目录
一、数据读取及分析
1、数据读取
2、数据分析
二、数据挖掘
三、模型构建及评估
四、划重点
推荐相关文章
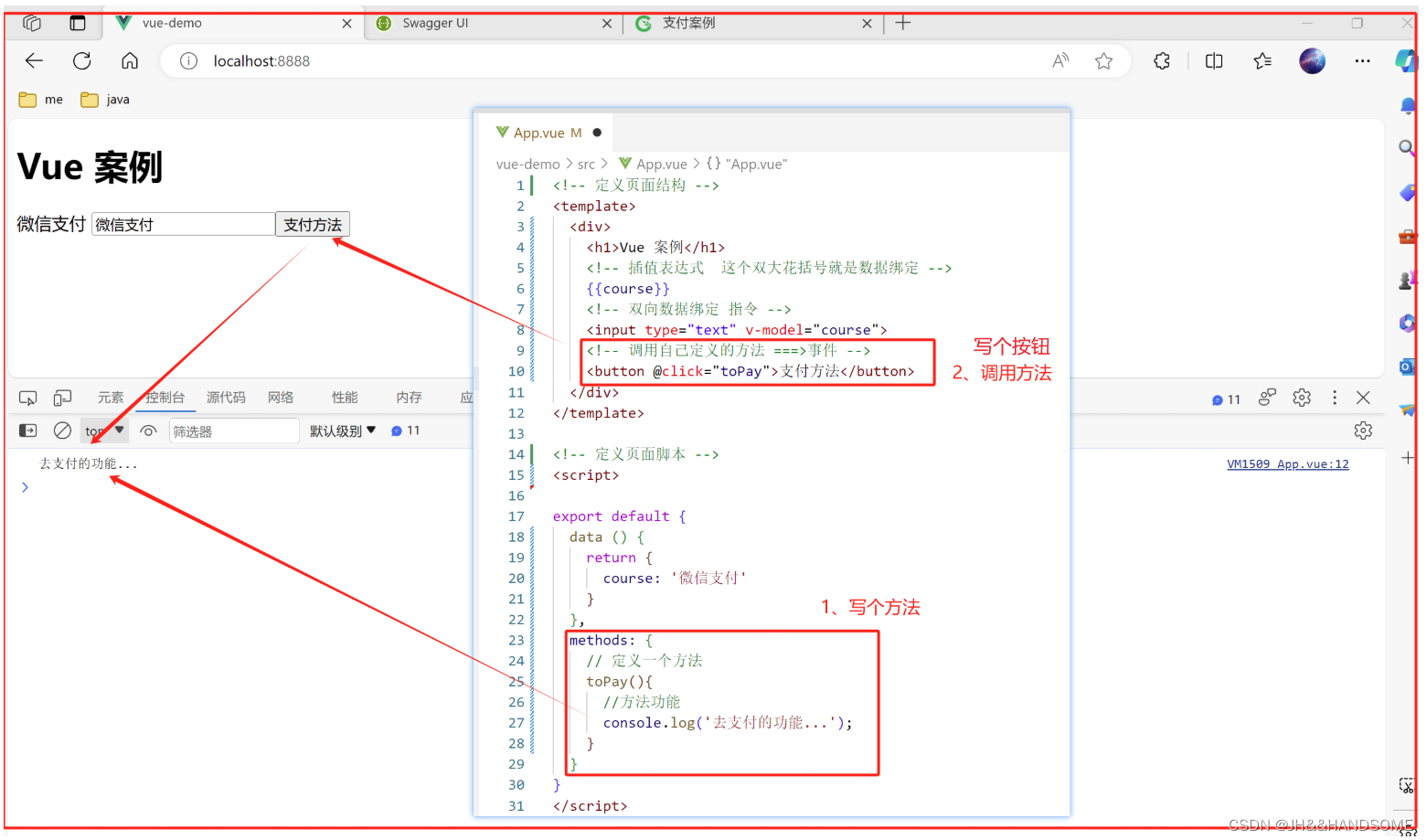
去年在DataCastle上参加了华录杯算法赛,初赛前10、进复赛就没打了。相比于之前文章 kaggle风控建模实战(文末附链接),本文数据处理较为复杂、特征挖掘内容较多,适合统计学/机器学习相关专业、或者有一定模型算法/数据挖掘经验的同学,经验较浅的也可以作为进阶项目实战提升。
一、数据读取及分析
1、数据读取
使用DataCastle上华录杯算法赛-企业安全风险评估赛道数据集,其中训练集7117条、测试集1500条,测试集没有给score、需要参赛选手上传预测结果平台自动评估反馈;下图为训练集数据,其中score为风险评分、取值范围0-100,因此这个赛题可以转为二分类模型、也可以用回归模型 数据获取见文末

