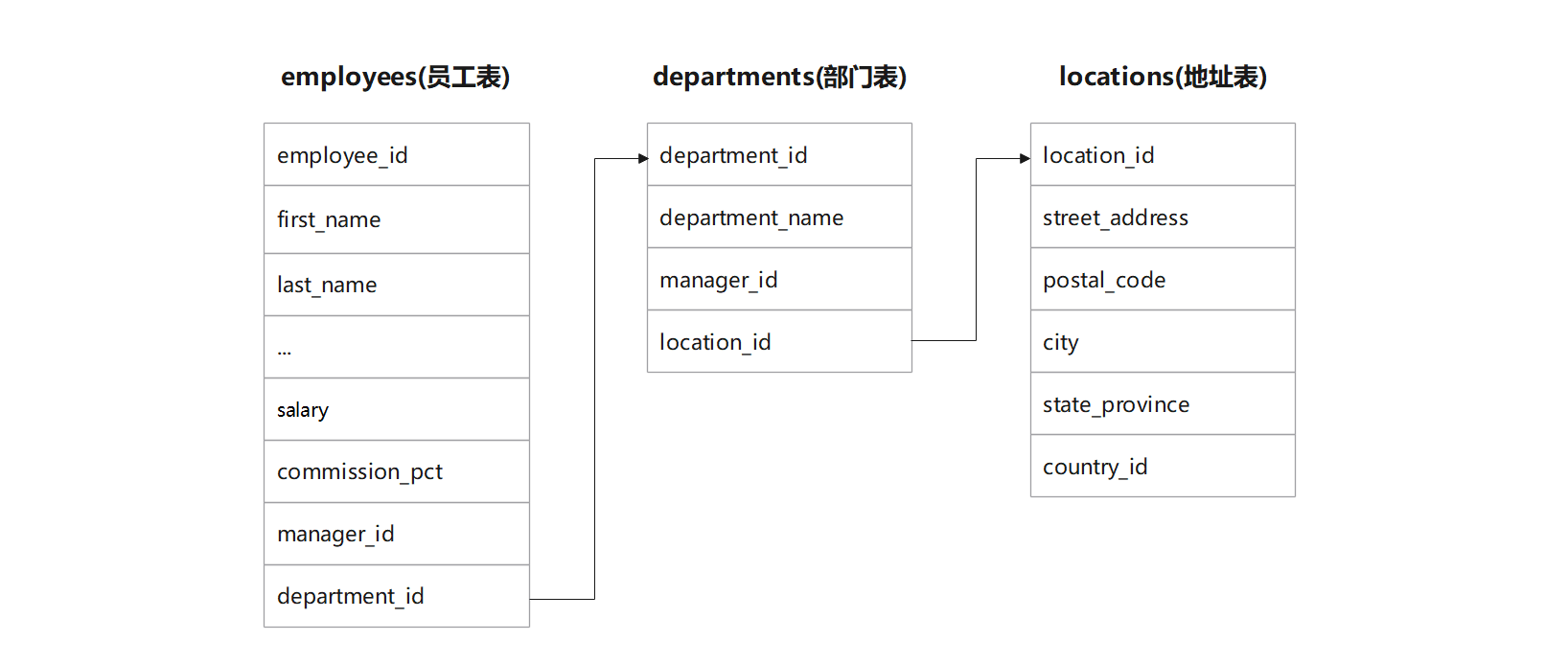
-- 1. 获取获取jack的部门id:
mysql>SELECT first_name, department_id FROM employees WHERE first_name ='Jack';+------------+---------------+| first_name | department_id |+------------+---------------+| Jack |80|+------------+---------------+1rowinset(0.03 sec)
-- 2. 通过部门id获取地址id:
mysql>SELECT department_id, location_id FROM departments WHERE department_id =80;+---------------+-------------+| department_id | location_id |+---------------+-------------+|80|2500|+---------------+-------------+1rowinset(0.01 sec)
-- 3. 通过地址id在地址表中获取工作的城市:
mysql>SELECT location_id, city FROM locations WHERE location_id =2500;+-------------+--------+| location_id | city |+-------------+--------+|2500| Oxford |+-------------+--------+1rowinset(0.01 sec)
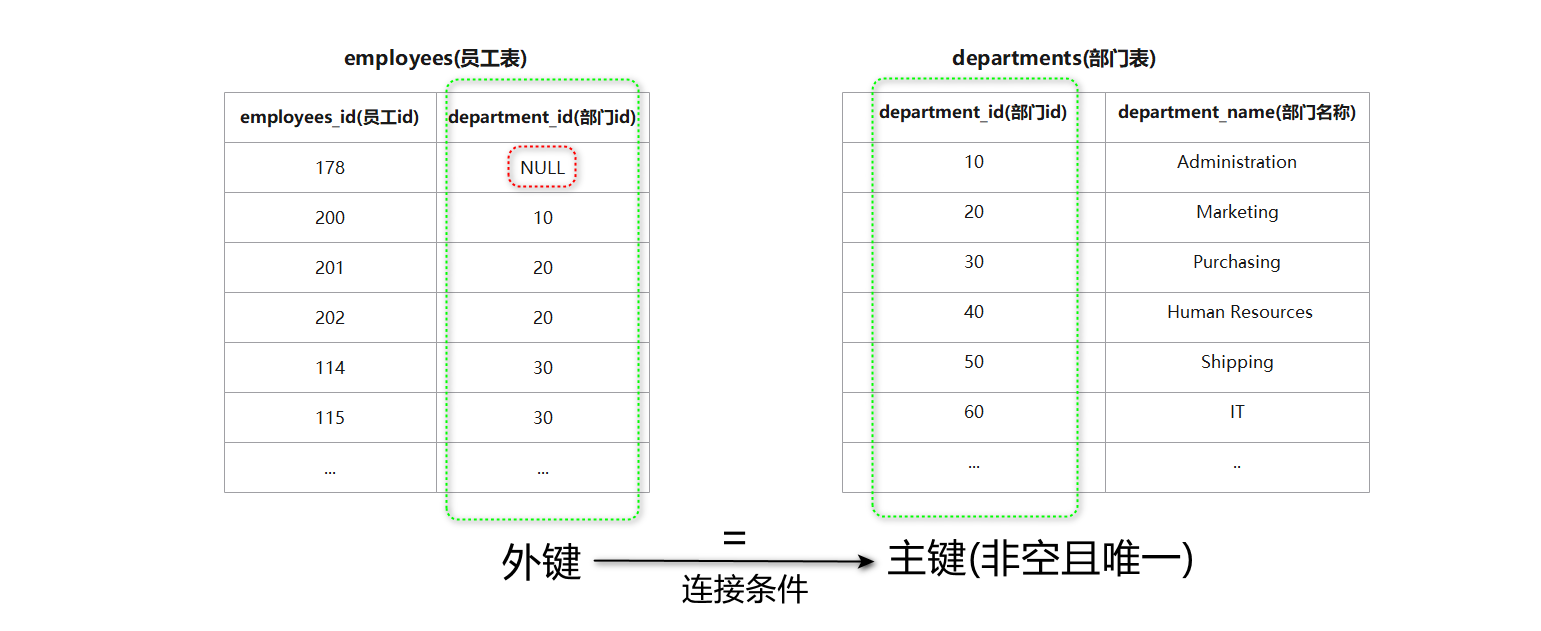
-- 等值连接案例: 查询员工名字与员工的部门名称:
