0. 项目来源
中文生成式预训练模型,以mT5为基础架构和初始权重,通过类似PEGASUS的方式进行预训练。
bert4keras版:t5-pegasus
pytorch版:t5-pegasus-pytorch
本次主要学习pytorch版的代码解读。
项目结构:
train.py:用于模型训练
1. model
(1)t5-base
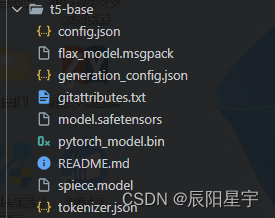
在T5模型中,不同的文件具有不同的含义和作用。下面是对每个文件的简要说明:
config.json:该文件包含了T5模型的配置信息,例如模型的层数、隐藏单元的维度、词汇表大小等。在加载T5模型时,需要使用该文件来构建模型的结构和参数。
flax_model.msgpack:这是一个二进制文件,包含了使用Flax库序列化的T5模型的权重。Flax是一个用于定义、训练和推断基于JAX的模型的库。此文件包含了模型的所有权重参数。
generation_config.json:这个文件包含了T5模型用于生成文本的配置信息,例如生成器的最大长度、温度参数等。在使用T5模型进行文本生成时,可以根据需要修改这些配置信息。
model.safetensors:这是一个二进制文件,包含了T5模型的安全张量(SafeTensors)。安全张量是一种保证模型权重不可修改的张量表示形式,用于提供额外的安全性和防止权重泄漏。
pytorch_model.bin:这是一个二进制文件,包含了T5模型的权重参数。它是基于PyTorch框架的模型权重的序列化形式。在加载T5模型时,可以使用该文件来初始化PyTorch模型的权重。
spiece.model:这是T5模型的词汇表文件,其中包含了模型使用的所有子词(subword)和它们对应的ID。在使用T5模型进行文本编码和解码时,需要使用该词汇表进行子词的映射。
tokenizer.json:该文件包含了T5模型的分词器(tokenizer)的配置信息和词汇表。分词器用于将输入文本切分成子词,以便输入到T5模型进行编码和解码。
这些文件在T5模型中扮演重要的角色,用于保存模型的配置、权重参数、词汇表等信息,以便在需要时加载和使用模型。
注:flax_model.msgpack和pytorch_model.bin的区别在于它们是针对不同的框架和序列化方式而生成的。Flax使用自己的序列化方式将模型权重保存到flax_model.msgpack文件中,而PyTorch使用其自己的序列化方式将模型权重保存到pytorch_model.bin文件中。如果要在Flax框架中加载模型权重,应使用flax_model.msgpack文件;如果要在PyTorch框架中加载模型权重,应使用pytorch_model.bin文件。这两个文件包含了相同的权重参数,但其序列化格式和加载方式略有不同。
(2)chinese_t5_pegasus_base
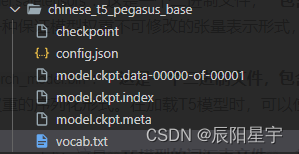
在"chinese_t5_pegasus_base"模型中,不同的文件具有以下含义:
checkpoint:这是一个文本文件,保存断点文件列表,记录了模型的训练信息,例如最新的模型检查点文件名、全局步数等。
config.json:该文件包含了T5 Pegasus模型的配置信息,例如模型的层数、隐藏单元的维度、词汇表大小等。在加载T5 Pegasus模型时,需要使用该文件来构建模型的结构和参数。
model.ckpt.data-00000-of-00001、model.ckpt.index、model.ckpt.meta:这些文件是TensorFlow训练保存的模型检查点文件。它们一起组成了TensorFlow的SavedModel格式,包含了T5 Pegasus模型的权重参数和计算图。
vocab.txt:这是T5 Pegasus模型的词汇表文件,其中包含了模型使用的所有词汇和它们对应的ID。在使用T5 Pegasus模型进行文本编码和解码时,需要使用该词汇表进行词汇的映射。
这些文件在"chinese_t5_pegasus_base"模型中扮演重要的角色,用于保存模型的配置、权重参数、词汇表等信息,以便在需要时加载和使用模型。
1. train.py
代码的作用是使用PyTorch Lightning库进行交叉验证训练,保存每个fold的模型权重,并在训练过程中输出一些性能指标(如BLEU和ROUGE)的日志信息。
pytorch_lightning库教程:16、Pytorch Lightning入门
'''
这段代码的作用是使用PyTorch Lightning库进行交叉验证训练,保存每个fold的模型权重,并在训练过程中输出一些性能指标(如BLEU和ROUGE)的日志信息。
'''
import os
import pytorch_lightning as pl
from utils import *
from models import LightModel
from args import parser
if __name__ == '__main__':
# 解析命令行参数
args = parser.parse_args()
# 创建模型和数据记载器
model = LightModel(args)
data = EncoderDecoderData(args, model.tokenizer)
dataloaders = data.get_dataloader()
# 进行交叉验证训练
for fold in range(args.kfold):
# pl.seed_everything设置随机种子,以确保可重复性
pl.seed_everything(args.seed + fold)
# 从dataloaders中获取当前fold的训练数据和验证数据,并将其分配给train_data和dev_data变量
train_data, dev_data = dataloaders['train'][fold], dataloaders['dev'][fold]
# 如果不是第一个fold(fold > 0),则重新创建一个新的LightModel对象,以便每个fold都有一个独立的模型实例
if fold > 0:
model = LightModel(args)
# 创建一个ModelCheckpoint回调对象,用于在训练过程中保存模型的权重
## 定义了保存模型的目录路径、文件名模板以及保存的条件和方式
checkpoint = pl.callbacks.ModelCheckpoint(
dirpath=args.output_dir,
filename='{fold:02d}-{epoch:02d}-{bleu:.4f}-{rouge:.4f}-{rouge-1:.4f}-{rouge-2:.4f}-{rouge-l:.4f}',
save_weights_only=True,
save_on_train_epoch_end=True,
monitor='rouge',
mode='max',
)
# 使用pl.Trainer.from_argparse_args方法创建一个Trainer对象,该对象用于管理训练和验证过程
## 使用args中的参数进行配置,并将之前创建的checkpoint回调对象传递给callbacks参数,logger=False参数禁止了训练过程中的日志输出
trainer = pl.Trainer.from_argparse_args(args, callbacks=[checkpoint], logger=False)
# 调用trainer.fit方法开始训练过程,传递model、train_data和dev_data作为参数
## 训练过程会根据配置的参数进行多个epoch的训练,并在训练过程中调用checkpoint回调对象来保存模型
trainer.fit(model, train_data, dev_data)
# 在每个fold的训练完成后,通过del语句删除model和trainer对象显示的释放内存,并使用torch.cuda.empty_cache()释放GPU显存
del model
del trainer
torch.cuda.empty_cache()
问题:
(1)为什么要保证每个fold都有一个独立的模型实例?
