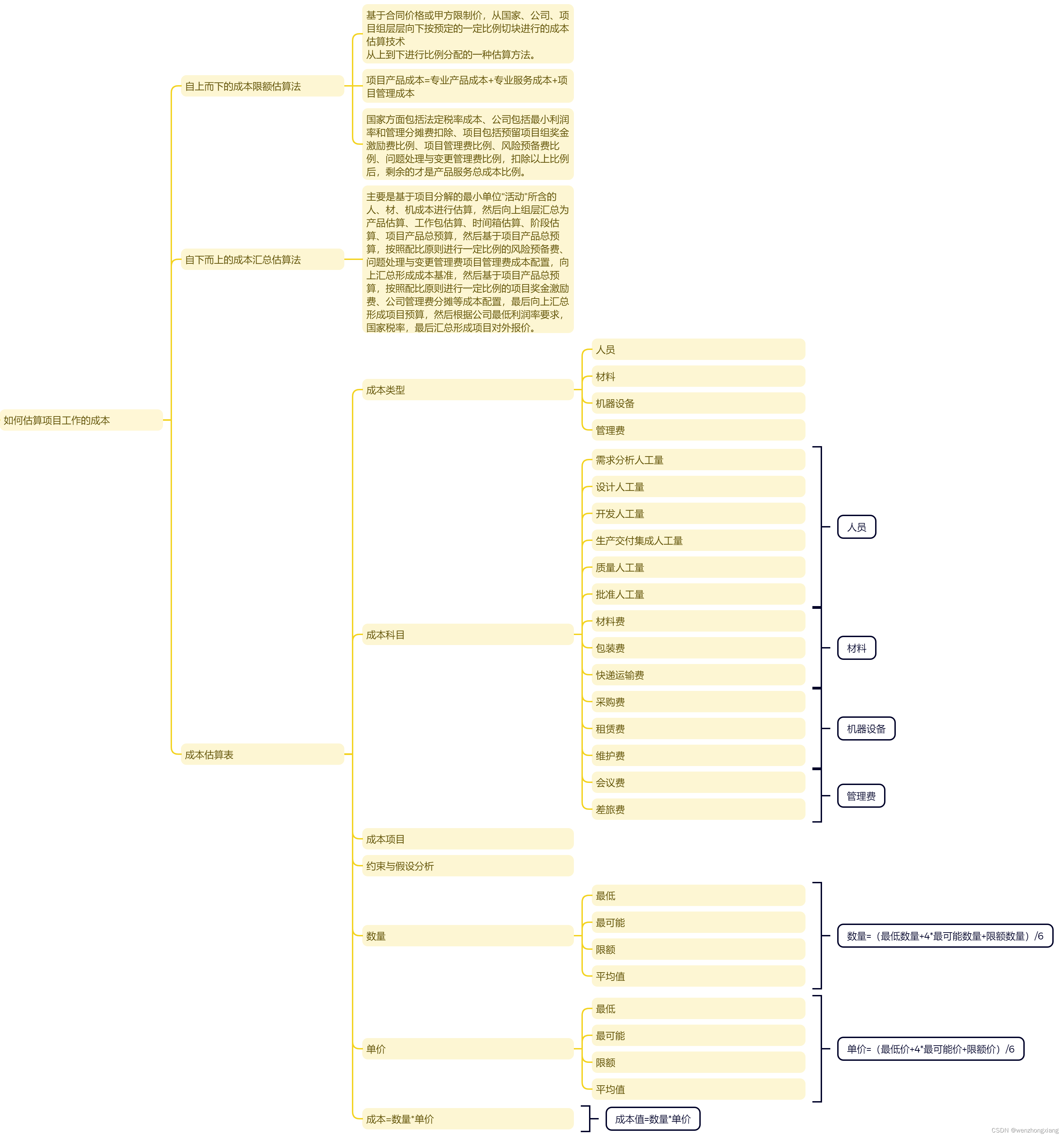
文章目录
- Tag
- 题目来源
- 题目解读
- 解题思路
- 方法一:哈希表
- 方法二:哈希表+滑动窗口+位运算
- 写在最后
Tag
【哈希表】【位运算+滑动窗口+哈希表】【字符串】【2023-11-05】
题目来源
187. 重复的DNA序列
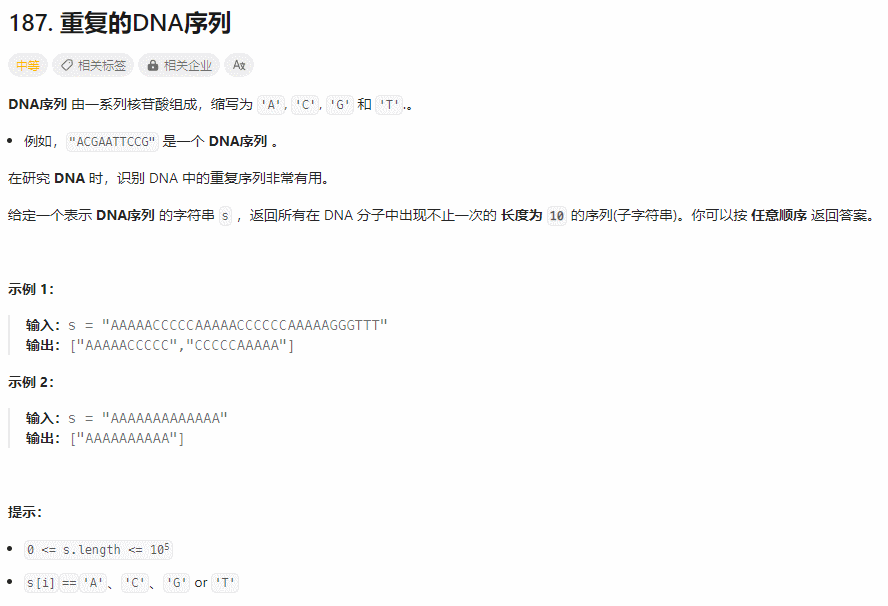
题目解读
找出字符串中重复出现的字符串。
解题思路
方法一:哈希表
一种朴素的方法是枚举所有长度为 10 的子字符串,并用哈希表计数,如果该子字符串的出现的次数超过一次,那么该子字符串就是答案要求的重复的 DNA 序列。
实现代码
class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
unordered_map<string, int> cnts;
int n = s.size();
vector<string> res;
for (int i = 0; i <= n - 10; ++i) {
string sub = s.substr(i, 10);
if (++cnts[sub] == 2) {
res.push_back(sub);
}
}
return res;
}
};
复杂度分析
时间复杂度:
O
(
N
⋅
L
)
O(N \cdot L)
O(N⋅L),
N
N
N 为字符串的 s 的长度,
L
L
L 为固定的字符串的大小。
空间复杂度: O ( N ) O(N) O(N)。
方法二:哈希表+滑动窗口+位运算
实际上我们可以使用一个固定大小的滑窗来记录长度为 10 的字符串。题目中已告知我们字符串中的字符种类只有四种,因此可以使用 2 个比特来表示每个字符,于是可以有:
- A 表示为二进制为
00; - C 表示为二进制为
01; - G 表示为二进制为
10; - T 表示为二进制为
11;
这样的话长度为 10 的字符串就可以使用 20 为比特来表示即一个 int 型整数,也就是说滑窗内的字符串可以使用一个 int 型整数表示,这样就降低了时间复杂度。具体地:
- 先向滑窗中塞进去