mysql>SELECT emp.first_name, dept.department_name FROM employees AS`emp`, departments AS`dept`->WHERE emp.department_id = dept.department_id;+-------------+------------------+| first_name | department_name |+-------------+------------------+| Jennifer | Administration || Michael | Marketing || Pat | Marketing || Den | Purchasing || Alexander | Purchasing || Shelli | Purchasing || Sigal | Purchasing ||...|...|-- 省略| Jose Manuel | Finance || Luis | Finance || Shelley | Accounting || William | Accounting |+-------------+------------------+106rowsinset(0.04 sec)
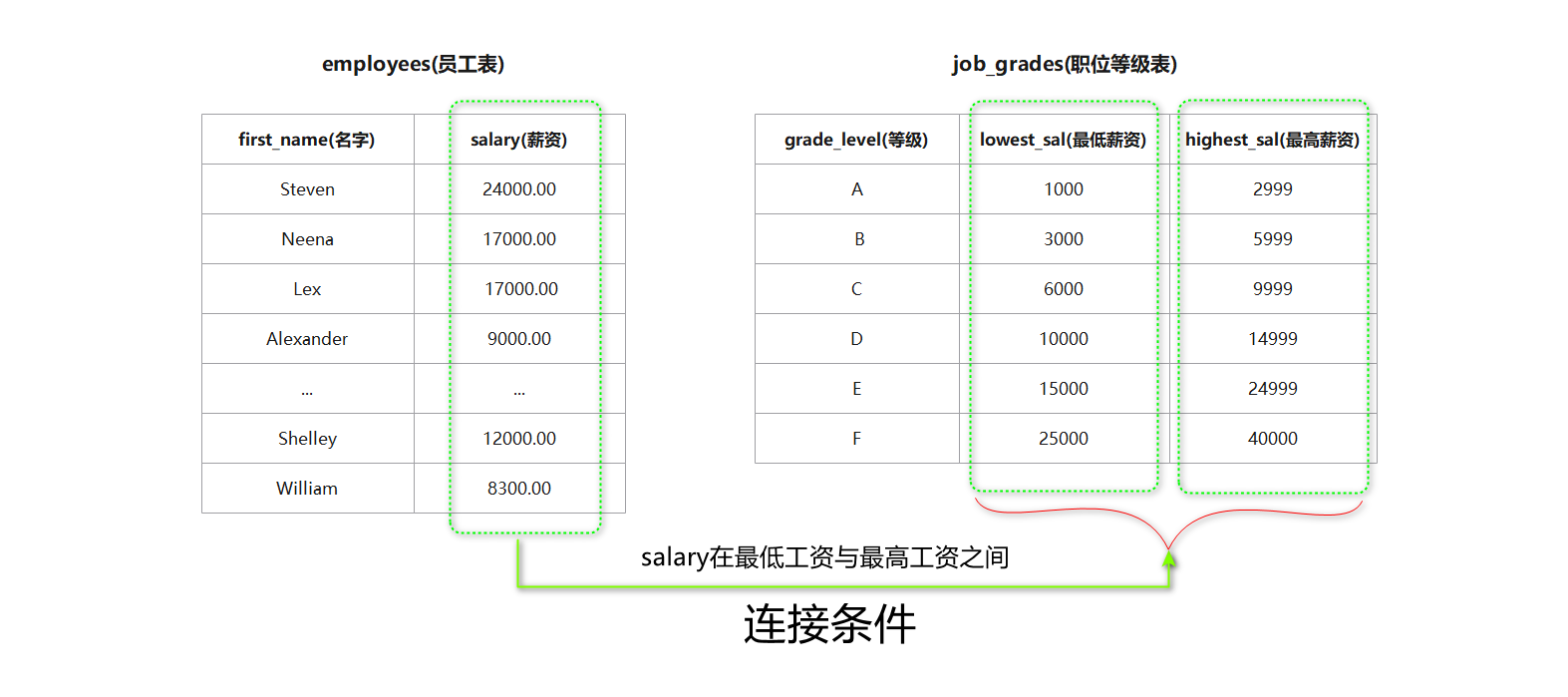
-- 非等值连接案例-- 1. 查看一下职务等级表:
mysql>select*from job_grades;+-------------+------------+-------------+| grade_level | lowest_sal | highest_sal |-- 最低 最高+-------------+------------+-------------+| A |1000|2999|-- 1000 ~ 2999 工资之间为A级.| B |3000|5999|-- 3000 ~ 5999 工资之间为B级.| C |6000|9999|-- 6000 ~ 9999 工资之间为C级.| D |10000|14999|-- 10000 ~ 14999 工资之间为D级.| E |15000|24999|-- 15000 ~ 24999 工资之间为E级.| F |25000|40000|-- 25000 ~ 40000 工资之间为F级.+-------------+------------+-------------+6rowsinset(0.01 sec)-- 2. 查询员工的名字, 工资, 职务等级.
mysql>SELECT emp.first_name, emp.salary, jg.grade_level FROM employees AS`emp`, job_grades AS`jg`WHERE emp.salary BETWEEN jg.lowest_sal AND jg.highest_sal;+-------------+----------+-------------+| first_name | salary | grade_level |+-------------+----------+-------------+| Steven |24000.00| E || Neena |17000.00| E || Lex |17000.00| E || Alexander |9000.00| C ||...|...|.|| Jennifer |4400.00| B || Michael |13000.00| D || Pat |6000.00| C || Susan |6500.00| C || Hermann |10000.00| D || Shelley |12000.00| D || William |8300.00| C |+-------------+----------+-------------+107rowsinset(0.00 sec)
-- 自连接案例, 查询员工的管理者名字: -- worker和manager本质上是同一张表, 只是用取别名的方式虚拟成两张表以代表不同的意义.
