一、lang_process()
从现在开始介绍 lang_process()函数,是GNU ld(GNU链接器)的一个核心函数,负责执行链接过程中的各个关键操作。lang_process(void) 函数涵盖了整个链接过程中的各个关键步骤,包括符号解析、重定位、大小计算、内存区域管理、节的映射和输出文件的生成等。这个函数的功能非常复杂,它确保了链接器能够将多个目标文件合并成最终的可执行文件或共享库。
void
lang_process (void)
{
/* Finalize dynamic list. */
if (link_info.dynamic_list)
lang_finalize_version_expr_head (&link_info.dynamic_list->head);
current_target = default_target;
/* Open the output file. */
lang_for_each_statement (ldlang_open_output); // 输出一下
init_opb (); // x = 1
ldemul_create_output_section_statements (); // 机器相关,x86函数为NULL
/* Add to the hash table all undefineds on the command line. */
lang_place_undefineds (); // 将未定义符号加入link_info.hash
if (!bfd_section_already_linked_table_init ()) // 初始化了一个hash table
einfo (_("%P%F: Failed to create hash table\n"));
/* Create a bfd for each input file. */
current_target = default_target; // elf64-x86-64
open_input_bfds (statement_list.head, OPEN_BFD_NORMAL); // 王子龙在看
#ifdef ENABLE_PLUGINS
if (link_info.lto_plugin_active) // 没进
{
lang_statement_list_type added;
lang_statement_list_type files, inputfiles;
/* Now all files are read, let the plugin(s) decide if there
are any more to be added to the link before we call the
emulation's after_open hook. We create a private list of
input statements for this purpose, which we will eventually
insert into the global statement list after the first claimed
file. */
added = *stat_ptr;
/* We need to manipulate all three chains in synchrony. */
files = file_chain;
inputfiles = input_file_chain;
if (plugin_call_all_symbols_read ())
einfo (_("%P%F: %s: plugin reported error after all symbols read\n"),
plugin_error_plugin ());
/* Open any newly added files, updating the file chains. */
open_input_bfds (*added.tail, OPEN_BFD_NORMAL);
/* Restore the global list pointer now they have all been added. */
lang_list_remove_tail (stat_ptr, &added);
/* And detach the fresh ends of the file lists. */
lang_list_remove_tail (&file_chain, &files);
lang_list_remove_tail (&input_file_chain, &inputfiles);
/* Were any new files added? */
if (added.head != NULL)
{
/* If so, we will insert them into the statement list immediately
after the first input file that was claimed by the plugin. */
plugin_insert = find_replacements_insert_point ();
/* If a plugin adds input files without having claimed any, we
don't really have a good idea where to place them. Just putting
them at the start or end of the list is liable to leave them
outside the crtbegin...crtend range. */
ASSERT (plugin_insert != NULL);
/* Splice the new statement list into the old one. */
lang_list_insert_after (stat_ptr, &added,
&plugin_insert->header.next);
/* Likewise for the file chains. */
lang_list_insert_after (&input_file_chain, &inputfiles,
&plugin_insert->next_real_file);
/* We must be careful when relinking file_chain; we may need to
insert the new files at the head of the list if the insert
point chosen is the dummy first input file. */
if (plugin_insert->filename)
lang_list_insert_after (&file_chain, &files, &plugin_insert->next);
else
lang_list_insert_after (&file_chain, &files, &file_chain.head);
/* Rescan archives in case new undefined symbols have appeared. */
open_input_bfds (statement_list.head, OPEN_BFD_RESCAN);
}
}
#endif /* ENABLE_PLUGINS */
/* Make sure that nobody has tried to add a symbol to this list
before now. */
ASSERT (link_info.gc_sym_list == NULL);
link_info.gc_sym_list = &entry_symbol; // {next = 0x55555599c470, name = 0x555555988b10 "_start"}
if (entry_symbol.name == NULL)
{
link_info.gc_sym_list = ldlang_undef_chain_list_head;
/* entry_symbol is normally initialied by a ENTRY definition in the
linker script or the -e command line option. But if neither of
these have been used, the target specific backend may still have
provided an entry symbol via a call to lang_default_entry().