数据集中详细信息包括如下9个表,需要以业户id为主键拼接、再做特征挖掘
(1)运政业户信息

(2)运政车辆信息

(3)车辆违法违规信息(道路交通安全,来源抄告)

(4)车辆违法违规信息(交通运输违法,来源抄告)

(5)动态监控报警信息(车辆,超速行驶)
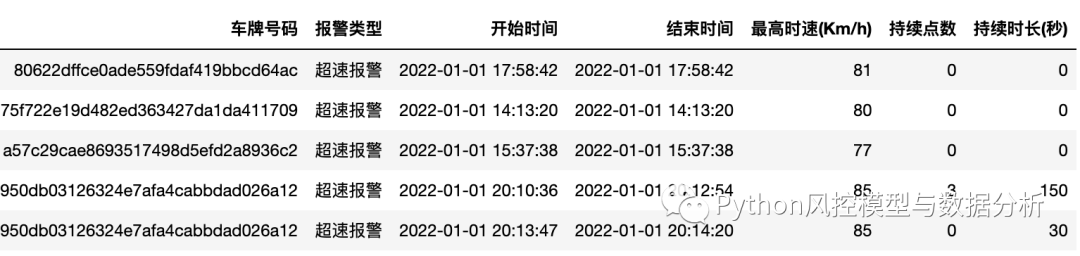
(6)动态监控报警信息(车辆,疲劳驾驶)

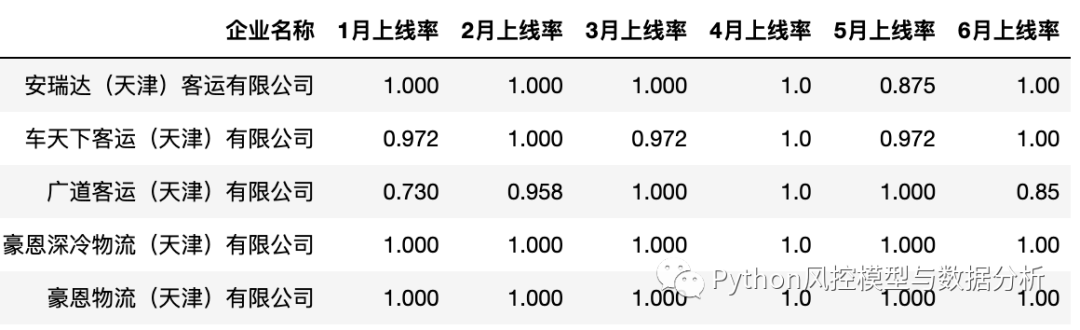
(7)动态监控上线率(企业,%)
(8)运政车辆年审记录信息

(9)运政质量信誉考核记录

2、数据分析
(1)训练集score分布,大多集中在高分(分数越代表安全风险越低)