为了让模型的权重只会受到当前fold训练数据的影响,不会受到其他fold的训练数据影响。
具体解释:保证每个fold都有一个独立的模型实例是为了确保交叉验证的准确性和可靠性。
在交叉验证过程中,数据集被分成k个子集(折叠),每个子集都会被轮流作为验证集,其余子集作为训练集。模型会在每个子集上进行训练和验证,最终得到k个模型的性能评估结果。
如果在每个fold中都使用同一个模型实例,那么在每个fold的训练过程中,模型的权重会被更新这会导致每个fold的模型在训练过程中相互影响,可能会导致不准确的评估结果。
为了避免这种情况,需要保证每个fold都有一个独立的模型实例。这样,在每个fold的训练过程中,模型的权重只会受当前fold的训练数据影响,不会受其他fold的训练数据影响。 这样可以确保每个fold的评估结果是相互独立且可靠的。
因此,为了保证交叉验证的准确性和可靠性,每个fold都需要使用一个独立的模型实例。
(2)ModelCheckpoint是什么?主要起到什么作用?
ModelCheckpoint是PyTorch Lightning库中的一个回调函数(callback),用于在训练过程中保存模型的权重。
具体解释:主要作用如下:
(1)定期保存模型权重:ModelCheckpoint可以在训练过程中的指定时间点保存模型的权重。例如,可以设置每个epoch结束后保存模型,或者根据验证指标的变化情况保存最佳模型的权重。
(2)自定义保存路径和文件名:可以通过dirpath和filename参数来指定保存模型权重的目录路径和文件名模板。可以在文件名中使用占位符来包含一些信息,如当前epoch、验证指标等。
(3)保存模型权重的条件和方式:可以通过设置monitor和mode参数来定义保存模型权重的条件和方式。monitor指定要监视的验证指标,mode指定验证指标的增大或减小。例如,可以根据验证指标的最大值或最小值保存模型权重。
(4)仅保存模型权重:通过设置save_weights_only=True,可以只保存模型的权重参数,而不保存完整的模型对象。这样可以节省存储空间。
(5)自定义保存逻辑:ModelCheckpoint还提供了一些其他参数和方法,可以根据需要自定义保存模型权重的逻辑。例如,可以通过设置save_top_k参数来保存最好的几个模型权重,或者通过重写on_train_epoch_end方法来实现自定义的保存逻辑。
总之,ModelCheckpoint的主要作用是在训练过程中定期保存模型权重,以便在训练结束后或者在验证过程中选择最佳的模型权重。这对于后续的模型评估、推理或部署非常有用。
(3)保存模型权重的条件和方式种monitor和mode这两个参数,具体是做什么的?
ModelCheckpoint的monitor和mode参数用于定义保存模型权重的条件和方式。
(1)monitor参数:指定要监视的验证指标。可以是任何有效的指标名称或字符串。通常,这个指标应该与模型的性能相关,如准确率、损失函数值或其他评估指标(如BLEU、ROUGE等)。
(2)mode参数:指定验证指标的增大或减小。 有两个可选值:
‘auto’:根据验证指标的类型自动选择模式。如果验证指标是损失函数,将选择’min’模式,即验证指标越小越好。如果验证指标是准确率或其他评估指标,将选择’max’模式,即验证指标越大越好。
‘min’:选择验证指标最小化的模式。当验证指标的值越小越好时,应选择此模式。
‘max’:选择验证指标最大化的模式。当验证指标的值越大越好时,应选择此模式。
根据monitor和mode的组合,ModelCheckpoint会在满足特定条件时保存模型权重。具体行为如下:
(1)如果mode为’min’,ModelCheckpoint会在验证指标的值减小时保存模型权重。
(2)如果mode为’max’,ModelCheckpoint会在验证指标的值增大时保存模型权重。
(3)如果mode为’auto’,ModelCheckpoint会根据验证指标的类型自动选择增大或减小的模式。
无论是’min’模式还是’max’模式,ModelCheckpoint都会根据monitor指定的验证指标进行比较,以确定是否要保存模型权重。例如,如果monitor='loss’且mode=‘min’,则ModelCheckpoint会在验证损失函数值减小时保存模型权重。
此外,ModelCheckpoint还提供了其他参数,如save_top_k,用于定义要保存的最好模型的数量。可以根据需求自定义保存模型权重的行为。
总之,monitor和mode参数用于在ModelCheckpoint中定义保存模型权重的条件和方式。通过设置这些参数,可以根据验证指标的变化自动选择并保存性能最佳的模型权重。
(4)monitor='rouge’是起什么作用?