Unfortunately this value will not be processed until lang_end()
is called, long after this function has finished. So detect this
case here and add the target's entry symbol to the list of starting
points for garbage collection resolution. */
lang_add_gc_name (entry_symbol_default);
}
lang_add_gc_name (link_info.init_function);
lang_add_gc_name (link_info.fini_function);
ldemul_after_open ();
if (config.map_file != NULL)
lang_print_asneeded ();
bfd_section_already_linked_table_free (); // 为啥又把table free了???
/* Make sure that we're not mixing architectures. We call this
after all the input files have been opened, but before we do any
other processing, so that any operations merge_private_bfd_data
does on the output file will be known during the rest of the
link. */
lang_check ();
/* Handle .exports instead of a version script if we're told to do so. */
if (command_line.version_exports_section)
lang_do_version_exports_section ();
/* Build all sets based on the information gathered from the input
files. */
ldctor_build_sets (); // 符号相关的
/* PR 13683: We must rerun the assignments prior to running garbage
collection in order to make sure that all symbol aliases are resolved.
这段注释的意思是,为了确保所有符号别名(symbol aliases)都得到解析,
我们必须在运行垃圾回收(garbage collection)之前重新运行赋值(assignments)过程。
在这里,“符号别名”指的是在链接脚本或源代码中通过别名来引用的符号。
例如,你可以在链接脚本或源代码中将一个符号(Symbol)用另一个名称来引用,
这被称为符号别名。这种情况下,为了确保所有的别名都指向了正确的符号,
需要在运行垃圾回收之前重新进行一次符号赋值的过程。
这是一个确保程序在连接时符号引用正确的重要步骤。 */
lang_do_assignments (lang_mark_phase_enum); // 看看
lang_do_memory_regions();
expld.phase = lang_first_phase_enum;
/* Size up the common data. */
lang_common (); // 处理符号的
/* Remove unreferenced sections if asked to. */
lang_gc_sections (); // 删除不用的节,ld --gc-sections开启
/* Check relocations. */
lang_check_relocs ();
/* Update wild statements.排序用的 */
update_wild_statements (statement_list.head);
/* Run through the contours of the script and attach input sections
to the correct output sections. */
lang_statement_iteration++;
map_input_to_output_sections (statement_list.head, NULL, NULL); // 重点看看!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
process_insert_statements ();
/* Find any sections not attached explicitly and handle them. */
lang_place_orphans ();
if (!bfd_link_relocatable (&link_info))
{// 进来了
asection *found;
/* Merge SEC_MERGE sections. This has to be done after GC of
sections, so that GCed sections are not merged, but before
assigning dynamic symbols, since removing whole input sections
is hard then. */
bfd_merge_sections (link_info.output_bfd, &link_info);
/* Look for a text section and set the readonly attribute in it. */
found = bfd_get_section_by_name (link_info.output_bfd, ".text");
if (found != NULL)
{
if (config.text_read_only)// 进了
found->flags |= SEC_READONLY;
else
found->flags &= ~SEC_READONLY;
}
}
/* Do anything special before sizing sections. This is where ELF
and other back-ends size dynamic sections. */
ldemul_before_allocation ();
/* We must record the program headers before we try to fix the
section positions, since they will affect SIZEOF_HEADERS. */
lang_record_phdrs ();
/* Check relro sections. */
if (link_info.relro && !bfd_link_relocatable (&link_info)) // 进了
lang_find_relro_sections (); // 这在干啥????
