文章目录
- 前言
- 第01节 Selenium概述
- 第02节 安装浏览器驱动(以Google为例)
- 第03节 定位页面元素
- 1. 打开指定页面
- 2. id 定位
- 3. name 定位
- 4. class 定位
- 5. tag 定位
- 6. xpath 定位
- 7. css 选择器
- 8. link 定位
- 9. 示例 有道翻译
- 第04节 浏览器控制
- 1. 修改浏览器窗口大小
- 2. 浏览器前进&后退
- 3. 浏览器刷新
- 4. 浏览器窗口切换
- 5. 常见操作
- 6. 示例 CSDN页面元素交互
- 第05节 鼠标控制
- 1.单击元素
- 2.双击元素
- 3.在元素上右键单击
- 4.在元素上悬停(鼠标悬停)
- 5.拖拽元素到另一个位置
- 第06节 键盘控制
- 1.输入文本
- 2.按键
- 3.组合键
- 4. 其他键盘操作
- 第07节 元素等待
- 1. 隐式等待
- 2. 显示等待
- 3. 自定义等待
- 4. 强制等待
- 第08节 切换操作
- 1. 窗口切换
- 2. 表单切换
- 第09节 滚轮操作
- 总结
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
第01节 Selenium概述
Selenium 是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接运行
在浏览器上,它支持所有主流的浏览器
因为 Selenium 可以控制浏览器发送请求,并获取网页数据,因此可以应用于爬虫领域
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网
站上某些动作是否发生
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用
Selenium 库的版本不同对应的方法名也会有所不同
官方文档:http://selenium-python.readthedocs.io/index.html
第02节 安装浏览器驱动(以Google为例)
1. 确认浏览器版本
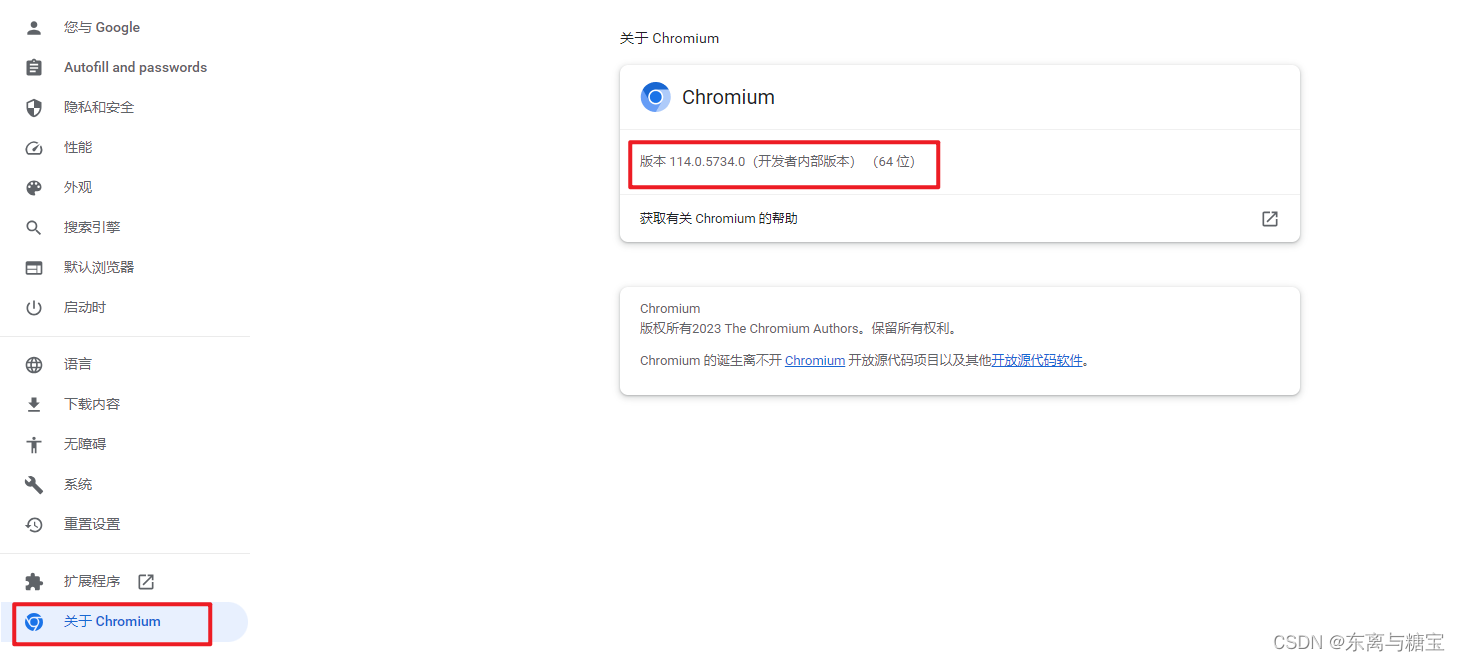
2. 下载对应版本的驱动


3. 如何下载历史版本的 chorm
- 获得浏览器版本号
访问 https://vikyd.github.io/download-chromium-history-version/ ,可能需要科学上网(dddd),然后在 version 下拉里面选择你要的平台,然后在输入框输入版本号,例如 : windows 64位 113.0版本

- 选择浏览器版本并下载压缩包
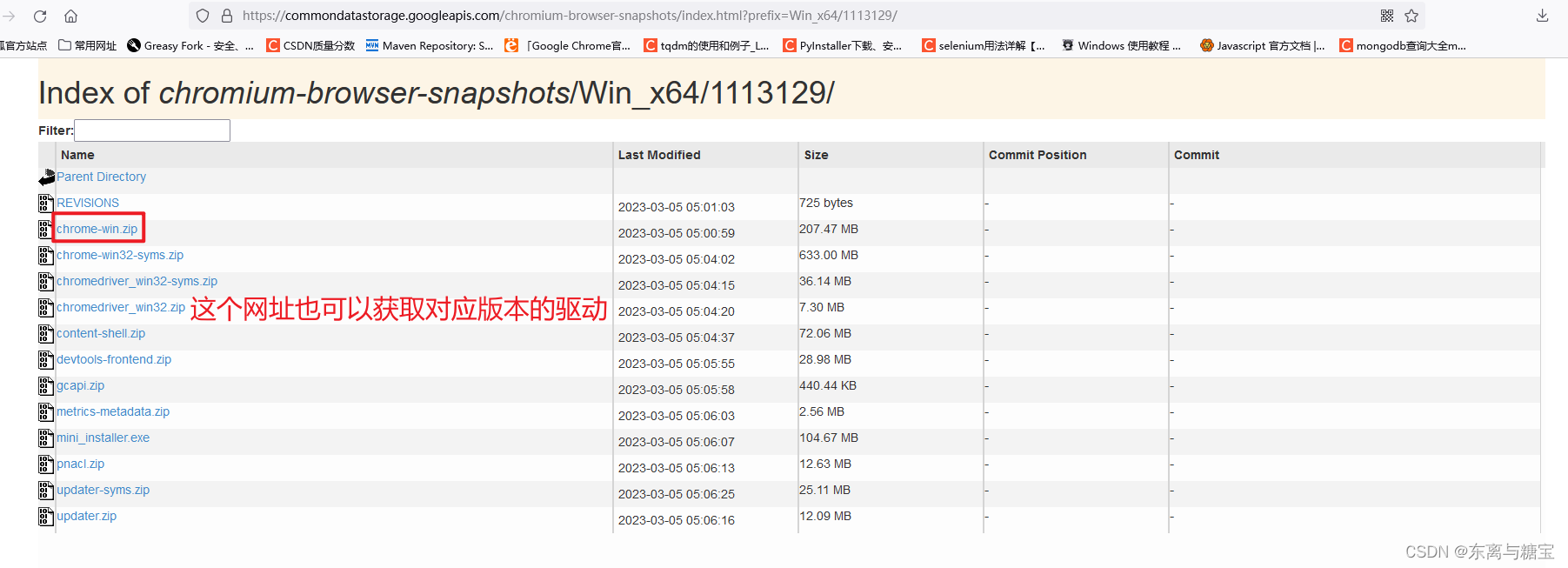
- 下载完成后解压即可使用
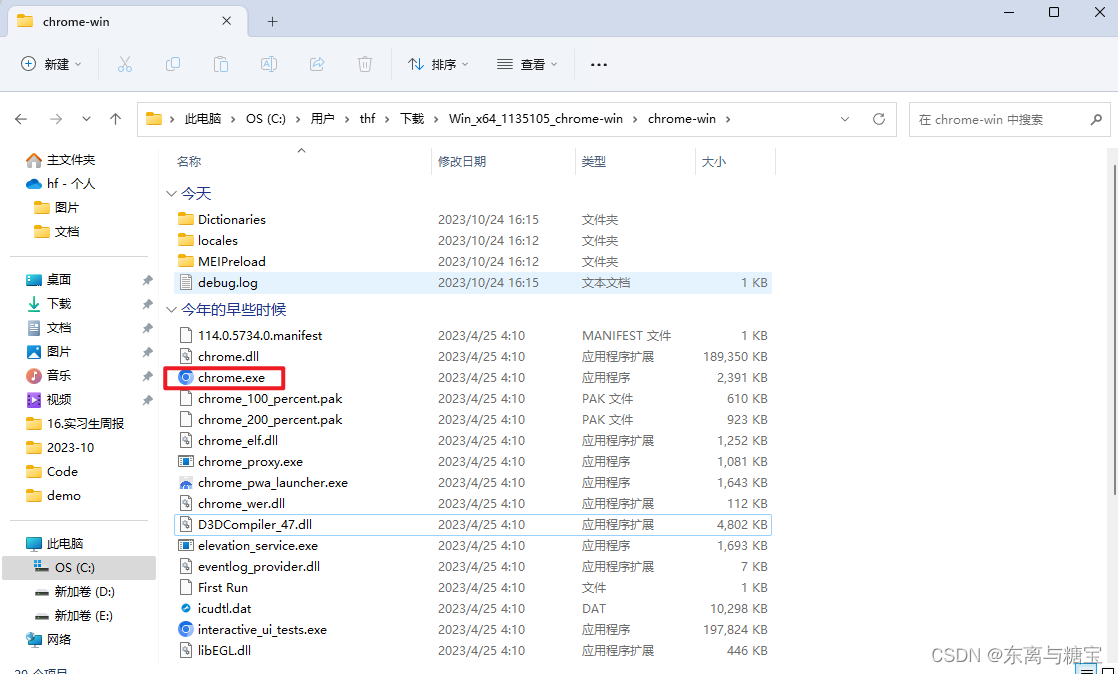
- 将 chromedriver.exe 保存到任意位置,并把当前路径保存到环境变量中(我的电脑>>右键属性>>高级系统设置>>高级>>环境变量>>系统变量>>Path),添加的时候要注意不要把 path 变量给覆盖了,如果覆盖了千万别关机,然后百度。添加成功后使用下面代码进行测试。
# 导入 webdriver
import time
from selenium import webdriver
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
from selenium.webdriver.common.by import By
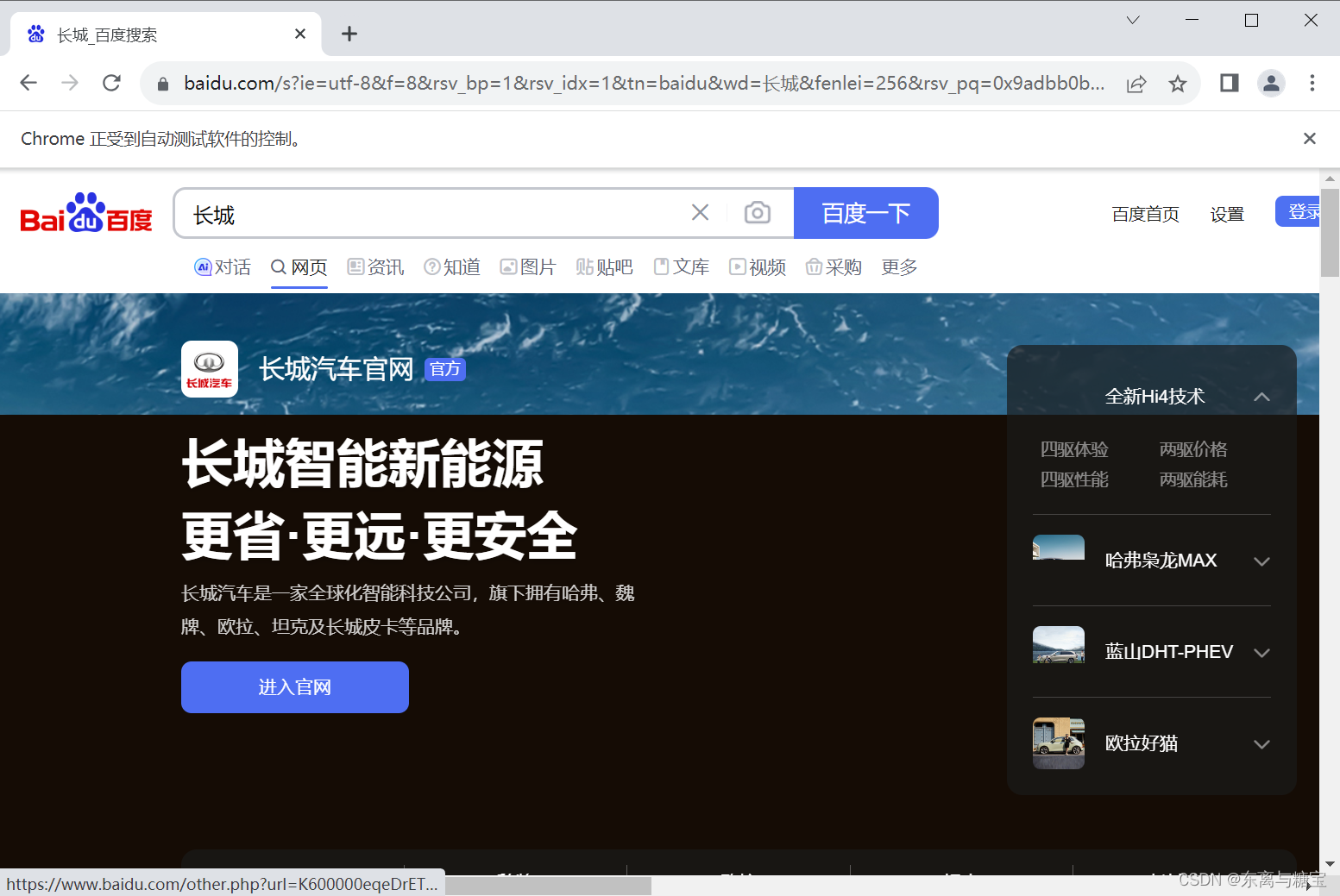
driver = webdriver.Chrome()
# get方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择
driver.get("https://www.baidu.com/")
# id="kw"是百度搜索输入框,输入字符串"长城"
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("长城")
# id="su"是百度搜索按钮,click() 是模拟点击
driver.find_element(By.CSS_SELECTOR,"#su").click()
