缓存中,以表示该键确实在数据存储中不存在。这样,在下一次请求相同键时,可以立即从缓存中获取哨兵值而不访问数据库,从而减轻数据库负担。
-
使用布隆过滤器:布隆过滤器是一种数据结构,可以用于快速确定某个数据是否存在于缓存中。如果布隆过滤器显示数据不存在,可以直接拒绝查询,而不访问数据库或缓存。这可以有效减少缓存穿透。
-
合理设置缓存失效时间:设置合适的缓存失效时间,避免长时间持有无效的缓存数据。这样可以防止在失效期间频繁访问数据库。
-
限制请求频率:在应用程序层面,可以实施请求频率限制,以防止频繁的请求击穿缓存。
小结:
防止 Redis 缓存穿透需要综合考虑多种策略,包括设置合理的缓存策略、使用哨兵值或布隆过滤器,以及在应用程序中增加异常查询的保护
4.Redis雪崩
4.1 简介
Redis 雪崩是指在某个时间点,大量缓存键同时失效,导致大量请求直接访问后端数据存储系统,从而对系统性能和可用性造成严重影响的情况
-
大规模缓存失效:当大量的缓存键在相同时间内失效,通常是因为这些键设置了相同的失效时间,或者是由于系统维护操作(如 Redis 重启)导致的。这会导致大量请求同时涌入后端数据存储系统。
-
热门数据集:如果系统中有一组特别热门的缓存数据,当这些缓存键同时失效并被请求时,会导致大量请求竞争获取相同的数据,增加了后端存储的负载
4.2 解决措施
-
合理设置缓存失效时间:避免将所有缓存键设置相同的失效时间。通过将失效时间分散,可以减少大规模失效的概率。
-
使用随机失效时间:将缓存键的失效时间设置为一个随机值,而不是固定的时间,以避免同时失效。
-
持久化备份:定期将缓存数据持久化到磁盘,以防止 Redis 重启时丢失所有数据。
-
热点数据预热:对于热门的数据集,可以在合适的时机手动刷新缓存,而不是等待缓存失效。
-
分布式缓存:使用多台 Redis 服务器来分担负载,以降低单点故障的风险。
-
请求限流:在应用程序层面,实施请求限流措施,以避免过多的请求同时涌入 Redis。
-
监控和报警:建立监控系统,实时监控 Redis 的性能和状态,以及缓存键的失效情况,及时发现问题并采取措施应对
小结:
总之,防止 Redis 雪崩需要综合考虑多种策略,包括设置合理的失效时间、持久化备份、数据预热、请求限流以及监控系统




![Verilog刷题[hdlbits] :Always case](https://img-blog.csdnimg.cn/f3ba9709a3cb4b118c3602a3fee64230.png)