mysql>SELECT worker.first_name AS"员工名字", manager.first_name AS"管理者名字"->FROM employees AS`worker`, employees AS`manager`->WHERE worker.manager_id = manager.employee_id;+-------------+------------+| 员工名字 | 管理者名字 |+-------------+------------+| Neena | Steven || Lex | Steven || Alexander | Lex || Bruce | Alexander || David | Alexander || Valli | Alexander ||...|...|| Jennifer | Neena || Michael | Steven || Pat | Michael || Susan | Neena || Hermann | Neena || Shelley | Neena || William | Shelley |+-------------+------------+106rowsinset(0.00 sec)
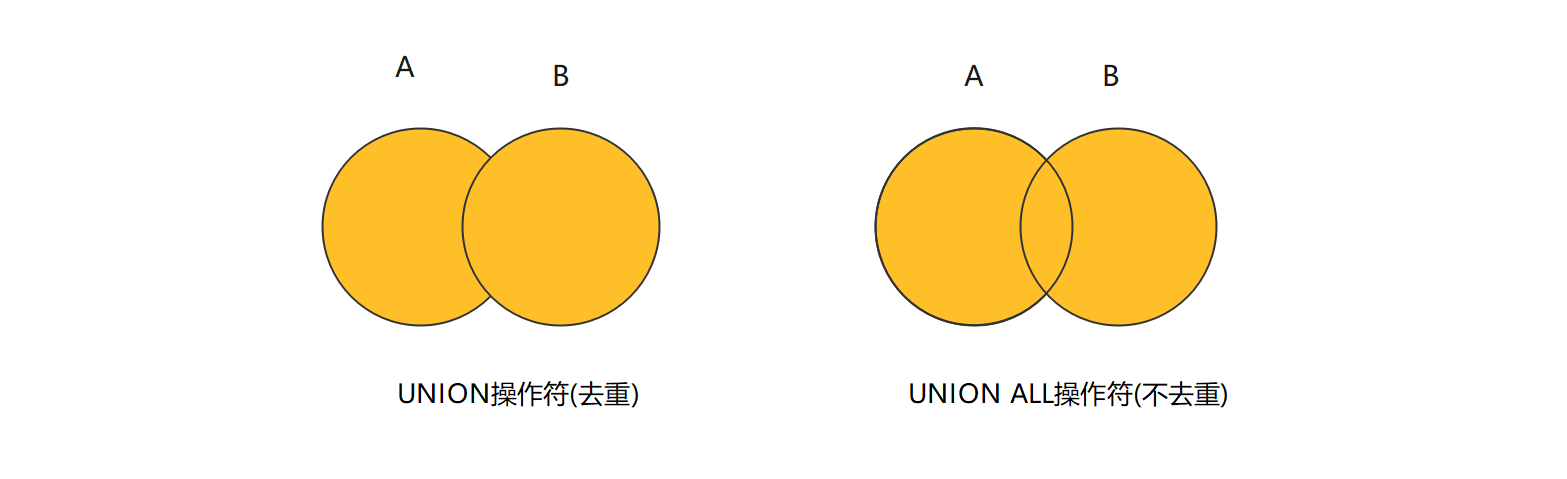
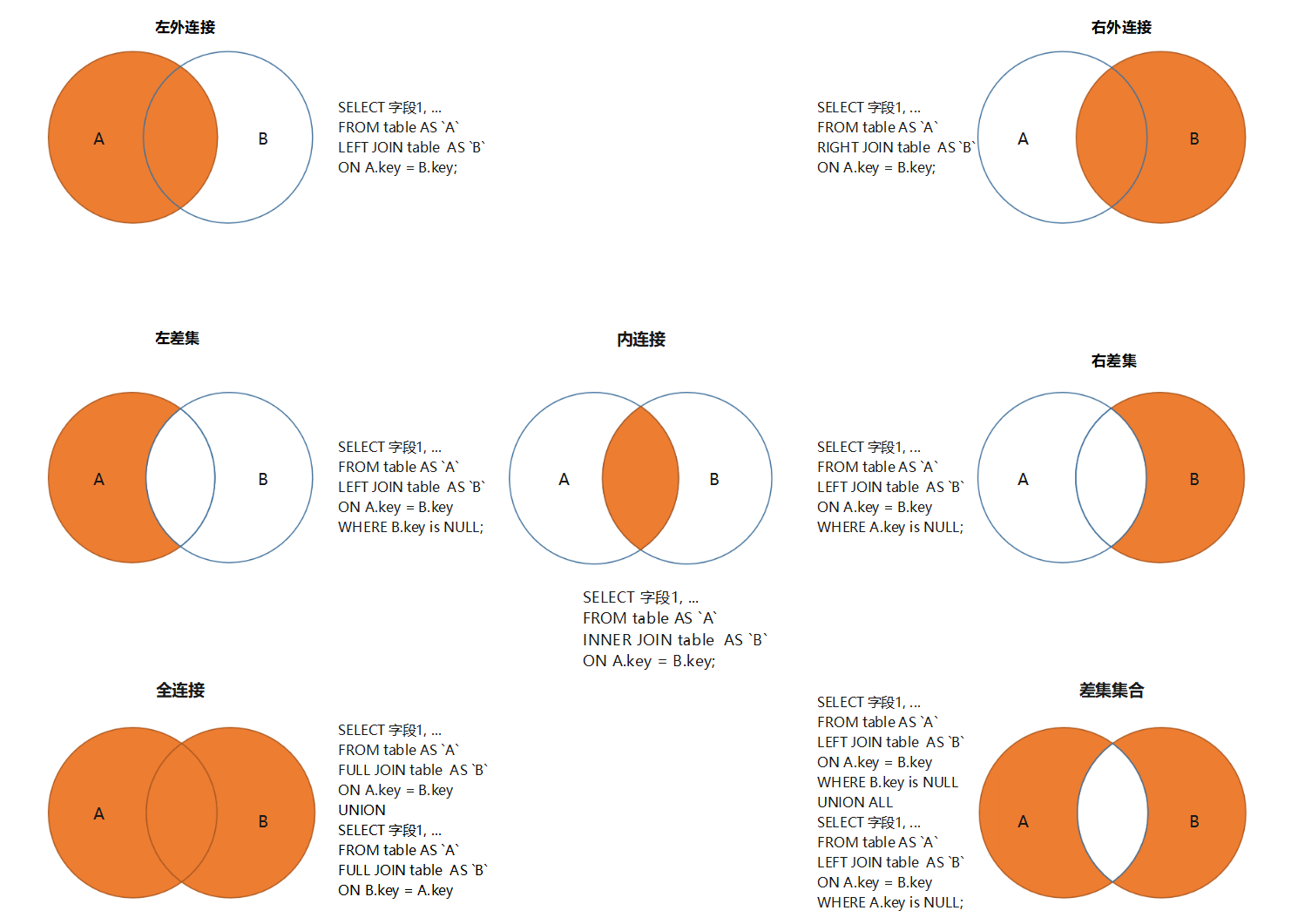
-- MySQL不支持FULL JOIN, 但是可以用LEFT JOIN UNION RIGHT join代替.