文章目录
- 内存模型与原子操作
- 内存模型
- 原子操作和原子类型
- 标准原子类型
- std::atomic_flag
- std::atomic\<bool>
- std::atomic<T\*>
- std::atomic<user_define_type> 类模板
- 非成员函数
- 同步操作和强制排序
- 同步发生与先行发生
- 内存序
- **顺序一致性**(memory_order_seq_cst)
- **自由序**(relax)
- **获取-释放序**(memory_order_acquire memory_order_release)
- **获取-释放序传递同步**(memory_order_acq_rel)
- **获取-释放序和memory_order_consume的数据依赖**
- 释放序与同行操作
- 栅栏
- 原子操作对非原子的操作排序
内存模型与原子操作
内存模型
无论是怎么样的类型,都会存储在一个或多个内存位置上。虽然相邻位域中是不同的对象,但仍视其为相同的内存位置。
struct s1{
int i: 8;
int j: 4;
int a: 3;//8+4+3=15位<sizeof(int)即8字节(相同位域不同对象)
double b;//8字节
};//8+8=16字节
struct s2{
int i: 8;
int j: 4;//8+4=12位<sizeof(int)即8字节(相同位域不同对象)
double b;//8字节
int a:3;//3位<sizeof(int)即8字节
};//8+8+8=24字节
四个需要牢记的原则:
- 每个变量都是对象,包括其成员变量的对象。
- 每个对象至少占有一个内存位置。
- 基本类型都有确定的内存位置(无论类型大小如何,即使他们是相邻的或是数组的一部分)。
- 相邻位域是相同内存中的一部分。
为了避免条件竞争,线程就要以一定的顺序执行。
- 第一种方式:互斥量确定了线程访问的顺序,避免未定义行为的发生。
- 另一种方式:原子操作未指定线程访问顺序,但拉回定义行为的区间。
在初始化开始阶段,线程对象确定好修改的顺序。大多数情况下,这个顺序不同于执行中的顺序,但在给定的程序中,所有线程都需要遵守这个顺序。
- 非原子类型需要使用同步操作,使线程遵守修改顺序。
- 而原子操作,编译器有责任去做同步。
所有线程都要遵守程序中每个独立对象的修改顺序,但没有必要遵守在独立对象上的操作顺序。
原子操作和原子类型
原子操作:不可再分割的操作(当然自然科学中有夸克,但是只是个名称不抬杠)。如果读取操作对象是原子操作,其它操作也是原子的。
标准原子类型
定义在头文件<atomic>中。语言中将文件中的类型定义为原子的,也能用互斥锁模拟原子操作。
大部分原子类型可通过特化std::atomic<>得到,几乎都有成员函数is_lock_free():
- 如果原子操作是直接用原子CPU指令实现无锁,返回true;
- 是内部使用锁结构,返回false。(内部没有互斥量的实现,才能有性能提升)
注:除std::atomic_flag不提供is_lock_free(),为简单布尔标志必然无锁。可以此为基础实现简单锁,进而实现其他基础原子类型。
C++17中有static constexpr bool is_always_lock_free;,返回true硬件上是无锁类型。
标准库提供了一组宏(对应于内置原子类型),编译时对各种整型原子操作是否无锁进行判别(有锁,其值为0;无锁,其值为2;无所状态运行时才能决定,其值为1):
-
ATOMIC_BOOL_LOCK_FREE
-
ATOMIC_CHAR_LOCK_FREE
-
ATOMIC_CHAR16_T_LOCK_FREE
-
ATOMIC_CHAR32_T_LOCK_FREE
-
ATOMIC_WCHAR_T_LOCK_FREE
-
ATOMIC_SHORT_LOCK_FREE
-
ATOMIC_INT_LOCK_FREE
-
ATOMIC_LONG_LOCK_FREE
-
ATOMIC_LLONG_LOCK_FREE
-
ATOMIC_POINTER_LOCK_FREE
内置原子类型备选名于其相关的std::stomic<>特化(避免两种混用):
| 原子类型 | 相关特化类 |
|---|---|
| atomic_bool | std::atomic |
| atomic_char | std::atomic |
| atomic_schar | std::atomic |
| atomic_uchar | std::atomic |
| atomic_int | std::atomic |
| atomic_short | std::atomic |
| atomic_long | std::atomic |
| atomic_llong | std::atomic |
| atomic_char16_t | std::atomic<char16_t> |
| atomic_char32_t | std::atomic<char32_t> |
| atomic_wchar_t | std::atomic<wchar_t> |
标准原子类型定义和对应的内置类型定义:
| 原子类型定义 | 标准库中相关类型定义 |
|---|---|
| atomic_int_least8_t | int_least8_t |
| atomic_int_least16_t | int_least16_t |
| atomic_int_least32_t | int_least32_t |
| atomic_int_least64_t | int_least64_t |
| atomic_int_fast8_t | int_fast8_t |
| atomic_int_fast16_t | int_fast16_t |
| atomic_int_fast32_t | int_fast32_t |
| atomic_int_fast64_t | int_fast64_t |
| atomic_intptr_t | intptr_t |
