文章目录
- 一、模型训练
- 1.1 准备测试数据
- 1.2 加载模型
- 1.3 默认配置训练的显存占用
- 1.4 Model’s Operations
- 1.5 Model’s Memory
- 二、梯度累积(Gradient Accumulation)
- 2.1 批量大小
- 2.2 梯度累积
- 三、梯度检查点(Gradient Checkpointing)
- 3.1 工作原理
- 3.2 实验
- 3.3 总结
- 四、混合精度训练(Mixed precision training)
- 4.1 浮点数类型
- 4.2 fp16
- 4.2.1 fp16训练时的优缺点
- 4.2.2 Weight Backup
- 4.2.3 Loss Scale
- 4.2.4 Precision Accumulated
- 4.2.5 混合精度训练策略(Automatic Mixed Precision,AMP)
- 4.2.6 实验结果
- 4.3 BF16
- 4.4 TF32
- 五、Flash Attention 2
- 六、优化器选择
- 6.1 Adafactor
- 6.2 8-bit Adam
- 6.3 multi_tensor
- 七、数据预加载(Data preloading)
- 八、DeepSpeed ZeRO
- 九、torch.compile
- 十、🤗Accelerate
- 十一、高效的软件预构建(Efficient Software Prebuilds)
- 十二、Mixture of Experts
- 十三、使用PyTorch原生注意力和Flash Attention
- 《 Methods and tools for efficient training on a single GPU》
- 《探索多种方案下 LLM 的预训练性能》
在训练大型模型时,应同时考虑以下两个方面:
- Data throughput/training time
- Model performance
最大化吞吐量(samples/second)可以降低训练成本,这通过尽可能地利用GPU来实现。如果所需的批次大小超出了GPU内存的限制,则可以使用内存优化技术(例如梯度累积)来帮助解决内存问题。而如果单GPU可以正常训练,那么就不需要使用内存优化技术,因为它们很可能会减慢训练速度。
本指南中涉及的方法和工具可以根据它们对训练过程的影响进行分类:
| 方法/工具 | 提高训练速度 | 优化内存利用率 |
|---|---|---|
| 批量大小 | 是 | 是 |
| 梯度累积 | 否 | 是 |
| 梯度检查点 | 否 | 是 |
| 混合精度训练 | 是 | (否) |
| 选择优化器 | 是 | 是 |
| 数据预加载 | 是 | 否 |
| DeepSpeed Zero | 否 | 是 |
| torch.compile | 是 | 否 |
注意:当使用小型模型和大批次大小进行混合精度时,将节省一些内存,但在使用大型模型和小批次大小时,内存使用量将更大。
你可以组合上述方法以获得累积效果。无论你是使用Trainer训练模型还是使用🤗Accelerate编写纯PyTorch循环,都可以实现这些技术。如果这些方法无法获得足够的收益,你可以尝试以下选项:
- 第十一章:使用高效软件预构建自定义Docker容器
- 第十二章:使用混合专家(MoE)模型
- 第十三章:将模型转换为BetterTransformer以利用PyTorch原生注意力
如果在A100这样的GPU上使用所有方法仍然不足以进行训练,请参考Efficient Training on Multiple GPUs中的多GPU并行技术,我在博客《分布式训练原理总结(DP、PP、TP 、ZeRO)》中对此做了翻译整理。
一、模型训练
参考《Model training anatomy》
要理解提高模型训练速度和内存利用效率的性能优化技巧,首先需要了解训练过程中GPU是如何被利用的,以及所执行的操作对计算强度的影响(不同操作的计算强度可以帮助优化计算资源的分配,以提高模型训练的效率)。
首先安装必要的库:
pip install transformers datasets accelerate nvidia-ml-py3
其中,nvidia-ml-py3库用于监测和管理GPU设备(GPU信息查询、性能监测、释放GPU内存等),以便在深度学习模型训练等任务中更好地控制和优化GPU资源的使用。
1.1 准备测试数据
首先创建一些虚拟数据,即512个随机input_ids和二分类的labels代表的数据样本,然后存入Dataset中。
import numpy as np
from datasets import Dataset
seq_len, dataset_size = 512, 512
dummy_data = {
"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
"labels": np.random.randint(0, 1, (dataset_size)),
}
ds = Dataset.from_dict(dummy_data)
ds.set_format("pt")
定义了两个辅助函数打印 GPU 利用率以及Trainer训练时的统计信息:
from pynvml import *
def print_gpu_utilization():
nvmlInit()
handle = nvmlDeviceGetHandleByIndex(0)
info = nvmlDeviceGetMemoryInfo(handle)
print(f"GPU memory occupied: {info.used//1024**2} MB.")
def print_summary(result):
print(f"Time: {result.metrics['train_runtime']:.2f}")
print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
print_gpu_utilization()
# 查看空闲 GPU 内存
print_gpu_utilization()
GPU memory occupied: 0 MB.
Kernels 是用于执行底层 GPU 上数学运算的函数,我们调用kernel函数对存储在GPU内存中的数据进行计算。每种神经网络层都需要不同的 kernels 来执行其特定的计算操作,如卷积核函数、激活函数等,所以CUDA编程的核心其实也就是如何合理的划分数据并且针对数据结构编写高效的kernel函数。
当一个模型加载到 GPU 时,与该模型相关的计算 kernels 也会被加载到 GPU 上,这样可以避免每次执行运算时都重复加载 kernels,提高运算效率。但需要注意的是,加载 kernels 会占用 GPU 存储空间,通常占用大约1-2GB的内存。因此,即使加载一个微小的张量到 GPU 上,也会触发 kernels 的加载,并且你可以通过观察 GPU 显存的使用来查看 kernels 占用的内存大小。
import torch
torch.ones((1, 1)).to("cuda")
print_gpu_utilization()
有关
kernel和CUDA编程的更多内容,可参考《CUDA编程-《Professional CUDA C Programming》第2章-读书笔记(文字+图解)》、谭升博客《GPU编程(CUDA)》
1.2 加载模型
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
print_gpu_utilization()
GPU memory occupied: 2631 MB.
我们可以看到,仅模型权重就占用了 1.3 GB 的 GPU 内存,具体的数字取决于您使用的GPU。现在,运行CLI nvidia-smi 查看是否得到相同的结果:
nvidia-smi
Tue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+
可以看到打印出的内存占用是一样的,还可以看到我们使用的是具有 16GB 内存的 V100 GPU。现在我们可以开始训练模型,看看 GPU 内存消耗是如何变化的。
default_args = {
"output_dir": "tmp",
"evaluation_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}
1.3 默认配置训练的显存占用
下面使用默认参数配置的Trainer 训练模型,我们没有使用任何 GPU 性能优化技术:
from transformers import TrainingArguments, Trainer, logging
logging.set_verbosity_error()
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
print_summary(result)
Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.