/* Size up the sections. */
lang_size_sections (NULL, !RELAXATION_ENABLED); // 看看
/* See if anything special should be done now we know how big
everything is. This is where relaxation is done. */
ldemul_after_allocation ();
/* Fix any .startof. or .sizeof. symbols. */
lang_set_startof (); // 符号相关的
/* Do all the assignments, now that we know the final resting places
of all the symbols. */
lang_do_assignments (lang_final_phase_enum);
ldemul_finish (); // 删除Execule中的符号,改为使用keep中的符号
/* Convert absolute symbols to section relative. */
ldexp_finalize_syms (); // 处理链接脚本定义的绝对符号
/* Make sure that the section addresses make sense. */
if (command_line.check_section_addresses) // 进了
lang_check_section_addresses ();
/* Check any required symbols are known. */
ldlang_check_require_defined_symbols ();
lang_end ();
}二、lang_process执行函数
1.lang_finalize_version_expr_head
if (link_info.dynamic_list)
lang_finalize_version_expr_head (&link_info.dynamic_list->head);1)link_info 是一个结构体或对象,用于存储与链接过程相关的各种信息和参数。它通常在链接器的代码中用来跟踪链接过程中的状态和配置。link_info 可能包含各种链接器的配置选项、输入文件列表、输出文件信息、符号表、段表、动态库信息等等,这取决于链接器的实现和配置。2)2)link_info.dynamic_list 是 link_info 结构体中的一个成员,用于存储与动态链接库版本信息和表达式相关的数据。
3)&link_info.dynamic_list->head:这是对动态链接库版本列表头部的引用。
4)lang_finalize_version_expr_head:这是链接器的一个函数或方法,它的目的是处理动态链接库版本信息和相关的表达式。这通常包括检查版本依赖关系,解析版本表达式,以及确保所链接的动态库版本符合版本规范。
2. lang_for_each_statement(打开输出文件)
在lang_process()中调用lang_for_each_statement函数,并将 ldlang_open_output (这是一个函数)作为参数传入。函数 lang_for_each_statement 通常用于遍历链接器语句列表,并对每个语句执行特定的操作。在这种情况下,它将每个语句传递给 ldlang_open_output 函数。
lang_for_each_statement 函数的作用是遍历链接器的语句列表,对每个语句执行特定的操作。它通常用于链接器的初始化和处理过程中,以便处理链接脚本中定义的各种语句,执行必要的操作来构建可执行文件或共享库。
具体来说,lang_for_each_statement 的主要作用包括:
-
遍历链接器语句:它帮助链接器迭代链接器语句列表,这些语句包括符号定义、节定义、输入文件、输出文件、地址重定位等等。
-
执行用户自定义操作:用户可以通过传递一个函数指针给
lang_for_each_statement,指定要在每个链接器语句上执行的操作。这允许用户定义处理链接器语句的自定义逻辑,以适应特定需求。 -
确保正确的链接过程:链接器的处理过程通常需要根据链接脚本和命令行选项执行一系列操作,如为符号分配地址、将输入文件与输出文件相关联、应用重定位等。
lang_for_each_statement确保了这些操作能够正确执行。 -
实现链接脚本逻辑:在链接脚本中,通常会定义一系列的链接器语句,包括节的位置和属性、符号的地址分配等。
lang_for_each_statement用于实现这些链接脚本的逻辑。
总之,lang_for_each_statement 是链接器内部用于管理和处理链接器语句的关键工具,它允许用户扩展和自定义链接过程,以适应不同的链接需求和目标。这种灵活性是链接器的一个关键特征,使其能够支持各种不同的输出文件格式和链接需求。
lang_for_each_statement (ldlang_open_output);lang_for_each_statement实现:
void
lang_for_each_statement (void (*func) (lang_statement_union_type *))
{
lang_for_each_statement_worker (func, statement_list.head);
}lang_for_each_statement 实际调用的是lang_for_each_statement_worker函数,传递的参数为ldlang_open_output函数和statement_list结构体的head字段,即语句列表的首个语句。
-
它会调用
lang_for_each_statement_worker函数,将传递给lang_for_each_statement的func函数指针和语句链表statement_list的头部(statement_list.head)作为参数传递给lang_for_each_statement_worker函数。 -
lang_for_each_statement_worker函数会遍历statement_list中的每个语句,对每个语句都调用传入的func函数来执行特定的操作
static lang_statement_list_type statement_list;typedef struct statement_list