| atomic_size_t | size_t |
| atomic_ptrdiff_t | ptrdiff_t |
| atomic_intmax_t | intmax_t |
注:原类型名前加上atomic_;signed写为s;unsigned写为u;long long写为ll。
原子类型没有传统意义上的拷贝构造函数和拷贝赋值操作符(返回atomic&),但可隐式转化成对应内置类型(支持赋值)。赋值操作返回atomic而非atomic&;命名函数返回操作值。
//构造函数
atomic() noexcept = default;
constexpr atomic( T desired ) noexcept;
atomic( const atomic& ) = delete;//删除
//赋值
T operator=( T desired ) noexcept;
T operator=( T desired ) volatile noexcept;
atomic& operator=( const atomic& ) = delete;//删除
atomic& operator=( const atomic& ) volatile = delete;//删除
//std::atomic通过coyping函数实例化必须使用T类型而非T&,如果不满足以下值为false
std::is_trivially_copyable<T>::value
std::is_copy_constructible<T>::value
std::is_move_constructible<T>::value
std::is_copy_assignable<T>::value
std::is_move_assignable<T>::value
每个原子类型及其所能使用的操作:
| 成员函数 | atomic_flag | atomic<bool> | atomic<T*> | atomic<内置类型> | atomic<其他类型> |
|---|---|---|---|---|---|
| test_and_set | Y | ||||
| clear | Y | ||||
| is_lock_free | Y | Y | Y | Y | |
| load | Y | Y | Y | Y | |
| store | Y | Y | Y | Y | |
| exchange | Y | Y | Y | Y | |
| compare_exchange_weak, compare_exchange_strong | Y | Y | Y | Y | |
| fetch_add, += | Y | Y | |||
| fetch_sub, -= | Y | Y | |||
| fetch_or, |= | Y | ||||
| fetch_and, &= | Y | ||||
| fetch_xor, ^= | Y | ||||
| ++, – | Y | Y |
没有除法、乘法及移位操作,但可以使用compare_exchange_weak()完成。
函数原子化操作,并且返回旧值;符合赋值运算会返回新值;前缀/后缀加减与普通用法一致。
另外两种exchange成员函数及其重载(success与failure选择不同的内存序或选择相同的内存序):
bool compare_exchange_weak( T& expected, T desired, std::memory_order success, std::memory_order failure ) noexcept;
bool compare_exchange_weak( T& expected, T desired, std::memory_order order = std::memory_order_seq_cst ) noexcept;
bool compare_exchange_strong( T& expected, T desired, std::memory_order success, std::memory_order failure ) noexcept;
bool compare_exchange_strong( T& expected, T desired, std::memory_order order = std::memory_order_seq_cst ) noexcept;
-
原子变量this值==期望值(expected)时,将修改this值为设定值(desired),返回true;
-
原子变量this值!= 期望值(expected)时,期望值(expected)修改为this值,返回false。
情况一也可能返回false,在缺少单条CAS操作(“比较-交换”指令)机器上,不能保证操作是原子的(可能被其他线程切换),这被称为“伪失败”(spurious failure)。常配合循环使用:
bool expected=false; extern atomic<bool> b; // 设置些什么 while(!b.compare_exchange_weak(expected,true) && !expected);如果CAS操作很耗时,当期望值不变时,使用
compare_exchange_strong()可以避免对值的重复计算。
每种函数类型的操作都有一个内存序参数,指定存储顺序。可大致分为三类:
- Store(存储)操作,可选如下内存序:
memory_order_relaxed,memory_order_release,memory_order_seq_cst。 - Load(读取)操作,可选如下内存序:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_seq_cst。 - Read-modify-write(读-改-写)操作,可选如下内存序:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst。(修改寄存器的值时,会使用三步指令改写值,第一步读取寄存器的值,第二步修改读出的值,第三步写回寄存器)
