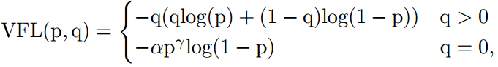1. 解决了什么问题?
出于安全和导航的目的,自驾感知系统需要全面而迅速地理解周围的环境。目前主流的研究方向有两个:第一种传感器融合方案整合激光雷达、相机和毫米波雷达,和第二种纯视觉方案。传感器融合方案的感知表现鲁棒,但是成本高,所要面临的环境挑战不少,因此大规模部署不太现实。纯视觉方案只依赖于相机传感器做感知,成本低廉,可以持续迭代。因此,纯视觉方案可能是自动驾驶行业的终极方向。

目前,纯视觉领域的研究焦点就是如何生成环境 BEV 图,赋能车载感知系统。传统的方法受限于相机的角度,生成的感知范围有限,制约了实时决策所需的空间感知能力。BEV 方法通过提供丰富的环境信息,提升自动驾驶,从而在复杂场景中做到实时决策。人们通常用高精地图来得到道路布局、车道线和其它静态元素。在这些静态信息之上是各种动态元素(车辆、行人和其它物体),为实时导航提供了必要的信息。本文试图在车辆各相机画面的坐标和 BEV 图之间构造直接的空间对应关系。BEV 图的各画面取决于它是哪个相机采集的,如上图所示,车辆前视相机采集的画面肯定落入 BEV 的上半部分,后视相机的画面肯定落入 BEV 的下半部分。

2. 提出了什么方法?
本文提出了 YOLO-BEV,通过环视相机的画面生成出一个 2D BEV 的车辆环境。通过设置八个相机,每个相机负责 4 5 ∘ 45^\circ 45∘,该系统将获取的图像整合成一个 3 × 3 3\times 3 3×3 的网格形式,中间是空白的,提供一个丰富的空间表征。本文采用了 YOLO 检测机制,YOLO 具有速度快和模型简洁的优点。作者对检测头做了特殊的设计,将全景数据转换为自车的统一的 BEV 图。
概览
YOLO-BEV 使用相机矩阵来采集数据,利用 YOLO 的主干网络做特征提取。针对 BEV 输出设计了一个检测层和相应的损失函数。本文关键创新点就是相机布局的设计,无缝地匹配生成的 BEV。该布局包括八个相机的安装,每个负责 4 5 ∘ 45^\circ 45∘角,从而得到 36 0 ∘ 360^\circ 360∘的视角。然后用一个 3 × 3 3\times 3 3×3矩阵的布局做图像预处理,根据 YOLO 特征图产生相应的 BEV。
下图展示了这个想法,相机在 BEV 视角下和各个区域对齐。输出的合成图像与车辆自上而下的视角保持对齐,目的是提高目标检测和空间识别的准确性。此外,作者将画面矩阵最底下的一列图像做了 18 0 ∘ 180^\circ 180∘ 的旋转,认为这样做更能匹配 BEV 的空间位置。

数据采集和预处理
nuPlan 数据集是自动驾驶领域非常重要的基准,包含了 1200 小时精心采集的高质量驾驶数据,场景涵盖了波士顿、匹兹堡、新加坡和拉斯维加斯的城区道路。它提供了多样化的驾驶场景和详尽的传感器数据,包括激光雷达、不同视角的相机、IMU 和高精度的 GPS 坐标。本文重点关注并优化自驾方案的计算效率,基于 nuPlan 数据集的八个相机的画面。
这些图像可以构建出一个 3 × 3 3\times 3 3×3画面矩阵,和 BEV 位置场景具有空间对应关系。为了生成可靠、准确的 ground-truth 数据,作者使用了一个直接的提取方法。nuPlan 数据集里的 tokens 是独一无二的,于是作者在输入图像和表示车辆位置的 BEV 坐标之间构建了一一对应的关系。本文的分析不包括行人和交通信号灯等信息,只考虑了车辆。这样,该方法可以加速计算过程,大幅度缩短获取有价值的结果的时间。
