文章目录
- YARN的由来
- YARN架构分析
- YARN资源管理模型
- YARN中的调度器
- 案例:YARN多资源队列配置和使用
YARN的由来
从Hadoop2开始,官方把资源管理单独剥离出来,主要是为了考虑后期作为一个公共的资源管理平台,任何满足规则的计算引擎都可以在它上面执行。所以YARN可以实现HADOOP集群的资源共享,不仅仅可以跑MapRedcue,还可以跑Spark、Flink。
YARN架构分析
YARN主要负责集群资源的管理和调度 ,支持主从架构,主节点最多可以有2个,从节点可以有多个
其中:ResourceManager:是主节点,主要负责集群资源的分配和管理
NodeManager:是从节点,主要负责当前机器资源管理
YARN资源管理模型
YARN主要管理内存和CPU这两种资源类型
当NodeManager节点启动的时候自动向ResourceManager注册,将当前节点上的可用CPU信息和内存信息注册上去。
这样所有的nodemanager注册完成以后,resourcemanager就知道目前集群的资源总量了。那我们现在来看一下我这个一主两从的集群资源是什么样子的,打开yarn的8088界面
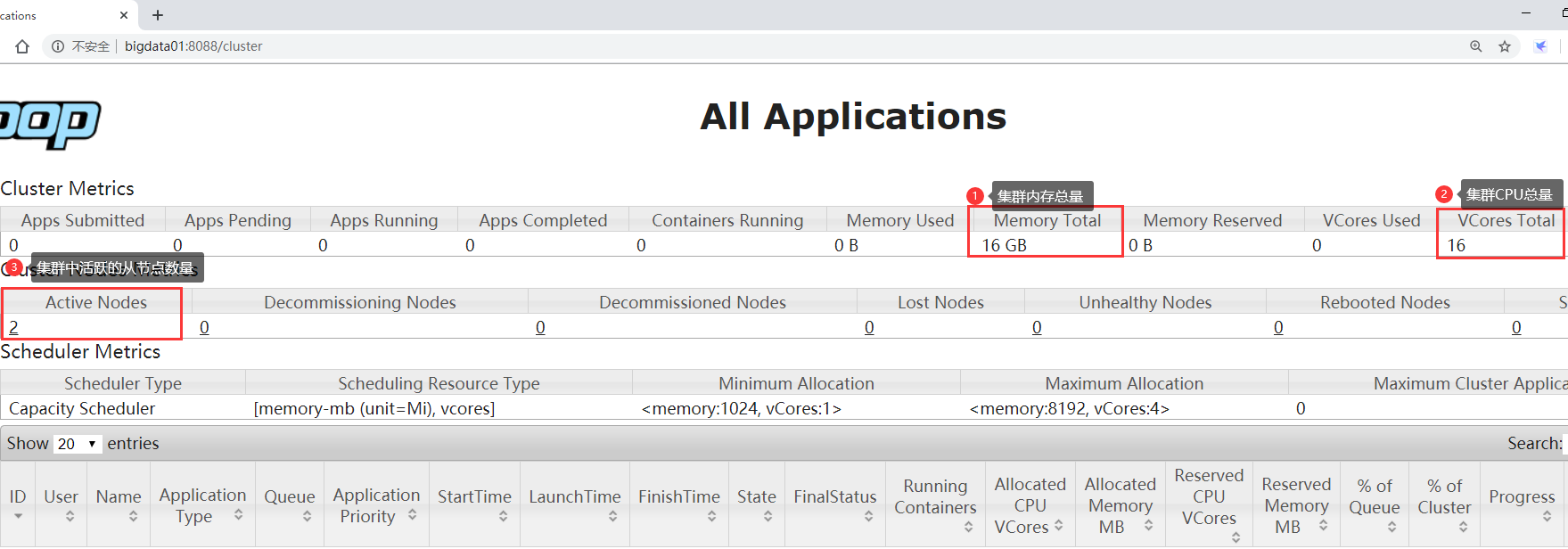
注意,这里面显示的资源是集群中所有从节点的资源总和,不包括主节点的资源,
- yarn.nodemanager.resource.memory-mb:单节点可分配的物理内存总量,默认是8MB*1024,即8G
- yarn.nodemanager.resource.cpu-vcores:单节点可分配的虚拟CPU个数,默认是8
这都是默认单节点的内存和CPU信息,就算你这个机器没有这么多资源,但是在yarn-default.xml中有这些默认资源的配置,这样当nodemanager去上报资源的时候就会读取这两个参数的值,这也就是为什么我们在前面看到了单节点都是8G内存和8个cpu,其实我们的linux机器是没有这么大资源的,那你这就是虚标啊,肯定不能这样干,你实际有多少就是多少,所以我们可以修改这些参数的值,修改的话就在yarn-site.xml中进行配置即可,改完之后就可以看到真实的信息了
YARN中的调度器
YARN中的调度器,这个是非常实用的东西,面试的时候也会经常问到。
大家可以想象一个场景,我们集群的资源是有限的,在实际工作中会有很多人向集群中提交任务,那这时候资源如何分配呢?