{
union lang_statement_union * head;
union lang_statement_union ** tail;
} lang_statement_list_type;typedef union lang_statement_union
{
lang_statement_header_type header;
lang_wild_statement_type wild_statement;
lang_data_statement_type data_statement;
lang_reloc_statement_type reloc_statement;
lang_address_statement_type address_statement;
lang_output_section_statement_type output_section_statement;
lang_assignment_statement_type assignment_statement;
lang_input_statement_type input_statement;
lang_target_statement_type target_statement;
lang_output_statement_type output_statement;
lang_input_section_type input_section;
lang_common_statement_type common_statement;
lang_object_symbols_statement_type object_symbols_statement;
lang_fill_statement_type fill_statement;
lang_padding_statement_type padding_statement;
lang_group_statement_type group_statement;
lang_insert_statement_type insert_statement;
} lang_statement_union_type;typedef struct lang_statement_header_struct
{
union lang_statement_union *next;
enum statement_enum type;
} lang_statement_header_type;enum statement_enum
{
lang_output_section_statement_enum,0
lang_assignment_statement_enum,1
lang_input_statement_enum,2
lang_address_statement_enum,3
lang_wild_statement_enum,4
lang_input_section_enum,5
lang_object_symbols_statement_enum,6
lang_fill_statement_enum,7
lang_data_statement_enum,8
lang_reloc_statement_enum,9
lang_target_statement_enum,10
lang_output_statement_enum,11
lang_padding_statement_enum,12
lang_group_statement_enum,13
lang_insert_statement_enum,14
lang_constructors_statement_enum
};
3. ldlang_open_output
static void
ldlang_open_output (lang_statement_union_type *statement)
{
switch (statement->header.type)
{
case lang_output_statement_enum: // 只有是输出语句类型时
ASSERT (link_info.output_bfd == NULL);
// link_info.output_bfd 是一个 BFD 句柄,用于表示链接器正在生成的输出文件。
// 它包含有关输出文件的各种信息,如文件格式、段、节、符号表等。通过该句柄,链接器可以访问和操作输出文件的各个部分,以正确地生成最终的目标文件或可执行文件。
open_output (statement->output_statement.name);
// 表示当前语句是描述输出文件的语句,该分支调用open_output函数打开该输出文件。statement->output_statement.name为输出文件的名称。
ldemul_set_output_arch (); // 它将链接器的输出架构设置为与当前目标或配置相关的架构。
if (config.magic_demand_paged
&& !bfd_link_relocatable (&link_info))
link_info.output_bfd->flags |= D_PAGED;
else
link_info.output_bfd->flags &= ~D_PAGED;
if (config.text_read_only)
link_info.output_bfd->flags |= WP_TEXT;
else
link_info.output_bfd->flags &= ~WP_TEXT;
if (link_info.traditional_format)
link_info.output_bfd->flags |= BFD_TRADITIONAL_FORMAT;
else
link_info.output_bfd->flags &= ~BFD_TRADITIONAL_FORMAT;
break;
case lang_target_statement_enum:
current_target = statement->target_statement.target;
// 表示当前语句是目标架构语句,该分支内部将当前目标架构设置为语句中指定的目标
break;
default:
break;
}
}4. lang_for_each_statement_worker
lang_for_each_statement_worker (void (*func) (lang_statement_union_type *),