当monitor='rouge’时,ModelCheckpoint会监视ROUGE评估指标的值,并根据指标的变化来决定是否保存模型权重。
具体解释:ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一组用于自动评估文本摘要和机器翻译结果的评估指标。它衡量生成文本与参考文本之间的重叠程度,常用于评估文本生成任务的质量。
ROUGE指标通常包括ROUGE-1、ROUGE-2和ROUGE-L等变体。ROUGE-1表示单个词的重叠情况,ROUGE-2表示连续两个词的重叠情况,ROUGE-L表示最长公共子序列的重叠情况。这些指标的值范围在0到1之间,值越大表示生成文本与参考文本的重叠程度越高。
当monitor='rouge’时,ModelCheckpoint会计算ROUGE指标并监视其值。根据mode参数的设置,它会在ROUGE指标增大或减小的情况下触发保存模型权重的操作。
例如,如果mode=‘max’,则ModelCheckpoint会在ROUGE指标值增大时保存模型权重。这意味着模型在生成文本任务中的质量越好,ROUGE指标值越大,模型的权重就会被保存。
通过监视ROUGE指标并保存最佳模型权重,可以选择具有更好生成文本质量的模型进行后续的评估、推理或部署。
(5)如何定义多个monitor监控指标变化?
要定义多个监控指标变化,可以将monitor参数设置为一个列表,其中包含要监视的多个指标。
具体解释:例如,假设我们想同时监视准确率(accuracy)和损失函数值(loss),可以按以下方式设置monitor参数:
monitor = [‘accuracy’, ‘loss’]
然后,将monitor参数传递给ModelCheckpoint回调函数,如下所示:
checkpoint_callback = ModelCheckpoint(monitor=monitor, …)
这样,ModelCheckpoint将同时监视这两个指标的值,并根据设置的mode参数来决定是否保存模型权重。
值得注意的是,当使用多个监控指标时,ModelCheckpoint默认将优先考虑第一个指标(即列表中的第一个元素)。它将根据第一个指标的值来判断是否保存模型权重。如果多个指标具有相同的值,它将根据后续指标的顺序进行决策。通过定义多个监控指标,可以更全面地评估模型的性能,并在满足特定条件的情况下保存模型权重。这样可以选择具有多个优秀指标表现的模型进行后续操作。
(6)已经在后续会创建新的model了,为什么还要del model和trainer?
在每个fold的训练完成后,通过del语句删除model和trainer对象的主要目的是释放资源和减少内存占用。
具体解释:训练一个模型需要占用大量的内存资源,特别是当模型很大、训练数据量大或训练过程中使用了复杂的计算图时。在交叉验证中,需要多次训练不同的fold,如果不删除之前的模型和训练器对象,它们会一直占用内存,导致内存消耗过大,可能会导致程序崩溃或性能下降。
通过使用del语句删除模型和训练器对象,可以显式地释放它们占用的内存。这样可以确保每个fold的训练是相互独立的,不会受之前fold的训练过程的影响。同时,也可以减少内存的占用,提高整体的运行效率。
需要注意的是,删除模型和训练器对象后,之前训练的结果和权重将无法再使用。如果需要保留训练的结果,可以将结果保存到磁盘或其他持久化存储中,在之后的操作中再加载和使用。
2. utils.py
(1)导入库
from transformers import BertTokenizer
from functools import partial
import json
import jieba
import torch
import torch.nn.functional as F
import numpy as np
from torch.utils.data import DataLoader, Dataset, Subset
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
import rouge
import re
from transformers import AdamW
import collections
rouge = rouge.Rouge()
smooth = SmoothingFunction().method1
这部分代码导入了所需的库和模块,包括BertTokenizer用于分词,torch用于深度学习框架,以及其他用于数据处理和评估的库。
rouge是用于计算文本摘要评估指标ROUGE的对象,smooth是用于计算BLEU评估指标的平滑函数。
(2)EncoderDecoderData类
EncoderDecoderData类用于处理数据,包括读取文件、编码输入文本、创建数据集和数据加载器等。
1)init初始化方法
def __init__(self, args, tokenizer, ):
# 读取数据文件
self.train_data = self.read_file(args.train_file) if args.train_file else None
self.dev_data = self.read_file(args.dev_file) if args.dev_file else None
self.predict_data = self.read_file(args.predict_file) if args.predict_file else None
# 读取参数
self.args = args
# 读取分词器
self.tokenizer = tokenizer
# 如果需要执行噪声注入。创建一个包含词汇表索引的列表self.vocab_pool,其中排除了特殊标记的索引。这个列表将用于在训练过程中进行噪声注入。
if self.args.noise_prob > 0:
# 通过将词汇表索引列表和特殊标记的索引集合相减,得到一个排除了特殊标记的词汇池。
## 最后,使用list()将词汇池转换回列表类型,并将结果赋值给self.vocab_pool。self.vocab_pool就是一个包含了除特殊标记之外的词汇表索引的列表。
self.vocab_pool = list(set(range(len(tokenizer))) - set(tokenizer.all_special_ids))
这段代码的作用是在构造函数中初始化类的实例变量,包括读取训练、验证和预测数据文件,设置参数和分词器,并在需要时创建词汇表索引列表。这些实例变量将在类的其他方法中使用,用于数据处理和加载的操作。
详解if中代码
首先,使用len(tokenizer)返回了分词器的词汇表大小,再使用range(len(tokenizer))创建一个包含分词器词汇表索引范围的列表。使用set(range(len(tokenizer)))转化为集合,便于操作。
然后,使用tokenizer.all_special_ids获取分词器中的所有特殊标记的索引。这些特殊标记通常用于表示句子的起始、结束、填充等。再使用set(tokenizer.all_special_ids)将特殊标记的索引转换为集合类型,以便进行集合操作。