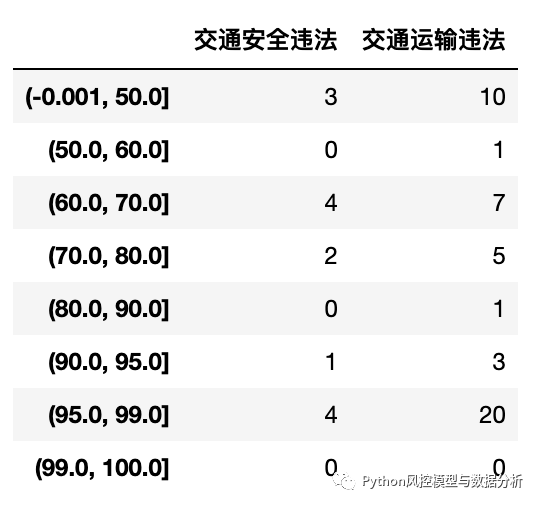
(2)将数据拼接后,查看存在过交通安全、运输违法车辆对应的业户id风险评分分布情况,可以发现这部分评分整体偏低,因此是否有过违法违规行为对风险评分影响较大
二、数据挖掘
1、运政业户信息和运政车辆信息表
均有行业类别字段(分别为企业的行业类别、车辆的行业类别),数据拼接后可以衍生类别一致性特征;
2、交通安全违法/运输违法表
按照观察时间往前切片[0,1,5,10,15,30,60,90,180,360,720](天),分别统计不同时间窗口下的交通安全违法次数、运输违法次数
3、动态监控报警信息(车辆,超速行驶)表/动态监控报警信息(车辆,疲劳驾驶)表
分别统计不同时间窗口下的超速报警次数;对最高时速(Km/h), 持续点数, 持续时长(秒)三个字段分别统计不同时间窗口下的max, min, mean, median, std, count, sum
4、动态监控上线率(企业,%)表
对近3个月、近6个月上线率分别统计mean, max, min, std;分别统计近3个月、近6个月上线率不满100%的次数
5、运政车辆年审记录信息表
分别统计近0,1,3,5,7,10,20年的年审次数、年审合格次数
6、运政质量信誉考核记录表
分别统计近30,90,360,720天的信誉考核次数,以及考核结果为优良(AAA), 合格(AA), 基本合格(A), 不合格(B)各类别的次数
数据挖掘代码,最终特征数量548个
def get_feature_across_window(df,key,col,func,day_diff,window_list,float_fea_list=[]):
l=[]
for window in window_list:
df_window=df[df[day_diff]<=window]
if func==cnt_feature:
df_window_sta=df_window.pipe(func,key,col).add_suffix('_'+'window'+'_'+str(window))
elif func==float_feature_stata:
df_window_sta=df_window.pipe(func,key,col,float_fea_list).add_suffix('_'+'window'+'_'+str(window))
l.append(df_window_sta)
return pd.concat(l,axis=1)
def cnt_feature(df,key,col):
result=df.groupby([key])[col].count().to_frame().rename(columns={col:'cnt'})
return result
STATS_LIST = ['max', 'min', 'mean', 'median', 'std','count','sum']
def float_feature_stata(df,key,col,float_fea_list,STATS_LIST=STATS_LIST):
l=[]
for col in float_fea_list:
df_col_sta=df.groupby(key)[col].agg(STATS_LIST)
df_col_sta.columns=[col+'_'+sta for sta in STATS_LIST]
l.append(df_col_sta)
return pd.concat(l,axis=1)
window_list=[0,1,5,10,15,30,60,90,180,360,720]
def traffic_safety_data_pre(df,window_list):
df_copy=df.copy()
df_copy['行业类别']=df_copy['行业类别'].map({'包车客运':'道路旅客运输','危货运输':'道路危险货物运输'})
df_copy['观察时间']='2022-06-30'
df_copy['day_diff']=(pd.to_datetime(df_copy['观察时间'])-pd.to_datetime(df_copy['违规时间'])).dt.days
key,col,func,day_diff,window_list='车牌号','行业类别',cnt_feature,'day_diff',window_list
result=df_copy.pipe(get_feature_across_window,key,col,func,day_diff,window_list)
return result
def speeding_data_pre(df,window_list):
df_copy=df.rename(columns={'车牌号码':'车牌号'}).copy()
df_copy['观察时间']='2022-06-30'
df_copy['day_diff']=(pd.to_datetime(df_copy['观察时间'])-pd.to_datetime(df_copy['开始时间'])).dt.days
key,col,func,day_diff,window_list='车牌号','报警类型',float_feature_stata,'day_diff',window_list
float_fea_list=['最高时速(Km/h)', '持续点数', '持续时长(秒)']
df_float=df_copy.pipe(get_feature_across_window,key,col,func,day_diff,window_list,float_fea_list)
key,col,func,day_diff,window_list='车牌号','报警类型',cnt_feature,'day_diff',window_list
df_cnt=df_copy.pipe(get_feature_across_window,key,col,func,day_diff,window_list)
return pd.concat([df_float,df_cnt],axis=1)
def get_launch_df(df):
df_copy=df.copy()
three_month_col=[str(month)+'月上线率' for month in [4,5,6]]
six_month_col=[str(month)+'月上线率' for month in [1,2,3,4,5,6]]
stata_list=['mean','max','min','std']
df_fea_3month=df_copy[three_month_col].agg(stata_list,axis=1).add_prefix('three_month_')
df_fea_6month=df_copy[six_month_col].agg(stata_list,axis=1).add_prefix('six_month_')
df_fea_3month_cnt=df_copy[df_copy[three_month_col]!=1].count(axis=1).to_frame().rename(columns={0:'not1_cnt'}).add_prefix('three_month_')
df_fea_6month_cnt=df_copy[df_copy[six_month_col]!=1].count(axis=1).to_frame().rename(columns={0:'not1_cnt'}).add_prefix('six_month_')
