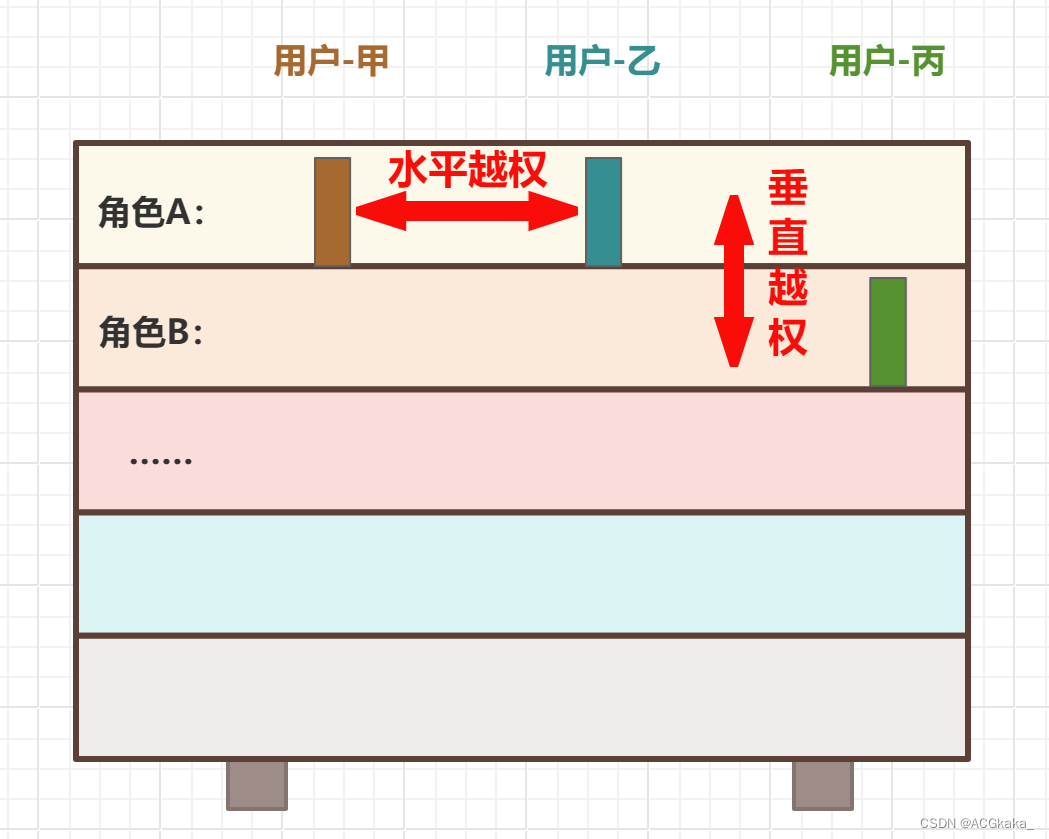
论文标题:
FSDiffReg: Feature-wise and Score-wise Diffusion-guided Unsupervised Deformable Image Registration for Cardiac Images
翻译:
FSDiffReg:心脏图像的特征和分数扩散引导无监督形变图像配准
摘要
无监督可变形图像配准是医学成像领域的一项具有挑战性的任务。在一系列基于深度学习的解决方案中,在保持变形拓扑的同时获得高质量的变形场仍然是一项艰巨的任务。
同时,扩散模型的潜在特征空间显示出潜在的变形语义建模。为了充分利用扩散模型指导配准任务的能力,我们提出了两个模块:
- 特征扩散引导模块(FDG)
- 分数扩散引导模块(SDG)
FDG使用扩散模型的多尺度语义特征来指导变形场的生成。
SDG使用扩散分数来指导优化过程,以在几乎没有任何额外计算的情况下保留变形拓扑。
FDG引入了一种直接特征扩散制导技术,利用交叉注意将扩散模型的中间特征集成到配准网络解码器的隐藏层中,从而产生变形场。此外,我们将特征引导嵌入到配准网络的多个层中,并在多个尺度上产生特征级变形场。最后,在获得多尺度形变场后,对其进行上采样和平均,生成全分辨率形变场进行配准
SDG通过基于扩散分数重新权衡基于相似性的无监督注册损失,为变形拓扑保存引入了明确的分数扩散指导。通过这种重称重方案,在优化过程中给予直接关注,以确保变形拓扑的保留。
Introduce
可变形图像配准是准确估计运动和固定图像对的相同解剖结构之间的非刚性体素对应关系(如变形场)的过程。快速、准确、逼真的图像配准算法对于提高临床实践的效率和准确性至关重要。通过观察病变等动态变化,医生可以更全面地为患者设计治疗方案。
传统的配准方法有:
VoxelMorph 以运动和固定的图像对作为输入,最大化图像对的相似度来训练配准网络。
为了获得更高的精度,大多数无监督方法采用具有多个子网络的级联网络或迭代优化策略。这些策略使得训练过程变得复杂,并且需要大量的计算资源。同时,为了获得更平滑、更真实的变形场,即拓扑保持,许多现有的工作引入了显式的微分同构约束或额外的循环一致性计算。
CycleMorph 在训练过程中利用双向配准一致性来保持拓扑结构
voxelmorphi-diff 采用了基于速度场的变形场和新的差胚估计
