可以考虑 安装完操作系统后,安装更新及其他基础软件如gcc cmake, 再安装英伟达几件套(这里列出了四个) 如果自带的python版本在3.8或以上,再安装python常用库。 python版本不能太低,看你要跑的代码的需求了。
| 顺序号 | 名称 | 全称 | 简要描述 | 包样例(后面的数字可能变化) | 安装后检查命令 |
| 1 | 显卡驱动 | 好比是一个接口,提供 使用GPU 的能力 | NVIDIA-Linux-x86_64-535.113.01.run | nvidia-smi | |
| 2 | cuda toolkit | Compute Unified Device Architecture | 这个工具集 提供了很多的工具和库,让你使用GPU时 不用从头开始造轮子。 | cuda_11.7.0_515.43.04_linux.run | nvcc -V |
| 3 | cudnn | CUDA Deep Neural Network library | 对深度学习中的卷积、池化、归一化等常用操作做了特别优化。 | cudnn-linux-x86_64-8.8.1.3_cuda11-archive.tar.xz | |
| 4 | nccl | NVIDIA Collective Communications Library | 用于加速多GPU之间通信的库, 单卡 可以不用安装。 | nccl_<version>_.txz | nccl-tests |
新手可能分不清这些包之间的关系,这这个表格可以简单快速的了解安装步骤清单,需要的包也可以提前准备下。 其中cudnn及nccl的包一定要注册才能下载..。单机单卡可以不用装nccl。有版本配套关系可以提前查询确定的。 好多教程都有,这里不列了。
一些说明记录:
一:
安装驱动可能会有报错: ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver, and must be disabled before proceeding. 解决这个错误需要禁用 系统自带的nouveau驱动,具体的操作搜一下有很多。
安装完成后记得用 nvidia-smi命令检查结果,再进入下一步
二:
CUDA是运算平台名称、CUDA Toolkit是工具包。如果有的文章写 如何安装cuda / 如何安装 cuda toolkit,可以当成是同一样东西。
NVCC就是CUDA的编译器, 类似于gcc就是c语言的编译器。
每个CUDA的版本(cudatoolkit)会要求一个 最低的显卡驱动版本;
而显卡驱动会提供一个 最高支持的CUDA 版本。
CUDA有两种API,分别是 运行时API和驱动API:Runtime API 与 Driver API。
nvcc的结果是对应 CUDA Runtime API(运行API)的版本
nvidia-smi是 CUDA Driver API(驱动API)的版本,也是 当前驱动支持的 最高CUDA版本
安装cuda成功 会提示:
===========
= Summary =
===========
Driver: Installed
Toolkit: Installed in /usr/local/cuda-11.7/
Please make sure that
- PATH includes /usr/local/cuda-11.7/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-11.7/lib64, or, add /usr/local/cuda-11.7/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-11.7/bin
To uninstall the NVIDIA Driver, run nvidia-uninstall
Logfile is /var/log/cuda-installer.log