9个字符; - 滑窗每向右移动一位,滑窗内就会增加一个字符,滑窗最左侧的字符离开窗口:
- 滑窗每向右移动一位,滑窗内就会增加一个字符,表示滑窗内字符串的二进制整数值
x = x << 2,x = x | bin[ch],bin[ch]表示字符ch对应的二进制; - 滑窗左侧的字符离开窗口,
x = x & ((1 << 20) - 1),因此时x有22位比特,我们只需要低20位,所以与上(1 << 20) - 1;
- 滑窗每向右移动一位,滑窗内就会增加一个字符,表示滑窗内字符串的二进制整数值
- 剩下就是更新哈希表,一旦有第二次出现的
x,则表示的字符串就是重复的 DNA 序列。
实现代码
class Solution {
public:
unordered_map<char, int> bin = {{'A', 0}, {'C', 1}, {'G', 2}, {'T', 3}};
vector<string> findRepeatedDnaSequences(string s) {
vector<string> res;
int n = s.size();
if (n <= 10) {
return res;
}
int x = 0;
for (int i = 0; i < 9; ++i) {
x = (x << 2) | bin[s[i]];
}
unordered_map<int, int> cnts;
for (int i =0; i <= n - 10; ++i) {
x = ((x << 2) | bin[s[i + 10 - 1]]) & ((1 << 20) - 1);
if (++cnts[x] == 2) {
res.push_back(s.substr(i, 10));
}
}
return res;
}
};
复杂度分析
时间复杂度:
O
(
N
)
O(N)
O(N),
N
N
N 为字符串的 s 的长度,
L
L
L 为固定的字符串的大小。
空间复杂度: O ( N ) O(N) O(N)。
写在最后
如果文章内容有任何错误或者您对文章有任何疑问,欢迎私信博主或者在评论区指出 💬💬💬。
如果大家有更优的时间、空间复杂度方法,欢迎评论区交流。
最后,感谢您的阅读,如果感到有所收获的话可以给博主点一个 👍 哦。