到这里就是属于原有的知识的扩充了。、
发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯发疯
舒服了
1.MySQL的安装
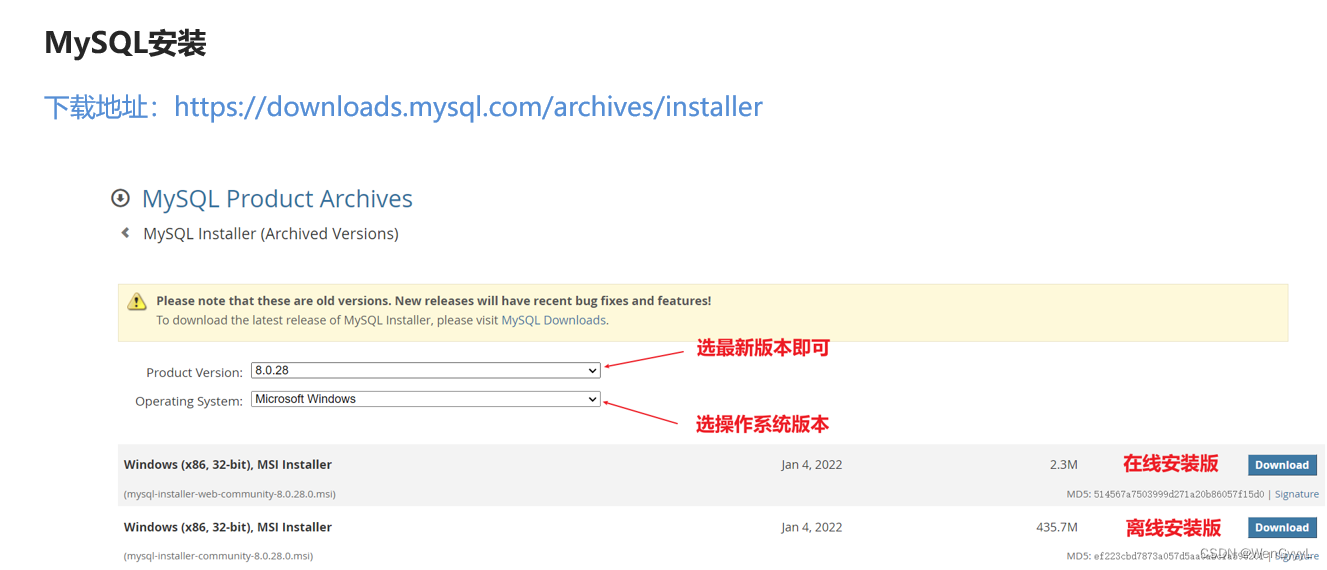
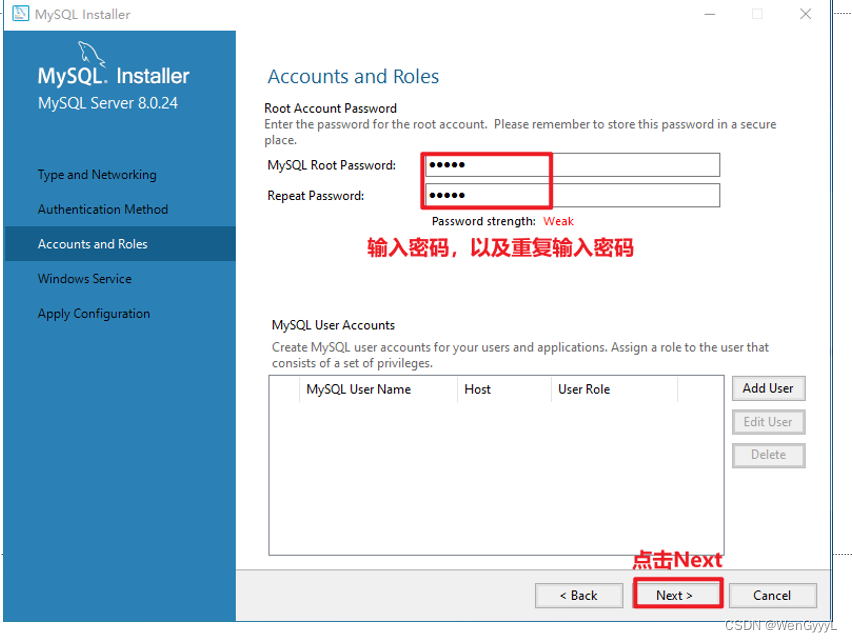