模型结构
本文模型基于 YOLO 架构构建,特征提取能力强、效率高。借鉴了主干和检测头的结构,模型将初始的 3 × 3 3\times 3 3×3 图像矩阵转换成一组丰富的多尺度特征图。这些特征图然后通过 CustomDetect 层做处理,实现准确的 BEV 目标定位。下图展示了该架构,它包括初始的 3 × 3 3\times 3 3×3 输入矩阵、主干网络和检测头,以及特殊设计的 CustomDetect 层。
CustomDetect 层包括 n l n_l nl层, n l n_l nl 与通道维度数组 c h = [ c h a n n e l 1 , c h a n n e l 2 , c h a n n e l 3 ] ch = [channel_1, channel_2, channel_3] ch=[channel1,channel2,channel3] 对齐。每一层 i i i都有一组卷积层。该序列卷积操作的数学表示如下:
Conv i , j = ReLU ( Conv2D ( X i , j − 1 , W i , j , b i , j ) ) , ∀ j ∈ { 1 , 2 , 3 } \text{Conv}_{i,j}=\text{ReLU}(\text{Conv2D}(X_{i,j-1}, W_{i,j}, b_{i,j})), \forall j\in \{1,2,3\} Convi,j=ReLU(Conv2D(Xi,j−1,Wi,j,bi,j)),∀j∈{1,2,3}
其中 X i , j − 1 X_{i,j-1} Xi,j−1表示第 i i i个检测层里第 j j j个卷积层的输入, W i , j , b i , j W_{i,j}, b_{i,j} Wi,j,bi,j表示相应的权重和偏置参数。使用了 ReLU 激活,为模型引入非线性。
前向计算时,将一组特征图输入 CustomDetect 层,每个特征图的维度都是 BatchSize × Channels × Height × W i d t h \text{BatchSize}\times \text{Channels}\times \text{Height}\times {Width} BatchSize×Channels×Height×Width。随后,将这些特征图变换为一组坐标和置信度得分张量。对于每个特征图 X i X_i Xi,
Y i = Conv i , 3 ( Conv i , 2 ( Conv i , 1 ( X i ) ) ) Y_i = \text{Conv}_{i,3}(\text{Conv}_{i,2}(\text{Conv}_{i,1}(X_i))) Yi=Convi,3(Convi,2(Convi,1(Xi)))
Y i Y_i Yi包含了 BEV 下目标定位的关键信息,目标位置和置信度得分。这些数据会用生成的网格进一步做优化,与输入特征图 X i X_i Xi的空间维度对应。该模型不仅利用了 YOLO 的特征提取机制,也扩展了边框回归方法,更准确地定位目标。CustomDetect 层输出关键的参数,如 物体的 x , y x,y x,y 坐标、朝向角、置信度。然后会用一个动态构建的网格来进一步优化这些参数,与输入特征图的空间维度对齐。

网格补偿机制