如果你提交了一个很占资源的任务,这一个任务就把集群中90%的资源都占用了,后面别人再提交任务,剩下的资源就不够用了,这个时候怎么办?
让他们等你的任务执行完了再执行?还是说你把你的资源匀出来一些分给他,你少占用一些,让他也能慢
具体如何去做这个是由YARN中的调度器负责的
YARN中支持三种调度器
1:FIFO Scheduler:先进先出(first in, first out)调度策略
2:Capacity Scheduler:FIFO Scheduler的多队列版本
3:FairScheduler:多队列,多用户共享资源
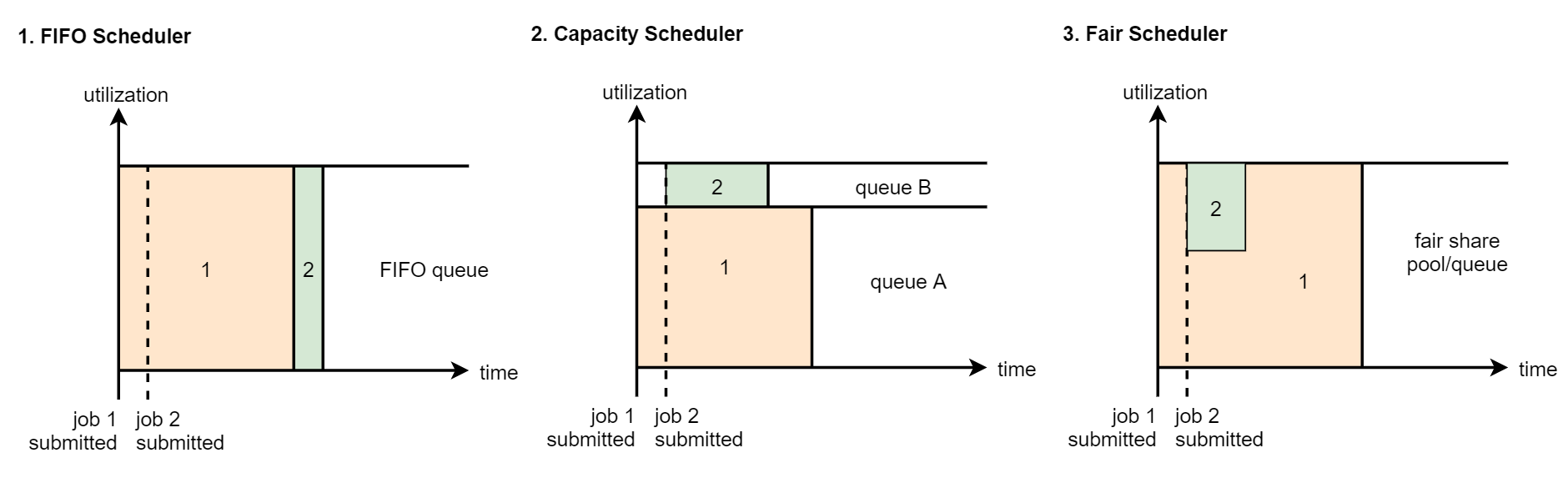
- FIFO Scheduler:是先进先出的,大家都是排队的,如果你的任务申请不到足够的资源,那你就等着,等前面的任务执行结束释放了资源之后你再执行。这种在有些时候是不合理的,因为我们有一些任务的优先级比较高,我们希望任务提交上去立刻就开始执行,这个就实现不了了。
- CapacityScheduler:它是FifoScheduler的多队列版本,就是我们先把集群中的整块资源划分成多份,我们可以人为的给这些资源定义使用场景,例如图里面的queue A里面运行普通的任务,queueB中运行优先级比较高的任务。这两个队列的资源是相互对立的。但是注意一点,队列内部还是按照先进先出的规则。
- FairScheduler:支持多个队列,每个队列可以配置一定的资源,每个队列中的任务共享其所在队列的所有资源,不需要排队等待资源具体是这样的,假设我们向一个队列中提交了一个任务,这个任务刚开始会占用整个队列的资源,当你再提交第二个任务的时候,第一个任务会把他的资源释放出来一部分给第二个任务使用
在实际工作中我们一般都是使用第二种, CapacityScheduler ,从hadoop2开始,CapacitySchedule r也是集群中的默认调度器了。那下面我们到集群上看一下,点击左侧的Scheduler查看
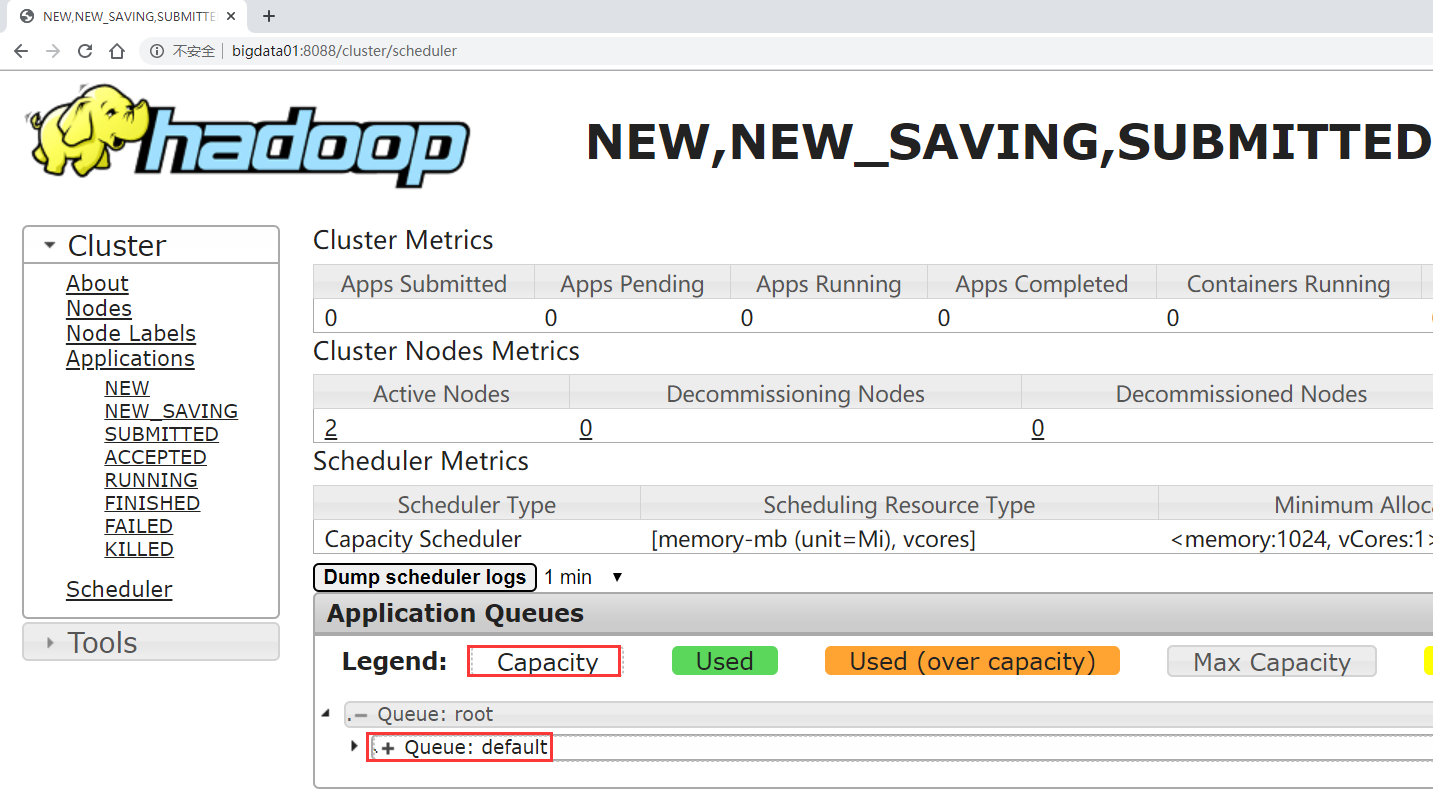
Capacity,这个是集群的调度器类型,
下面的root是根的意思,他下面目前只有一个队列,叫default,我们之前提交的任务都会进入到这个队列中。
案例:YARN多资源队列配置和使用
我们的需求是这样的,希望增加2个队列,一个是online队列,一个是offline队列,然后向offline队列中提交一个mapreduce任务。
- online队列里面运行实时任务
- offline队列里面运行离线任务,我们现在学习的mapreduce就属于离线任务
实时任务我们后面会学习,等讲到了再具体分析。
这两个队列其实也是我们公司中最开始分配的队列,不过随着后期集群规模的扩大和业务需求的增加,后期又增加了多个队列。在这里我们先增加这2个队列,后期再增加多个也是一样的。
具体步骤如下:
修改集群中 etc/hadoop 目录下的 capacity-scheduler.xml 配置文件
修改和增加以下参数,针对已有的参数,修改value中的值,针对没有的参数,则直接增加
这里的 default 是需要保留的,增加 online,offline ,这三个队列的资源比例为 7:1:2
