spark从0到1 基础知识 一文全
- 1 开发前准备
- 2 spark架构,任务提交流程
- 3 开发中涉及的python知识
学习中的测试学习代码详情代码请见本人github中的sparkcp项目
https://gi@thub.com/define@qq/spa@rkcp
1 开发前准备
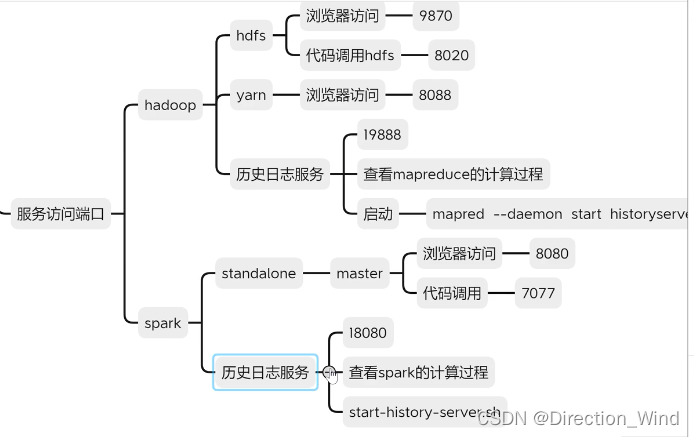
主要是本机使用,所以 安装了个python3,装了个pyspark(pip3 install pyspark),直接装了个3.4的spark,直接命名行敲pyspark,就能以spark.submit.deployMode=client模式启动一个spark,并且自动给了UI地址http://********:4040 供测试是否正常。
2 spark架构,任务提交流程
- 部署方式:local / cluster(使用集群调度,分为 standalone或yarn) / 云服务(阿里maxcompute)
local: 使用单台机器部署。