CustomDetect 模块加入了一个网格补偿机制,用于优化预测的目标位置。该机制将相对坐标变换成一组富含全局信息、上下文相关的坐标,即相对于特征图的整体空间范围。
网格创建
对于每个检测层,记作 i i i,会初始化一个精心构建的网格 G i G_i Gi。该网格与 i i i层输出的特征图 F i F_i Fi维度一致。 G i G_i Gi的每个格子都有一个中心坐标 ( x c e n t e r , y c e n t e r ) (x_{center},y_{center}) (xcenter,ycenter)。这个格子在网格 G i G_i Gi里的笛卡尔坐标是 ( m , n ) (m,n) (m,n),
x
c
e
n
t
e
r
=
m
+
0.5
width of
F
i
x_{center}=\frac{m+0.5}{\text{width of }F_i}
xcenter=width of Fim+0.5
y
c
e
n
t
e
r
=
n
+
0.5
height of
F
i
y_{center}=\frac{n+0.5}{\text{height of }F_i}
ycenter=height of Fin+0.5
精度驱动的坐标修正
( x p r e d , y p r e d ) (x_{pred}, y_{pred}) (xpred,ypred) 表示网络预测的特征图 F i F_i Fi上某一格子的坐标。该预测坐标需经过一个复杂的修正过程,利用到 G i G_i Gi对应的格子的中心坐标,
x
a
d
j
u
s
t
e
d
=
(
x
p
r
e
d
2
×
width of
F
i
)
+
x
c
e
n
t
e
r
x_{adjusted}=(\frac{x_{pred}}{2\times \text{width of }F_i}) + x_{center}
xadjusted=(2×width of Fixpred)+xcenter
y
a
d
j
u
s
t
e
d
=
(
y
p
r
e
d
2
×
height of
F
i
)
+
y
c
e
n
t
e
r
y_{adjusted}=(\frac{y_{pred}}{2\times \text{height of }F_i}) + y_{center}
yadjusted=(2×height of Fiypred)+ycenter
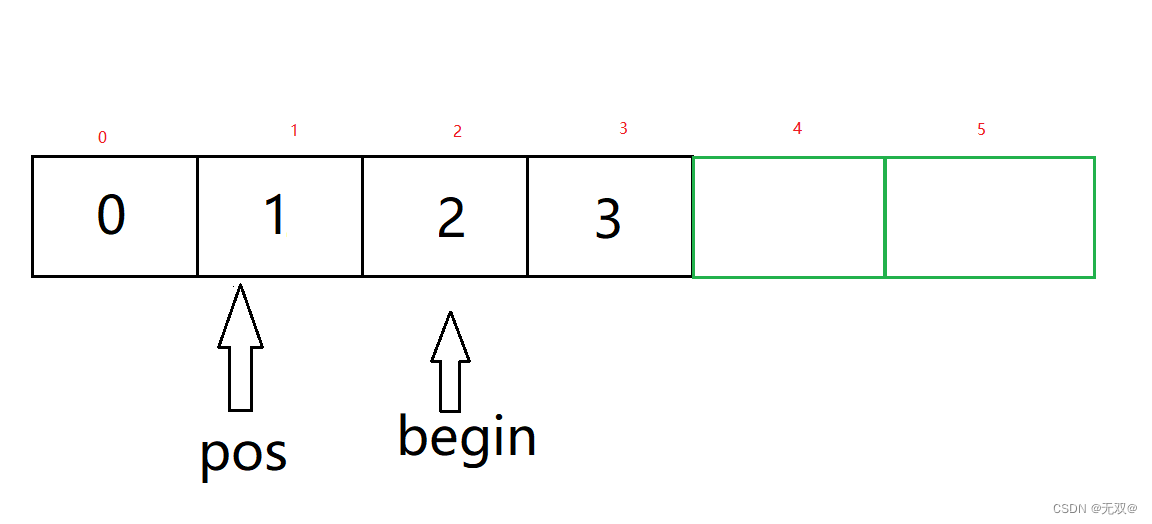
该修正机制不仅极大地提升了模型的定位能力,也提升了算法的效率和稳定性。如下图所示,假设有一个 3 × 3 3\times 3 3×3特征图 F i F_i Fi,格子的索引从左上角的 ( 0 , 0 ) (0,0) (0,0)到右下角的 ( 2 , 2 ) (2,2) (2,2)。用特征图 F i F_i Fi的宽度和高度来计算每个格子的中心坐标。例如, ( 0 , 0 ) (0,0) (0,0)格子的中心坐标是 ( 1 2 × width of F i , 1 2 × height of F i ) (\frac{1}{2\times \text{width of }F_i}, \frac{1}{2\times \text{height of }F_i}) (2×width of Fi1,2×height of Fi1)。我们假设网络预测该格子的坐标是 ( x p r e d , y p r e d ) (x_{pred}, y_{pred}) (xpred,ypred),其可以通过下面的方式做修正:
x
a
d
j
u
s
t
e
d
=
(
x
p
r
e
d
2
×
width of
F
i
)
+
1
2
×
width of
F
i
x_{adjusted}=(\frac{x_{pred}}{2\times \text{width of }F_i}) + \frac{1}{2\times \text{width of }F_i}
xadjusted=(2×width of Fixpred)+2×width of Fi1
y
a
d
j
u
s
t
e
d
=
(
y
p
r
e
d
2
×
height of
F
i
)
+
1
2
×
height of
F
i
y_{adjusted}=(\frac{y_{pred}}{2\times \text{height of }F_i}) + \frac{1}{2\times \text{height of }F_i}
yadjusted=(2×height of Fiypred)+2×height of Fi1

损失函数
采用了 multi-faceted 方法来设计损失函数,优化模型的性能,在该目标函数中融合了空间和置信度的信息。
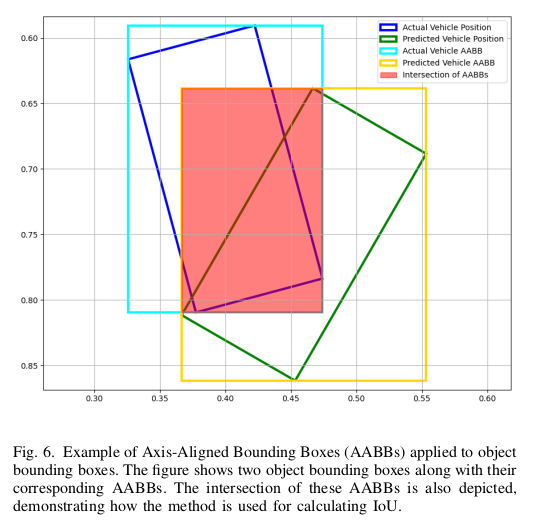
空间部分引入了边框损失,使用 MSE。给定预测边框坐标和朝向角,转化成轴对齐边框(AABB)来计算与 ground-truth 框的 IOU。下图展示了该轴对齐边框 AABB 以及 IOU。AABB 简化了 IOU 的计算,与更准确的带朝向角的边框方法相比,它的 IOU 值可能会大一些。这是因为与轴对齐的边框可能会覆盖一些非重叠的区域。实验表明该误差是可以接受的,它仍能有效地帮助损失的下降。边框损失定义为:
L b o x = MSE ( I O U p r e d , I O U g t ) L_{box}=\text{MSE}(IOU_{pred}, IOU_{gt}) Lbox=MSE(IOUpred,IOUgt)
选用 MSE 作为 IOU 损失,能保证梯度流比较平滑。
置信度部分是用一个二值交叉熵损失实现的。对正负类别的样本计算损失。预测框如果与 ground-truth 框的 IOU 超过一定阈值,则判定正样本。对于正样本,损失为:
L p o s = B C E ( C p r e d , 1 ) + L b b o x L_{pos}=BCE(C_{pred}, 1) + L_{bbox} Lpos=BCE(Cpred,1)+Lbbox
若预测框和任意一个 ground-truth 框的 IOU 都很低,则判定为负样本,损失如下:
L n e g = B C E ( C p r e d , 0 ) L_{neg}=BCE(C_{pred}, 0) Lneg=BCE(Cpred,0)
最终的损失是这些损失的加权和,
L t o t a l + α L b b o x + β ( L p o s + L n e g ) L_{total}+\alpha L_{bbox} + \beta(L_{pos}+L_{neg}) Ltotal+αLbbox+β(Lpos+Lneg)
α , β \alpha,\beta α,β 平衡空间和置信度部分的权重,微调模型时提供一定的灵活性。该损失受到 YOLO 启发,构建了一个灵活且鲁棒的损失函数,能够解决自动驾驶任务内在的挑战,如实时目标跟踪和高精定位。