如果没有出现这个提示,要你去看日志,应该是没装成功的,本人之前遇到的错误主要还是与驱动安装有关,可能之前的没有卸载干净。
加入环境变量后, 记得source /etc/profile
vi /etc/profile
export PATH=$PATH:/usr/local/cuda-11.7/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.7/lib64
安装完成后记得用nvcc --version命令检查结果,再进入下一步。
三:
cudnn的安装主要是替换和加多头文件及包。很多安装指导解包后都是下面两步:
tar -xf cudnn-linux-x86_64-8.8.1.3_cuda11-archive.tar.xz
cp cudnn-linux-x86_64-8.8.1.3_cuda11-archive/include/* /usr/local/cuda/include/
cp cudnn-linux-x86_64-8.8.1.3_cuda11-archive/lib/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/*.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
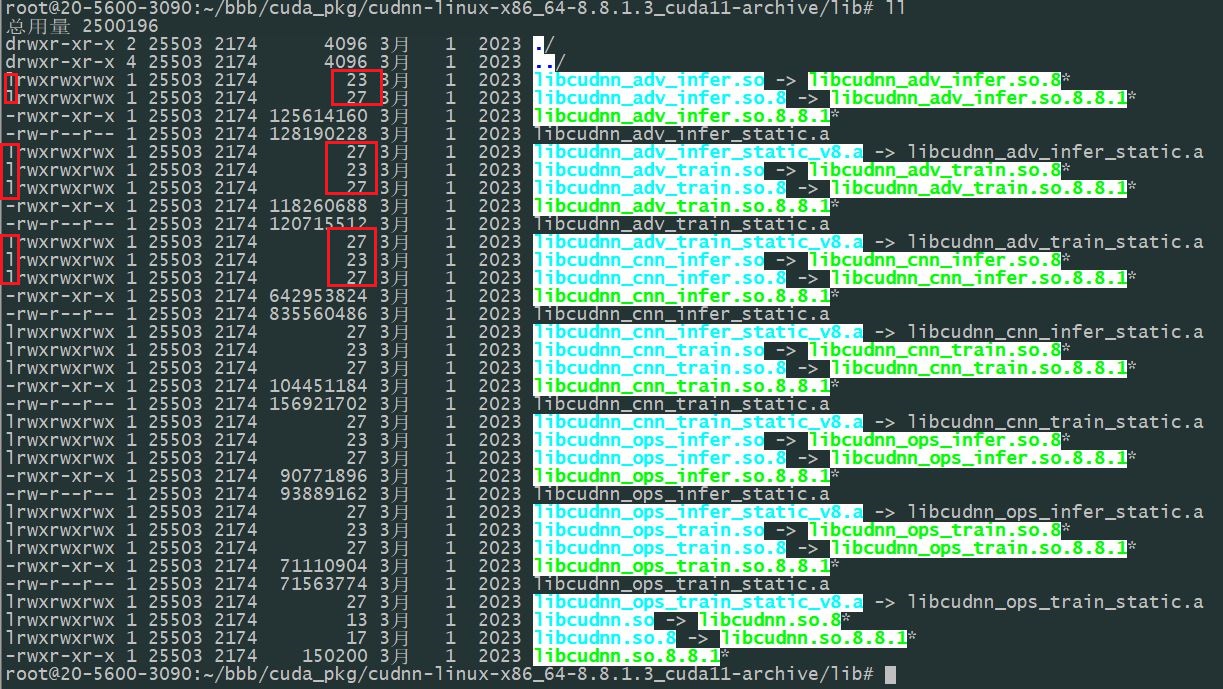
执行完以后,可以再运行sudo ldconfig 看看有没有报错。
如果有报错:
/sbin/ldconfig.real: /usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8 不是符号链接
/sbin/ldconfig.real: /usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8 不是符号链接
/sbin/ldconfig.real: /usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8 不是符号链接
/sbin/ldconfig.real: /usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8 不是符号链接
/sbin/ldconfig.real: /usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8 不是符号链接
/sbin/ldconfig.real: /usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8 不是符号链接
/sbin/ldconfig.real: /usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8 不是符号链接
ll看一下 解包后的文件,有很多是链接,但拷过去的不是链接。
解包后的:
拷贝过去的:
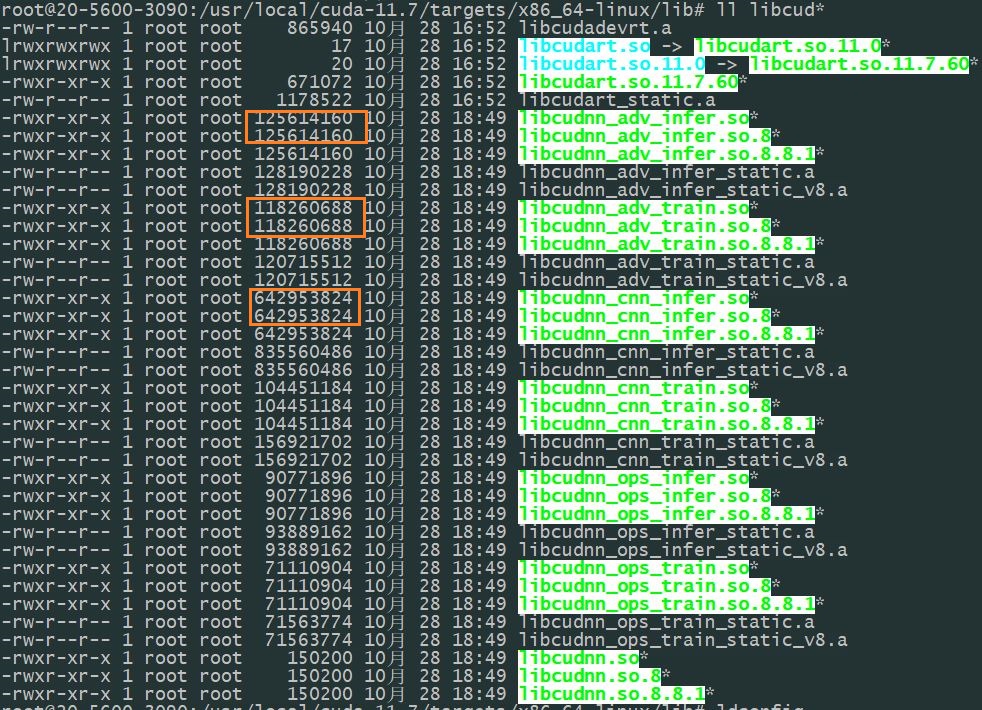
我用的最基本的方法,重新建链接。 考虑 试情况执行:
cd /usr/local/cuda/lib64/ (cd到拷贝后的目标目录)
rm -f libcudnn_adv_infer.so libcudnn_adv_infer.so.8
rm -f libcudnn_adv_train.so libcudnn_adv_train.so.8
rm -f libcudnn_cnn_infer.so libcudnn_cnn_infer.so.8
rm -f libcudnn_cnn_train.so libcudnn_cnn_train.so.8
rm -f libcudnn_ops_infer.so libcudnn_ops_infer.so.8
rm -f libcudnn_ops_train.so libcudnn_ops_train.so.8