接下来,通过set(range(len(tokenizer))) - set(tokenizer.all_special_ids)将词汇表索引列表和特殊标记的索引集合相减,得到一个排除了特殊标记的词汇池。
最后,使用list()将词汇池转换回列表类型,并将结果赋值给self.vocab_pool。这样,self.vocab_pool就是一个包含了除特殊标记之外的词汇表索引的列表。
词汇池的作用是在进行噪声注入时,从中随机选择索引,用于替换原始文本中的词汇,从而引入噪声。在训练过程中,可以使用这个词汇池来生成具有噪声的输入样本,以增强模型的鲁棒性和泛化能力。
2)get_predict_dataloader方法
def get_predict_dataloader(self):
# 创建一个名为predict_dataset的KeyDataset对象,将self.predict_data作为参数传递给它。KeyDataset是一个自定义的数据集类,用于存储和处理预测数据。
predict_dataset = KeyDataset(self.predict_data)
# 使用DataLoader类创建一个名为predict_dataloader的数据加载器。
## 该数据加载器使用predict_dataset作为数据集,batch_size=self.args.batch_size * 2设置了批处理的大小,表示每个批次中包含的样本数量。
## self.args.batch_size是一个参数,表示批处理的大小。这里将其乘以2是为了增加批处理的大小,以提高预测的效率。
## collate_fn=self.predict_collate指定了一个用于处理批次数据的函数。self.predict_collate是EncoderDecoderData类中定义的一个方法,用于对预测数据进行编码和处理。
predict_dataloader = DataLoader(predict_dataset,
batch_size=self.args.batch_size * 2,
collate_fn=self.predict_collate)
return predict_dataloader
这段代码的作用是创建一个用于预测的数据加载器。它首先根据预测数据创建一个数据集对象,然后使用数据集对象和相关参数创建一个数据加载器,并指定一个用于处理批次数据的函数。这样,我们可以使用返回的数据加载器来进行预测操作,以方便地处理预测数据。
3)read_file方法
def read_file(self, file):
return [json.loads(x) for x in open(file, encoding='utf-8')]
该方法用于从文件中读取数据,文件路径作为参数传入,返回一个包含文件中数据的列表。
4)encode_src方法
def encode_src(self, src):
# 代码中使用self.tokenizer对源文本进行编码。self.tokenizer是一个分词器对象,用于将文本转换为模型可接受的输入格式。
## src:要进行编码的源文本。padding=True:将编码后的序列进行填充,使其具有相同的长度。
## return_tensors='pt':返回PyTorch张量格式的编码结果。
## max_length=self.args.max_source_length:限制编码序列的最大长度,self.args.max_source_length是一个参数,表示最大长度。
## truncation='longest_first':如果编码序列的长度超过了最大长度,将其进行截断,截断策略是从序列的开头进行截断。
## return_attention_mask=True:返回注意力掩码,用于指示哪些位置是有效输入。
## return_token_type_ids=False:不返回标记类型ID,因为该方法只用于编码源文本。
res = self.tokenizer(src,
padding=True,
return_tensors='pt',
max_length=self.args.max_source_length,
truncation='longest_first',
return_attention_mask=True,
return_token_type_ids=False)
return res
encode_src方法的作用是使用分词器对源文本进行编码,生成模型可接受的输入格式。它将源文本作为参数传递给分词器,并根据指定的参数对文本进行编码和处理。最终,返回编码后的结果。这个方法常用于将文本数据转换为模型可处理的张量格式,以便进行后续的模型推理和处理。
5)train_collate方法
def train_collate(self, batch):
# 检查batch[0]是否是列表类型
if isinstance(batch[0], list):
# 如果batch[0]是列表类型,说明batch是一个嵌套的列表,例如[[sample1], [sample2], ...],则将batch重新赋值为batch[0],即max_token_dataset。
batch = batch[0] # max_token_dataset
# 从batch中提取源文本(src)和目标文本(tgt)
src = [b['src'] for b in batch]
tgt = [b['tgt'] for b in batch]
# 调用self.encode_src(src)对源文本进行编码
src_tokenized = self.encode_src(src)
# 使用self.tokenizer.as_target_tokenizer()切换分词器的模式为目标文本模式,以便对目标文本进行编码。它将当前的分词器转换为适用于目标文本的分词器。这样可以确保源文本和目标文本在分词处理时使用相应的分词器,并保持一致性。
with self.tokenizer.as_target_tokenizer():
# 调用self.tokenizer对目标文本(tgt)进行编码。传递了一系列参数来指定编码的行为,包括最大长度、填充、返回PyTorch张量格式等。
tgt_tokenized = self.tokenizer(
tgt,
max_length=self.args.max_target_length,
padding=True,
return_tensors='pt',
truncation='longest_first')
# 对目标文本的注意力掩码和输入ID进行了处理,将最后一个位置的标记移除,以对齐解码器的输入和输出。
## tgt_tokenized['attention_mask'][:, :-1]:这行代码截取了目标文本(decoder)的注意力掩码。
## tgt_tokenized['attention_mask']是一个二进制序列,用于指示目标文本中哪些位置是真实的输入,哪些位置是填充的。
## 通过[:, :-1],对注意力掩码进行切片操作,将最后一个位置移除。因为在训练过程中,解码器的输入ID和注意力掩码是相对于目标文本进行左移一个位置的,最后一个位置的标记通常是 EOS(结束标记),在解码时不需要输入和生成。
decoder_attention_mask = tgt_tokenized['attention_mask'][:, :-1]