具体的比例需要根据实际的业务需求来,看你们那些类型的任务比较多,对应的队列中资源比例就调高一些,我们现在暂时还没有online任务,所以我就把online队列的资源占比设置的小一些。
先修改bigdata01上的配置
[root@bigdata01 hadoop]# vi capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,online,offline</value>
<description>队列列表,多个队列之间使用逗号分割</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>default队列70%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.capacity</name>
<value>10</value>
<description>online队列10%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.capacity</name>
<value>20</value>
<description>offline队列20%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>70</value>
<description>Default队列可使用的资源上限.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.maximum-capacity</name>
<value>10</value>
<description>online队列可使用的资源上限.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.maximum-capacity</name>
<value>20</value>
<description>offline队列可使用的资源上限.</description>
</property>
修改好以后再同步到另外两个节点上
[root@bigdata01 hadoop]# scp -rq capacity-scheduler.xml bigdata02:/data/soft/
[root@bigdata01 hadoop]# scp -rq capacity-scheduler.xml bigdata03:/data/soft/
然后重启集群才能生效
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
进入yarn的web界面,查看最新的调度器队列信息

注意了,现在默认提交的任务还是会进入default的队列,如果希望向offline队列提交任务的话,需要指定队列名称,不指定就进默认的队列。在这里我们还需要同步微调一下代码,否则我们指定的队列信息 代码是无法识别的。拷贝WordCountJob类,新的类名为 WordCountJobQueue
主要在job配置中增加一行代码
package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 指定队列名称
*/
public class WordCountJobQueue {
/**
* Map阶段
*/
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word : words) {
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2,v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongW
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context co
throws IOException, InterruptedException {
//创建一个sum变量,保存v2s的和
long sum = 0L;
//对v2s中的数据进行累加求和
for(LongWritable v2: v2s){
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+"
//logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try{
//指定Job需要的配置参数
Configuration conf = new Configuration();
//解析命令行中-D后面传递过来的参数,添加到conf中
String[] remainingArgs = new GenericOptionsParser(conf, args).get
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个
job.setJarByClass(WordCountJobQueue.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(remainingArgs[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(remainingArgs[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
}
}
重新编译打包,上传到服务器上面
执行任务
[root@bigdata01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dep

如果我们去掉指定队列名称的配置,此时还会使用default队列
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /outqueue
[root@bigdata01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dep
到yarn中查看任务的信息,显示是在default队列中执行

这就是YARN中调度器多资源队列的配置,在工作中我们只要掌握如何使用这些队列就可以了,具体如何配置是我们向运维同学提需求,他们去配置。