time.sleep(20)
第03节 定位页面元素
定位一个元素用 element,定位一组元素用 elements
1. 打开指定页面
1. 不切换新窗口
要使用 Selenium 来打开指定页面,首先需要初始化一个 WebDriver 实例,然后使用该实例打开目标页面。下面是一个使用 Python 和 Selenium 的示例,演示如何打开指定的页面:
from selenium import webdriver
# 初始化一个WebDriver实例,这里使用Chrome作为浏览器
driver = webdriver.Chrome()
# 打开指定的页面,将URL替换为你要访问的网页地址
url = "https://www.example.com"
driver.get(url)
# 在这里,你可以执行与打开页面相关的操作
# 最后,关闭浏览器窗口
driver.quit()
在上述代码中,我们首先导入 Selenium 的 webdriver 模块,并初始化了一个 Chrome 浏览器的 WebDriver 实例。然后,使用 get 方法打开指定的页面,将目标网页的 URL 替换为你要访问的网页地址。之后,你可以在页面上执行与你的测试或任务相关的操作,然后使用 quit 方法关闭浏览器窗口
2. 切换新窗口
上面的方法会在当前窗口或标签页中打开一个新的页面,将当前页面替换为新的 URL ,使用 window.open(url) 打开新页面:
driver.execute_script("window.open('https://www.example.com', '_blank');") # 使用JavaScript打开一个新页面
这种方法使用 execute_script 方法执行 JavaScript 代码,在新的浏览器窗口或标签页中打开指定的 URL。'_blank' 参数告诉浏览器在新窗口或标签页中打开 URL。这种方式适用于在新窗口中打开页面,而不替换当前页面
请注意,如果你使用 window.open() 方法打开新页面,你可能需要使用 driver.window_handles 和 driver.switch_to.window() 来管理不同窗口之间的切换,就像后面提到的窗口句柄一样。这可以让你在不同的浏览器窗口中执行操作
总之,execute_script 方法通常与其他 Selenium 方法一起使用,用于执行 JavaScript 以实现特定的交互和操作,但它本身不用于打开新页面
3. 保持浏览器窗口打开
默认情况下,Selenium WebDriver 在脚本执行结束后会关闭浏览器窗口,但通过将选项 "detach" 设置为 True,你可以使浏览器窗口保持打开状态,以便手动进行操作
from selenium import webdriver
# 创建ChromeOptions对象
options = webdriver.ChromeOptions()
# 添加选项,防止浏览器自动关闭
options.add_experimental_option("detach", True)
# 初始化一个WebDriver实例,将选项传递给Chrome
driver = webdriver.Chrome(options=options)
# 打开指定的页面
url = "https://www.csdn.net"
driver.get(url)
# 在这里,你可以执行与打开页面相关的操作
# 手动关闭浏览器时,可以保持它打开
2. id 定位
要使用 Selenium 通过元素的 ID 进行定位,你可以使用 By.ID 选择器和 find_element 方法。以下是如何通过元素的ID进行定位的示例:
from selenium import webdriver
# 初始化一个WebDriver实例,这里使用Chrome作为浏览器
driver = webdriver.Chrome()
# 打开指定的页面
url = "https://www.example.com"
driver.get(url)
# 通过元素的ID进行定位并执行操作
element = driver.find_element(By.ID, "element_id")
# 在这里,你可以执行与该元素相关的操作,例如单击、输入文本等
element.click()