## tgt_tokenized['input_ids'][:, :-1]:这行代码截取了目标文本(decoder)的输入ID。tgt_tokenized['input_ids']是一个整数序列,表示目标文本中每个词对应的索引值。通过[:, :-1],对输入ID进行切片操作,将最后一个位置移除,与注意力掩码的处理方式相同。
decoder_input_ids = tgt_tokenized['input_ids'][:, :-1]
# 生成目标文本的标签,用于模型的训练。为了生成标签(labels),首先克隆目标文本的输入ID(tgt_tokenized['input_ids']),然后使用masked_fill_方法将标签中与分词器的填充标记相对应的位置用-100进行填充。这样可以在训练过程中忽略这些位置的预测。
## tgt_tokenized['input_ids'][:, 1:]:这行代码是获取目标文本的输入ID,并进行切片操作,获取移除目标文本中的起始标记("[START]")的文本。再用clone(),进行一个克隆操作。
labels = tgt_tokenized['input_ids'][:, 1:].clone()
## 使用一个特定的值(-100)来填充在目标文本输入ID中与填充标记(pad token)相对应的位置。self.tokenizer.pad_token_id会生成一个布尔掩码,其中对应的位置为True表示是填充标记,False表示是真实的标记。
labels.masked_fill_(labels == self.tokenizer.pad_token_id, -100)
# 判断是否存在噪声注入的参数
if self.args.noise_prob > 0:
# 创建一个布尔张量noise_indices,其形状与labels相同,并且张量中的每个元素都是从均匀分布 [0, 1) 中随机采样得到的。。该张量的元素以self.args.noise_prob的概率随机取值为True或False。这样可以确定哪些位置将被注入噪声。
noise_indices = torch.rand_like(labels) < self.args.noise_prob
# 使用逻辑与运算符&对noise_indices进行进一步过滤,确保只选择非起始标记、非结束标记的位置,并且这些位置在解码器的注意力掩码(decoder_attention_mask)中是有效的。这样可以避免在序列的开头和结尾以及填充位置注入噪声。
## noise_indices 是一个布尔掩码,表示哪些位置是噪声位置。
## (decoder_input_ids != self.tokenizer.bos_token_id):这个条件用于排除解码器输入序列中起始标记(bos_token_id)所在的位置。解码器输入序列中的起始标记不应该被认为是噪声,因此将对应位置的布尔值设置为 True。
## (labels != self.tokenizer.eos_token_id):这个条件用于排除目标文本序列中结束标记(eos_token_id)所在的位置。目标文本序列中的结束标记不应该被认为是噪声,因此将对应位置的布尔值设置为 True。
## decoder_attention_mask.bool():decoder_attention_mask 是一个注意力掩码,用于指示解码器输入序列中的填充位置。.bool() 的作用是将注意力掩码转换为布尔类型的张量,其中非零元素被视为 True,零元素被视为 False。
noise_indices = noise_indices & (decoder_input_ids != self.tokenizer.bos_token_id) \
& (labels != self.tokenizer.eos_token_id) & decoder_attention_mask.bool()
# 从self.vocab_pool中随机选择与解码器的输入ID(decoder_input_ids)形状相同的噪声输入(noise_inp)。self.vocab_pool是一个词汇池,包含了用于噪声注入的备选词汇。
noise_inp = np.random.choice(self.vocab_pool, decoder_input_ids.shape)
# 使用torch.where函数根据noise_indices的值,在相应位置将噪声输入 noise_inp 插入到解码器的输入序列 decoder_input_ids 的指定位置。如果noise_indices中的元素为True,则在对应位置使用相应的噪声输入noise_inp,为False的,则保持decoder_input_ids解码器的输入ID不变。
decoder_input_ids = torch.where(noise_indices, noise_inp, decoder_input_ids)
# 将处理后的数据组织成一个字典res,其中包含了各个部分的数据,用于作为模型训练的输入。
## 'input_ids': 源文本经过编码后的输入ID。这是一个整数序列,表示将源文本中的每个词转换为对应的索引值。
## 'attention_mask': 源文本的注意力掩码。这是一个二进制序列,与输入ID的长度相同,用于指示哪些位置是真实的输入,哪些位置是填充的。注意力机制可以根据掩码来忽略填充位置的影响。
## 'decoder_input_ids': 解码器的输入ID。这是一个整数序列,表示将目标文本中的每个词转换为对应的索引值,作为解码器的输入。
## 'decoder_attention_mask': 解码器的注意力掩码。这是一个二进制序列,与解码器的输入ID的长度相同,用于指示哪些位置是真实的输入,哪些位置是填充的。
## 'labels': 标签序列。这是一个整数序列,与解码器的输入ID的长度相同,用于指示解码器应该预测的目标文本中的每个词。
res = {'input_ids': src_tokenized['input_ids'],
'attention_mask': src_tokenized['attention_mask'],
'decoder_input_ids': decoder_input_ids,
'decoder_attention_mask': decoder_attention_mask,
'labels': labels}
return res
train_collate方法的作用是对训练数据进行处理和组织,生成模型训练所需的输入。它从批次数据中提取源文本和目标文本,分别对它们进行编码,并根据编码结果生成解码器的输入ID、解码器的注意力掩码和标签。如果设置了噪声注入的参数,还会进行噪声注入的操作。最后,将处理后的结果组织成一个字典并返回。这个方法常用于训练数据的预处理和数据加载过程中。
问题:
(1)为什么要batch是一个嵌套的列表时候,需要batch = batch[0]?