return pd.concat([
df_copy,
df_fea_3month,
df_fea_6month,
df_fea_3month_cnt,
df_fea_6month_cnt
],axis=1)
def annual_review_df(df):
df_copy=df.rename(columns={'车辆牌照号':'车牌号'}).copy()
df_copy['观察时间']=2022
df_copy['year_diff']=df_copy['观察时间']-df_copy['年审年度']
key,col,func,day_diff,window_list='车牌号','审批结果',cnt_feature,'year_diff',[0,1,3,5,7,10,20]
df_review_cnt=df_copy.pipe(get_feature_across_window,key,col,func,day_diff,window_list).add_prefix('review_')
df_qualified_cnt=df_copy[df_copy['审批结果']=='年审合格'].pipe(get_feature_across_window,key,col,func,day_diff,window_list).add_prefix('qualified_')
df_annual_review=pd.concat([df_review_cnt,df_qualified_cnt],axis=1)
return df_annual_review
def reputation_assessment_df(df):
df_copy=df.copy()
df_copy['观察时间']='2022-06-30'
df_copy['day_diff']=(pd.to_datetime(df_copy['观察时间'])-pd.to_datetime(df_copy['考核日期'])).dt.days
key,col,func,day_diff,window_list='业户ID','质量信誉考核结果',cnt_feature,'day_diff',[30,90,360,720]
df_reputation_all=df_copy.pipe(get_feature_across_window,key,col,func,day_diff,window_list).add_prefix('reputation_all_')
l=[]
for grade in ['优良(AAA)', '合格(AA)', '基本合格(A)', '不合格(B)']:
key,col,func,day_diff,window_list='业户ID','质量信誉考核结果',cnt_feature,'day_diff',[30,90,360,720]
df_reputation_grade=df_copy[df_copy['质量信誉考核结果']==grade].pipe(get_feature_across_window,key,col,func,day_diff,window_list).add_prefix('reputation_'+re.findall('\((.*?)\)',grade)[0]+'_')
l.append(df_reputation_grade)
df_reputation_assessment=pd.concat([df_reputation_all]+l,axis=1)
return df_reputation_assessment
def get_all_df(df_list,df_train_label):
df_all=df_list[1].rename(columns={'车辆牌照号':'车牌号'}).merge(df_train_label,left_on=['车牌号'],right_on=['car_id'],how='left').drop(['car_id'],axis=1)
df_all['sample_label']=np.where(df_all.score.notnull(),'train','test')
df_all=df_all.merge(df_list[0],on=['业户ID'],how='left')
df_all.rename(columns={'行业类别_x':'车辆行业类别','行业类别_y':'企业行业类别'},inplace=True)
df_all['类别一致性']=np.where(df_all['车辆行业类别']==df_all['企业行业类别'],1,0)
df_traffic_safety=df_list[2].pipe(traffic_safety_data_pre,[30,90,180,360,720])
df_illegal_trans=df_list[3].pipe(traffic_safety_data_pre,[30,90,180,360,720])
df_speeding=df_list[4].pipe(speeding_data_pre,window_list)
df_fatigue_driving=df_list[5].pipe(speeding_data_pre,window_list)
df_launch=df_list[6].pipe(get_launch_df)
df_annual_review=df_list[7].pipe(annual_review_df)
df_reputation_assessment=df_list[8].pipe(reputation_assessment_df)
df_license_concat=pd.concat([
df_traffic_safety.add_prefix('traffic_safety_'),
df_illegal_trans.add_prefix('illegal_trans_'),
df_speeding.add_prefix('speeding_'),
df_fatigue_driving.add_prefix('fatigue_driving_'),
df_annual_review.add_prefix('annual_review_')
],axis=1)
df_launch.columns=['launch_'+col if col not in ['企业名称'] else col for col in df_launch.columns]
df_all=df_all.merge(df_license_concat.reset_index(),on=['车牌号'],how='left')
df_all=df_all.merge(df_launch,on=['企业名称'],how='left')
df_all=df_all.merge(df_reputation_assessment.reset_index(),on=['业户ID'],how='left')
return df_all
df_all=get_all_df(df_list,df_train_label)
print(df_all.shape)
df_all.head()
fea_list=['车牌颜色','车辆行业类别','企业行业类别','类别一致性']+list(df_all.loc[:,'traffic_safety_cnt_window_30':].columns)
len(fea_list)
三、模型构建及评估
使用xgb构建回归模型,使用mse、mae、r2进行评估(其他回归模型、二分类模型的方式大家可以自行尝试)