std::atomic_flag
最简单类型,只能在设置与清除两个状态切换,功能有限。
atomic_flag只能被ATOMIC_FLAG_INIT进行初始化,由于是静态存储,无初始化顺序问题。只能做销毁、清除或设置三件事对应于clear()成员函数和test_and_set()成员函数。
std::atomic_flag f = ATOMIC_FLAG_INIT;//标志位总是初始化为“清除”
f.clear(std::memory_order_release);
bool x=f.test_and_set(); // 读改写能应用任何语义
实现自旋锁(经足够std::lock_guard<>使用):
class spinlock_mutex{
std::atomic_flag flag;
public:
spinlock_mutex():flag(ATOMIC_FLAG_INIT){}
void lock(){while(flag.test_and_set(std::memory_order_acquire));}
void unlock(){flag.clear(std::memory_order_release);}
};
std::atomic<bool>
与std::atomic_flag相比,可用非原子bool类型进行构造初始化。
- 不同于通常的操作:它返回一 个bool值来代替指定对象。
- 另一种模式:通过返回值完成赋值。如果返回
atomic&,使用该值的代码都要显式加载,但这可能会被其他线程修改。
std::atomic<bool>可能不是无锁的。为保证操作的原子性,其实现中可能要内置的互斥量。
std::atomic<T*>
可以通过合适的类型指针进行构造和赋值。其成员函数获取与返回的类型都是T*,而非是std::atomic<T*>。
有fetch_add()和fetch_sub()函数,将原子类型的地址偏移若干位地址,但函数返回值仍然指向第一个元素的地址(旧值)。这种操作也被称为“交换-相加”,并且这是一个原子的“读-改-写”操作,如同三种exchange()。
std::atomic<user_define_type> 类模板
为使用std::atomic<user_define_type>,需满足一定标准(数据不以引用或指针传递):
- 必须使用编译器创建的拷贝赋值操作(编译器使用
memcpy()按位复制或赋值等价操作)。 - 所有的基类和非静态数据成员也都需要支持拷贝赋值操作。
- 比较-交换操作操作就类似于
memcmp()使用位比较,而非为类定义一个比较操作符。
通常,编译器生成的代码会使用内部锁,因此有死锁的风险。也可让编译器将用户定义类型当作为一组原始字节,这样可对std::atomic<user_define_type>直接使用原子指令(无锁)。
std::atomic<user_define_type>在使用compare_exchange_strong函数的过程中(比较操作与memcmp不同),可能因为两个值的表达方式不同而失败(如float与double)。
由于平台不同,有些平台支持user_define_type≤一个int或void*类型时,std::atomic<>使用原子指令;有些平台支持user_define_type≤两个int或void*类型时,std::atomic<>使用原子指令,即“双字节比较和交换”(double-word-compare-and-swap,DWCAS)指令。
不能使用包含有计 数器,标志指针和简单数组的类型,作为特化类型。虽然这不会导致任何问题,但是越是复杂的数据结构, 就有越多的操作,而非只有赋值和比较。如果这种情况发生了,最好使用std::mutex保护数据。
非成员函数
需要atomic_为前缀,指定内存序时会分成两种:一种无标签,另一种以_explicit为后缀。
成员函数隐式引用原子对象,所有非成员函数都持有一指向原子对象的指针(作为第一个参数)。
非成员函数的设计是为了与C语言兼容(没有引用)。
C++标准库也对原子类型中的 std::shared_ptr<> 智能指针类型提供非成员函数。可使用的原子操作有:load, store, exchange和compare/exchange,通过重载函数std::shared_ptr<>*
可作为第一个参数。 std::experimental::atomic_shared_ptr支持无锁实现,同样可用函数is_lock_free确定是否无锁。
同步操作和强制排序
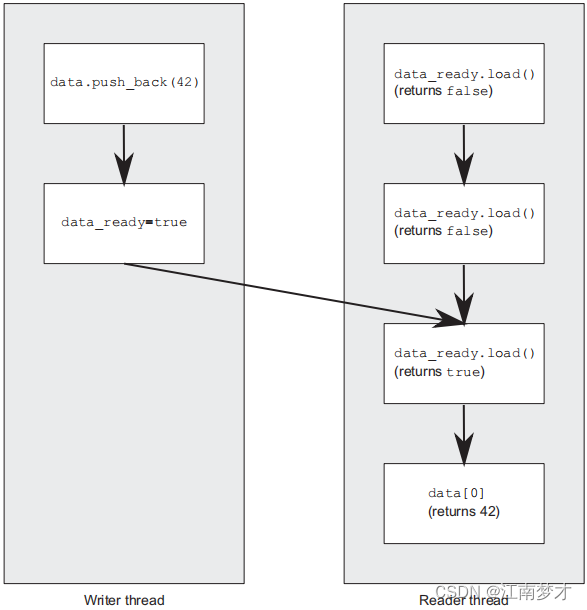
C++中一句语句可能会有多个步骤(理解为机器语),在并行中可能导致步骤的混乱或编译器重排语句。可使用锁或是使用原子操作+内存序。
#include <vector>
#include <atomic>
#include <iostream>
std::vector<int> data;
std::atomic<bool> data_ready(false);
void reader_thread(){
while(!data_ready.load()){ // 1
std::this_thread::sleep(std::milliseconds(1));
}
std::cout<<"The answer="<<data[0]<<"\m"; // 2
}
void writer_thread(){
data.push_back(42); // 3
data_ready=true; // 4
}
访问顺序通过对std::atomic<bool>类型的data_ready变量进行操作完成,这些操作是通过***先行(happens-before)和同发(synchronizes-with)***确定顺序:
- 3先行于4;
- 1读取4的输入(写入与读取同发),因此3和4先行于1;
- 1先行于2。