在代码中,batch = batch[0]这一行的作用是处理特殊情况,即当batch是一个嵌套的列表时。
在某些情况下,数据加载器可能会返回一个嵌套的列表作为批次数据。例如,当使用多个数据源或进行数据拆分时,每个批次的数据可能被组织为嵌套的列表,形如[[sample1], [sample2], …]。
为了统一处理这种情况,代码中的batch = batch[0]将嵌套的列表重新赋值为batch[0],即将其展平为一个单层的列表。
这样处理后,batch就变成了一个单层的列表,其中每个元素代表一个样本。后续的代码就可以按照单层列表的形式进行处理,提取源文本和目标文本等信息。
总结起来,batch = batch[0]的作用是将嵌套的列表重新赋值为单层的列表,以便后续的代码能够统一处理批次数据。这样可以确保代码在不同情况下都能正确处理数据,提高代码的灵活性和适用性。
(2)为什么解码器的输入ID和注意力掩码是相对于目标文本进行左移一个位置?
在序列生成任务中,解码器的任务是根据先前生成的标记来预测下一个标记。为了实现这个目标,解码器的输入序列通常会相对于目标文本进行左移一个位置。
这种左移操作的目的是为了将目标文本序列在时间步上错开一个位置,使得解码器在每个时间步都能根据先前生成的标记来预测下一个标记。这种错位操作有助于模型学习到序列的依赖关系和上下文信息。
举个例子,假设目标文本是"Hello, how are you?“,对应的解码器输入序列和解码器输出序列如下:
解码器输入序列(左移一个位置):”[START] Hello, how are you?"
解码器输出序列: “Hello, how are you? [END]”
其中,"[START]“表示序列的起始标记,”[END]"表示序列的结束标记。解码器在每个时间步根据解码器输入序列的上下文信息预测下一个标记,最终生成完整的目标文本。
通过将解码器的输入ID和注意力掩码相对于目标文本进行左移一个位置,可以使解码器能够在每个时间步预测下一个标记,并与目标文本对齐。这样有助于训练模型学习到正确的序列生成方式和上下文依赖关系。
总结起来,解码器的输入ID和注意力掩码相对于目标文本进行左移一个位置是为了使解码器能够根据先前生成的标记预测下一个标记,以正确学习序列生成任务。这种错位操作有助于模型学习到序列的依赖关系和上下文信息。
(3)为什么需要处理目标文本(decoder)的注意力掩码和输入ID的操作?
通过上述操作,目标文本的注意力掩码和输入ID都被截取了最后一个位置,这是为了对齐解码器的输入和输出。在训练过程中,解码器的输入序列会比输出序列提前一个位置,因此需要对目标文本的注意力掩码和输入ID进行相应的处理。
6)dev_collate方法
def dev_collate(self, batch):
return self.train_collate(batch)
调用train_collate对验证集数据进行预处理和数据加载
7)predict_collate方法
def predict_collate(self, batch):
src = [x['src'] for x in batch]
return self.encode_src(src)
调用encode_src对预测数据进行批处理,对输入的批次数据进行编码,并返回编码后的结果。
8)get_dataloader方法
def get_dataloader(self):
# ret是一个字典,用于存储训练集和验证集的数据加载器
ret = {'train': [], 'dev': []}
# 使用训练集数据构建KeyDataset对象
base_dataset = KeyDataset(self.train_data)
# 如果 self.args.kfold 大于 1,表示使用 k-fold 交叉验证方式。
if self.args.kfold > 1:
# 使用 KFold 函数从训练数据中划分出多个训练集和验证集的索引。
from sklearn.model_selection import KFold
for train_idx, dev_idx in KFold(n_splits=self.args.kfold, shuffle=True,
random_state=self.args.seed).split(range(len(self.train_data))):
# 使用 Subset 函数根据索引从 base_dataset 中选择训练集和验证集的子集
train_dataset = Subset(base_dataset, train_idx)
dev_dataset = Subset(base_dataset, dev_idx)
# 使用 DataLoader 类构建训练集和验证集的数据加载器
train_dataloader = DataLoader(train_dataset,
batch_size=self.args.batch_size, # batch_size 参数指定了每个批次的大小
collate_fn=self.train_collate, # collate_fn 参数指定了用于批处理的数据处理函
num_workers=self.args.num_workers, # num_workers 参数指定了用于数据加载的线程数
shuffle=True)
dev_dataloader = DataLoader(dev_dataset,
batch_size=self.args.batch_size * 2,
collate_fn=self.dev_collate)
ret['train'].append(train_dataloader)
ret['dev'].append(dev_dataloader)
else:
# 如果 self.args.kfold 等于 1 且 self.dev_data 为 None,表示不使用交叉验证,而是将训练数据划分为训练集和验证集
if self.args.kfold == 1 and self.dev_data is None:
# train_test_split 函数将训练数据划分为训练集和验证集的索引。
from sklearn.model_selection import train_test_split
train_idx, dev_idx = train_test_split(range(len(self.train_data)),
test_size=0.2,
random_state=self.args.seed)
# 使用 Subset 函数根据索引从 base_dataset 中选择训练集和验证集的子集
train_dataset = Subset(base_dataset, train_idx)
dev_dataset = Subset(base_dataset, dev_idx)
else:
# 如果self.dev_data不为None,则报错
assert self.dev_data is not None, 'When no kfold, dev data must be targeted'
# 对于kfold<1且self.dev_data为None时,将base_data构建为train_dataset、self.dev_data构建为dev_dataset
train_dataset = base_dataset