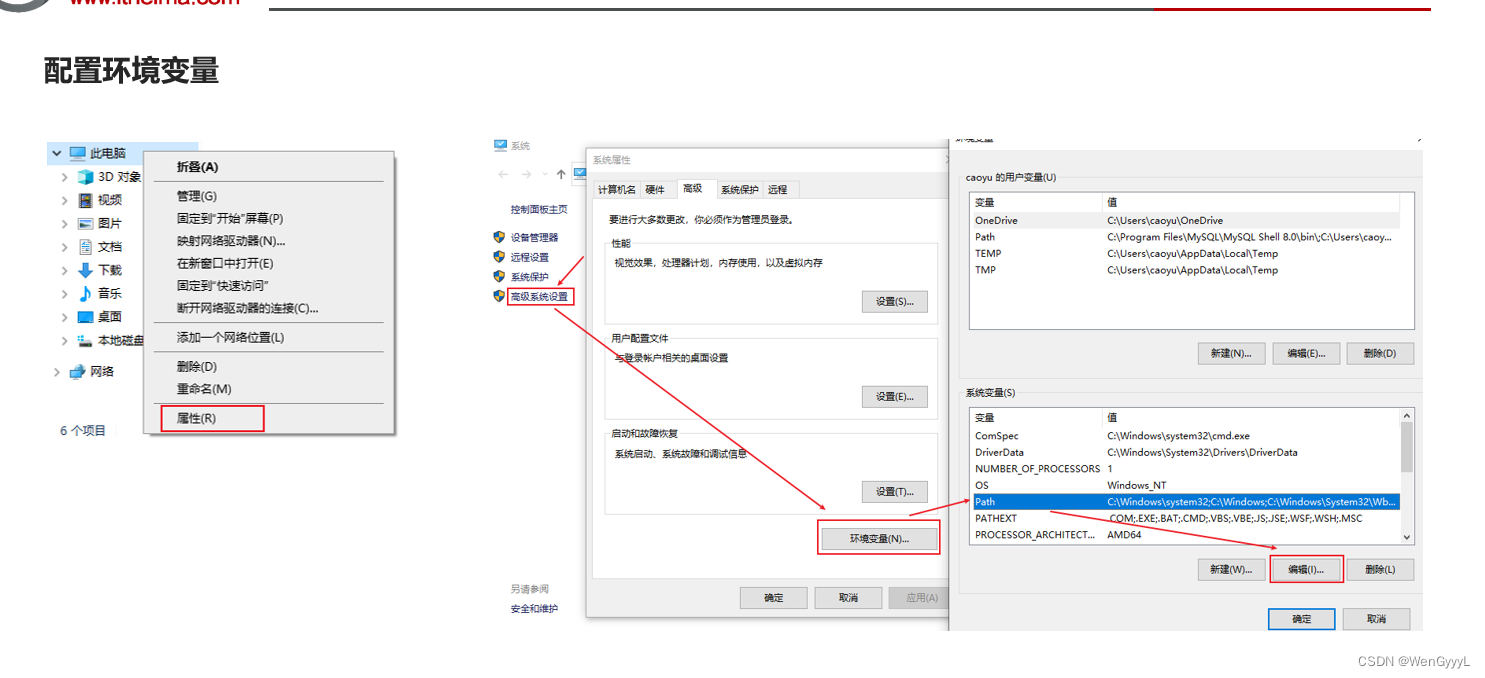
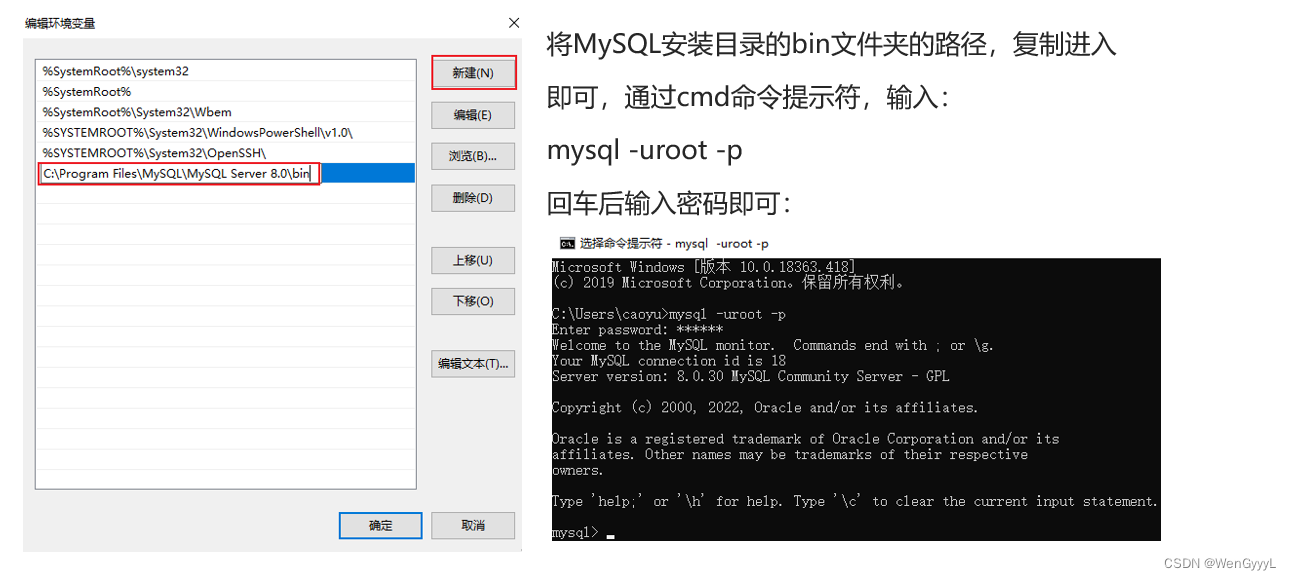
2.了解SQL语言