可以看到,batch_size=4时就几乎填满了整个GPU内存,而较大的batch_size通常可以带来更快的模型收敛或更好的最终性能,为此,我们需要根据模型的需求调整batch_size大小。实际上,我们使用的V100 GPU内存比模型大小多得多,所以有必要剖析一下模型操作和内存需求。
1.4 Model’s Operations
根据《Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020》的结论,Transformer架构中的运算由三大组成部分(以计算强度排序):
-
Tensor Contractions
包括线性层和多头注意力机制的矩阵乘法运算,这是Transformer训练中最计算密集的部分。 -
Statistical Normalizations
包括Softmax和层归一化(layer normalization),并涉及一个或多个reduction operations。这部分相比Tensor Contractions计算量较小。 -
Element-wise Operators
包括偏置(biases)、dropout、激活函数(activations)和残差连接(residual connections)。这部分计算量最小。
分析性能瓶颈时,了解这些知识会很有帮助。
reduction operations指的是归约操作,即对一个张量中所有元素进行某种统计计算,从而将一个张量转换成一个标量。比如Softmax将一个向量归一化为概率分布,实现注意力机制的权重计算。它包含对向量进行求指数运算、求和运算等归约过程。layer normalization需要计算特征向量的均值和方差,这也是归约过程。
1.5 Model’s Memory
我们看到,与仅仅将模型加载到GPU相比,模型训练需要使用更多的内存。这是因为训练过程中有许多组件都使用了GPU内存:
- 模型权重
fp32:每个参数4字节- 混合精度训练:每个参数6字节(同时在内存中维护fp32版本和fp16版本)
- 优化器状态(optimizer states)
normal AdamW:每个参数8字节(维护一阶动量和二阶动量2个状态,都是fp32版本)8-bit AdamW(如bitsandbytes):每个参数2字节(也是两个状态,但都是int8版本)SGD:每个参数4字节(仅维护1个状态)
- 梯度: 每个参数4字节(无论是否启用混合精度训练,梯度始终以fp32存储)
- Forward Activations:用于梯度计算,其大小取决于许多因素,比如序列长度、隐含层大小和批量大小。
- 临时缓存:各种暂存变量,一旦计算完成就会释放,但当时可能需要额外内存,所以也可能导致OOM。编程时必须考虑这些临时变量,及时释放不再需要的变量。
- 特定功能的内存:除了以上的消耗,可能还有特殊的内存需求。例如,使用束搜索(beam search)生成文本时,需要维护输入和输出的多个副本。
所以一个典型的使用AdamW优化器进行混合精度模型训练的模型,每个参数需6字节,AdamW优化器需要8字节,梯度需要4字节,一共需要18字节,另外再加上Activations内存。推理时不需要优化器状态和梯度,所以只需要6 bytes加activations内存。
这是HF文档《Model training anatomy》的内容,与ZeRO论文并不一致。ZeRO论文中,使用AdamW优化器进行混合精度模型训练的模型,fp16格式的参数和梯度,每个2字节,fp32格式的优化器的状态信息,包括参数、动量和方差,都是4字节,一共16字节/参数。
最后,反向传播比前向椽笔的计算量更大,执行速度更慢,这是模型训练时的性能瓶颈之一。
- 对于卷积和线性层,前向传播只需要计算输出,反向传播需要计算权重梯度和输入梯度,所以反向传播计算量是前向传播的2倍,其执行速度也慢2倍左右。
- Activations通常受到带宽限制,而反向传播时Activations读取的数据量往往比前向传播更多。
Activations前向传播读取一次输入,写入一次输出;而反向传播需要读取两次数据(gradOutput和前向传播的输出),并写入一次gradInput。
现在你已经理解了影响GPU利用率和计算速度的因素,下面开始了解单GPU性能优化技术。
二、梯度累积(Gradient Accumulation)
参考:
NVIDIA文档《Linear/Fully-Connected Layers User’s Guide》
2.1 批量大小
训练数据的Batch size大小对训练过程的收敛性,以及训练模型的最终准确性具有关键影响。过大的Batch size可能陷入局部最小值,导致在训练集之外的泛化性不好。过小的Batch size会导致梯度变化过大,训练过程不稳定,模型收敛过慢。所以一般每个神经网络根据其数据集规模,都有一个最佳Batch size。
Tensor Core 是GPU用于加速矩阵计算的专门模块,它对矩阵维度有优化要求,使用正确的乘数可以发挥Tensor Core的最大计算能力。例如,对于fp16数据类型,除A100 GPU外,推荐使用8的倍数。在A100 GPU上,推荐使用64的倍数。
对于small parameters,要考虑Dimension Quantization Effects.,选择正确的乘数可以显着提升速度。
在GPU上进行大规模矩阵运算(如GEMM)时,通常会将大矩阵分割成小的tile,然后对每个tile进行并行计算。
tile size就是每个小tile的形状大小。比如对两个1024x1024的矩阵相乘,可以划分为许多32x32的tile,那么这里的tile size就是32。一般来说,tile size越小,越能发挥GPU的并行计算能力,但太小则会增加数据访问时间。tile size越大,每个tile内数据越容易重用,但tile数减少会降低并行度。Dimension Quantization Effects是指tile划分时使用合适的乘数可以获得显著的速度提升。更多信息可参考NVIDIA文档《Linear/Fully-Connected Layers User’s Guide》。
2.2 梯度累积
当模型太大时,训练中可能无法启用合适的Batch size,甚至只能启用Batch size=1。此时除了数据并行策略,还有一个常用的方法就是梯度累积。
梯度累积(Gradient Accumulation)是一种不需要额外硬件资源就可以增加Batch Size的训练技巧,是一个通过时间换空间的优化措施。正常反向传播时,计算出一个batch的梯度就马上更新参数;而梯度累积是将多个Batch训练数据的梯度进行累积,达到指定累积次数后,使用累积梯度统一更新一次模型参数,以达到一个较大Batch Size的模型训练效果。累积梯度等于多个Batch训练数据的梯度的平均值。
梯度下降所用的梯度,实际上是多个样本算出来的梯度的平均值,以