**线程间先行(inter-thread-happens-before)依赖与同发(synchronizes-with)**即1与4的关系;
线程间先行可以与**语句排序(sequenced-before relation)**相结合即1与2,3与4的先后关系。
因此在单线程时,对数据进行一次修改,只要一次同步即可。
这可得出:对于原子操作,默认写入操作要在读取操作之前。当然还有其他顺序。
同步发生与先行发生
同发(synchronizes-with)是在原子类型之间进行的操作。如果线程A存储了一个值,并且线程B不断读取了这个值,直到读取的值合适,那线程A的操作与线程B的操作就是同步发生关系。
**先行(happens-before)与强先行(strongly-happens-before)**是程序中操作排序的基本构件,指定了某个操作去影响另一个操作。
- 在单一声明(一条语句)中不可能排序,所以无法先行安排顺序(也就没有先行发生)。
- 线程A中的原子操作与线程B中的原子操作同发,A是线程间先行于B,这种先行关系可在线程间传递。也可进一步与代码语句的顺序相结合。
- 强先行与先行的不同处在于
memory_order_consume可用于线程间先行但不用于强先行。由于大多数代码并不适用memory_order_consume内存序,因此这种区别在实际中可能不会表现的很明显。
内存序
用于控制变量在不同线程见的顺序可见性问题,共六种:
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst//默认内存序列
} memory_order;
代表了三种内存模型:
- 顺序一致性(memory_order_seq_cst)
- 获取-释放序(memory_order_consume, memory_order_acquire, memory_order_release和memory_order_acq_rel)
- 自由序(memory_order_relaxed)
不同的内存序在不同的CPU架构下时间成本不同,允许使用不同内存序提升相关操作的性能。
顺序一致性(memory_order_seq_cst)
因为程序中的行为从任意角度去看,语句都保持一定顺序。如果原子实例的所有操作都是顺序一致的,那么多线程就会由单线程以某种特殊的顺序执行。可写出所有可能的操作序列并验证消除不一致的操作序列,但这种操作较难操作重排;重排时其他线程也要看到。
对同一变量的存储操作与读取操作是同发的。这对两个及以上线程的语句排序提供了限制,但是顺序一致性(sequentially consistent)的限制比语句排序还要大。因此所有使用顺序一致性的原子操作,都要储存后再加载。这种限制不会作用到使用自由序(memory_order_relaxed)原子操作的线程,仍可用看到原子操作有不同的语句顺序,为了保证同步最好都使用顺序一致性。
在多核处理器使用这种语序,同步操作的代价较大,因为处理器间的所有操作,需要保证一致。
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x(){ x.store(true,std::memory_order_seq_cst); } // 1
void write_y(){ y.store(true,std::memory_order_seq_cst); } // 2
void read_x_then_y(){//y返回false,因存储x=true发生在存储y=true之前
while(!x.load(std::memory_order_seq_cst)) ;//x=true时,跳出循环
if(y.load(std::memory_order_seq_cst)) ++z; // 3 y=true时,++z
}
void read_y_then_x(){//x必然返回true,因while循环保证y为true
while(!y.load(std::memory_order_seq_cst)) ;
if(x.load(std::memory_order_seq_cst)) ++z; // 4
}
int main(){
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0); // 永远不被触发
}
开启四条线程,语句1和语句3需要一个确定的顺序,而memory_order_seq_cst保证了读取操作在保存操作之前,即保存x.store(true)之后y再进行修改。
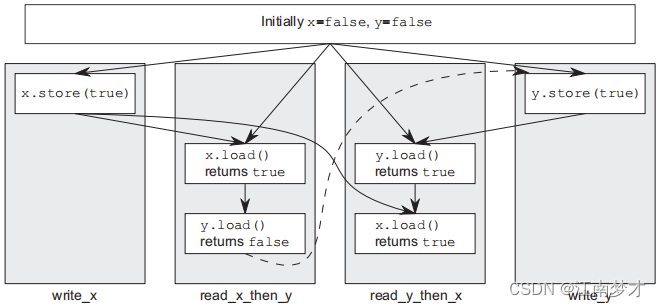
非顺序一致性内存(余下5种)
为写出/了解一段使用非默认顺序代码,需要知道不仅是编译器能重新排列代码顺序,而且不同线程即使运行相同的代码都能有不同的代码顺序。因为操作在其他线程上没有明确的顺序限制,不同的CPU缓存和内部缓冲区,在同样的存储空间中可以存储不同的值。没有明确顺序限制时,就需要所有线程要对每个独立变量修改顺序。对不同变量的操作可以体现在不同线程的不同序列上,提供的值要与任意附加顺序限制保持一致。
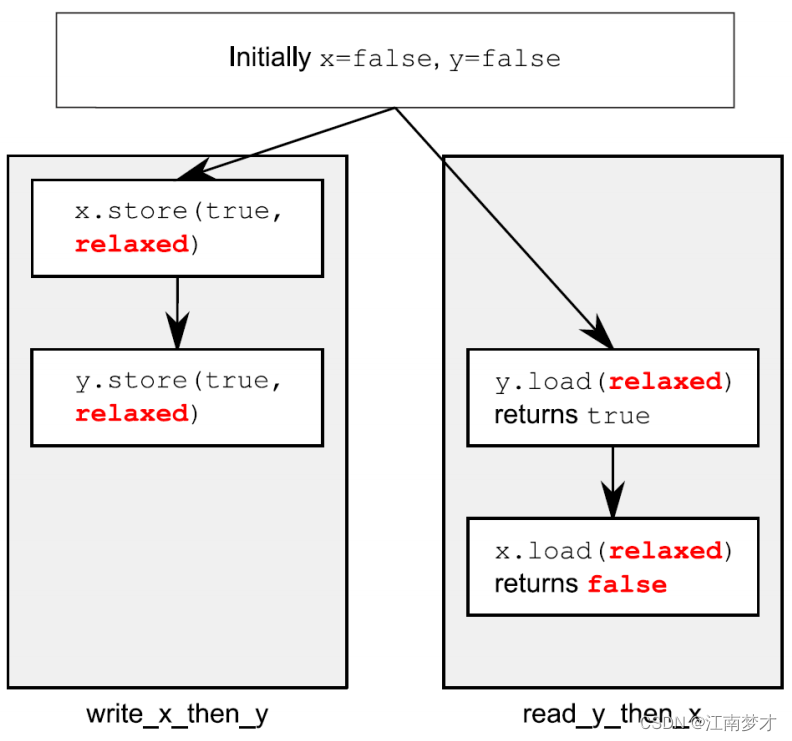
自由序(relax)
- 自由序的原子操作不再遵从同发关系。
- 单线程中的单个原子变量遵守先行关系,但与其他线程没有顺序要求。
- 单线程中的单个原子变量不能重排序(不同变量间会乱序执行),所以当线程看到原子变量时,后续线程无法读取之前的变量值。
- 在没有任何额外的同步的情况下,每个线程都会修改语句顺序,线程间唯一的共同点是使用了
memory_order_relaxed。
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y(){
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_relaxed); // 2
}
void read_y_then_x(){
while(!y.load(std::memory_order_relaxed)); // 3
