1 Drop Delete Truncate三者之间的区别和联系
drop删除整张表,包括表结构和表数据。用法 drop table 表名
truncate表示清空数据,不会删除表结构。truncate table 表名
delete表示删除数据,不会删除表结构。delete from 表名 where 列名 = 值,
那么,truncate和delete的区别:
truncate属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。由DBA所使用。不产生日志信息
delete 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segment 中,事务提交之后才生效。开发人员日常使用较为频繁。产生数据的binlog日志。
一般来说执行效率:drop > truncate > delete。
2 SQL查询语句中的Limit关键词的用法。
select _column,_column from _table [where Clause] [limit N][offset M] select * : 返回所有记录
limit N : 返回 N 条记录
offset M : 跳过 M 条记录, 默认 M=0, 单独使用似乎不起作用
limit N,M : 相当于 limit M offset N , 从第 N 条记录开始, 返回 M 条记录
以下表示均为找表table_a的前5行数据。
1 select * from table_a limit 5; --> limit n; 表示前n行数据
2 select * from table_a limit 0, 5; --> limit m , n ;表示第m+1,到第m+ n行的n条数据
3 select * from table_a limit 5 offset 5; --> limit n offset m ; 表示的是偏移m行,从第m+1到第n行的n条数据。
常见的分页查询
select * from _table limit (page_number-1)*lines_perpage, lines_perpage
或
select * from _table limit lines_perpage offset (page_number-1)*lines_perpage3. where group by和Having的先后顺序
SELECT cust_name, COUNT() AS num
FROM Customers
WHERE cust_email IS NOT NULL
GROUP BY cust_name
HAVING COUNT() >= 1;having:
having 用于对汇总的 group by 结果进行过滤。 having 一般都是和 group by 连用。
having vs where:
where:过滤过滤指定的行,后面不能加聚合函数(分组函数)。where 在group by 前。 having:过滤分组,一般都是和 group by 连用,不能单独使用。having 在 group by 之后
执行顺序: where---->group by---->Having ,聚合函数只能用在Having, select
此外:order by 和 where的顺序,先where - order by
完整的顺序:Where, Group By, Having, Order by
4.SQL语句中Like通配符%和下划线_的用法
% :表示任意0个或多个字符,可匹配任意类型和长度的字符。
_ : 表示任意单个字符。
注意:如果要搜索 字符中有下划线的,需要对_进行转义
- select * from t where x like '%\_%' escape ''; 搜索中间含有下划线的查询条件,通过escape进行转义。
- Like对应的否定是NOT LIKE (类似于判断字符串是否为空,IS NULL / IS NOT NULL)
5.内连接 外连接 之间的关系
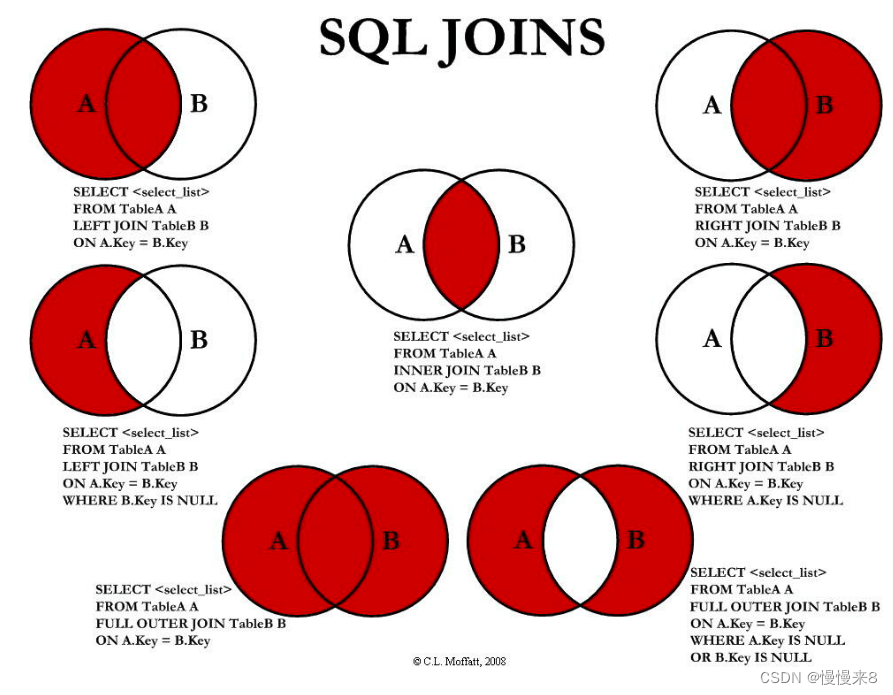
ON 和 WHERE 的区别:
连接表时,SQL 会根据连接条件生成一张新的临时表。ON 就是连接条件,它决定临时表的生成。
WHERE 是在临时表生成以后,再对临时表中的数据进行过滤,生成最终的结果集,这个时候已经没有 JOIN-ON 了。所以总结来说就是:SQL 先根据 ON 生成一张临时表,然后再根据 WHERE 对临时表进行筛选。
如果不加任何修饰词,只写 JOIN,那么默认为 INNER JOIN。
对于 INNER JOIN 来说,还有一种隐式的写法,称为 “隐式内连接”,也就是没有 INNER JOIN 关键字,使用 WHERE 语句实现内连接的功能。
隐式内连接
select c.cust_name, o.order_num
from Customers c, Orders o
where c.cust_id = o.cust_id
order by c.cust_name;显式内连接
select c.cust_name, o.order_num
from Customers c
inner join Orders o
using(cust_id)
order by c.cust_name;6.IN 和EXISTS查询的区别
1 IN后面的子查询返回的结果集是单个列表值的集合;而EXISTS所跟的是查询的结果集
2 IN是先进行内部查询,再根据结果进行外部查询;而EXISTS则从外部表开始遍历每一行,判断其是否满足条件
3 IN主要的查询效率是依赖于外表的索引,而EXISTS的查询效率是依赖于内表的索引。
4 因此,当子查询结果集较大,而外表较小时,EXISTS的性能较好;
当子查询结果集较小,而外部表较大的时候。IN的性能较好