batch_size=128为例,你可以一次性算出128个样本的梯度然后平均,我也可以每次算16个样本的平均梯度,然后缓存累加起来,算够了8次之后,然后把总梯度除以8,然后才执行参数更新。当然,必须累积到了8次之后,用8次的平均梯度才去更新参数,不能每算16个就去更新一次,不然就是batch_size=16了。
梯度累积跟数据并行有高度的相似性:数据并行是空间上的, 数据被拆分成多个 tensor,同时喂给多个设备并行计算,然后将梯度累加在一起更新;而 梯度累积是时间上的数据并行, 数据被拆分成多个 tensor, 按照时序依次进入同一个设备串行计算,然后将梯度累加在一起更新。所以数据并行和梯度累积在数学上完全等价。以下是梯度累积的伪代码:
# batch accumulation parameter
accum_iter = 8
# loop through enumaretad batches
for batch_idx, (inputs, labels) in enumerate(data_loader):
# forward pass
preds = model(inputs)
loss = criterion(preds, labels)
# scale the loss to the mean of the accumulated batch size
loss = loss / accum_iter
# backward pass
loss.backward()
# weights update
if ((batch_idx + 1) % accum_iter == 0) or (batch_idx + 1 == len(data_loader)):
optimizer.step()
optimizer.zero_grad()
也可以通过向[TrainingArguments]添加gradient_accumulation_steps参数来启用梯度累积:
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
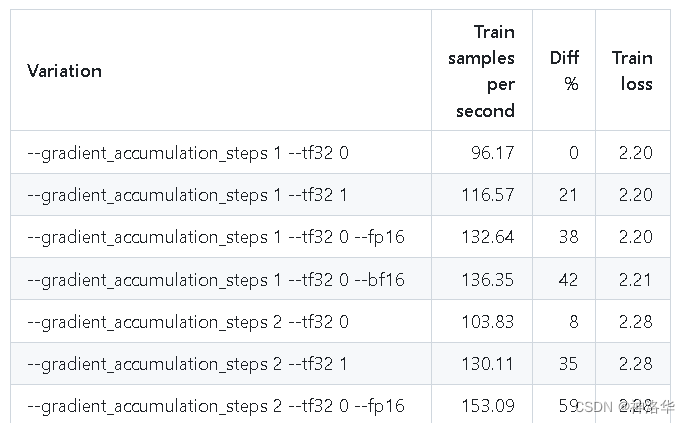
上述示例中,等效于batch_size=4。在本文第十章中,还有更具体的accelerate示例来说明。有关gradient_accumulation_steps大小对训练的影响,可参考[Benchmark] HF Trainer on RTX-3090和[Benchmark] HF Trainer on A100。
梯度累积解决了很多问题:
-
在单卡下,梯度累积可以将一个大的 batch size 拆分成等价的多个小 micro-batch ,从而达到节省显存的目的。
-
在数据并行下,梯度累积解决了反向梯度同步开销占比过大的问题(随着机器数和设备数的增加,梯度的 AllReduce 同步开销也加大),因为梯度同步变成了一个稀疏操作,因此可以提升数据并行的加速比。
-
在流水线并行下, 梯度累积使得不同 stage 之间可以并行执行不同的
micro-batch, 从而让各个阶段的计算不阻塞,达到流水的目的。如果每个micro-batch前向计算的中间结果(activation)被后向计算所消费,则需要在显存中缓存 8份(梯度累加的次数)完整的前向activation。这时就不得不用另一项重要的技术:activation checkpointing(也称Gradient Checkpointing)。
三、梯度检查点(Gradient Checkpointing)
《Fitting larger networks into memory》
3.1 工作原理
即使将批次大小设置为1并使用梯度累积,一些大型模型仍可能遇到内存问题。这是因为还有其他组件也需要内存存储。
在神经网络中,一般在线性变换(如矩阵乘法)之后,还会加入非线性激活函数,该激活函数的输出就是一个激活值(activation)。因此,我们也把神经网络中的每一层(包括输入层)在前向传播过程中产生的输出值称之为activation。
在反向传播阶段,需要计算每层的权重/参数梯度。根据链式法则,这需要该层的激活值和后层的梯度作为输入。所以标准反向传播需要将每层前向的激活值存储下来,以备反向传播计算参数梯度时使用,而这会导致显著的内存开销。
∂
Loss
∂
W
=
(
∂
Loss
∂
输出
)
⋅
(
∂
输出
∂
激活输入
)
⋅
(
∂
激活输入
∂
W
)
\frac{\partial \text{Loss}}{\partial W} = \left(\frac{\partial \text{Loss}}{\partial \text{输出}}\right) \cdot \left(\frac{\partial \text{输出}}{\partial \text{激活输入}}\right) \cdot \left(\frac{\partial \text{激活输入}}{\partial W}\right)
∂W∂Loss=(∂输出∂Loss)⋅(∂激活输入∂输出)⋅(∂W∂激活输入)
例如,对于具有 n 层的简单前馈神经网络,梯度计算图如下图所示:

Default:前向传播时保留每层的激活值
下图可视化了梯度计算图中反向传动的默认策略。可以看到,在峰值时,该算法存储所有激活,这意味着深度为 n 的网络需要 O ( n ) O(n) O(n) 内存(下图下图要 7 个内存单元来计算目标)。

memory-poor:放弃所有激活值,在反向传播时重新计算
另一种策略是完全抛弃这些激活值,在反向传播需要时重新计算以节省内存(下图要 4 个内存单元)。但这样会引入额外的计算开销,减慢训练过程,即内存消耗为 O ( 1 ) O(1) O(1),但计算消耗为 O ( n 2 ) O(n^2) O(n2)。

Gradient Checkpointing
折衷方案是保存一些中间结果,这些保存的节点被称之为Checkpoint。对于长度为 n 的链,如果要求任一节点最多只计算两次,那么每隔 n \sqrt n n 步放置一个检查点(下图第三个节点)是最省内存的策略。

此策略需要存储5个节点,额外要求一些前向计算过程。

| 策略 | 内存消耗 | 计算量 |
|---|---|---|
| Default | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) |
| memory-poor | O ( 1 ) O(1) O(1) | O ( n 2 ) O(n^2) O(n2) |
| Gradient Checkpointing | O ( n ) O(\sqrt n) O(n) | O ( n ) O(n) O(n) |
上面只讨论了简单的全连接层的情况,如果是更复杂的网络结构,例如包含残差连接的ResNet等,
Checkpoint的选择更为复杂,详见《Fitting larger networks into memory》。
3.2 实验