-- 语法如下:SELECT 字段列表 FROM A表 LEFTJOIN B表 ON 关联条件 WHERE 等其他子句;UNION[ALL]SELECT 字段列表 FROM A表 RIGHTJOIN B表 ON 关联条件 WHERE 等其他子句;-- 注意: 执行UNION ALL语句时所需要的资源比UNION语句少.-- 如果明确知道合并数据后的结果数据不存在重复数据, 或者不需要去除重复的数据, 则尽量使用UNION ALL语句, 以提高数据查询的效率.
-- 问题: 为什么是 WHERE B.key_column IS NULL; 而不是 WHERE A.key_column IS NULL;SELECT A.*FROM table_A A
LEFTJOIN table_B B ON A.key_column = B.key_column
WHERE B.key_column ISNULL;
SQL查询中, 使用LEFT JOIN来连接table_A和table_B.
这意味着, 获取到 table_A 的所有记录, 并与table_B中匹配的记录进行连接.
如果table_B中没有与table_A中的记录匹配的记录, 那么table_B中的所有列都将为NULL.
因此, 当我们使用WHERE B.key_column IS NULL, 我们实际上是在查找那些在table_B中没有与table_A中的记录匹配的记录.
换句话说, 这些记录存在于table_A中, 但不存在于table_B中, 即 A - (A ∩ B).
现在有一个员工的id为null, 那么A.key_column IS NULL得到的结果没有问题(但这并不代表这个方式是正确的).
如果员工的id不是null, 而是其他不存在与B表中的id, 那么那么A.key_column IS NULL得到的结果就是一个空集.