SYMNet 采用对称变形场估计来实现这一目标
论文的主要贡献
-
本文提出了一种新的基于特征的扩散引导模块(FDG),该模块利用扩散模型中的多尺度中间特征有效地指导配准网络生成变形场。
-
我们还提出了一个分数扩散引导模块(SDG),它利用扩散模型的分数函数在优化过程中指导变形拓扑保存,而不会产生任何额外的计算负担。
-
在心脏数据集上的实验结果验证了我们提出的方法的有效性。
Method
Baseline Registration Model
- 给定一个固定图像f、移动未对齐图像m和受扰动的噪声图像xt
- 我们将这个输入xin = {f, m, xt}输入配准网络的共享编码器Eβ,然后输入配准解码器Rθ。
- 配准解码器Rθ输出变形场φ,由我们的特征扩散引导模块Gσ引导
- 我们将m和ϕ馈送到空间变换层(STL)以生成扭曲的图像m(ϕ)。
- 通过对基于相似度的损失函数LscoreNCC进行优化,得到最终的配准模型。
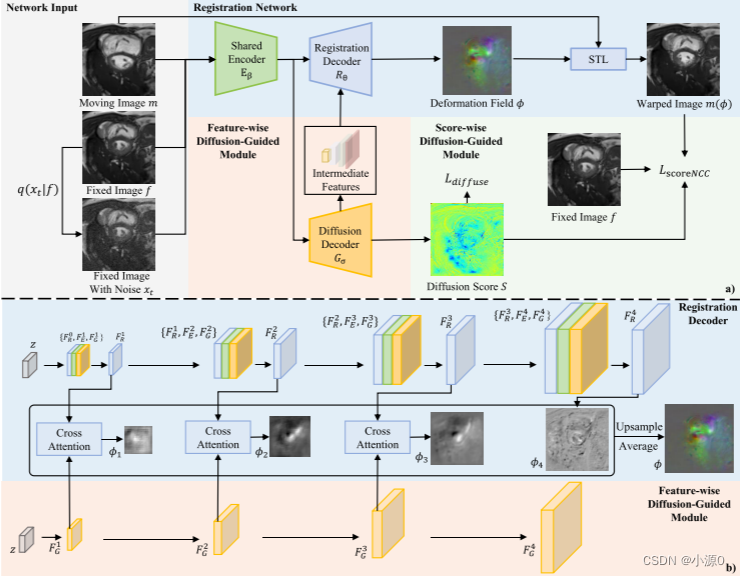
a) FSDiffReg的工作流程。 b)特征扩散引导模块的过程说明。
特征扩散引导模块
- 主要组成是:辅助去噪扩散解码器Gσ
- 给定输入xin = {f, m, xt}, UNet共享编码器Eβ提取表示z
- z再被送入扩散解码器G和配准解码器R,得到中间特征映射对Fi = {(f i G, Fi R)}, i = 1,…,从解码器的第i层取N
- 值得注意的是,我们通过结合来自扩散解码器的制导来生成配准解码器的特征映射
分数扩散引导模块
- 给定由共享编码器z = Eβ(xin)编码的表示z,扩散解码器Gσ输出一个扩散分数估计S = Gσ(z)。然后,基于分数的扩散引导模块(SDG)使用该分数来重新权衡基于相似性的归一化互相关损失函数,
- 通过这种方式,SDG利用扩散分数明确地指出难以注册的区域,即变形拓扑难以保持的区域,然后在损失函数中分配更高的权重以获得更大的关注,反之亦然对于容易注册的区域。因此,SDG模块在没有额外约束的情况下,有效地将变形拓扑信息纳入优化过程
整体训练与推理
损失函数: 我们的网络在特征预测可变形域,然后输出配准的图像。我们的方法的总损失函数定义为
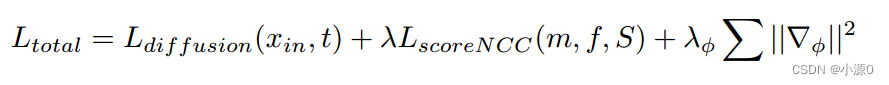
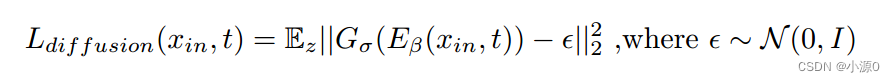