# 最后,关闭浏览器窗口
driver.quit()
在上述示例中,driver.find_element(By.ID, "element_id") 通过元素的ID属性来定位元素,并将其存储在变量 element 中,然后可以执行与该元素相关的操作。记得将 "element_id" 替换为你要查找的元素的实际 ID。
3. name 定位
# 通过元素的name属性进行定位并执行操作
element = driver.find_element(By.NAME,"element_name")
4. class 定位
# 通过元素的CSS类名进行定位并执行操作
element = driver.find_element(By.By.CLASS_NAME, ".element_class")
5. tag 定位
每个 tag 往往用来定义一类功能,所以通过 tag 来识别某个元素的成功率很低,每个页面一般都用很多相同的 tag
# 通过元素的标签名进行定位并执行操作
element = driver.find_element(By.TAG_NAME,"element_tag")
element_tag 在示例代码中代表你要查找的元素的 HTML 标签名,例如 < div >, < a >, < p >等。具体来说,如果你要查找一个 < div > 元素,你可以将 element_tag 替换为 "div" ,如果你要查找一个 < a > 元素,你可以将 element_tag 替换为 "a",以此类推
6. xpath 定位
XPath(XML Path Language)是一种用于在 XML 文档中定位元素的语言,也适用于HTML 文档,因为 HTML 是一种基于 XML 的标记语言的变体。XPath 是一种功能强大的元素定位方法,它允许你准确地定位网页上的元素,无论它们在文档中的位置如何。以下是XPath定位的一些示例:
1. 通过元素名称定位:
- 定位所有的链接元素://a
- 定位所有的段落元素://p
- 定位第一个标题元素://h1
2. 通过元素属性定位:
-
定位具有特定 id 属性的元素:
//*[@id='element_id'] -
定位具有特定 class 属性的元素:
//*[@class='element_class']
3. 通过文本内容定位:
-
定位包含特定文本的元素:
//*[text()='要查找的文本'] -
定位以特定文本开头的元素:
//*[starts-with(text(), '开头文本')] -
定位包含特定文本的链接:
//a[contains(text(), '链接文本')]
4. 通过元素层次结构定位:
-
定位父元素的子元素:
//div[@id='parent_id']/p(查找 id 属性为 'parent_id' 的 < div > 元素下的所有 < p > 元素) -
定位祖先元素的子元素:
//div[@class='grandparent_class']//span(查找 class 属性为 'grandparent_class' 的祖先元素下的所有< span >元素)
5. 使用逻辑运算符:
-
定位同时满足多个条件的元素:
//input[@type='text' and @name='username'](查找type属性为 'text' 且 name 属性为 'username' 的输入框)
这些只是 XPath 的一些基本示例,XPath具有非常丰富的语法和功能,你可以根据需要组合和定制不同的条件来定位元素。在Selenium中,你可以使用 find_element + By.XPATH 方法来实现 XPath 定位,例如:
element = driver.find_element(By.XPATH,"//a[contains(text(), '链接文本')]")
这将查找包含特定文本的链接元素,你可以根据需要修改 XPath 表达式来定位不同的元素。
6. 示例
<html>
<head>...<head/>
<body>
<div id="csdn-toolbar">
<div class="toolbar-inside">
<div class="toolbar-container">
<div class="toolbar-container-left">...</div>
