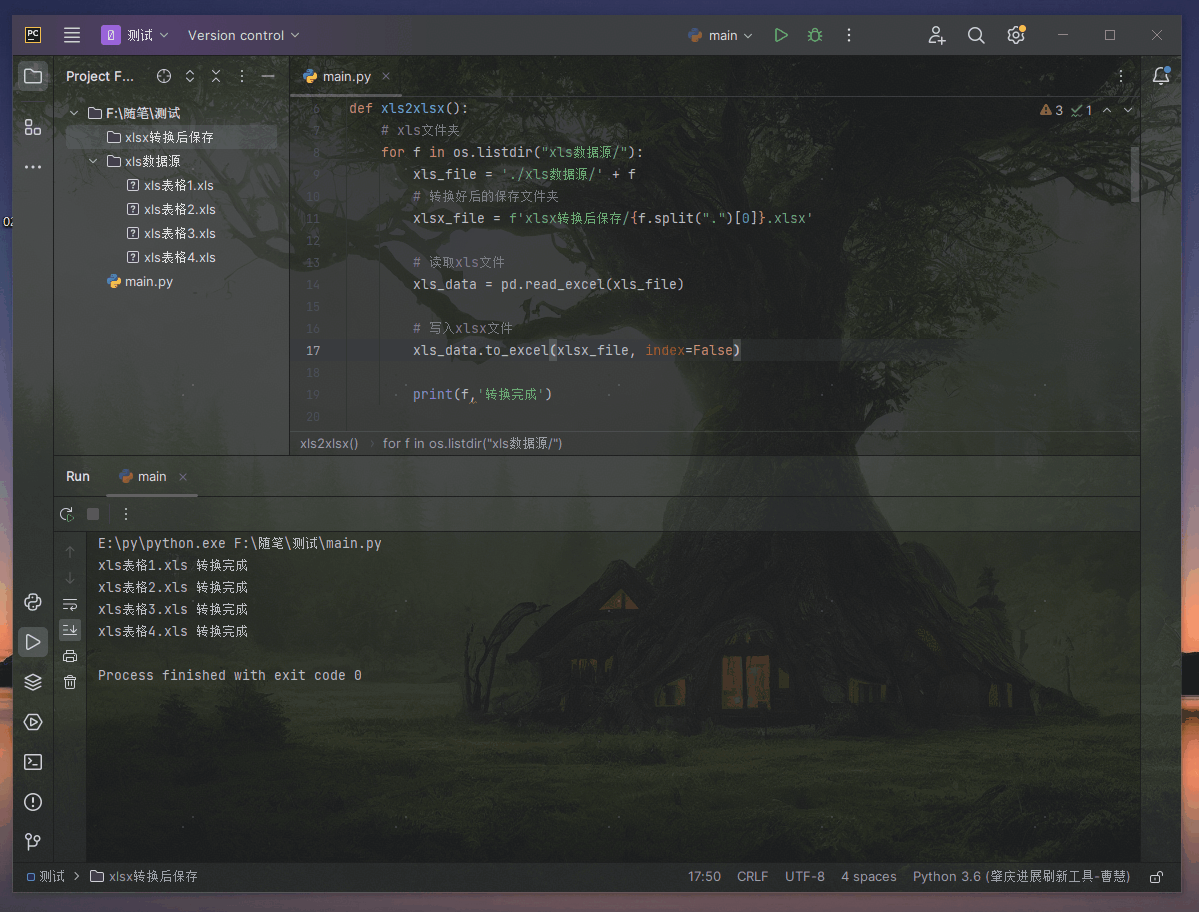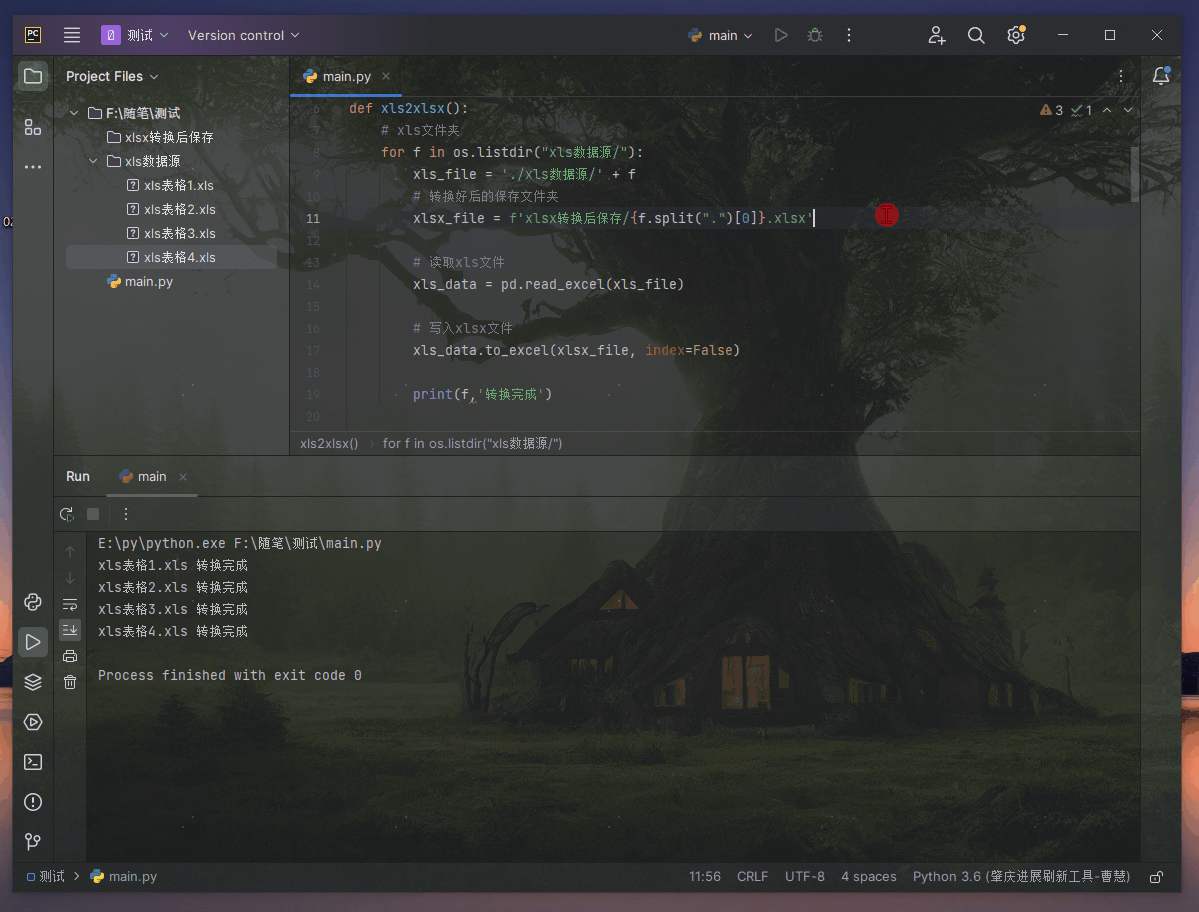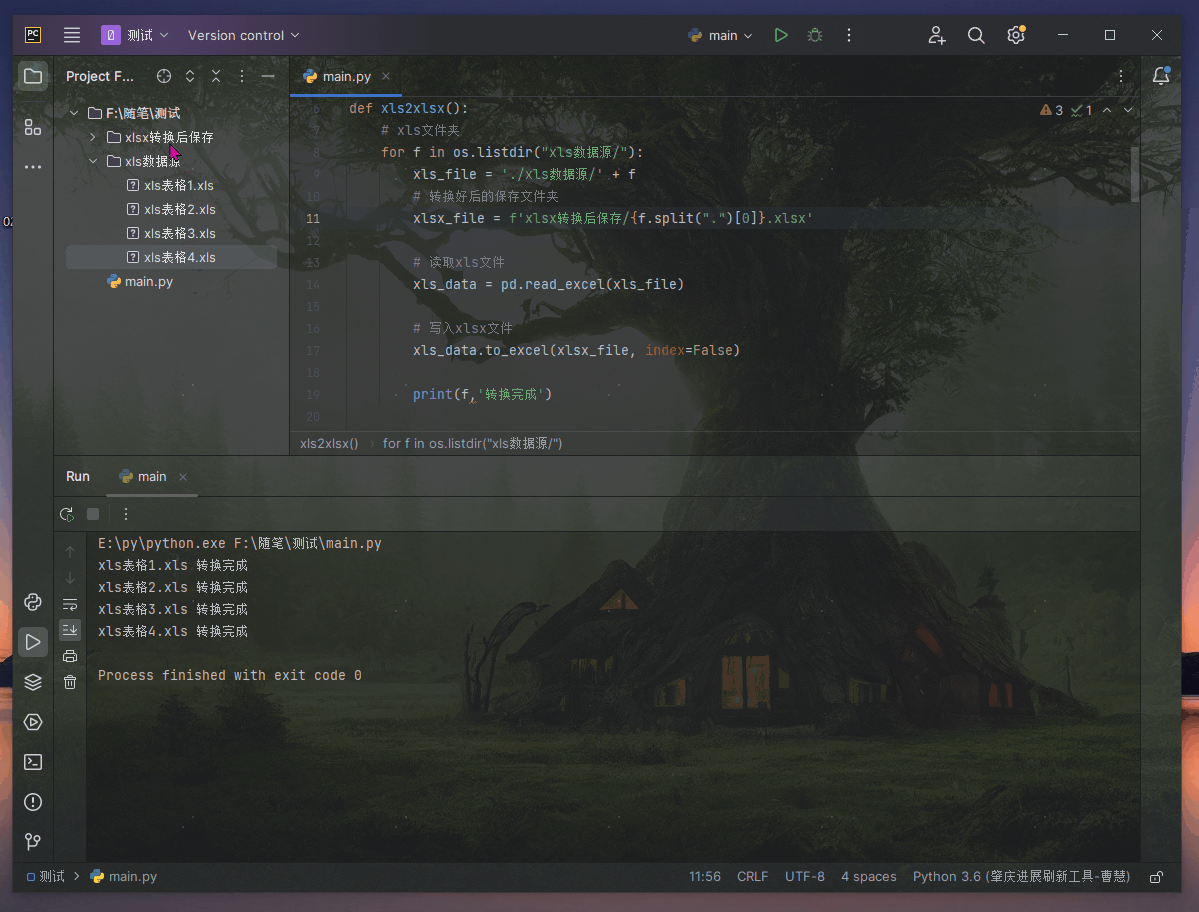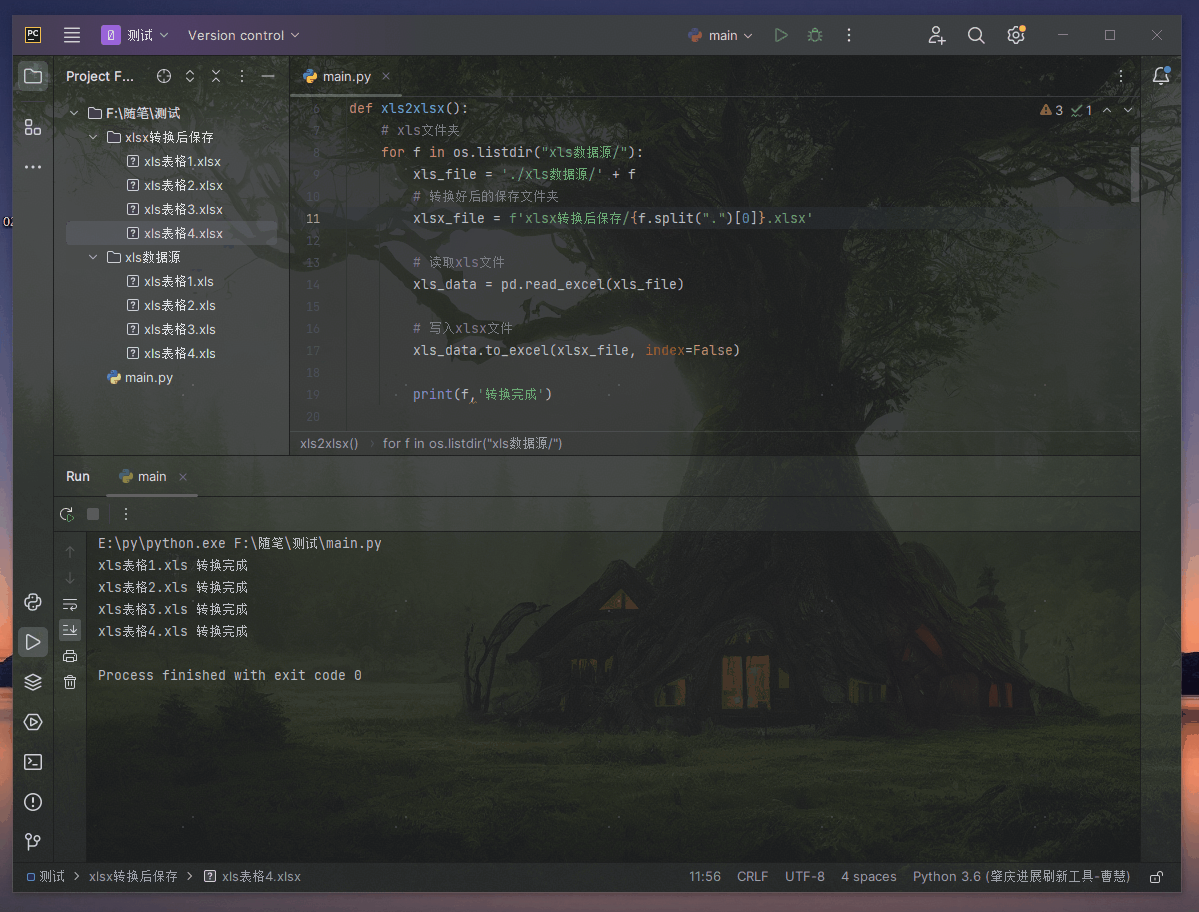
