哈希
前言:大一大二就一直听说哈希哈希,但一直都没有真正的概念:What is 哈希?这篇博客就浅浅聊一下作者认知中的哈希。
理解哈希
哈希(Hash)也可以称作散列,实质就是一种映射,过程是将值作为参数输入到哈希函数中,通过一定的算法得到输出值,输入值和输出值几乎是一一对应的(注意这里的几乎),在这个过程中输入是无限的(任意长度),一样的输入对应一样的输出,不同的输入也有可能对应相同的输出(即哈希碰撞),最终结果具有离散均匀性。
根据以上过程可知哈希具有四个特点:
①输入是无限的
②一样的输入对应一样的输出
③不同的输入也可能一样的输出(哈希碰撞)但概率很小
④离散均匀性
这还是很抽象,接下来就举个栗子吧~~
首先根据经典的哈希,假设两个条件:①无穷的输入域(例如任意长度字符串)②有限的输出域S(即输出的结果肯定在S范围中)
现在假设我有一个函数Function(参数为整数),那么我可以试着输入任意数量任意大小整数都会有一个输出,例如Function(1234567)会有一个输出结果,当我再次调用Function(1234567)时输出结果不变(即函数内部不存在随机数的计算),如果给定参数不同,那么输出结果也有可能相同,原因是S是有限的输出域,而我有无限的输入,有可能导致不同的输入经过哈希函数计算得到相同的结果,一般碰撞概率很小,只有当输入数据极大量时才有可能产生碰撞,接着我用一个大圆来抽象表示输出域,输出结果抽象为一个个小黑点,大量数据输入后,产生的图像如下图所示。

可以看到输出结果分布是非常离散且均匀的,此时若用一个小圆在输出域中采样,采样出的数量也是非常均匀的,like下图。

那么能实现以上四个特点的这样一个Function函数就称为哈希函数,经典的哈希函数模板有 MD5 算法:返回值在0~264-1,SHAL算法:返回值在0~2128-1,java中的哈希函数返回值在0~232-1,哈希函数的具体实现算法先不用管(大牛搞出来的)。
加工
日常使用哈希我们不希望输出域太大,此时我们就需要加工一下来使用,具体加工方法是在最后增加一个过程:即样本经过哈希函数得到的输出再模一个值m得到最终输出结果,如下图。