cluster: 正常集群模式,其中standalone(包含 master 和 worker 两个服务,master只有一个单点故障,worker 可以运行在多台服务器上) ,standalone是spark自带的,yarn是hadoop的。 - mr在调用yarn的资源时,由applicationMaster管理计算任务,所有信息都会汇报给applicationmaster。那么 spark在计算时,由driver管理计算任务,是一个计算程序进程。
spark在计算时:
- 由driver管理计算任务,他本质是一个计算程序的进程
- spark是以线程方式进行计算代码,线程(task )是在executor进程中进行计算,executor就是一个资源空间。
其中standalone是没有applicationMaster的,yarn模式提交会有applicationMaster.。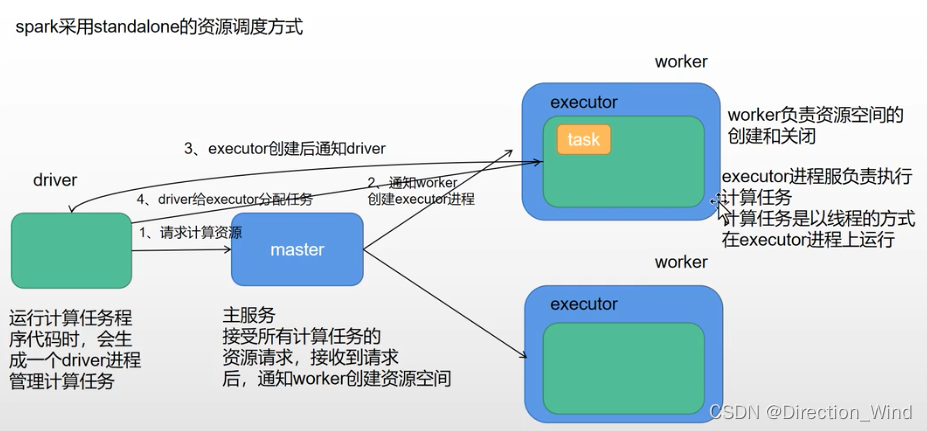
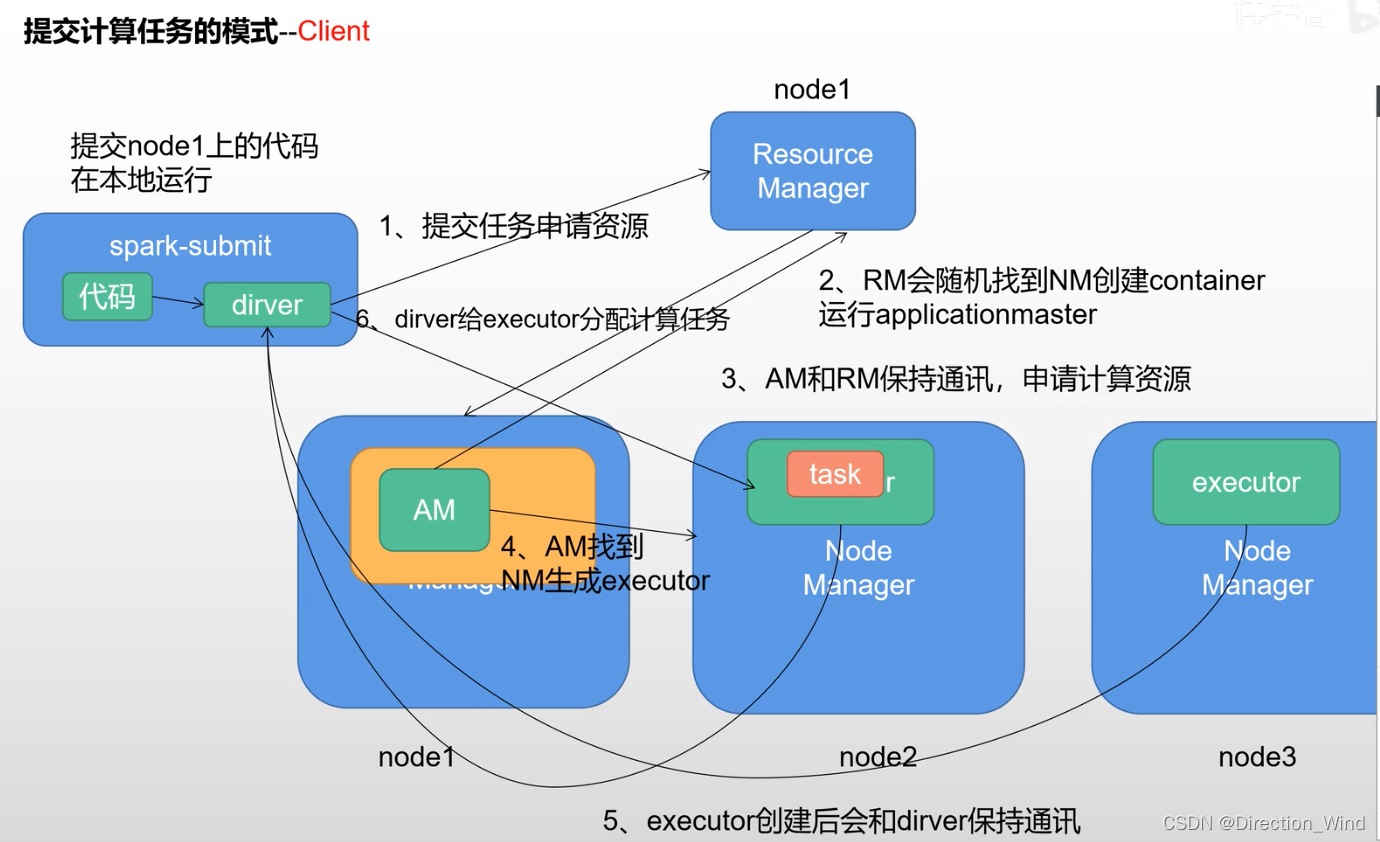
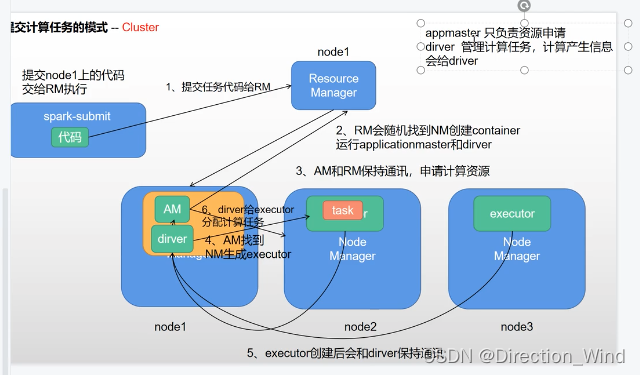
spark-submit --master yarn --name cluster_demo --deploy-mode client/cluster b.py