if(x.load(std::memory_order_relaxed)) ++z; // 4
}
int main(){
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 可能会被触发,因为操作4可能读取false,即使操作3读取true
//x和y是不同变量,没有顺序将保证每个操作产生相关值的可见性
}
三个变量与五个线程:
#include <thread>
#include <atomic>
#include <iostream>
std::atomic<int> x(0),y(0),z(0); // 1 三个全局原子变量
std::atomic<bool> go(false); // 2 确保线程同时退出
unsigned const loop_count=10;
struct read_values{ int x,y,z; };
read_values values1[loop_count];
read_values values2[loop_count];
read_values values3[loop_count];
read_values values4[loop_count];
read_values values5[loop_count];
void increment(std::atomic<int>* var_to_inc, read_values* values){
while(!go) std::this_thread::yield(); // 3 自旋,等待信号
for(unsigned i=0 ; i<loop_count ; ++i){
values[i].x=x.load(std::memory_order_relaxed);
values[i].y=y.load(std::memory_order_relaxed);
values[i].z=z.load(std::memory_order_relaxed);
//每次循环更新一个原子变量
var_to_inc->store(i+1,std::memory_order_relaxed); // 4
std::this_thread::yield();
}
}
void read_vals(read_values* values){
while(!go) std::this_thread::yield(); // 5 自旋,等待信号
for(unsigned i=0;i<loop_count;++i){
values[i].x=x.load(std::memory_order_relaxed);
values[i].y=y.load(std::memory_order_relaxed);
values[i].z=z.load(std::memory_order_relaxed);
std::this_thread::yield();
}
}
void print(read_values* v){
for(unsigned i=0;i<loop_count;++i){
if(i) std::cout<<",";
std::cout<<"("<<v[i].x<<","<<v[i].y<<","<<v[i].z<<")";
}
std::cout<<std::endl;
}
int main(){
std::thread t1(increment,&x,values1); // x递增,y和z从全局原子变量读取
std::thread t2(increment,&y,values2); // y递增,x和z从全局原子变量读取
std::thread t3(increment,&z,values3); // z递增,x和y从全局原子变量读取
std::thread t4(read_vals,values4); // 线程读取相应变量,但不同变量乱序
std::thread t5(read_vals,values5);
go=true; // 6 开始执行主循环的信号
t5.join();
t4.join();
t3.join();
t2.join();
t1.join();
print(values1); // 7 打印最终结果
print(values2);
print(values3);
print(values4);
print(values5);
}
/*五个线程的输出结果,123行的xyz分别递增,45行读取xyz的值,分均匀递增
(0,0,1),(1,0,2),(2,1,3),(3,1,4),(4,1,5),(5,1,6),(6,2,7),(7,2,8),(8,2,9),(9,2,10)
(2,0,2),(6,1,6),(10,2,10),(10,3,10),(10,4,10),(10,5,10),(10,6,10),(10,7,10),(10,8,10),(10,9,10)
(0,0,0),(1,0,1),(2,1,2),(3,1,3),(4,1,4),(5,1,5),(6,2,6),(7,2,7),(8,2,8),(9,2,9)
(0,0,0),(0,0,0),(1,0,1),(2,0,2),(3,1,3),(4,1,4),(5,1,5),(5,1,6),(6,2,7),(7,2,8)
(10,3,10),(10,3,10),(10,4,10),(10,5,10),(10,6,10),(10,8,10),(10,8,10),(10,9,10),(10,10,10),(10,10,10)
*/
强烈建议避免自由序的原子操作,除非它们是硬性要求。
获取-释放序(memory_order_acquire memory_order_release)
自由序加强版,不同在于加入了同步机制。不同的线程仍有不同的顺序。
- 原子加载就是获取操作(memory_order_acquire),该调用后的读写操作不会重排到前面。
- 原子存储就是释放操作(memory_order_release),该调用前的读写操作不会重排到后面。