语法特征

(1)DDL
1.库管理

2.表管理

(2)DML
1.INSERT

2.DELETE

3.UPDATE

(3)DQL
1.查询语句

2.过滤(条件过滤)

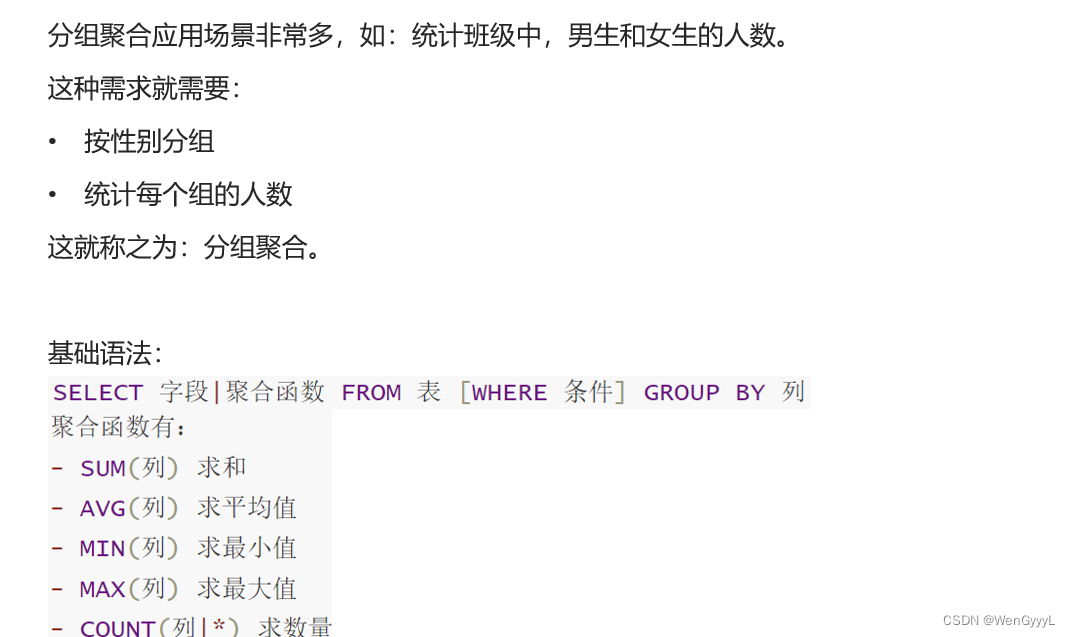
3. 分组聚合(GROUP BY)
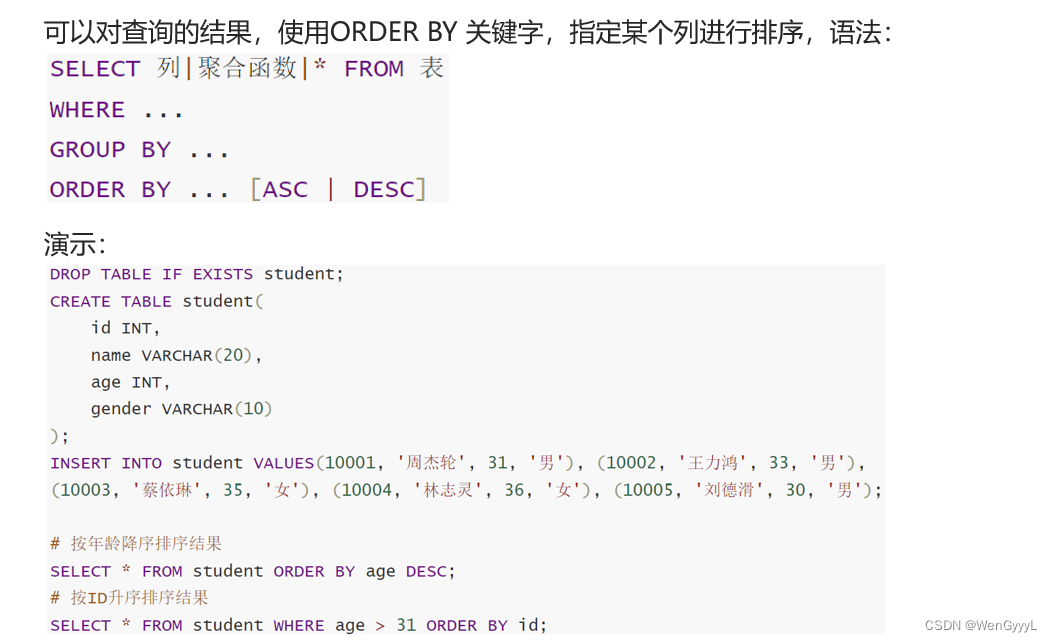
SQL中的ORDER BY语句用于将查询结果按照指定的列进行排序。它可以按照升序或降序排列结果集。
具体语法如下:
``` SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... [ASC|DESC]; ```其中,`column1`, `column2`等表示要排序的列,可以同时按多列排序。`ASC`表示升序排列(默认),`DESC`表示降序排列。
例如,如果要按照某个列的值进行升序排序,可以使用以下语句:
``` SELECT * FROM table_name ORDER BY column1 ASC; ```如果要按照多个列的值进行排序,可以使用以下语句:
``` SELECT * FROM table_name ORDER BY column1 ASC, column2 DESC; ```此语句将首先按照`column1`的升序排列结果集,如果`column1`的值相同,则按照`column2`的降序排列结果集。
ORDER BY语句可以与聚合函数一起使用,例如:
``` SELECT COUNT(*) AS count FROM table_name GROUP BY column1 ORDER BY count DESC; ```此语句将按照某个列的分组结果进行聚合,并将聚合结果按照计数值的降序排列。