<div class="toolbar-container-middle">
<div class="toolbar-search onlySearch">
<div class="toolbar-search-container">
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
根据上面的标签需要定位 最后一行 input 标签,以下列出了四种方式,xpath 定位的方式多样并不唯一,使用时根据情况进行解析即可。
# 绝对路径(层级关系)定位
driver.find_element(By.XPATH,
"/html/body/div/div/div/div[2]/div/div/input[1]")
# 利用元素属性定位
driver.find_element(By.XPATH,
"//*[@id='toolbar-search-input']"))
# 层级+元素属性定位
driver.find_element(By.XPATH,
"//div[@id='csdn-toolbar']/div/div/div[2]/div/div/input[1]")
# 逻辑运算符定位
driver.find_element(By.XPATH,
"//*[@id='toolbar-search-input' and @autocomplete='off']")
7. css 选择器
CSS 使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性,一般定位速度比 xpath 要快,使用CSS 选择器进行元素定位在 Selenium 中是非常常见和方便的。以下是一些常见的 CSS 选择器示例:
1. 通过元素名称定位:
- 定位所有的链接元素:a
- 定位所有的段落元素:p
- 定位所有的按钮元素:button
2. 通过元素ID定位:
定位具有特定 ID属性的元素:#element_id
element = driver.find_element(By.CSS_SELECTOR,"#element_id")
3. 通过类名定位:
- 定位具有特定 class 属性的元素:.element_class
element = driver.find_element(By.CSS_SELECTOR,".element_class")
4. 通过元素属性定位:
- 定位具有特定属性值的元素:[attribute=‘value’]
element = driver.find_element(By.CSS_SELECTOR,"[name='username']")
5. 通过属性值的部分匹配:
- 定位包含特定属性值的元素:[attribute*=‘value’]
element = driver.find_element(By.CSS_SELECTOR,"[href*='example.com']")
6. 通过组合条件:
- 定位同时满足多个条件的元素:.class1.class2
element = driver.find_element(By.CSS_SELECTOR,".element_class1.element_class2")
7. 子元素定位:
- 定位父元素的子元素:#parent_id > .child_class
element = driver.find_element(By.CSS_SELECTOR,"#parent_id > .child_class")
8. 伪类选择器:
例如 定位鼠标悬停的元素::hover
element = driver.find_element(By.CSS_SELECTOR,"a:hover")
8. link 定位
使用 Selenium 来定位超链接(link)元素通常涉及到查找带有 <a> 标签的元素,这是 HTML 中的链接标签。你可以使用不同的方法来定位超链接,如通过文本内容、链接文本、部分链接文本等。以下是一些常见的链接定位示例:
1.通过链接文本(完全匹配)定位:
使用链接的文本内容来定位,确保文本与链接完全匹配:
# 查找所有链接文本为"下一页"的元素
element = driver.find_elements(By.LINK_TEXT, "文本")
2.通过链接文本(部分匹配)定位:
使用链接的部分文本内容来定位,可以匹配链接文本的一部分:
element = driver.find_element(By.PARTIAL_LINK_TEXT,"部分文本")
例如,如果你的链接文本是"点击这里以获取更多信息",你可以使用"点击这里"或"获取更多信息"来进行部分匹配。
这些方法非常方便,特别是当你知道链接的文本内容时。但请注意,它们对文本大小写敏感,所以确保文本内容的大小写与链接文本匹配。
要查找多个链接,你可以使用 find_element**s**(By.LINK_TEXT, "文本") 或 find_element**s**(By.PARTIAL_LINK_TEXT,"部分文本"),它们会返回一个元素列表,你可以在列表中迭代查找多个链接元素。
示例:
elements = driver.find_elements(By.PARTIAL_LINK_TEXT,"部分文本")
for element in elements:
print(element.text)
这将打印所有包含"部分文本"的链接文本的链接元素。
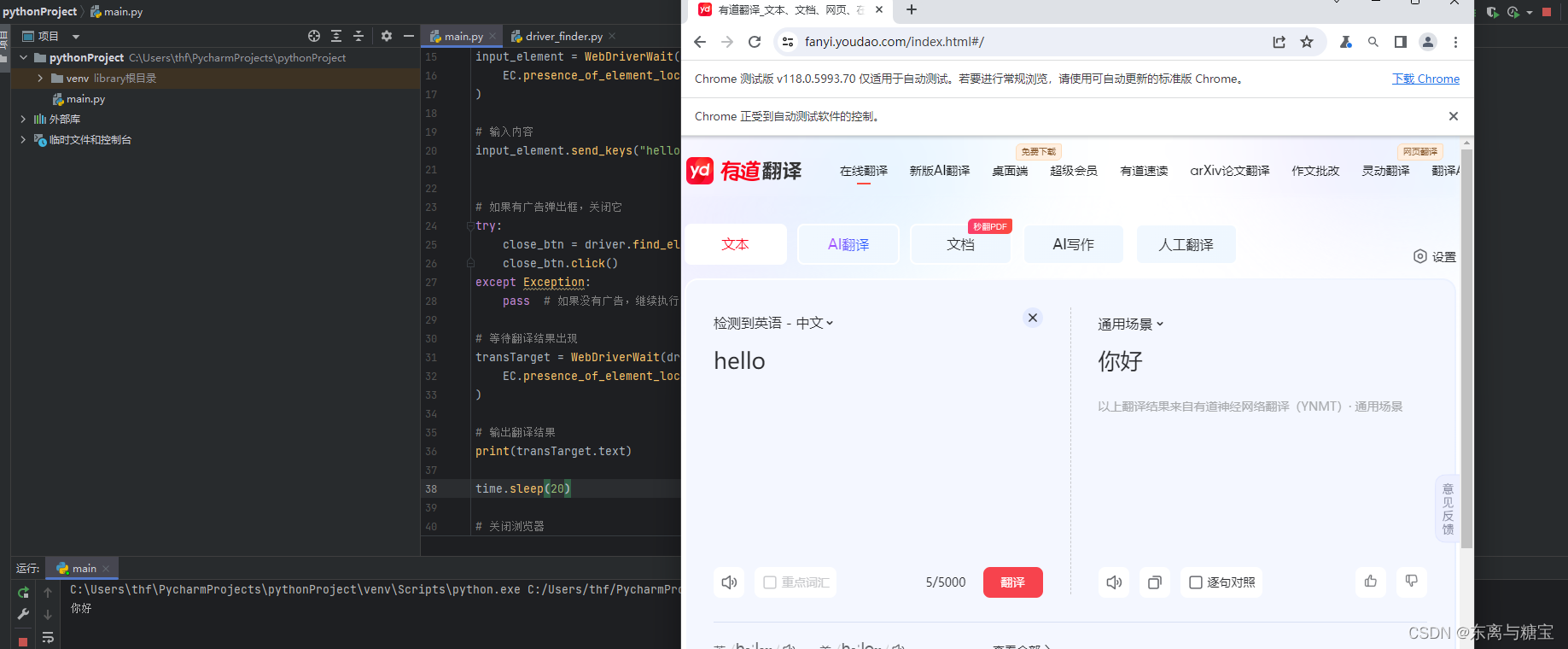
9. 示例 有道翻译
访问有道翻译网站,输入单词,并获取翻译后的内容
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 创建ChromeOptions对象
options = webdriver.ChromeOptions()
# 添加选项,防止浏览器自动关闭
options.add_experimental_option("detach", True)
# 创建Chrome WebDriver
driver = webdriver.Chrome(options=options)
# 打开有道翻译页面
driver.get("https://fanyi.youdao.com/")
# 等待输入框可见
input_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "js_fanyi_input"))
)
# 输入内容
input_element.send_keys("hello")
# 如果有广告弹出框,关闭它
try:
close_btn = driver.find_element(By.CSS_SELECTOR, ".close")
close_btn.click()
except Exception:
pass # 如果没有广告,继续执行
# 等待翻译结果出现
transTarget = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "js_fanyi_output_resultOutput"))
)
# 输出翻译结果
print(transTarget.text)
# 关闭浏览器
# driver.quit()
第04节 浏览器控制
1. 修改浏览器窗口大小
webdriver 提供 set_window_size() 方法来修改浏览器窗口的大小
from selenium import webdriver
# 初始化浏览器驱动程序,这里使用Chrome作为示例
driver = webdriver.Chrome()
# 最大化浏览器窗口
driver.maximize_window()
# 或者设置特定大小的窗口
# driver.set_window_size(1024, 768) # 传递所需的宽度和高度
# 访问网页
driver.get("https://www.example.com")
# 在这里执行其他操作...
# 关闭浏览器
driver.quit()
2. 浏览器前进&后退
要在 Selenium 中执行浏览器的前进和后退操作,你可以使用 forward() 和 back() 方法
# 在这里执行其他操作...
# 执行前进操作
driver.forward()
# 执行后退操作
driver.back()
# 在这里执行其他操作...
请注意,前进和后退操作通常依赖于浏览器的历史记录。如果浏览器历史记录中没有前进或后退的页面,这些方法可能不会执行任何操作。因此,在使用前进和后退之前,确保浏览器已经访问了多个页面以建立历史记录
3. 浏览器刷新
要在Selenium中执行浏览器刷新操作,你可以使用refresh()方法。以下是一个示例,演示如何在Python中使用Selenium来刷新浏览器页面:
from selenium import webdriver
# 刷新浏览器页面
driver.refresh()
这个方法将会重新加载当前页面,就像用户手动点击浏览器的刷新按钮一样。刷新操作可用于重新加载页面内容,以确保你的测试脚本在页面状态变化时可以重新加载页面
4. 浏览器窗口切换
在 Selenium 中,要切换浏览器窗口,你可以使用 window_handles 属性来获取当前打开的所有窗口句柄,然后使用 switch_to.window() 方法切换到特定的窗口句柄。以下是一个示例,演示如何在 Python 中使用 Selenium 来切换浏览器窗口:
from selenium import webdriver
# 初始化浏览器驱动程序,这里使用Chrome作为示例
driver = webdriver.Chrome()
# 打开第一个网页
driver.get("https://www.example1.com")
# 打开第二个网页
driver.execute_script("window.open('https://www.example2.com', '_blank');")
# 获取所有窗口句柄
window_handles = driver.window_handles
# 切换到第二个窗口
driver.switch_to.window(window_handles[1])
# 在第二个窗口执行操作
# 切换回第一个窗口
driver.switch_to.window(window_handles[0])
# 在第一个窗口执行操作
# 关闭浏览器
driver.quit()
在上述示例中,我们首先打开两个不同的网页,然后使用 window_handles 获取所有窗口句柄。通过切换到不同的窗口句柄,我们可以在不同的浏览器窗口中执行操作
请注意,窗口句柄的索引通常是从 0 开始的,所以第一个窗口的句柄是 window_handles[0] ,第二个窗口的句柄是 window_handles[1] ,依此类推。你可以根据需要切换到其他窗口句柄以执行操作
窗口句柄(Window Handle)是一个用来唯一标识浏览器窗口的标识符或引用。每当你打开一个新的浏览器窗口或标签页时,浏览器会为该窗口分配一个唯一的句柄。这些句柄是在浏览器级别分配的,用于标识不同的浏览器窗口或标签页,以便在多窗口浏览器环境中进行切换和操作
在 Selenium 等自动化测试工具中,窗口句柄用于控制和切换不同的浏览器窗口,以便在多个窗口之间执行操作。通过获取窗口句柄,你可以将焦点从一个窗口切换到另一个窗口,从而执行各种操作,例如在不同窗口之间切换、操作弹出窗口等
窗口句柄通常是一个字符串,你可以使用它来定位和操作特定的浏览器窗口。在 Selenium 中,你可以使用 window_handles 属性来获取当前打开的所有窗口句柄,然后使用 switch_to.window() 方法切换到特定的窗口句柄。这使得在多窗口浏览器环境中进行自动化测试或操作变得更加容易
5. 常见操作
当使用 Selenium WebDriver 或类似的自动化测试工具时,这些方法可以用于与 Web 页面的元素进行交互和获取信息。以下是每个方法的使用示例:
1. send_keys(): 模拟输入指定内容
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com")
# 找到输入框元素并输入文本
input_element = driver.find_element_by_id("username")
input_element.send_keys("myusername")
在这个例子中,send_keys() 方法模拟在具有 id 为 “username” 的输入框中输入 “myusername”
2. clear(): 清除文本内容
# 清除输入框中的文本
input_element.clear()
clear() 方法用于清除之前输入框中的文本内容
3. is_displayed(): 判断该元素是否可见
# 检查元素是否可见
if input_element.is_displayed():
print("Input element is visible on the page.")