将梯度检查点方法应用于 TensorFlow 官方提供的 ResNet example ( CIFAR-10 数据集,batch size = 1280),并记录不同策略时的内存使用和执行时间,可以得出和上一节相同的结论——传统的反向传播(regular backprop)的内存使用和计算时间随着神经网络的深度线性增长,但使用梯度检查点时内存使用则与网络深度的平方根成正比,后者内存需求相对较低。
另外梯度检查点方法需要进行额外的前向传播计算。实验中,在GTX1080上训练时间增加了20%,V100 GPU上训练时间增加了30%。
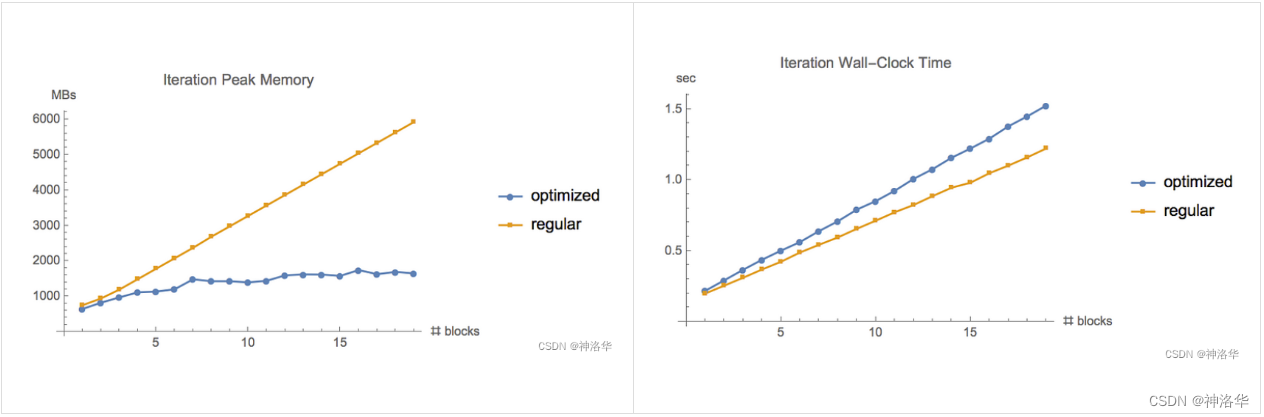
- 当尝试在更深的神经网络上应用梯度检查点方法时,这种差异更为明显(左图)
- 根据传统方法的内存需求进行推断,运行此迭代需要大约
60GB的内存,而使用梯度检查点方法仅需要6GB的内存。监控此期间内存的使用情况,将看到一个之子图——前半部分对应于第一个前向传递并保存初始检查点,后半部分峰值表示重新计算每个检查点中被遗忘的activation(右图)。
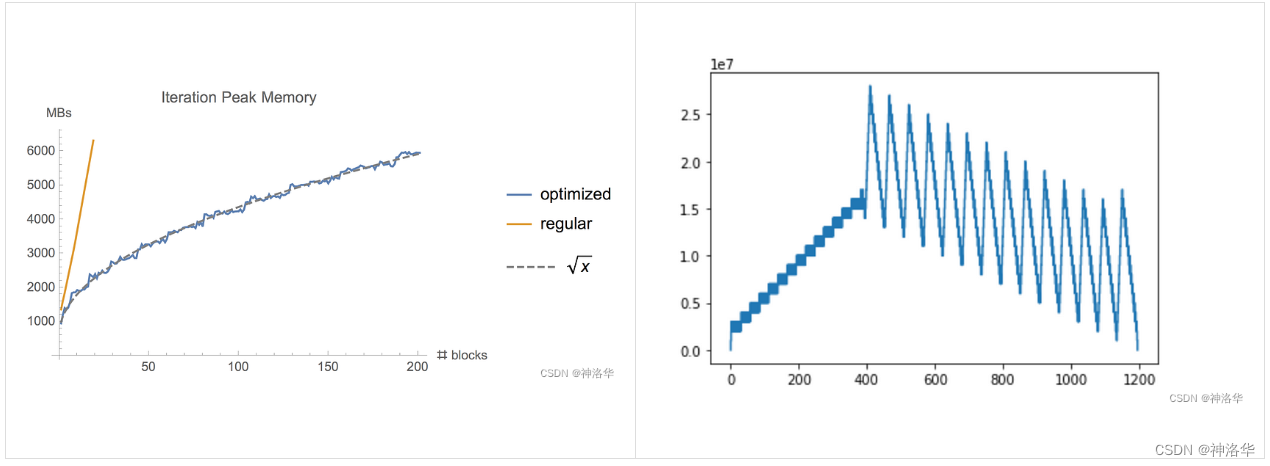
3.3 总结
Gradient Checkpointing 在这两种方法之间提供了一种妥协方案,其的核心思想是在前向网络中定期存储中间结果的快照(checkpoint), 然后在计算某一层的梯度时,从最近的一个快照开始重新运行前向计算,得到必要的中间结果。这样就使得大量的 activation 不需要一直保存到反向计算,有效减少了大量 Tensor 的生命周期,节省了大量的内存,但同时会增加一些计算量(训练速度会减慢约20%)。
要在[Trainer]中启用渐变检查点,请将相应的flag传递给[TrainingArguments]:
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
四、混合精度训练(Mixed precision training)
- 《全网最全-混合精度训练原理》、《浅谈混合精度训练》、 HF博客《大规模 Transformer 模型 8 比特矩阵乘简介》
- 论文《Mixed Precision Training》 、《Accelerating AI Training with NVIDIA TF32 Tensor Cores》、Nvidia混合精度训练文档、Scaling Neural Machine Translation
混合精度训练是一种旨在通过利用较低精度数值格式来优化训练模型计算效率的技术。传统上,大多数模型使用32位浮点精度(fp32或float32)来表示和处理变量。然而,并不是所有变量都需要这种高精度级别以获得准确的结果。通过将某些变量的精度降低到较低的数值格式,如16位浮点精度(fp16),我们可以加速计算。
为了保证模型的精度,使用 FP32 权重作为精确的 “主权重 (master weight)”,而使用 FP16/BF16 权重进行前向和后向传播计算以提高训练速度,最后在梯度更新阶段再使用 FP16/BF16 梯度更新 FP32 主权重。由于训练中使用了两种精度的数据,所以这种方法被称为混合精度训练。
在训练期间,主权重始终为 FP32。推理时,半精度权重通常能提供与 FP32 相似的精度,这样我们仅需一半 GPU 显存就能获得相同的结果(只有在模型梯度更新时才需要精确的 FP32 权重)。
大多数情况下,混合精度训练是通过使用fp16(16位浮点数)数据类型来实现的,但某些GPU架构(如Ampere架构)提供了bf16和tf32数据类型。
4.1 浮点数类型


在机器学习中,不同浮点数据类型也被称为“精度”,模型的大小由其参数量及其精度决定。根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,每种精度都是由三个不同的位来表示:
sign bit:最高位,表示符号位。exponent bit:中间位,表示指数位。fraction bit:最低位,表示分数位(也有称尾数位)。
后来为了便于训练,又引入了BF16和TF32。参考IEEE 754,五种精度概览如下:
| 数据类型 | 字节数 | Sign Bit | Exponent Bit | Fraction Bit | 数值范围 | 最小精度 | 说明 |
|---|---|---|---|---|---|---|---|
| fp64 | 8 | 1 | 11 | 52 | ± 1.8 ⋅ 1 0 308 ±1.8·10^{308} ±1.8⋅10308 | 2.23 ⋅ 1 0 − 308 2.23·10^{−308} 2.23⋅10−308 | 深度学习中计算精度最高的数据类型 |
| fp32 | 4 | 1 | 8 | 23 | ± 3.39 ⋅ 1 0 38 ±3.39·10^{38} ±3.39⋅1038 | 1.8 ⋅ 1 0 − 38 1.8·10^{-38} 1.8⋅10−38 | 标准数据类型,大部分硬件都支持 |
| fp16 | 2 | 1 | 5 | 10 | ± 65504 ±65504 ±65504 | 6.10 ⋅ 1 0 − 5 6.10·10^{−5} 6.10⋅10−5 | |
| BF16 | 2 | 1 | 8 | 7 | ± 3.39 ⋅ 1 0 38 ±3.39·10^{38} ±3.39⋅1038 | 0.0078 0.0078 0.0078 | Facebook提出的二进制浮点数格式,对指数部分使用fp32精度,小数部分使用7位 |
| TF32 | 4 | 1 | 8 | 10 | ± 3.39 ⋅ 1 0 38 ±3.39·10^{38} ±3.39⋅1038 | 6.10 ⋅ 1 0 − 5 6.10·10^{−5} 6.10⋅10−5 | Tensor Core的运算格式,结合了 BF16 的范围和 FP16 的精度 |
FP16格式指数位为5,所以指数范围为[-14,15],尾数为10,所以其最小正规化数的值为 2 − 14 ∗ ( 1 + 2 − 10 ) 2^{-14} * (1 + 2^{-10}) 2−14∗(1+2−10),约等于 6.1035 × 1 0 − 5 6.1035 \times 10^{-5} 6.1035×10−5。
Float32 (FP32) 是标准的 IEEE 32 位浮点表示,大部分硬件都支持 FP32 运算指令,它可以表示大范围的浮点数。
在 Float16 (FP16) 数据类型中,指数保留 5 位,尾数保留 10 位。这使得 FP16 数字的数值范围远低于 FP32。因此 FP16 存在上溢 (当用于表示非常大的数时) 和下溢 (当用于表示非常小的数时) 的风险。
例如,当你执行 10k * 10k 时,最终结果应为 100M,FP16 无法表示该数,因为 FP16 能表示的最大数是 64k。因此你最终会得到 NaN (Not a Number,不是数字)。在神经网络的计算中,因为计算是按层和 batch 顺序进行的,因此一旦出现 NaN,之前的所有计算就全毁了。一般情况下,我们可以通过缩放损失 (loss scaling) 来缓解这个问题,但该方法并非总能奏效。