此时最终的输出结果范围就在0~m-1上,并且结果在0~m-1上也同样均匀分布(很简单推),这样我们就人为缩小了哈希的结果域。
用途
问题:
假设有一个大文件,文件中有40亿个的无符号整数(范围在0~42亿+),若只给1G内存,内存中出现最多次的是哪个数?
题解:
此时就有小朋友想用哈希表做了,HashMap中含有一个key和一个value,我们可以用key代表一个无符号整数,value代表这个无符号整数出现的次数,看起来这样好像能轻松解决这个问题。真的是这样吗?我们可以看到该问题给定的要求是1G内存,而在这题中,key的类型是int(4字节),value类型也考虑为int,那么一个HashMap结构至少占8个字节(不考虑哈希表内部索引空间浪费了,就假定为没有该空间),40亿个HashMap最坏情况(即每个数都不一样)那就是需要占用32G的内存,这远远超出了问题中所给定的要求。
那么这时,我们就可以加工了,直接把每一个结果取余100,就能将32G的文件分割为一百份,由于离散均匀性,我们可以将这一百份小文件看成大小相等的一百份,并且每个种类的key都只会出现在其中一份小文件中,那么每一份小文件就只占用32G / 100的内存,即满足题目要求,此时再分别统计所有小文件中的最大值求出最终结果。
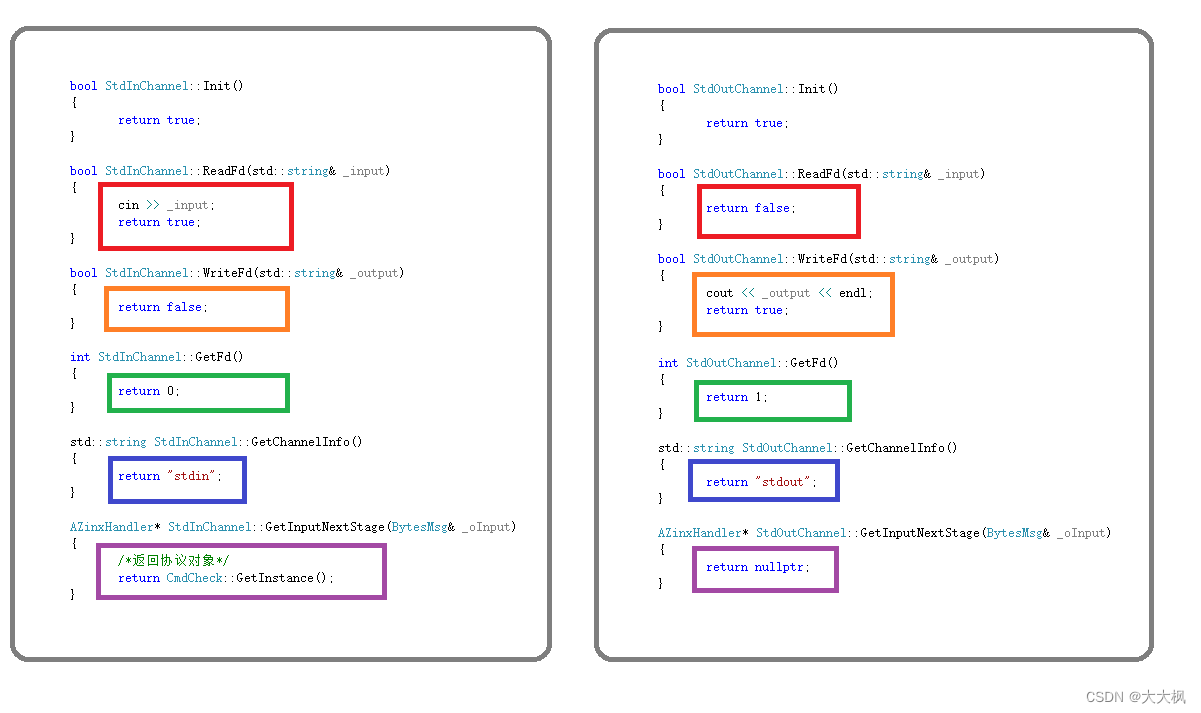
哈希表的实现
哈希表是怎么实现的呢,为什么能做到查询的时间复杂度是O(1),假设有一个大小为18的输出域,输入字符串“abc”、”bcd”、“xyz”,若经过哈希函数计算后取模18得到以下结果,可以发现,当得到相同值时,将他们接成一个链表就行。由于离散均匀性,每一个链的长度几乎是均匀变长的。哈希表查询的时候就是相同流程,计算出结果后去对应的位置遍历链表查询,此时就有一个问题,如果输出域太小,链表长度过长,那么查询的时候就无法做到O(1)的时间复杂度,所以当链表长度达到一个阈值,就触发扩容(扩容规则可以是变为两倍),18扩容为36,那么每个链表长度就变为一半,不过此时就需要把所有值重新计算(将模18改为用模36计算)放入输出域。