else:
print("Input element is not visible on the page.")
is_displayed() 方法用于检查页面上的元素是否可见。在这个例子中,如果输入框可见,将会打印 “Input element is visible on the page.”
4. get_attribute(): 获取标签属性值
# 获取元素的href属性值
link_element = driver.find_element_by_link_text("Example Link")
href_value = link_element.get_attribute("href")
print("Href attribute value is:", href_value)
get_attribute() 方法用于获取元素的指定属性的值。在这个例子中,它获取链接文本为 “Example Link” 的元素的 href 属性值
5. size: 返回元素的尺寸
# 获取元素的宽度和高度
element_size = input_element.size
print("Element size is:", element_size)
size 是一个属性,用于返回元素的宽度和高度。在这个例子中,它获取输入框元素的尺寸
6. text: 返回元素文本
# 获取元素的文本内容
paragraph_element = driver.find_element_by_css_selector("p")
paragraph_text = paragraph_element.text
print("Paragraph text is:", paragraph_text)
text 是一个属性,用于返回元素的文本内容。在这个例子中,它获取 <p> 元素的文本内容
6. 示例 CSDN页面元素交互
# coding=utf-8
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
time.sleep(2)
# 定位搜索输入框
text_label = driver.find_element(By.ID, "toolbar-search-input")
# 在搜索框中输入 东离与糖宝
text_label.send_keys('东离与糖宝')
time.sleep(2)
# 清除搜索框中的内容
text_label.clear()
time.sleep(2)
# 输出搜索框元素是否可见
print(text_label.is_displayed())
# 输出placeholder的值
print(text_label.get_attribute('placeholder'))
# 定位搜索按钮
button = driver.find_element(By.ID, 'toolbar-search-button')
# 输出按钮的大小
print(button.size)
# 输出按钮上的文本
print(button.text)
'''输出内容
True
搜CSDN
{'height': 32, 'width': 88}
搜索
'''
第05节 鼠标控制
1.单击元素
左键不需要用到 ActionChains
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://example.com")
element = driver.find_element_by_id("my_element")
# 单击元素
ActionChains(driver).click(element).perform()
2.双击元素
# 双击元素
ActionChains(driver).double_click(element).perform()
3.在元素上右键单击
# 右键单击元素
ActionChains(driver).context_click(element).perform()
4.在元素上悬停(鼠标悬停)
模拟悬停的作用一般是为了显示隐藏的下拉框
# 鼠标悬停在元素上
ActionChains(driver).move_to_element(element).perform()
5.拖拽元素到另一个位置
# 拖拽元素到目标位置
target_element = driver.find_element_by_id("target_element")
ActionChains(driver).drag_and_drop(element, target_element).perform()
第06节 键盘控制
1.输入文本
使用 send_keys 方法可以将文本输入到活动元素中,就像用户手动键入一样
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com")
# 定位到文本输入框并输入文本
text_input = driver.find_element_by_id("my_textbox")
text_input.send_keys("Hello, World!")
2.按键
使用 send_keys 方法可以模拟特定按键的操作,如回车键、退格键、Tab键等。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://example.com")
# 模拟按下回车键
text_input = driver.find_element_by_id("my_textbox")
text_input.send_keys(Keys.ENTER)
3.组合键
你可以使用 Keys 类来模拟键盘上的组合键,例如 Ctrl+C(复制)和Ctrl+V(粘贴)。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://example.com")
# 模拟Ctrl+C(复制)
text_input = driver.find_element_by_id("my_textbox")
text_input.send_keys(Keys.CONTROL, 'c')
# 模拟Ctrl+V(粘贴)
another_text_input = driver.find_element_by_id("another_textbox")
another_text_input.send_keys(Keys.CONTROL, 'v')
4. 其他键盘操作
| 操作 | 描述 |
|---|---|
| Keys.F1 | F1键 |
| Keys.SPACE | 空格 |
| Keys.TAB | Tab键 |
| Keys.ESCAPE | ESC键 |
| Keys.ALT | Alt键 |
| Keys.SHIFT | Shift键 |
| Keys.ARROW_DOWN | 向下箭头 |
| Keys.ARROW_LEFT | 向左箭头 |
| Keys.ARROW_RIGHT | 向右箭头 |
| Keys.ARROW_UP | 向上箭头 |
第07节 元素等待
现在的大多数的 Web 应用程序是使用 Ajax 技术。当一个页面被加载到浏览器时, 该页面内的元素可以在不同的时间点被加载。这使得定位元素变得困难, 如果元素不再页面之中,会抛出 ElementNotVisibleException 异常。 使用 waits, 我们可以解决这个问题。waits 提供了一些操作之间的时间间隔- 主要是定位元素或针对该元素的任何其他操作。
Selenium Webdriver 提供两种类型的 waits - 隐式和显式。 显式等待会让 WebDriver 等待满足一定的条件以后再进一步的执行。 而隐式等待让 Webdriver 等待一定的时间后再才是查找某元素。
1. 隐式等待
隐式等待(Implicit Wait):设置一个全局等待时间,如果 Selenium 无法立即找到元素,它会等待指定的时间,然后再次尝试。这对于整个测试过程都适用
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # 设置等待时间为10秒
driver.get("https://example.com")
element = driver.find_element_by_id("myElement")
2. 显示等待
显式等待(Explicit Wait):显式等待允许你为特定操作等待特定条件。你可以等待元素可见、可点击等条件。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com")
# 等待元素可见
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.ID, "myElement"))
)
# 等待元素可点击
element = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "myElement"))
)
3. 自定义等待
自定义等待:你还可以根据需要创建自定义等待条件。例如,你可以等待元素的文本内容等于特定值。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
def wait_for_element_with_text(driver, by, value, text, timeout=10):
return WebDriverWait(driver, timeout).until(
lambda driver: driver.find_element(by, value).text == text
)
driver = webdriver.Chrome()
driver.get("https://example.com")
# 等待元素文本内容等于特定值
wait_for_element_with_text(driver, By.ID, "myElement", "Hello, World!")