lang_statement_union_type *s)
// 传进来的是ldlang_open_output函数以及statement_list.head
{
for (; s != NULL; s = s->header.next)
{
func (s); // 调用ldlang_open_output
switch (s->header.type)
{
case lang_constructors_statement_enum:
lang_for_each_statement_worker (func, constructor_list.head);
break;
case lang_output_section_statement_enum:
if (s->output_section_statement.constraint != -1)
lang_for_each_statement_worker(func,
s->output_section_statement.children.head);
break;
case lang_wild_statement_enum:
lang_for_each_statement_worker (func,
s->wild_statement.children.head);
break;
case lang_group_statement_enum:
lang_for_each_statement_worker (func,
s->group_statement.children.head);
break;
case lang_data_statement_enum:
case lang_reloc_statement_enum:
case lang_object_symbols_statement_enum:
case lang_output_statement_enum:
case lang_target_statement_enum:
case lang_input_section_enum:
case lang_input_statement_enum:
case lang_assignment_statement_enum:
case lang_padding_statement_enum:
case lang_address_statement_enum:
case lang_fill_statement_enum:
case lang_insert_statement_enum:
break;
default:
FAIL ();
break;
}
}
}5.open_output
static void
open_output (const char *name)
{
// 确定输出文件的目标架构(用户指出/其它/默认) elf64-x86-64
output_target = lang_get_output_target ();
// 查看生成的目标文件与用户指定的字节序一致,选择适当的输出目标(output_target)
// 根据用户指定或者默认的目标架构来决定输出文件的字节序
/* Has the user requested a particular endianness on the command
line? */
// command_line.endian 用户的命令行
if (command_line.endian != ENDIAN_UNSET)
{
// ENDIAN_UNSET 用于表示字节序未明确定义或未设置
/* Get the chosen target. */
const bfd_target *target
= bfd_iterate_over_targets (get_target, (void *) output_target);
// target 用于存储当前遍历到的目标文件描述符。当找到与 output_target 匹配的目标时,target 将存储该匹配的目标。
//目标文件格式:描述目标文件所采用的二进制文件格式,如ELF、COFF、Mach-O等。这包括文件头的结构和元数据。
//目标体系结构:描述目标文件的目标计算机体系结构,如x86、ARM、MIPS等。这决定了目标文件的指令集和寄存器布局。
//字节序(endianness):描述目标文件中数据的排列顺序,如大端序(Big-Endian)或小端序(Little-Endian)。
//文件扩展名:用于标识目标文件格式的常见文件扩展名,如".elf"、".o"等。
//其他格式特定的信息:包括段、节、符号表等目标文件的特定信息。
/* If the target is not supported, we cannot do anything. */
if (target != NULL)
{
enum bfd_endian desired_endian;
if (command_line.endian == ENDIAN_BIG)
desired_endian = BFD_ENDIAN_BIG;
else
desired_endian = BFD_ENDIAN_LITTLE;
/* See if the target has the wrong endianness. This should
not happen if the linker script has provided big and
little endian alternatives, but some scrips don't do
this. */
if (target->byteorder != desired_endian)
// target->byteorder 表示目标文件描述符所使用的字节序
{
/* If it does, then see if the target provides
an alternative with the correct endianness. */
if (target->alternative_target != NULL
&& (target->alternative_target->byteorder == desired_endian))
output_target = target->alternative_target->name;
else
{
/* Try to find a target as similar as possible to
the default target, but which has the desired
endian characteristic. */