- 原子读-改-写操作,不是获取操作就是释放操作(成对使用,同步就能读取已写入值),或兼有的获取释放操作 (memory_order_acq_rel)。
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x(){ x.store(true,std::memory_order_seq_release); }
void write_y(){ y.store(true,std::memory_order_seq_release); }
void read_x_then_y(){
while(!x.load(std::memory_order_seq_acquire)) ;
if(y.load(std::memory_order_seq_acquire)) ++z; // 1
}
void read_y_then_x(){
while(!y.load(std::memory_order_seq_acquire)) ;
if(x.load(std::memory_order_seq_acquire)) ++z; // 2
}
int main(){
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
/*
可能会被触发,因加载x和y时,可能读到false;
它们由不同线程写入,获取与释放不会影响其他线程操作。
(ab线程未改写xy,cd线程就读取对应的值)
可见自由序第二点,原子变量对,其他线程无顺序要求
*/
assert(z.load()!=0);
}
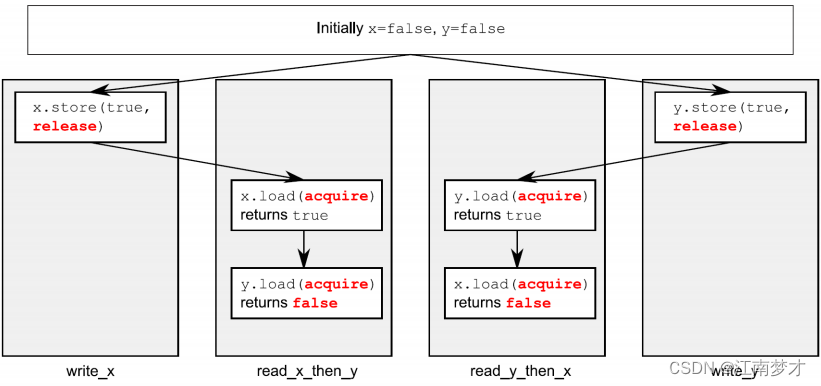
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y(){//因为1和2在同一线程,所以1先行于2
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_release); // 2
}
void read_y_then_x(){//2与3同步,储存x先行于y加载先行于x加载
while(!y.load(std::memory_order_acquire)) ; // 3 自旋,等待y被设置为true
if(x.load(std::memory_order_relaxed)) ++z; // 4 x必为真
}//2和3都是release,则x无序访问,无法保证4为真,5就会触发了
int main(){
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 5 不会触发,不存在上一段代码那种其他线程先结束的情况
}
release操作的值被acquire操作看到,才能产生效果。
获取-释放序列可以在若干线程间使用同步数据,甚至在“中间”线程接触到数据前使用。
获取-释放序传递同步(memory_order_acq_rel)
std::atomic<int> data[5];
std::atomic<bool> sync1(false),sync2(false);
void thread_1(){//修改共享变量
data[0].store(42,std::memory_order_relaxed);
data[1].store(97,std::memory_order_relaxed);
data[2].store(17,std::memory_order_relaxed);
data[3].store(-141,std::memory_order_relaxed);
data[4].store(2003,std::memory_order_relaxed);
sync1.store(true,std::memory_order_release); // 1.设置sync1 先行于前面五行操作
}
void thread_2(){//“加载-获取”读取由“存储-释放”操作过的变量,再进行一次“存储-释放”操作
while(!sync1.load(std::memory_order_acquire)); // 2.直到sync1设置后,循环结束
sync2.store(true,std::memory_order_release); // 3.设置sync2 先行于thread_3
}
void thread_3(){//“加载-获取”读取第二个共享变量,使用“加载-获取”操作读取“存储-释放”值
while(!sync2.load(std::memory_order_acquire)); // 4.直到sync1设置后,循环结束
assert(data[0].load(std::memory_order_relaxed)==42); //断言不会被触发
assert(data[1].load(std::memory_order_relaxed)==97);
assert(data[2].load(std::memory_order_relaxed)==17);
assert(data[3].load(std::memory_order_relaxed)==-141);
assert(data[4].load(std::memory_order_relaxed)==2003);
}
通过在thread_2中使用“读-改-写”操作且内存序设为memory_order_acq_rel,可将sync1和sync2合并成一个独立的变量:
std::atomic<int> sync(0);
void thread_1(){
// ...
sync.store(1,std::memory_order_release);
}
void thread_2(){
int expected=1;
while(!sync.compare_exchange_strong(expected,2,std::memory_order_acq_rel))
expected=1;
}
void thread_3(){
while(sync.load(std::memory_order_acquire)<2);
// ...