说完实现原理,再说说增删查改时间复杂度O(1)到底是怎么来的?输入的值经过哈希函数计算这个过程时间复杂度是O(1),得到的值再进行模运算时间复杂度同样是O(1),假设链表长度是k,遍历链表的时间复杂度就是O(k),当我们让k的大小始终很小时,就能看作O(1),所以扩容就是为了保证时间复杂度维持在O(1)。
接下来看看扩容的代价,假设有1000个字符串要加进去,设一开始哈希表格子大小为2,每次扩容容量乘2,那么需要经历log1000次扩容,所以扩容的次数理论来说是O(logkN),k为初始容量大小,N为要加入的内容大小,但实际情况远远小于logN,而每次重新计算哈希值的代价是O(N),因为每个值扩容后都要重新计算,故总的扩容代价是O(N*logN),那么单次代价即为O(logN)水平,当我将k的值稍微设计大一些,此时O(logN)就会变成一个特别小的代价值,实际情况N并不会过大,而且哈希表有增有删,删的情况还会减小扩容次数,故O(logN)可以逼近O(1)。Java等一些虚拟机语言还有离线扩容技术,可以不占用用户在线时间进行扩容,进一步加速了哈希表的使用,所以哈希表在实际使用是O(1),理论上是O(logN)。
以上就是哈希表的原理,具体的实现改进还有很多,比如开放地址法等等,这里就不过多赘述。
Tips:java中的HashMap、HashSet就是用哈希原理实现的哈希表,HashMap就只是比HashSet多了一个伴随的value值,原理是相同的,算法时间复杂度为O(1);TreeMap和TreeSet即 java 中利用搜索树实现的 Map 和 Set,实际上用的是红黑树,而红黑树是一棵近似平衡的 二叉搜索树,算法时间复杂度为O(logN)。
布隆过滤器
布隆过滤器是来解决类似黑名单系统、爬虫去重问题的
比如一个网站的黑名单url有100亿个,每个url大小限制为64Byte。需要做到给定一个url,判断该url是否出现在黑名单中,且这个黑名单只有增加和查询的需求,没有删除需求。
如果直接使用HashSet,那么占用空间大概是640G,十分浪费空间,或者搞成硬盘来记录url值,但这样慢的一p,所以咱们还是用内存来实现。
布隆过滤器允许一定的失误率,即有些不位于黑名单的url可能会被判定为在黑名单中(白 -> 黑),但不会出现原本位于黑名单中的url判定为不在黑名单中(黑 -> 白),而且通过人为的设计,可以让失误率很低,让工程上可以接受,例如爬网页,有些网页被杀掉了,没拿到信息,但在其他网页同样能得到信息。
那这么好用的布隆过滤器咋实现?
我们先来看看位图:
位图:一个数组,每个元素所占空间为1bit(bitarr bitmap)
假设我们想操作第178位,具体实现如下:
实现:使用基础类型拼凑
public class BitMap {
public static void main(String[] args) {
int a = 0;
int[] arr = new int[10]; //32bit * 10 -> 320bits
//arr[0] 0 ~ 31
//arr[1] 32 ~ 63
int i = 178; //想取第178位bit
int numIndex = i / 32;
int bitIndex = i % 32;
//拿到第178位的状态
int s = (arr[numIndex] >> bitIndex) & 1;
//把第178位的状态改为1
arr[numIndex] = arr[numIndex] | (1 << bitIndex);
//把第178位的状态改为0
arr[numIndex] = arr[numIndex] & (~(1 << bitIndex));
}
}
布隆过滤器就是一个大位图,长度为m的bitarr(实际占用空间为m / 8字节)
加入黑名单的步骤:对于每一个url来说,用k个不同的哈希函数算出k个哈希值out,然后将每一个out模m,得到对应于位图中的位置,将该位置设置为1,可以想象成将这些位置描黑,而取k个哈希函数相当于取k个特征,特征越多就越精确,就像一张图片你需要多取一些特征点才能归类为猫而不是归类为动物,从而使结果更精准。
查询黑名单的步骤:对于某一个url来说,算出k个哈希值,然后模m算出对应于位图中的位置,只有这些位置全是1(也就是都被描黑了),这个url才处于黑名单中,只要有一个位置不是1,就代表其不在黑名单中
决定失误率p的因素:位图大小m和哈希函数个数k。n(样本量)假定为100亿,若m越大,p则会越小(类似于反比例函数);当m由p-m图像确定后,k较小时,随着k的增加,p会下降,但到达某一个临界(与m有关)时,随着k的增加,p会上升(类似于二次函数),因为k逼近m,空间占用率太大了。