SiamMAE:一种从视频中进行表示学习的孪生掩码自编码器,在视频目标分割、人体姿态跟踪、语义part分割上性能表现出色单位:斯坦福大学(李飞飞、吴佳俊等人), 普林斯顿大学(邓嘉)
在图像或场景之间建立对应关系是计算机视觉中的一项重大挑战,尤其是考虑到遮挡、视点变化和不同的对象外观。 在本文中,我们介绍了Siamese
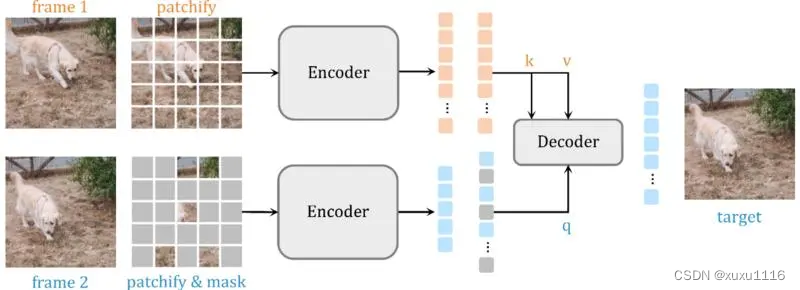
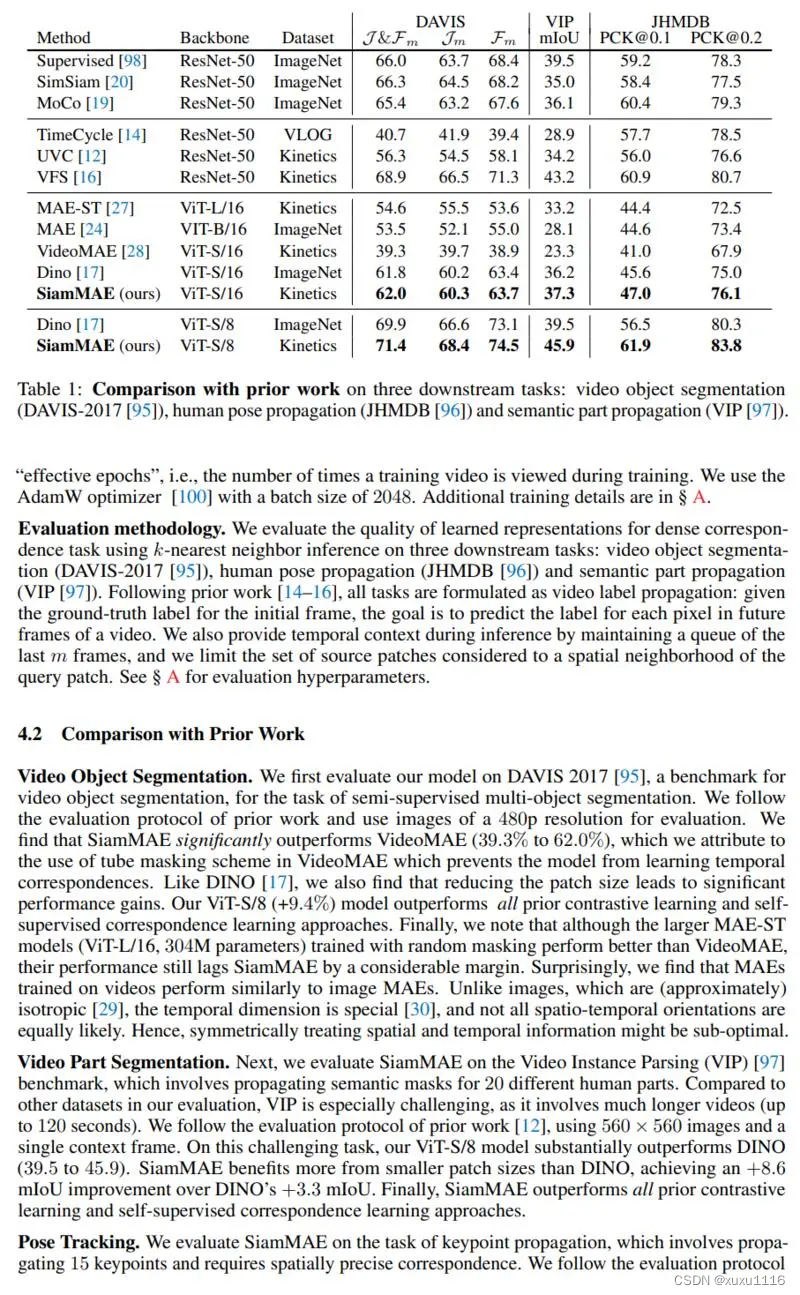
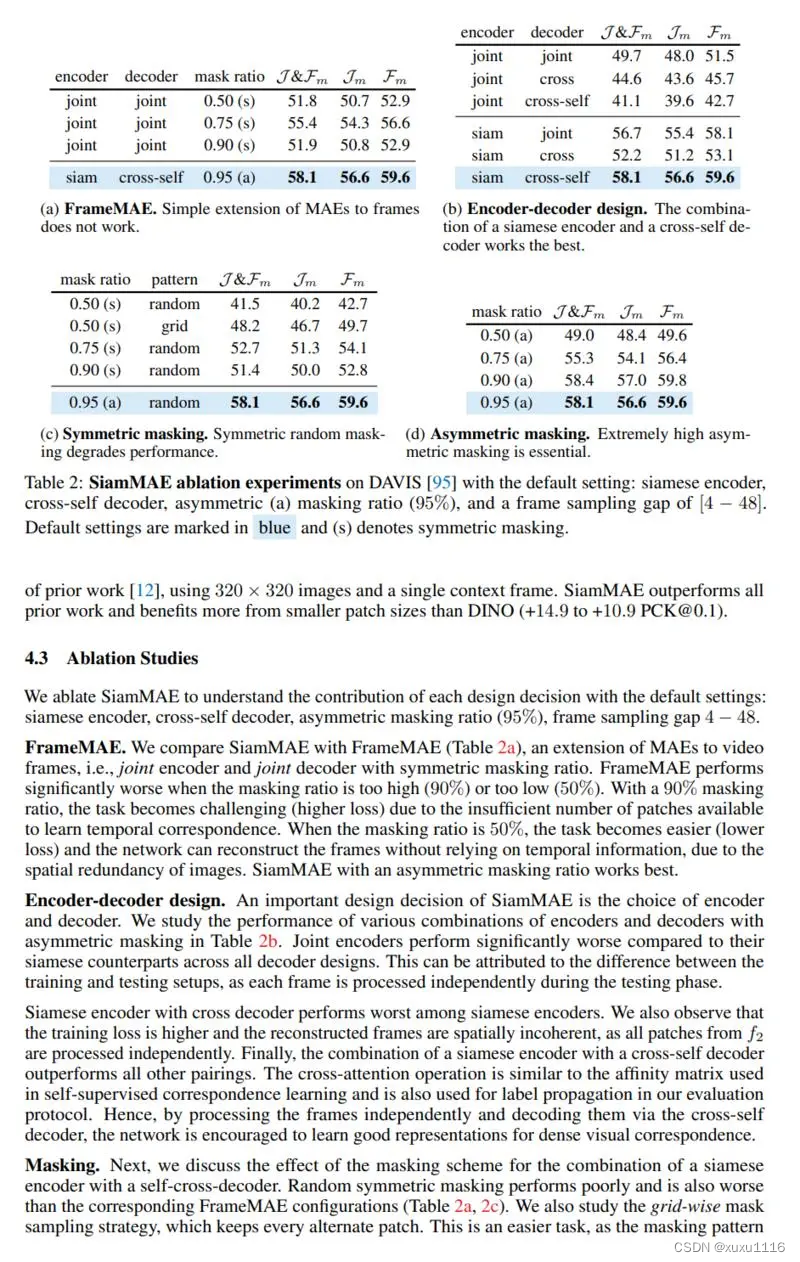
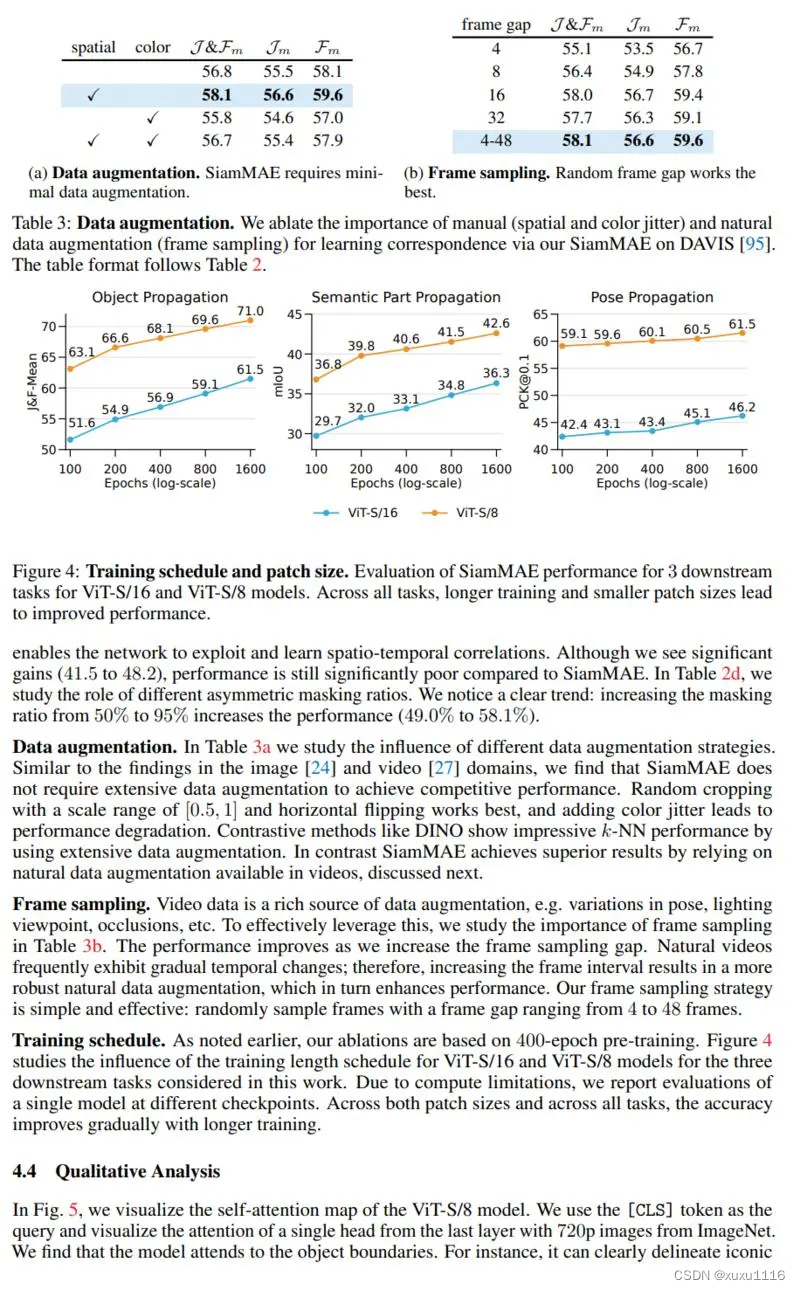
掩码自编码器 (SiamMAE),这是掩码自编码器 (MAE) 的简单扩展,用于从视频中学习视觉对应。 SiamMAE 对随机采样的视频帧对进行操作,并对它们进行不对称屏蔽。 这些帧由编码器网络独立处理,由一系列交叉注意层组成的解码器负责预测未来帧中丢失的补丁。 通过在未来帧中掩码大部分 (95%) 的patch,同时保持过去的帧不变,SiamMAE 鼓励网络专注于对象运动并学习以对象为中心的表示。 尽管概念简单,但通过 SiamMAE 学习的特征在视频目标分割、姿势关键点传播和语义部分传播任务方面优于最先进的自监督方法。 SiamMAE 在不依赖数据增强、基于跟踪的手工任务或其他防止表征崩溃的技术的情况下取得了有竞争力的结果。
主页:https://siam-mae-video.github.io/
demo:https://siam-mae-video.github.io/resources/attn/koala.webm
论文下载链接:https://siam-mae-video.github.io/resources/paper.pdf





更多论文创新点加微信群:Lh1141755859
公众号:CV算法小屋