其中Ldiffusion为训练扩散解码器Gσ的辅助损失函数,t为xt的噪声级。我们提出的LscoreNCC鼓励在保持形变拓扑的同时最大限度地提高配准图像和参考图像之间的相似性。||∇φ ||2是变形场的常规平滑惩罚。λ和λ φ是超参数,我们在实验中经验地将它们设置为20。
Inference阶段: 我们将原始的参考图像f输入到网络中,而不是扰动后的图像xt,网络的总输入就变成了xin = {f, m, f}。
给定该网络输入xin,我们的网络首先在运动图像m和参考图像f之间产生变形场φ,并将运动图像m和变形场φ馈送到空间变换层(STL),产生配准的运动图像m(φ)。配准的运动图像是我们网络的最终输出。
实验和结果
数据集与预处理
我们使用公开可用的3D心脏MR数据集ACDC进行实验。该数据集包括100个具有相应分割图的4D时域心脏MRI数据。我们选择舒张末期的3D图像作为固定图像,选择收缩末期的图像作为运动图像。我们将所有扫描重新采样到1.5×1.5×3.15mm的体素间距,然后裁剪为128 × 128 × 32的体素大小。我们将所有图像的强度归一化为[−1,1]。训练集包含90对图像,其余10对图像组成测试集。
实施细节
框架由PyTorch库1.12.0实现的
使用DDPM-UNet的3D编码器作为我们的共享编码器
使用DDPM-UNet的3D解码器作为我们的扩散解码器
对于配准部分,我们只使用DDPM UNet的3D解码器作为配准解码器来生成变形场,而不是完整3D UNet。在扩散任务中,我们在2000个时间步长内逐渐将噪音时间表从10−6增加到10−2。我们使用Nvidia RTX3090 GPU和Adam优化算法来训练模型,其中λ=20,λξ=20,γ=1,批量大小B=1,学习率为2×10−4,最大时间为700个时期。
评估指标
我们采用了三种评估指标,即DICE、|J|≤0(%)和SD(|J|)来衡量图像配准性能,遵循现有的配准方法。DICE测量扭曲的运动图像和固定的参考图像之间的解剖分割图的空间重叠。Dice分数越高表示翘曲的运动图像和固定的参考图像之间的对准越好,从而反映了配准质量的提高|J|≤0(%)表示配准域的雅可比行列式中非正值的百分比。该度量表示缺乏一对一配准映射关系的体素的百分比,从而导致不切实际的变形和粗糙度。SD(|J|)是指配准域的雅可比行列式的标准偏差。较低的标准偏差表示配准场在整个图像上相对平滑和一致。