from math import sqrt
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score
def init_params_regression():
params_xgb={
'objective':'reg:squarederror',
'eval_metric':'rmse',
# 'silent':0,
'nthread':4,
'n_estimators':500,
'eta':0.02,
# 'num_leaves':10,
'max_depth':3,
'min_child_weight':50,
'scale_pos_weight':1,
'gamma':5,
'reg_alpha':2,
'reg_lambda':2,
'subsample':0.8,
'colsample_bytree':0.8,
'seed':123
}
return params_xgb
def mse_value(y_value,df,model):
y_pred=model.predict(df)
mae=mean_absolute_error(y_value, y_pred)
mse=mean_squared_error(y_value, y_pred)
r2=r2_score(y_value, y_pred)
return mae,mse,r2
def model_train_sklearn_regression(model_label,train,y_name,model_var,params=None,random_state=123):
if params is None:
params=init_params_regression()
x_train,x_test, y_train, y_test =train_test_split(train[model_var],train[y_name],test_size=0.2, random_state=random_state)
model=XGBRegressor(**params)
model.fit(x_train,y_train,eval_set=[(x_train, y_train),(x_test, y_test)],verbose=False) # 调参时设verbose=False
train_mae,train_mse,train_r2=mse_value(y_train,x_train,model)
test_mae,test_mse,test_r2=mse_value(y_test,x_test,model)
all_mae,all_mse,all_r2=mse_value(train[y_name],train[model_var],model)
dic={
'model_label':model_label,
'train':y_train.count(),
'test':y_test.count(),
'all':train.shape[0],
'train_mse':train_mse,'train_mae':train_mae,'train_r2':train_r2,
'test_mse':test_mse,'test_mae':test_mae,'test_r2':test_r2,
'all_mse':all_mse,'all_mae':all_mae,'all_r2':all_r2,
}
return dic,model
params=init_params_regression()
params.update({'n_estimators':900,'eta':0.65})
model_result,model=model_train_sklearn_regression('label',df_all[df_all['sample_label']=='train'],'score',
fea_list[3:],params=params)
model_result四、划重点
关注公众号 Python风控模型与数据分析,回复 企业风险算法实战 获取本篇数据及代码
推荐相关文章
租房价格分析及预测(xgb+catboost+rf)
kaggle风控建模实战(XGB+LGB+RF+LR)
NGBoost参数详解及实战
catboost参数详解及实战(强推)
风控算法赛lgb实战-拍拍贷魔镜杯