}
当互斥量保护数据时,因为锁住与解锁的操作都是顺序一致的操作,就保证了结果一致。当对原子变量使用获取和释放序时,代码必然会使用锁,即使内部操作序不一致,其外部表现将会为顺序一致。
获取-释放序和memory_order_consume的数据依赖
memory_order_consume非常特别,完全依赖于数据,且与线程间先行关系有些许不同。即使在C++17中也不推荐使用。
数据依赖:后一操作依赖于前一操作的结果,这两个操作就有数据依赖。
两种新关系用来处理数据依赖:前序依赖(dependency-ordered-before)和携带依赖(carries-a-dependency-to)。
携带依赖(carries-a-dependency-to)严格用于单线程内及其数据依赖模型,这种依赖可以传递。
前序依赖(dependency-ordered-before)可用于线程之间。一个原子操作使用前序依赖的例子:限制了同步数据的直接依赖;一个保存操作A(标记为memory_ order_release, memory_order_acq_rel或memory_order_seq_cst)前序依赖一个读取操作B(标记为memory_order_consume),前提是操作B使用了保存的值。这与你在使用读取操作(标记为memory_order_acquire)得到的同步关系相反。
如果A前序依赖B,那A同样线程间先行于B。
保存操作使用memory_order_release,读取操作使用memory_order_consume,这确保了其原子操作加载指向某些数据的指针,所指向的数据是正确同步的,而不对任何其他非依赖的数据施加任何同步要求(常用于指针)。
struct X{int i;std::string s;};
std::atomic<X*> p;
std::atomic<int> a;
void create_x(){
X* x=new X;
x->i=42;
x->s="hello";
a.store(99,std::memory_order_relaxed); // 1
p.store(x,std::memory_order_release); // 2
}
void use_x(){
X* x;
while(!(x=p.load(std::memory_order_consume))) // 3
std::this_thread::sleep(std::chrono::microseconds(1));
assert(x->i==42); // 4 成立不会报错
assert(x->s=="hello"); // 5 成立不会报错
assert(a.load(std::memory_order_relaxed)==99); // 6 无法保证会不会被触发
}
int main(){
std::thread t1(create_x);
std::thread t2(use_x);
t1.join();
t2.join();
}
如果不想为携带依赖增加其他开销。想使用编译器在寄存器中缓存这些值,以及优化重排序操作代码。可以使用std::kill_dependecy()显式打破依赖链,它会复制提供的参数给返回值。
int global_data[]={ … };
std::atomic<int> index;
void f(){
int i=index.load(std::memory_order_consume);
// std::kill_dependency()让编译器知道这里不需要重新读取该数组的内容
do_something_with(global_data[std::kill_dependency(i)]);
}
实际操作中,应该使用memory_order_acquire,而不是memory_order_consume和 std::kill_dependency。
释放序与同行操作
综上store可用memory_order_release, memory_order_acq_rel或 memory_order_seq_cst;同理load可用 memory_order_consume, memory_order_acquire或memory_order_seq_cst。store的值将被load。这一系列标记与操作构成了release顺序以及初始store或dependency-ordered-before最终load。
#include <atomic>
#include <thread>
using namespace std;
vector<int> queue_data;
atomic<int> count;
void populate_queue(){
unsigned const number_of_items=20;
queue_data.clear();
for(unsigned i=0;i<number_of_items;++i){ queue_data.push_back(i); }
count.store(number_of_items,memory_order_release); // 1 初始化存储
}
void consume_queue_items(){
while(true){
int item_index;
//一个“读-改-写”操作
if((item_index=count.fetch_sub(1,memory_order_acquire))<=0){// 2
wait_for_more_items(); // 3 等待更多元素
continue;
}
process(queue_data[item_index-1]); // 4 安全读取queue_data
}
}
int main(){
thread a(populate_queue);
thread b(consume_queue_items);
thread c(consume_queue_items);
a.join();
b.join();
c.join();
}
例子中线程a使用store操作,线程b和c使用“读-改-写”操作(fetch_sub),第二个fetch_sub会读取第一个fetch_sub修改的值而不是线程a会store的值。由于,第一个fetch_sub会参与release顺序排列。因此,store操作会与每一个使用memory_order_acquire的“读-改-写”操作(fetch_sub)同发。但是两个消费者线程(b和c)没有同发关系。
下图虚线表示release顺序,实线表示同发关系。
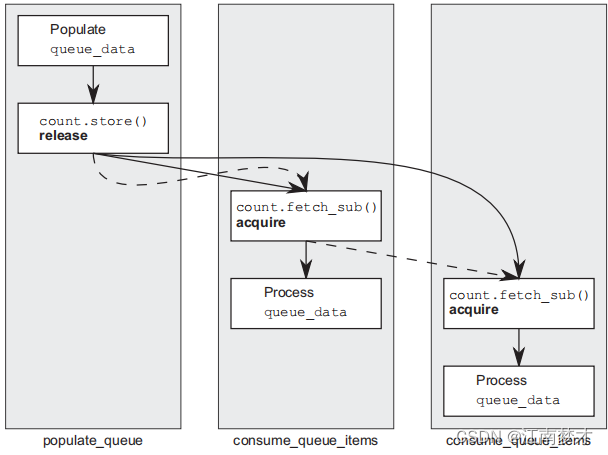
栅栏
拦住原子操作,不再继续对数据进行修改。常与memory_order_relaxed一起使用,使用栅栏将限制这种原子操作随意排序的自由。
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y(){
x.store(true,std::memory_order_relaxed); // 1
std::atomic_thread_fence(std::memory_order_release); // 2 释放栅栏
y.store(true,std::memory_order_relaxed); // 3 是release时,栅栏2也有影响
}
void read_y_then_x(){
while(!y.load(std::memory_order_relaxed));//4 是acquire时,栅栏5也有影响
std::atomic_thread_fence(std::memory_order_acquire); // 5 获取栅栏
if(x.load(std::memory_order_relaxed)) ++z; // 6
}
int main(){
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 7
}
当release栅栏后store一个acquire内存序的值,那么acquire栅栏将同步该值;
当acquire栅栏前load一个被release操作的值,那么这个值就与acquire栅栏同步。
虽然,栅栏同步依赖于读取/写入的操作发生于栅栏之前/后,但是这里有一点很重要:同步点,就是栅栏本身。
void write_x_then_y(){
std::atomic_thread_fence(std::memory_order_release);
x.store(true,std::memory_order_relaxed);
y.store(true,std::memory_order_relaxed);