dev_dataset = KeyDataset(self.dev_data)
# 使用 DataLoader 类构建训练集和验证集的数据加载器,并将它们添加到 ret 字典中
train_dataloader = DataLoader(train_dataset,
batch_size=self.args.batch_size,
collate_fn=self.train_collate,
num_workers=self.args.num_workers, shuffle=True)
dev_dataloader = DataLoader(dev_dataset,
batch_size=self.args.batch_size * 2,
collate_fn=self.dev_collate)
ret['train'].append(train_dataloader)
ret['dev'].append(dev_dataloader)
return ret
根据给定的训练数据、验证数据和交叉验证参数,构建了适用于训练和验证的数据加载器,并将它们存储在一个字典中返回。这样的设计可以方便地在模型训练过程中使用数据加载器进行数据的迭代和批处理操作。
(3)KeyDataset类
# # 继承自 PyTorch 的 Dataset 类。数据集类用于加载和处理训练数据、验证数据或测试数据。
class KeyDataset(Dataset):
def __init__(self, dict_data):
self.data = dict_data
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
KeyDataset 类用于包装和管理字典类型的数据集。它提供了获取数据集长度和根据索引获取样本的方法,以便在训练过程中使用数据加载器进行数据的迭代和批处理操作。通过实例化 KeyDataset 对象,并传入相应的字典数据,可以方便地使用 PyTorch 提供的数据处理工具和函数对数据集进行操作。
Dataset类
Dataset 类是 PyTorch 中用于表示数据集的抽象类。它是一个基类,用于定义自定义数据集类的接口和方法。所有自定义的数据集类都需要继承自 Dataset 类,并实现其中的抽象方法。
Dataset 类的主要作用是提供对数据集进行加载、处理和索引的功能,以便在训练、验证或测试过程中使用。通过使用 Dataset 类,可以将数据集封装为一个可迭代的对象,便于与数据加载器(DataLoader)结合使用,实现数据的批处理和并行加载。
下面是 Dataset 类的一些常用方法:
init(self, …): 类的构造函数,用于初始化数据集对象。可以在这个方法中接受输入参数,并对数据集进行必要的初始化操作。
len(self): 返回数据集的长度,即样本的数量。在这个方法中,需要实现返回整数值的逻辑。
getitem(self, index): 根据给定的索引 index,获取数据集中的一个样本。在这个方法中,需要实现根据索引获取样本的逻辑,并将样本以合适的格式返回。
通过继承 Dataset 类并实现上述方法,可以创建自定义的数据集类,用于加载和处理特定类型的数据。例如,可以创建图像数据集、文本数据集或时间序列数据集等。自定义数据集类可以根据具体的数据格式和处理需求,实现数据的加载、预处理、转换或增强等操作。
使用自定义的数据集类,可以方便地将数据集传递给 DataLoader 对象,进而实现对数据集的批处理、并行加载和数据迭代。
(4)compute_bleu方法
def compute_bleu(label, pred, weights=None):
# weights 是一个可选参数,用于指定 BLEU 评分中不同 n-gram 的权重。如果没有提供 weights 参数,则使用默认的权重 (0.25, 0.25, 0.25, 0.25)。这表示在计算 BLEU 时,会考虑 1-gram、2-gram、3-gram 和 4-gram 的权重都相等。
weights = weights or (0.25, 0.25, 0.25, 0.25)
# 使用np.mean() 函数计算 BLEU 评分列表的平均值,并将结果作为函数的返回值
## 在每个样本对 (a, b) 上执行 BLEU 计算,并将结果汇总为一个列表
## 在每次迭代中,sentence_bleu() 函数用于计算给定参考翻译 a 和预测翻译 b 之间的 BLEU 评分
## 在 sentence_bleu() 函数调用中,references 参数接受一个参考翻译的列表,其中每个参考翻译都被转换为一个词语的列表
## hypothesis 参数接受预测的翻译结果,也被转换为一个词语的列表
## smoothing_function 是一个平滑函数,用于处理 BLEU 计算中可能出现的零频问题
## weights 参数用于指定不同 n-gram 的权重
return np.mean([sentence_bleu(references=[list(a)], hypothesis=list(b), smoothing_function=smooth, weights=weights)
for a, b in zip(label, pred)])
用于计算预测结果的 BLEU(Bilingual Evaluation Understudy)评分,是一种常用的机器翻译评价指标,用于衡量机器生成的翻译结果与人工参考翻译之间的相似程度。
sentence_bleu()函数
sentence_bleu() 是一个用于计算句子级别 BLEU 评分的函数。它是 NLTK(Natural Language Toolkit)库中的一个函数,用于衡量机器生成的句子与参考句子之间的相似度。
sentence_bleu() 函数接受多个参数,用于计算 BLEU 评分。
references 参数是参考句子的列表,其中每个参考句子都被转换为一个词语的列表。参考句子可以有多个,以便与机器生成的句子进行比较。
hypothesis 参数是机器生成的句子,也被转换为一个词语的列表。
smoothing_function 参数是一个平滑函数,用于处理 BLEU 计算中可能出现的零频问题。平滑函数可以选择不同的方法来处理翻译结果中可能缺失的 n-gram。
weights 参数是一个权重列表,用于指定不同 n-gram 的权重。默认情况下,权重是均等的,即每个 n-gram 的权重都相等。
(5)compute_rouge方法
def compute_rouge(label, pred, weights=None):
# weights 是一个可选参数,用于指定 ROUGE 评分中不同部分的权重。如果没有提供 weights 参数,则使用默认的权重 (0.2, 0.4, 0.4)。这表示在计算 ROUGE 时,1-gram 的权重为 0.2,2-gram 的权重为 0.4,Longest Common Subsequence(LCS)的权重为 0.4。
weights = weights or (0.2, 0.4, 0.4)
# 如果 label、pred 是字符串,则将其转换为单个元素的列表。
if isinstance(label, str):