4.结果排序(ORDER BY)
5.结果分页(LIMIT)
在SQL中,LIMIT语句用于限制查询结果集的数量。它可以让你只查询出指定范围内的数据。具体语法如下:
``` SELECT column1, column2, ... FROM table_name LIMIT offset, count; ```其中,`offset`指定查询结果集的偏移量(即从第几行开始查询),`count`指定查询结果集的数量(即查询多少行数据)。
例如,如果要查询表中前10条数据,可以使用以下语句:
``` SELECT * FROM table_name LIMIT 0, 10; ```此语句将从第1行开始查询(偏移量为0),查询10行数据。
如果要查询表中的第11~20条数据,可以使用以下语句:
``` SELECT * FROM table_name LIMIT 10, 10; ```此语句将从第11行开始查询,查询10行数据。

3.Python和MySQL的交集
(1)pymysql
(2)连接示例代码

代码示例:
"""
演示python pymysql库的操作
"""
from pymysql import Connection
# 构建连接
conn = Connection(
host="localhost",
port=3306,
user="root",
password="2004"
)
# print(conn.get_server_info())
# 执行非查询性质的sql
cursor = conn.cursor()
# 选择数据库
conn.select_db("db1")
# 执行sql
# cursor.execute("create table test_pymysql(id int);")
# 执行查询性质的sql
cursor.execute("select * from tb_brand")
res = cursor.fetchall()
print(type(res))
print(res)
# 关闭连接
conn.close()
(3)数据插入

需要提交,也这就是事物
手动提交事物
"""
演示python pymysql库的操作
"""
from pymysql import Connection
# 构建连接
conn = Connection(
host="localhost",
port=3306,
user="root",
password="2004"
)
# print(conn.get_server_info())
# 执行非查询性质的sql
cursor = conn.cursor()
# 选择数据库
conn.select_db("db1")
# 执行sql
cursor.execute("insert into tb_brand values(49,'迈首科技', '迈首集团', 313, '迈出第一步', 1)")
# 手动提交事物
conn.commit()
# 关闭连接
conn.close()
自动提交事物
autocommit = True
"""
演示python pymysql库的操作
"""
from pymysql import Connection
# 构建连接
conn = Connection(
host="localhost",
port=3306,
user="root",
password="2004",
autocommit=True
)
# print(conn.get_server_info())
# 执行非查询性质的sql
cursor = conn.cursor()
# 选择数据库
conn.select_db("db1")
# 执行sql
cursor.execute("insert into tb_brand values(50,'迈首科技技术有限公司', '迈首集团', 313, '迈出一大步', 1)")
# 手动提交事物
# conn.commit()
# 关闭连接
conn.close()
4.综合案例
将删一篇文章的数据存入通过py写入数据库中
"""
将面向对象章节最后案例的数据写入数据库
"""
from pymysql import Connection
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
text_file_reader = TextFileReader("D:\\IOText\\DataDoing\\2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:\\IOText\\DataDoing\\2011年2月销售数据JSON.txt")
month_1_data: list[Record] = text_file_reader.read_data()
month_2_data: list[Record] = json_file_reader.read_data()
# 将两个月份的数据合并
all_data: list[Record] = month_1_data + month_2_data
# print(all_data)
# 构建连接对象
conn = Connection(
host="127.0.0.1",
port=3306,
user="root",
password="2004",
autocommit=True
)
# 获取游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("py_sql")
# 组织sql语句
for record in all_data:
sql = (f"insert into orders(order_date, order_id, money, province) "
f"values('{record.date}', '{record.order_id}', {record.money}, '{record.province}')")
# 执行sql语句
cursor.execute(sql)
# print(sql)
conn.close()
另外的两个代码文件在我的另一篇文章第二阶段第一章——面向对象-CSDN博客的最后可以找到,测试数据的文件也有。
拜拜
ヾ( ̄▽ ̄)Bye~Bye~再也不见