————————————————p(失误率)与m(位图大小)的关系图————————————————

————————————————p(失误率)与k(哈希函数个数)的关系图————————————————
布隆过滤器只和样本量n、失误率p这两个参数有关,与单样本大小无关(例如url大小),因为最后会被转化为哈希值,只要保证哈希函数能接受这个数值即可。
三个相关的公式:
m
=
−
n
∗
l
n
p
(
l
n
2
)
2
b
i
t
(
向上取整
)
k
=
l
n
2
∗
m
n
≈
0.7
∗
m
n
个
(
向上取整
)
p
真
=
(
1
−
e
−
n
∗
k
真
m
真
)
k
真
m=-\frac{n*lnp}{(ln2)^2}\quad bit(向上取整)\\ k=ln2*\frac{m}{n}≈0.7*\frac{m}{n}\quad 个(向上取整)\\ p_真=(1-e^{-\frac{n*k_真}{m_真}})^{k_真}
m=−(ln2)2n∗lnpbit(向上取整)k=ln2∗nm≈0.7∗nm个(向上取整)p真=(1−e−m真n∗k真)k真
当类似于黑名单这个集合结构系统,不需要删除行为,允许有一定失误率,那么就需要设计布隆过滤器,设计布隆过滤器只需要以上三个公式。
已经有的条件:
①样本量n
②失误率p
对于上述黑名单示例,经计算后m的大小理论值大概是26G(原本需要640G),极大地减小了内存的占用,实际使用可以多申请一点比如申请32G内存,实际失误率会更小,计算就是第三个公式。
一致性哈希(Google改变世界技术三架马车之一)
一致性哈希原理:
一致性哈希是用来讨论分布式数据服务器(多台机器)怎么组织的问题
经典组织方式:假设有3台服务器,那么就先将数据转化为哈希值,再模3,分配到对应的服务器上,可以做到数据种类的均匀分配
负载均衡是由高频、中频、低频各自是否达到一定的数量来决定,此时由哈希函数是可以将这些数据均分的(根据离散均匀性,此时哈希函数需要选择种类较多的key,比如人名、身份证,而不适于选择类似于国家名的key)
经典结构的问题:若增加机器或减少机器,所有数据都需要重新计算哈希值,因此数据迁移的代价是全量的(比如原本模3,加了一个机器之后,就需要将全部数据模4重新计算分配,所以像MySQL这种一台机器的就搞不了,太慢了)
**一致性哈希的处理方式:**将哈希值的域比作一个环,先使用一个特定于服务器的哈希函数为每个服务器计算一个哈希值,将这些机器插入到这个环中。此时数据分配的方式是,这个数据所计算出的哈希值在环上顺时针方向最近的机器。实现方式是通过二分的方式查找大于等于当前哈希值中最近的机器,若没有比当前哈希值大的机器,则代表是最小的那个机器(因为是环)逻辑图如下。

在一致性哈希下,若新增或删减了服务器,则只需要迁移部分的数据即可完成数据的迁移,因为此时只用考虑增加或删减的那台机器与邻近机器的那一段数据。
例如下图,新增一个结点五,只需要把结点四到结点五之间的数据从节点一要回给结点五即可。

一致性哈希的问题:
① 当机器较少时,可能做不到这些机器将环均分
② 即使可以做到机器数量较少时将环均分,也无法保证增加或减少机器后负载均衡
解决方式:虚拟结点技术
虚拟结点技术本质上是按比例去抢环。假设有3台机器,则给这3台机器每个分配1000个字符串,此时不再让机器去占环上的位置,而让虚拟结点去占,即每台机器计算1000个哈希值,让这1000个哈希值占环上。此时这些虚拟结点之间的数据迁移可以用很简单的方式实现。当增加服务器时,则同理给这台服务器添加1000个虚拟结点,由于哈希分配均匀,因此它会均匀地从前3台机器中夺取数据到自己身上。减少机器也同理,减少机器时,自己的数据会均匀地分配到其他机器上。
一致性哈希还可以管理负载。例如若某台机器比较强,则可以分配更多的虚拟结点,而某台机器较弱,则可分配较少的虚拟结点。
以上就是关于作者对哈希的学习和理解,真的很想描述清楚分享给大家,能力有限,觉得写的不好不要见怪,有问题或错误欢迎评论区指出。