于是我们发明了一种新格式 Bfloat16 (BF16) 来规避这些限制。BF16 保留与 FP32 相同的动态范围,但相对于 FP16,损失了 3 位精度。因此,在使用 BF16 精度时,大数值绝对没有问题,但是精度会比 FP16 差。
在 Ampere 架构中,NVIDIA 还引入了 TensorFloat-32(TF32) 精度格式,它使用 19 位表示,结合了 BF16 的范围和 FP16 的精度。目前,它仅在某些操作的内部使用。另外,TF32 是一个计算数据类型而不是存储数据类型。
4.2 fp16
4.2.1 fp16训练时的优缺点
使用FP16训练神经网络,相对比使用FP32带来的优点有:
- 减少内存占用:FP16的位宽是FP32的一半,因此权重等参数所占用的内存也是原来的一半,节省下来的内存可以放更大的网络模型或者使用更多的数据进行训练。
- 加快通讯效率:针对分布式训练,特别是在大模型训练的过程中,通讯的开销制约了网络模型训练的整体性能,通讯的位宽少了意味着可以提升通讯性能,减少等待时间,加快数据的流通。
- 计算效率更高:使用FP16进行运算速度更快。
但是使用FP16同样会带来一些问题,主要有以下两点
- 数据溢出: FP16的有效数据表示范围比FP32的要窄很多,使用FP16替换FP32会出现
Overflow(上溢,表示非常大的数时)和Underflow(下溢,表示非常小的数时)的情况。在深度学习中,需要计算网络模型中权重的梯度(一阶导数),因此梯度会比权重值更加小,往往容易出现下溢的情况。 - 舍入误差(
Rounding Error): 当网络模型的反向梯度很小时,一般FP32能够表示,但是转换到FP16会小于其最小间隔( 6.10 ⋅ 1 0 − 5 6.10·10^{−5} 6.10⋅10−5),导致数据溢出。如0.00006666666在FP32中能正常表示,但是这不满足FP16最小间隔,所以转换到FP16后会表示成为0.000067,多余的数会强制舍入。
为了避免精度溢出和舍入误差,可以通过FP16和FP32的混合精度训练(Mixed-Precision)来实现。混合精度训练过程中可以引入权重备份(Weight Backup)、损失放大(Loss Scaling)、精度累加(Precision Accumulated)三种相关的技术。
4.2.2 Weight Backup
权重备份主要用于解决舍入误差的问题,其主要思路可以概括为:weights, activations, gradients 等数据在训练中都利用FP16来存储,同时复制一份FP32格式的weights,用于weights更新。论文《Mixed precision training》中,作者以下图来阐述:

权重更新公式为:
w
e
i
g
h
t
=
w
e
i
g
h
t
+
η
∗
g
r
a
d
i
e
n
t
weight = weight +\eta * gradient
weight=weight+η∗gradient
深度学习中,
l
r
∗
g
r
a
d
i
e
n
t
lr * gradient
lr∗gradient的值可能会非常小,利用FP16来进行相加的话,则很可能会出现舍入误差问题,导致更新无效。因此通过将权重weights拷贝成FP32格式,并且确保整个更新过程是在FP32 格式下进行的。即:
w
e
i
g
h
t
32
=
w
e
i
g
h
t
32
+
η
∗
g
r
a
d
i
e
n
t
16
weight_{32} = weight_{32} + \eta * gradient_{16}
weight32=weight32+η∗gradient16
权重用FP32格式备份一次,那岂不是使得内存占用反而更高了呢?是的,额外拷贝一份weight的确增加了训练时候内存的占用。 但实际上,训练过程中,内存中占据大部分的基本都是激活值activations,特别是在batchsize 很大的情况下。因此,只要 activation 使用 FP16 存储,则最终模型与 FP32 相比起来, 内存占用也基本能够减半。反过来说,较小的batch_size可能会导致占用的GPU内存增加。
要启用混合精度训练,请将fp16标志设置为True:
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
4.2.3 Loss Scale
使用FP16表示会造成了数据下溢出(Underflow)的问题,此时梯度都会置为0,导致模型不收敛,于是需要引入损失缩放(Loss Scaling)技术。
为了解决梯度过小的问题,论文中对前向计算出来的loss值进行scale(放大),由于链式法则的存在,loss上的scale会作用在反向传播的每一层的梯度上,这样比在每一层梯度上进行放大更加高效。 scaled 过后的梯度,就会平移到 fp16 有效的展示范围内。具体来说:
- Scale up阶:网络模型前向计算后在反响传播前,将得到的损失变化值DLoss增大 2 K 2^K 2K倍。
- Scale down阶段:反向传播后,将权重梯度缩减 2 K 2^K 2K倍,恢复FP32值进行存储。
此外还有动态损失缩放(Dynamic Loss Scaling)技术,每当梯度溢出时候减少损失缩放规模,并且间歇性地尝试增加损失规模,从而实现在不引起溢出的情况下使用最高损失缩放因子,更好地恢复精度。
4.2.4 Precision Accumulated
精度累加是指在混合精度的模型训练过程中,使用FP16进行矩阵乘法运算,利用FP32来进行矩阵乘法中间的累加(accumulated)以弥补丢失的精度,然后再将FP32的值转化为FP16进行存储。 这么做的原因主要是为了减少加法过程中的舍入误差,尽量减缓精度损失的问题。
Nvidia Volta 结构中带有Tensor Core,可用于实现FP16的矩阵相乘,以及使用fp16 or fp32 来进行累加。正因为在累加阶段能够使用FP32大幅减少混合精度训练的精度损失,所以支持Nvidia Volta 结构的GPU(例如V100),才能利用 fp16 混合精度来进行加速。

4.2.5 混合精度训练策略(Automatic Mixed Precision,AMP)
从迭代的开始、迭代中期和迭代后期,都可以使用不同的混合精度策略来提升训练性能的同时保证计算的精度。以动态的混合精度达到计算和内存的最高效率比也是一个较为前沿的研究方向。
以NVIDIA的APEX混合精度库为例,用户可以通过选择一个"optimization level"或opt_level来选择不同的混合精度训练策略,还可以通过直接将特定属性的值传递给amp.initialize来更精细地控制opt_level的行为:
# Declare model and optimizer as usual, with default (FP32) precision
model = torch.nn.Linear(D_in, D_out).cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
# Allow Amp to perform casts as required by the opt_level
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
...
# loss.backward() becomes:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
...
opt_level有四种属性,具体如下图所示。
O0: FP32 trainingO1:混合精度(推荐用于典型用途),只优化前向计算部分。
根据实际Tensor和Ops之间的关系建立黑白名单来使用FP16。例如GEMM和CNN卷积操作对于FP16操作特别友好的计算,会把输入的数据和权重转换成FP16进行运算,而softmax、batchnorm等标量和向量在FP32操作好的计算,则是继续使用FP32进行运算,另外还提供了动态损失缩放(dynamic loss scaling)。O2: “Almost FP16” 混合精度 ,除梯度更新部分以外都使用混合精度。使用了权重备份来减少舍入误差,使用损失缩放来避免数据溢出(提供动态损失缩放)。O3: FP16 training

4.2.6 实验结果
fp16混合精度训练基本没有精度损失:
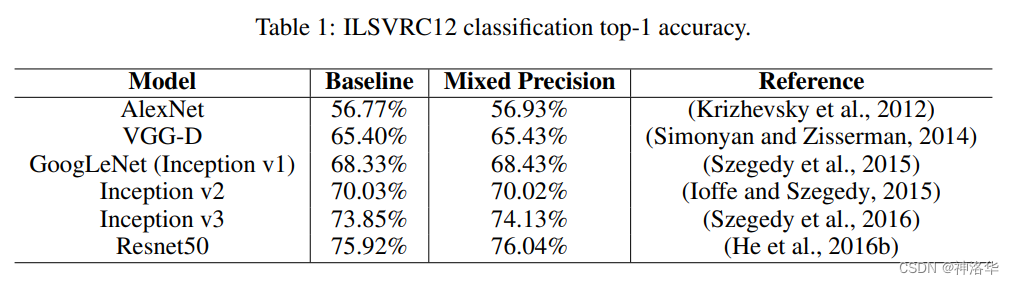
Ampere架构的GPU上(例如A100)默认的TF32格式可以达到与FP32格式相同的训练精度,而不需要改变训练脚本的超参数。相比Volta架构的GPU(例如V100)上的单精度运算,它可以在矩阵乘法和卷积运算上带来10倍的加速。

实际中,对整个网络的加速效果因任务而异,因为内存访问仍然是FP32,且TF32模式不影响非矩阵乘法和卷积的层。下图展示了从V100切换到A100,各种任务的单精度训练实际获得的2-6倍加速效果。此外,切换到FP16混合精度可以进一步获得高达2倍的加速(计算更快,内存访问减半),混合精度训练可以最大限度地提升A100上的训练速度。
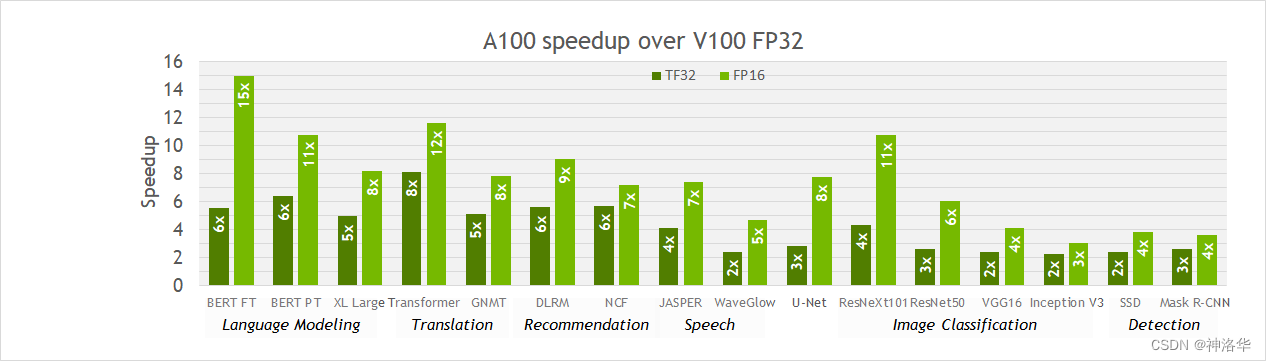
《浅谈混合精度训练》中,作者给出了实际的混合精度训练测试效果。
4.3 BF16
如果你可以使用Ampere或更新的硬件,可以使用bf16进行混合精度训练和评估。尽管bf16的精度比fp16更差,但动态范围更大( 65504 → 3.39 ⋅ 1 0 38 65504\rightarrow 3.39\cdot 10^{38} 65504→3.39⋅1038)。
你可以使用以下命令在🤗Trainer中启用BF16:
training_args = TrainingArguments(bf16=True, **default_args)
4.4 TF32
在Ampere架构的GPU上启用tf32支持,可以提升3倍的吞吐量,仅需要在代码中添加以下内容:
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
你也可以在🤗Trainer中启用此模式:
training_args = TrainingArguments(tf32=True, **default_args)
综合来看,tf32精度接近fp32,计算速度慢于fp16。有关tf32与其他精度的更多信息,请参见以下基准测试:RTX-3090和A100。
无法直接通过
tensor.to(dtype=torch.tf32)访问tf32,因为它是内部CUDA数据类型。你需要torch >= 1.7才能使用tf32数据类型。
五、Flash Attention 2
您可以通过在transformers中使用 Flash Attention 2 集成来加快训练吞吐量,详见《Efficient Inference on a Single GPU》。
六、优化器选择
在训练Transformer模型时,常见的优化器包括Adam和AdamW(带有权重衰减的Adam)。Adam存储了梯度的均值和方差来自适应地调整每个参数的学习率,以提高训练的稳定性和速度。然而,它会增加内存占用,大致等于模型参数的数量。
为了解决这个问题,你可以使用替代的优化器。例如,如果你安装了NVIDIA/apex,adamw_apex_fused将为你提供所有支持的AdamW优化器中的最快训练体验。
此外,Trainer集成了各种优化器——adamw_hf、adamw_torch、adamw_torch_fused、adamw_apex_fused、adamw_anyprecision、adafactor或adamw_bnb_8bit。你可以根据需求选择其中一个来进行模型训练。此外,还可以通过第三方实现来添加更多的优化器。
对于一个3B参数模型,如“t5-3b”:
AdamW:需要24GB的GPU内存,因为它对每个参数使用了8字节(维护梯度的均值和方差2个状态,每个状态使用FP32精度,都是4字节),3B参数 * 8字节/参数 = 24GB。Adafactor:需要超过12GB。它对每个参数使用略多于4字节(3B参数 * 4字节/参数 = 12GB),还有一些额外的空间。adamw_bnb_8bit:所有优化器状态都被量化为8位整数(1字节),所以每个参数使用了2字节,总共只会使用6GB的内存。
6.1 Adafactor
Adafactor不会为每个权重矩阵中的每个元素保留滚动平均值。相反,它保留了汇总信息(逐行和逐列的滚动平均值之和),显著减小了内存占用。然而,与Adam相比,在某些情况下,Adafactor可能收敛较慢。
你可以设置optim="adafactor"来启用Adafactor:
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
结合其他方法(梯度积累、梯度检查点和混合精度训练),可以在保持吞吐量的同时实现最多3倍的改进!然而,正如前面提到的,Adafactor的收敛性可能比Adam差。
6.2 8-bit Adam
与Adafactor不同,8位Adam保留完整状态并对其进行量化。量化意味着以较低的精度存储状态,并仅在优化时进行解量化,这类似于混合精度训练的思路。
你可以设置optim="adamw_bnb_8bit"来启用adamw_bnb_8bit:
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
我们也可以使用bitsandbytes库实现的8位Adam优化器,来演示如何将第三方库的优化器集成到trainer中。首先初始化优化器。这涉及两个步骤:
- 将模型的参数分组为两组——一组应用权重衰减,另一组不应用权重衰减。通常,偏差和层规范化参数不会应用权重衰减。
- 进行一些参数处理,使用与之前AdamW优化器相同的参数。
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
然后,将自定义优化器作为参数传递给Trainer:
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
结合其他方法(梯度积累、梯度检查点和混合精度训练),你可以获得约3倍的内存改进,甚至更高的吞吐量,就像使用Adafactor一样。
6.3 multi_tensor
pytorch-nightly引入了torch.optim._multi_tensor,可以显著加快大量小特征张量的优化器速度。它以后将成为默认选项,如果想提前尝试,可查看 issue。
七、数据预加载(Data preloading)
对于模型的高效训练来说,保证GPU能够以其最大处理速度接收数据是非常重要的。默认情况下,所有数据处理都在主进程中进行,但主进程可能无法快速地从磁盘读取数据,从而形成一个瓶颈,导致GPU利用率不高。为了减少这种瓶颈,可以配置以下TrainingArguments参数:
dataloader_pin_memory:默认为True,表示设置DataLoader的pin_memory属性为True。此参数可以确保数据被预加载到CPU的固定内存中,通常能够显著加速从CPU到GPU内存的传输速度dataloader_num_workers=4:DataLoader的num_workers属性默认为0,设为4可以启动多个工作进程来更快地预加载数据。在训练过程中监视GPU的利用率时,如果GPU利用率远低于100%,可以尝试增加工作进程的数量。当然,问题可能不仅仅在数据加载上,所以增加工作进程并不一定会导致更好的性能。
八、DeepSpeed ZeRO
《大模型分布式训练策略:ZeRO、FSDP》、《DeepSpeed官方教程(huggingface DeepSpeed文档翻译)》、🤗Accelerate DeepSpeed指南
ZeRO(Zero Redundancy Optimizer)是一种用于优化大规模深度学习模型训练的技术。它的主要目标是降低训练期间的内存占用、通信开销和计算负载,从而使用户能够训练更大的模型并更高效地利用硬件资源。
ZERO分为ZeRO-DP和ZeRO-R,分别用来优化model states(模型状态,包括优化器参数、梯度、模型参数)和residual states(残余状态内存),但是这些策略会减慢训练速度。后续还有其改进方法ZeRO-Offload和ZeRO-Infinity,分别实现将GPU的数据和计算卸载到CPU和NVMe内存,能在有限资源下能够训练前所未有规模的模型,而无需对模型代码进行重构。
DeepSpeed是一个开源的深度学习优化库,已与🤗 Transformers和🤗 Accelerate集成,其提供了以上所有ZERO方法的具体实现。如果你的模型在单个GPU上可以正常训练,则不需要使用DeepSpeed,因为这些优化内存的策略都会减慢训练速度。而如果模型无法在单个GPU上正常训练,或者可以训练但是无法使用合适的batch size,则可以利用DeepSpeed的ZeRO + CPU Offload或NVMe Offload来处理更大的模型。
有关ZeRO、ZeRO-Offload和ZeRO-Infinity的详细原理可以参考我的贴子《大模型分布式训练策略:ZeRO、FSDP》,有关DeepSpeed的使用可参考另一篇帖子《DeepSpeed官方教程(huggingface DeepSpeed文档翻译)》,其中有单GPU部署和notebook部署的部分。如果你更喜欢使用🤗Accelerate,请参考🤗Accelerate DeepSpeed指南。
九、torch.compile
torch.compile教程
PyTorch 2.0引入了一个新的编译函数,仅添加一行代码model = torch.compile(model)就可以优化模型。在TrainingArguments中传入torch_compile选项可启用此功能:
training_args = TrainingArguments(torch_compile=True, **default_args)
torch.compile使用Python的帧评估API来自动从现有的PyTorch程序中创建图形。在捕获图形之后,可以部署不同的后端将图形降到优化引擎。你可以在PyTorch文档中找到更多详细信息和基准测试。
torch.compile具有不断增长的后端列表,可以通过调用torchdynamo.list_backends()找到。每个后端都有其可选的依赖项。通过在TrainingArguments中指定要使用的后端的方式选择要使用的后端。最常用的几个后端是:
调试后端:
dynamo.optimize("eager")- 使用PyTorch运行提取的GraphModule,这对于调试TorchDynamo问题非常有用。dynamo.optimize("aot_eager")- 使用AotAutograd而没有编译器的AotAutograd’s提取的前向和后向图的PyTorch eager运行。这对于调试非常有用,不太可能带来速度提升。
训练和推断后端:
dynamo.optimize("inductor")- 使用具有AotAutograd和cudagraphs的TorchInductor后端,通过利用codegened Triton内核平衡地训练每个专家的门控函数来进行训练。了解更多dynamo.optimize("nvfuser")- 使用TorchScript的nvFuser。了解更多dynamo.optimize("aot_nvfuser")- 使用AotAutograd的nvFuser。了解更多dynamo.optimize("aot_cudagraphs")- 使用AotAutograd的cudagraphs。了解更多
仅推断后端:
dynamo.optimize("ofi")- 使用Torchscript的optimize_for_inference。了解更多dynamo.optimize("fx2trt")- 使用Nvidia TensorRT进行推断优化。了解更多dynamo.optimize("onnxrt")- 使用ONNXRT进行CPU/GPU上的推断。了解更多dynamo.optimize("ipex")- 使用IPEX进行CPU上的推断。了解更多
有关在🤗 Transformers中使用torch.compile的示例,请查看博客《Getting started with Pytorch 2.0 and Hugging Face Transformers》,其中介绍了如何使用最新的PyTorch 2.0功能对BERT模型进行文本分类的微调。
十、🤗Accelerate