}//此时7处断言可能会被触发,x与y的顺序不再有硬性规定。
原子操作对非原子的操作排序
#include <atomic>
#include <thread>
#include <assert.h>
bool x=false; // x现在是一个非原子变量
std::atomic<bool> y;
std::atomic<int> z;
void write_x_then_y(){
x=true; // 1 在栅栏前存储x
std::atomic_thread_fence(std::memory_order_release);
y.store(true,std::memory_order_relaxed); // 2 在栅栏后存储y
}
void read_y_then_x(){
while(!y.load(std::memory_order_relaxed)) ; // 3 在#2写入前,持续等待
std::atomic_thread_fence(std::memory_order_acquire);
if(x) ++z; // 4 这里读取到的值,是#1中写入
}
int main(){
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 5 断言将不会触发
}
不仅是栅栏可对非原子操作排序,原子操作也为非原子访问排序,可以动态分配对象。
在原子操作之前的非原子操作,它们先行于原子操作;当这个原子操作先行于另一线程,此时非原子操作就先行于其他线程。以自旋锁的实现为例:
class spinlock_mutex{
std::atomic_flag flag;
public:
spinlock_mutex():flag(ATOMIC_FLAG_INIT){}
void lock(){ while(flag.test_and_set(std::memory_order_acquire)) ; }
void unlock(){flag.clear(std::memory_order_release);}
};//保护数据的修改先行于等待解锁,先行于第二个线程的上锁,先行于第二个线程对保护数据的修改
以下的工具都可以提供同步:
std::thread
- std::thread构造新线程时,构造函数与调用函数或新线程的可调用对象间的同步。
- 对std::thread对象调用join,可以和对应的线程进行同步。
std::mutex, std::timed_mutex, std::recursive_mutex, std::recursibe_timed_mutex
- 对给定互斥量对象调用lock和unlock,以及对try_lock,try_lock_for或try_lock_until,会形成该互斥量的锁序。
- 对给定的互斥量调用unlock,需要在调用lock或成功调用try_lock,try_lock_for或try_lock_until之后,这样才符合互斥量的锁序。
- 对try_lock,try_lock_for或try_lock_until失败的调用,不具有任何同步关系。
std::shared_mutex , std::shared_timed_mutex
- 对给定互斥量对象调用lock、unlock、lock_shared和unlock_shared,以及对 try_lock , try_lock_for, try_lock_until, try_lock_shared, try_lock_shared_for或try_lock_shared_until的成功调用,会形成该互斥量的锁序。
- 对给定的互斥量调用unlock,需要在调用lock或shared_lock,亦或是成功调用try_lock , try_lock_for, try_lock_until, try_lock_shared, try_lock_shared_for或try_lock_shared_until之后,才符合互斥量的锁序。
- 对try_lock,try_lock_for,try_lock_until,try_lock_shared,try_lock_shared_for或try_lock_shared_until失败的调用,不具有任何同步关系。
std::shared_mutex和std::shared_timed_mutex
- 成功的调用std::promise对象的set_value或set_exception与成功的调用wait或get之间同步,或是调用wait_for或wait_until的返回例如future状态std::future_status::ready与promise共享同步状态。
- 给定std::promise对象的析构函数,该对象存储了一个std::future_error异常,成功的调用wait或get后,共享同步状态与promise之间的同步,或是调用wait_for或wait_until返回的future状态std::future_status::ready时,与promise共享同步状态。
std::packaged_task , std::future和std::shared_future
- 成功的调用std::packaged_task对象的函数操作符与成功的调用wait或get之间同步,或是调用wait_for或wait_until的返回future状态std::future_status::ready与打包任务共享同步状态。
- std::packaged_task对象的析构函数,该对象存储了一个std::future_error异常,其共享同步状态与打包任务之间的同步在于成功的调用wait或get,或是调用wait_for或wait_until返回的future状态std::future_status::ready与打包任务共享同步状态。
std::async , std::future和std::shared_future
- 使用std::launch::async策略性的通过std::async启动线程执行任务与成功的调用wait和get之间是同步的,或调用wait_for或wait_until返回的future状态std::future_status::ready与产生的任务共享同步状态。
- 使用std::launch::deferred策略性的通过std::async启动任务与成功的调用wait和get之间是同步的,或调用wait_for或wait_until返回的future状态std::future_status::ready与promise共享同步状态。
std::experimental::future , std::experimental::shared_future和持续性
- 异步共享状态变为就绪的事件与该共享状态上调度延续函数的调用同步。
- 持续性函数的完成与成功调用wait或get的返回同步,或调用wait_for或wait_until返回的期望值状态std::future_status::ready与调用then构建的持续性返回的future同步,或是与在调度用使用这个future的操作同步。
std::experimental::latch
- 对std::experimental::latch实例调用count_down或count_down_and_wait与在该对象上成功的调用wait或count_down_and_wait之间是同步的。
std::experimental::barrier
- 对std::experimental::barrier实例调用arrive_and_wait或arrive_and_drop与在该对象上随后成功完成的arrive_and_wait之间是同步的。
std::experimental::flex_barrier
- 对std::experimental::flex_barrier实例调用arrive_and_wait或arrive_and_drop与在该对象上随后成功完成 的arrive_and_wait之间是同步的。
- 对std::experimental::flex_barrier实例调用arrive_and_wait或arrive_and_drop与在该对象上随后完成的给定函数之间是同步的。
- 对std::experimental::flex_barrier实例的给定函数的返回与每次对arrive_and_wait的调用同步,当调用给定函数线程会在栅栏处阻塞等待。
std::condition_variable和std::condition_variable_any
- 条件变量不提供任何同步关系,它们是对忙等待的优化,所有同步都由互斥量提供。