label = [label]
if isinstance(pred, str):
pred = [pred]
# 将 label 和 pred 中的每个元素(句子)转换为以空格分隔的单词字符串
label = [' '.join(x) for x in label]
pred = [' '.join(x) for x in pred]
# 一个内部函数,用于计算单个句子对的 ROUGE 评分
def _compute_rouge(label, pred):
try:
# rouge.get_scores() 函数返回一个包含 ROUGE 评分的字典列表,其中包括 1-gram、2-gram 和 LCS 的 ROUGE 分数。
## hyps 参数接受预测的摘要句子,refs 参数接受参考摘要句子。
scores = rouge.get_scores(hyps=label, refs=pred)[0]
# 使用rouge.get_scores() 提取 ROUGE-1、ROUGE-2 和 ROUGE-L 的 F1 分数,并将它们存储在 scores 列表中。
scores = [scores['rouge-1']['f'], scores['rouge-2']['f'], scores['rouge-l']['f']]
# 在计算 ROUGE 评分时出现异常(例如,当参考摘要为空时),则将 scores 设置为零。
except ValueError:
scores = [0, 0, 0]
return scores
# 在每个句子对 (label, pred) 上调用 _compute_rouge 函数,并将结果汇总为一个列表,再使用np.mean计算所有句子对的 ROUGE 分数列表的平均值
scores = np.mean([_compute_rouge(*x) for x in zip(label, pred)], axis=0)
# 返回一个包含 ROUGE 评分的字典
return {
# 'rouge' 键对应的值是根据权重计算的加权 ROUGE 分数。
'rouge': sum(s * w for s, w in zip(scores, weights)),
# 返回ROUGE-1、ROUGE-2 和 ROUGE-L 的 F1 分数
'rouge-1': scores[0], 'rouge-2': scores[1], 'rouge-l': scores[2]
}
用于计算预测结果的 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评分,一种常用的文本摘要评价指标,用于衡量机器生成的摘要与人工参考摘要之间的相似程度。
(6)ce_loss方法
def ce_loss(logits, labels, is_prob=False, eps=0):
# logits 是一个张量,表示模型的输出。它的形状是 [batch_size, num_classes],其中 batch_size 是批量大小,num_classes 是类别数量。
logits = logits.view(-1, logits.size(-1))
labels = labels.view(-1)
# is_prob 是一个布尔值,默认为 False。如果为 True,则表示 logits 是经过 softmax 函数处理后的概率值;如果为 False,则表示 logits 是未经处理的原始值。
if not is_prob:
loss = F.cross_entropy(logits, labels, label_smoothing=eps)
else:
lprob = (logits + 1e-9).log() # softmax处理
loss = F.nll_loss(lprob, labels)
return loss
这段代码定义了一个名为 ce_loss 的函数,用于计算交叉熵损失(Cross-Entropy Loss)。
(7)kl_loss方法
# logtis 和 logits2 是两个张量,分别表示两个模型的输出。它们的形状是 [batch_size, num_classes],其中 batch_size 是批量大小,num_classes 是类别数量
# mask 是一个张量,用于指示哪些位置需要被掩蔽(mask)。它的形状与 logtis 和 logits2 相同
def kl_loss(logtis, logits2, mask):
# prob1 和 prob2 是将 logtis 和 logits2 经过 softmax 函数处理后得到的概率分布。它们的形状与 logtis 和 logits2 相同
## -1 是一个参数,表示对最后一个维度进行 softmax 操作。在这种情况下,logtis 中的每个样本的概率值将在最后一个维度上进行归一化。
prob1 = F.softmax(logtis, -1)
prob2 = F.softmax(logits2, -1)
# lprob1 和 lprob2 是将 prob1 和 prob2 取对数后得到的对数概率。它们的形状与 logtis 和 logits2 相同
lprob1 = prob1.log()
lprob2 = prob2.log()
# 使用 F.kl_div() 函数计算两个概率分布之间的 KL 散度损失。reduction 参数设置为 'none',表示不进行降维操作,保留每个样本的损失值
## F.kl_div() 函数接受三个参数:input、target 和 reduction。input 是预测的对数概率,target 是目标概率分布。
## lprob1 是预测的对数概率,prob2 是目标概率分布,计算得到 loss1;lprob2 是预测的对数概率,prob1 是目标概率分布,计算得到 loss2
loss1 = F.kl_div(lprob1, prob2, reduction='none')
loss2 = F.kl_div(lprob2, prob1, reduction='none')
# 根据 mask 进行掩蔽操作,将指定位置的损失值置为 0
## mask 中等于 0 的位置转换为布尔类型张量,并增加一个维度,形状变为 [batch_size, num_classes, 1]
mask = (mask == 0).bool().unsqueeze(-1)
# 使用 masked_fill_() 方法将 loss1 和 loss2 中与 mask 中为 True 的位置对应的元素置为 0,使用 sum() 方法对掩蔽后的损失值进行求和
loss1 = loss1.masked_fill_(mask, 0.0).sum()
loss2 = loss2.masked_fill_(mask, 0.0).sum()
loss = (loss1 + loss2) / 2
return loss
这段代码定义了一个名为 kl_loss 的函数,用于计算两个概率分布之间的 KL 散度(Kullback-Leibler Divergence)损失。








![vm虚拟机逆向---[GWCTF 2019]babyvm 复现【详解】](https://img-blog.csdnimg.cn/a894813526af4f0a8574e425a25c9b44.png)