Accelerate文档、Accelerator main class
通过在编写纯粹的PyTorch循环中加入进行一些细微的修改,🤗Accelerate就可以实现以上方法。例如在TrainingArguments中使用了以下参数:
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
使用🤗Accelerate可得到同样的实现:
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable() # 启用梯度检查点
# 初始化Accelerator时指定启用混合精度训练
accelerator = Accelerator(fp16=training_args.fp16)
# 启用adamw_bnb_8bit
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
# 调用accelerator进行反向传播
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
在🤗Accelerate中,通过少量的代码即可实现这些优化技术,并且具有更灵活的训练循环。要了解所有功能的完整文档,请查看Accelerate文档。
十一、高效的软件预构建(Efficient Software Prebuilds)
PyTorch的pip and conda builds 已经预先构建了cuda工具包(cuda toolkit),这足以运行PyTorch,但如果你需要构建cuda扩展,则还不够。
有时,可能需要额外的工作来预先构建一些组件。例如,如果您使用不带预编译版本的库(如apex)。在某些情况下,要弄清楚如何在整个系统上安装正确的cuda工具包可能会很复杂。为了解决这些情况,PyTorch和NVIDIA发布了一个新版本的NGC Docker容器,其中已经预先构建了一切。您只需要在其上安装您的程序,它就可以立即运行。
如果你想调整pytorch源代码或进行自定义构建,这种方法也很有用。要找到所需的Docker映像版本,请查看PyTorch发布说明,选择最新的月度版本。转到所选版本的发布说明,检查环境组件是否符合你的需求(包括NVIDIA驱动程序要求!),然后在该文档的顶部转到相应的NGC页面。如果出现迷失情况,这里是所有PyTorch NGC镜像索引。
接下来,请按照下载和部署Docker映像的说明进行操作。
十二、Mixture of Experts
《More Efficient In-Context Learning with GLaM》
Transformer也集成了最近报导的"专家混合"(Mixture of Experts,MoE)功能,从而实现了训练速度的4-5倍加速以及更快的推断速度。
这项技术的背后思想是,更多的参数通常会带来更好的性能,但增加参数数量也会增加训练成本。MoE技术允许在不增加训练成本的情况下,将参数数量增加一个数量级。
在这种方法中,每个前馈神经网络(FFN)层都被替换为一个MoE层,每个MoE层包含多个专家,并具有一个门控函数,根据输入标记在序列中的位置以平衡的方式训练每个专家。

这种方法的主要缺点是需要大量的GPU内存,几乎比其密集等效模型多一个数量级,为此提出了各种知识蒸馏和方法,你需要在这些方法中进行权衡。你可以选择只使用少数experts以及一个比原本模型小2-3倍的基本模型,而不是使用数十甚至数百个experts,这将使模型变小5倍,从而在适度增加内存需求的同时适度提高训练速度。
下面列出相关论文:
- “Switch Transformer: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity” by Ben-Zaken et al.
- “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding” by Fedus et al.
- “MixNMatch: Training a Convolutional Neural Network with a Switchable Mixture of Experts” by Aghajanyan et al.
- “Scalable Mixture Models for Deep Learning” by Chen et al.
大多数相关论文和实现都是基于Tensorflow/TPUs的:
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- GLaM: Generalist Language Model (GLaM)
对于PyTorch,DeepSpeed也集成了MoE,相关资源如下:
- 论文:DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
- DeepSpeed文档:Mixture of Experts
- microsoft博客:DeepSpeed powers 8x larger MoE model training with high performance,Scalable and Efficient MoE Training for Multitask Multilingual Models
十三、使用PyTorch原生注意力和Flash Attention
PyTorch 2.0发布了一个原生的torch.nn.functional.scaled_dot_product_attention (SDPA),它允许使用融合的GPU内核,例如 memory-efficient attention和flash attention。
在安装了optimum软件包之后,可以替换相关的内部模块以使用PyTorch的原生注意力,一旦转换完成,可以像往常一样训练模型。
model = model.to_bettertransformer()
更多关于SDPA的加速和节省内存的信息,详见PyTorch博客《Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0》
如果没有提供
attention_mask,PyTorch原生的scaled_dot_product_attention运算符只能调度到Flash Attention。
默认情况下,在训练模式下,BetterTransformer集成会drops the mask support and can only be used for training that does not require a padding mask for batched training。所以BetterTransformer不适用于需要padding mask的模型,例如掩码语言建模或因果语言建模(masked language modeling or causal language modeling)。