B.key_column IS NULL能保证结果一定是对的, 而A.key_column IS NULL无法保证!
-- 右差集 B - (A∩B) : 返回右表没有被匹配成功的行.
mysql>SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS`emp`RIGHTJOIN departments AS`dept`ON emp.department_id = dept.department_id
WHERE emp.department_id ISNULL;+------------+-------------+---------------+----------------------+| first_name | employee_id | department_id | department_name |+------------+-------------+---------------+----------------------+|NULL|NULL|120| Treasury ||NULL|NULL|130| Corporate Tax ||NULL|NULL|140| Control And Credit ||NULL|NULL|150| Shareholder Services ||NULL|NULL|160| Benefits ||NULL|NULL|170| Manufacturing ||NULL|NULL|180| Construction ||NULL|NULL|190| Contracting ||NULL|NULL|200| Operations ||NULL|NULL|210| IT Support ||NULL|NULL|220| NOC ||NULL|NULL|230| IT Helpdesk ||NULL|NULL|240| Government Sales ||NULL|NULL|250| Retail Sales ||NULL|NULL|260| Recruiting ||NULL|NULL|270| Payroll |+------------+-------------+---------------+----------------------+16rowsinset(0.00 sec)
-- 全连接, 返回两个表的所有行.
mysql>SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS`emp`LEFTJOIN departments AS`dept`ON emp.department_id = dept.department_id
UNIONSELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS`emp`RIGHTJOIN departments AS`dept`ON emp.department_id = dept.department_id;+-------------+-------------+---------------+----------------------+| first_name | employee_id | department_id | department_name |+-------------+-------------+---------------+----------------------+| Steven |100|90| Executive ||...|...|..|...|-- 省略| Jack |177|80| Sales || Kimberely |178|NULL|NULL||...|...|..|...|-- 省略|NULL|NULL|120| Treasury ||NULL|NULL|130| Corporate Tax ||NULL|NULL|140| Control And Credit ||NULL|NULL|150| Shareholder Services ||NULL|NULL|160| Benefits ||NULL|NULL|170| Manufacturing ||NULL|NULL|180| Construction ||NULL|NULL|190| Contracting ||NULL|NULL|200| Operations ||NULL|NULL|210| IT Support ||NULL|NULL|220| NOC ||NULL|NULL|230| IT Helpdesk ||NULL|NULL|240| Government Sales ||NULL|NULL|250| Retail Sales ||NULL|NULL|260| Recruiting ||NULL|NULL|270| Payroll |+-------------+-------------+---------------+----------------------+123rowsinset(0.01 sec)
-- 差集集合, 返回左差集与右差集的集合,
mysql>SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS`emp`LEFTJOIN departments AS`dept`ON emp.department_id = dept.department_id
WHERE dept.department_id ISNULLUNIONALL-- 没有重复的行使用UNION ALL效率更高!SELECT emp.first_name, emp.employee_id, dept.department_id, dept.department_name
FROM employees AS`emp`RIGHTJOIN departments AS`dept`ON emp.department_id = dept.department_id
WHERE emp.department_id ISNULL;+------------+-------------+---------------+----------------------+| first_name | employee_id | department_id | department_name |+------------+-------------+---------------+----------------------+| Kimberely |178|NULL|NULL||NULL|NULL|120| Treasury ||NULL|NULL|130| Corporate Tax ||NULL|NULL|140| Control And Credit ||NULL|NULL|150| Shareholder Services ||NULL|NULL|160| Benefits ||NULL|NULL|170| Manufacturing ||NULL|NULL|180| Construction ||NULL|NULL|190| Contracting ||NULL|NULL|200| Operations ||NULL|NULL|210| IT Support ||NULL|NULL|220| NOC ||NULL|NULL|230| IT Helpdesk ||NULL|NULL|240| Government Sales ||NULL|NULL|250| Retail Sales ||NULL|NULL|260| Recruiting ||NULL|NULL|270| Payroll |+------------+-------------+---------------+----------------------+17rowsinset(0.00 sec)
题图来自 Decoding Rust: Everything You Need to Know About the Programming Language[1] File: rust/library/std/src/os/watchos/mod.rs 该文件(rust/library/std/src/os/watchos/mod.rs)的作用是为Rust标准库提供支持WatchOS操作系统的特定功能。 W…

![[ASP]校无忧在线考试系统 v3.7](https://img-blog.csdnimg.cn/18b52012834743c8b8a02856d4a6b3af.png)