rm -f libcudnn.so libcudnn.so.8
ln -s "libcudnn_adv_infer.so.8.8.1" libcudnn_adv_infer.so.8
ln -s libcudnn_adv_infer.so.8 libcudnn_adv_infer.so
ln -s "libcudnn_adv_train.so.8.8.1" libcudnn_adv_train.so.8
ln -s libcudnn_adv_train.so.8 libcudnn_adv_train.so
ln -s "libcudnn_cnn_infer.so.8.8.1" libcudnn_cnn_infer.so.8
ln -s libcudnn_cnn_infer.so.8 libcudnn_cnn_infer.so
ln -s "libcudnn_cnn_train.so.8.8.1" libcudnn_cnn_train.so.8
ln -s libcudnn_cnn_train.so.8 libcudnn_cnn_train.so
ln -s "libcudnn_ops_infer.so.8.8.1" libcudnn_ops_infer.so.8
ln -s libcudnn_ops_infer.so.8 libcudnn_ops_infer.so
ln -s "libcudnn_ops_train.so.8.8.1" libcudnn_ops_train.so.8
ln -s libcudnn_ops_train.so.8 libcudnn_ops_train.so
ln -s "libcudnn.so.8.8.1" libcudnn.so.8
ln -s libcudnn.so.8 libcudnn.so
再执行ldconfig 就没有报错了。
bitsandbytes 也可以从源码安装。装完后试一下 python3 -m bitsandbytes有没有报错。
如果你还不是一个装环境熟手 可以考虑先从头装起。 我刚开始试过在别人装了一部分anacoda及显卡驱动的包上再继续装,很折磨人,搞了很久最后还是没搞定。 GPU服务器一般不是我们个人电脑,上面没多少琐碎的东西。重要的包备份一下,就可以重来了。是的,重装操作系统,再继续。
把需要安装的 列表和执行命令记录下来,加速下一次的安装。 当然可以写个脚本,更加自动化。
重装操作系统后,记得 sudo apt-get update 或 yum -y update,这一步一定要做,省去后面好多不必要的麻烦。
接下来是安装gcc make这些。 把这些常用的软件装好之后,再开始装 英伟达驱动这些。
我最近几年也不用anacoda装包了。anacoda能装的包,pip一样能装。
英伟达相关的包,conda安装的包可能还只是全部的一部分,在其他场景用起来可能又不够.. 比如又缺少头文件之类。 我一般不使用anacoda这种方式。
看到某位大侠用的版本关系,可以参考:
操作系统: CentOS 7
CPUs: 单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
GPUs: 8卡A800 80GB GPUs
Python: 3.10 (需要先升级OpenSSL到1.1.1t版本(点击下载OpenSSL),然后再编译安装Python),
NVIDIA驱动程序版本: 515.65.01,根据不同型号选择不同的驱动程序。
CUDA工具包: 11.7
NCCL: nccl_2.14.3-1+cuda11.7
cuDNN: 8.8.1.3_cuda11
这篇文章也参考学习了:
https://blog.csdn.net/weixin_39928010/article/details/131142603
https://blog.csdn.net/qq_42406643/article/details/109545766