bfd_iterate_over_targets (closest_target_match,
(void *) target);
/* Oh dear - we could not find any targets that
satisfy our requirements. */
if (winner == NULL)
einfo (_("%P: warning: could not find any targets"
" that match endianness requirement\n"));
else
output_target = winner->name;
}
}
}
}
link_info.output_bfd = bfd_openw (name, output_target);
// 该函数接受输出文件的名称和目标架构作为参数
// 链接器需要将生成的代码和数据写入此输出文件。
// 调用bfd_openw函数打开输出文件,并赋值给link_info.output_bfd,设置link_info;
if (link_info.output_bfd == NULL)
{
if (bfd_get_error () == bfd_error_invalid_target)
einfo (_("%P%F: target %s not found\n"), output_target);
einfo (_("%P%F: cannot open output file %s: %E\n"), name);
}
delete_output_file_on_failure = TRUE;
// 设置输出文件的格式
if (!bfd_set_format (link_info.output_bfd, bfd_object))
einfo (_("%P%F:%s: can not make object file: %E\n"), name);
// 设置输出文件的架构
if (!bfd_set_arch_mach (link_info.output_bfd,
ldfile_output_architecture,
ldfile_output_machine))
einfo (_("%P%F:%s: can not set architecture: %E\n"), name);
// 函数创建链接时使用的hash表,用于存储链接器符号表中的符号信息,用于符号解析和链接过程中的符号查找
link_info.hash = bfd_link_hash_table_create (link_info.output_bfd);
if (link_info.hash == NULL)
einfo (_("%P%F: can not create hash table: %E\n"));
bfd_set_gp_size (link_info.output_bfd, g_switch_value);
}
6. bfd_openw
bfd *
bfd_openw (const char *filename, const char *target)
{
bfd *nbfd;
const bfd_target *target_vec;
/* nbfd has to point to head of malloc'ed block so that bfd_close may
reclaim it correctly. */
nbfd = _bfd_new_bfd ();
if (nbfd == NULL)
return NULL;
target_vec = bfd_find_target (target, nbfd);
if (target_vec == NULL)
{
_bfd_delete_bfd (nbfd);
return NULL;
}
/* PR 11983: Do not cache the original filename, but
rather make a copy - the original might go away. */
nbfd->filename = xstrdup (filename);
nbfd->direction = write_direction;
if (bfd_open_file (nbfd) == NULL)
{
/* File not writeable, etc. */
bfd_set_error (bfd_error_system_call);
_bfd_delete_bfd (nbfd);
return NULL;
}
return nbfd;
}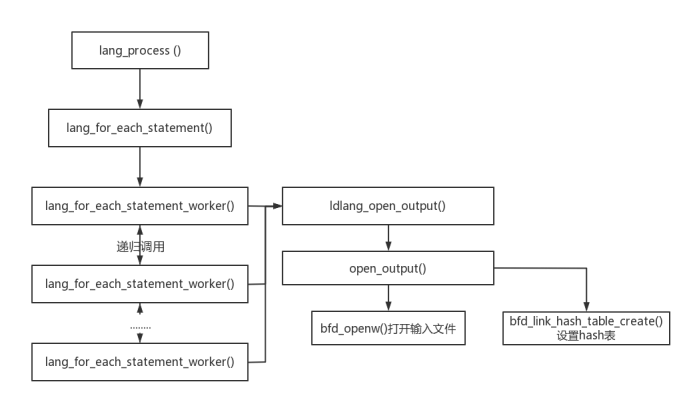 在lang_process()中,调用lang_for_each_statement() ,将ldlang_open_output作为参数传入,实际调用的是lang_for_each_statement_worker函数,传递的参数为dlang_open_output函数与statement_list结构体的head字段,即语句列表的首个语句。lang_for_each_statement_worker函数最开始会先运行作为参数被传递进来的ldlang_open_output函数,并把另一个参数statement_list结构体的head字段传递给ldlang_open_output函数。
在lang_process()中,调用lang_for_each_statement() ,将ldlang_open_output作为参数传入,实际调用的是lang_for_each_statement_worker函数,传递的参数为dlang_open_output函数与statement_list结构体的head字段,即语句列表的首个语句。lang_for_each_statement_worker函数最开始会先运行作为参数被传递进来的ldlang_open_output函数,并把另一个参数statement_list结构体的head字段传递给ldlang_open_output函数。
open_output函数主要工作为:
1.确定输出文件的目标架构;
2.根据用户指定或者默认的目标架构来决定输出文件的字节序;
3.调用bfd_openw函数打开输出文件,并赋值给link_info.output_bfd,设置link_info;
4.调用bfd_link_hash_table_create函数创建链接时使用的hash表,用于存储链接器符号表中的符号信息,用于符号解析和链接过程中的符号查找。