4. 强制等待
将隐式等待改为强制等待(使用 time.sleep())通常不是一个好的做法,因为它会导致代码效率低下并且可能会浪费时间。
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com") # 替换为你要访问的网页URL
# 假设你已经定位到了包含文本的 WebElement 对象
element = driver.find_element_by_css_selector("span.red-packet-icon-mini > span.num")
# 使用强制等待
time.sleep(5) # 强制等待 5 秒
# 获取 <span> 元素的文本内容
text_content = element.text
# 打印文本内容
print(text_content)
值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别
第08节 切换操作
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 switch_to.windows() 方法。
1. 窗口切换
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 switch_to.windows() 方法。
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
# 设置隐式等待
driver.implicitly_wait(3)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击 python,进入分类页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 切换窗口
driver.switch_to.window(driver.window_handles[-1])
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
print(driver.window_handles)

上面代码在点击跳转后,使用 switch_to 切换窗口,window_handles返回的 handle 列表是按照页面出现时间进行排序的,最新打开的页面肯定是最后一个,这样用 driver.window_handles[-1] + switch_to 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 key(别名) 与 value(handle),保存到字典中,后续根据 key 来取 handle 。
2. 表单切换
1. iframe 切换
很多页面也会用带 frame/iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用 switch_to.frame() 方法将当前操作的对象切换成 frame/iframe 内嵌的页面。
switch_to.frame() 默认可以用的 id 或 name 属性直接定位,但如果 iframe 没有 id 或 name ,这时就需要使用 xpath 进行定位。
iframe = driver.find_element(By.ID, "my-iframe-id")
driver.switch_to.frame(iframe)
2.切换回默认内容:
如果在 iframe 中完成操作后,要切换回主页面,可以使用 switch_to.default_content() 方法:
driver.switch_to.default_content()
这些方法可以帮助你在 Selenium 中进行窗口和 iframe 的切换操作。记住,切换窗口或 iframe 之前,你需要获取到对应的窗口句柄或 iframe 元素。
3. 举例
确切地,要找到位于 iframe 中的元素,你需要按照以下步骤进行操作:
1.首先,你需要找到 iframe 元素本身,然后切换到该 iframe
2.在 iframe 内部,你可以使用常规的方法来查找和操作元素
以下是一个示例,演示如何切换到 iframe 并找到其中的元素:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com")
# 找到 iframe 元素,可以根据其 ID、名称或其他属性来定位
iframe = driver.find_element(By.ID, "my-iframe-id")
# 切换到 iframe
driver.switch_to.frame(iframe)
# 在 iframe 中查找元素并执行操作
element_inside_iframe = driver.find_element(By.CLASS_NAME, "element-class")
element_inside_iframe.click()
# 切换回主页面
driver.switch_to.default_content()
在这个示例中,我们首先通过其 ID 找到了 iframe 元素,然后使用 driver.switch_to.frame() 切换到了 iframe 中,接下来在 iframe 内查找元素并执行操作。最后,使用 driver.switch_to.default_content() 切换回主页面。
记住,要确保你正确找到了 iframe 元素,以及在切换到 iframe 后,使用 driver.find_element() 方法来查找位于 iframe 内部的元素。
第09节 滚轮操作
要在 Selenium 中模拟滚轮操作,你可以使用 ActionChains 类的 send_keys 方法,将 Keys.PAGE_DOWN 或 Keys.SPACE 等按键发送到页面。这将模拟向下滚动页面。
在你的示例代码中,你已经创建了一个 ActionChains 对象,所以你只需要在循环中使用 send_keys 方法来模拟滚轮操作。以下是如何修改你的代码以模拟滚轮向下滚动:
from selenium.webdriver.common.keys import Keys
# ...
# 计算滚动的时间间隔(以毫秒为单位)
scroll_interval = 500 # 每500毫秒滚动一次
# 创建ActionChains对象
action_chains = ActionChains(driver)
# 模拟滚动
for _ in range(int(scroll_duration * 1000 / scroll_interval)):
action_chains.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(scroll_interval / 1000)
这段代码会模拟按下 Page Down 键来滚动页面。你可以根据需要调整 scroll_interval 和 scroll_duration 来控制滚动的速度和持续时间。
总结
欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)