文章目录
- 统计学习方法 逻辑斯蒂回归与最大熵模型
- 逻辑斯蒂回归
- 逻辑斯蒂分布
- 二项逻辑斯蒂回归
- 多项逻辑斯蒂回归
- 最大熵模型
- 原理
- 定义
- 学习
- 极大似然估计
统计学习方法 逻辑斯蒂回归与最大熵模型
学习李航的《统计学习方法》时,关于逻辑斯蒂回归与最大熵模型的笔记。
逻辑斯蒂回归
虽然叫逻辑回归,但是实际上是一种分类模型。
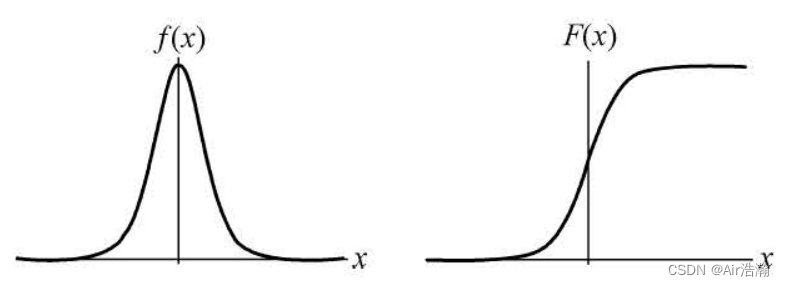
逻辑斯蒂分布
逻辑斯蒂分布(logistic distribution):设
X
X
X 是连续性随机变量,若
X
X
X 服从逻辑斯蒂分布,则
X
X
X 的分布函数和概率密度函数为:
F
(
x
)
=
P
(
X
≤
x
)
=
1
1
+
e
−
(
x
−
μ
)
/
γ
f
(
x
)
=
F
′
(
x
)
=
e
−
(
x
−
μ
)
/
γ
γ
(
1
+
e
−
(
x
−
μ
)
/
γ
)
2
\begin{aligned} F(x)=&\, P(X \leq x) = \frac{1}{1+ \mathrm{e}^{-(x-\mu)/\gamma}} \\ f(x)=&\, F'(x) = \frac{\mathrm{e}^{-(x-\mu)/\gamma}}{\gamma(1+\mathrm{e}^{-(x-\mu)/\gamma})^2} \end{aligned}
F(x)=f(x)=P(X≤x)=1+e−(x−μ)/γ1F′(x)=γ(1+e−(x−μ)/γ)2e−(x−μ)/γ
其中
μ
\mu
μ 为位置参数,
γ
\gamma
γ 为形状参数。密度函数关于
x
=
μ
x=\mu
x=μ 对称,分布函数关于
(
μ
,
1
2
)
(\mu,\frac{1}{2})
(μ,21) 中心对称:
二项逻辑斯蒂回归
二项逻辑回归是一种分类模型,可以写成条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) ,其中随机变量 X X X 代表特征, Y Y Y 的取值为 0 或 1,代表类别。具体地,该条件概率分布由以下公式确定:
二项逻辑斯蒂回归:是如下的条件概率分布:
P
(
Y
=
1
∣
x
)
=
exp
(
w
⋅
x
+
b
)
1
+
exp
(
w
⋅
x
+
b
)
P
(
Y
=
0
∣
x
)
=
1
1
+
exp
(
w
⋅
x
+
b
)
\begin{aligned} P(Y=1|x)=&\, \frac{\exp(w\cdot x+b)}{1+\exp(w\cdot x+b)} \\ P(Y=0|x)=&\, \frac{1}{1+\exp(w\cdot x+b)} \end{aligned}
P(Y=1∣x)=P(Y=0∣x)=1+exp(w⋅x+b)exp(w⋅x+b)1+exp(w⋅x+b)1
其中
x
∈
R
n
x\in\R^n
x∈Rn 是输入(实例),
Y
∈
{
0
,
1
}
Y\in\set{0,1}
Y∈{0,1} 是输出(标签值),
w
∈
R
n
w\in\R^n
w∈Rn 和
b
∈
R
b\in\R
b∈R 是参数。有时为了方便,将输入向量扩充为
x
=
(
x
(
1
)
,
x
(
2
)
,
⋯
,
x
(
n
)
,
1
)
T
x=(x^{(1)},x^{(2)},\cdots,x^{(n)},1)^T
x=(x(1),x(2),⋯,x(n),1)T ,权值扩充为
w
=
(
w
(
1
)
,
w
(
2
)
,
⋯
,
w
(
n
)
,
b
)
T
w=(w^{(1)},w^{(2)},\cdots,w^{(n)},b)^T
w=(w(1),w(2),⋯,w(n),b)T ,这样模型就可以写作:
P
(
Y
=
1
∣
x
)
=
exp
(
w
⋅
x
)
1
+
exp
(
w
⋅
x
)
P
(
Y
=
0
∣
x
)
=
1
1
+
exp
(
w
⋅
x
)
\begin{aligned} P(Y=1|x)=&\, \frac{\exp(w\cdot x)}{1+\exp(w\cdot x)} \\ P(Y=0|x)=&\, \frac{1}{1+\exp(w\cdot x)} \end{aligned}
P(Y=1∣x)=P(Y=0∣x)=1+exp(w⋅x)exp(w⋅x)1+exp(w⋅x)1
二项逻辑回归得到的是两个概率,代表该实例属于两个类别的概率分别是多少。
几率:一个事件的几率是指该事件发生的概率与该事件不发生的概率的比值,即
p
1
−
p
\frac{p}{1-p}
1−pp ;该事件的 对数几率 或 logit 函数为:
logit
(
p
)
=
log
p
1
−
p
\text{logit}(p)=\log\frac{p}{1-p}
logit(p)=log1−pp
对于二项逻辑回归而言,其对数几率为一个线性函数:
log
P
(
Y
=
1
∣
X
)
1
−
P
(
Y
=
1
∣
X
)
=
w
⋅
x
\log \frac{P(Y=1|X)}{1-P(Y=1|X)}=w\cdot x
log1−P(Y=1∣X)P(Y=1∣X)=w⋅x
模型参数估计:使用极大似然估计法,对于给定的数据集
T
=
{
(
x
1
,
y
x
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
)
}
T=\set{(x_1,y_x),(x_2,y_2),\cdots,(x_N,y_N)}
T={(x1,yx),(x2,y2),⋯,(xN,yN)} ,设:
P
(
Y
=
1
∣
x
)
=
π
(
x
)
,
P
(
Y
=
0
∣
x
)
=
1
−
π
(
x
)
P(Y=1|x)=\pi(x),\quad P(Y=0|x)=1-\pi(x)
P(Y=1∣x)=π(x),P(Y=0∣x)=1−π(x)
则似然函数为:
∏
i
=
1
N
[
π
(
x
i
)
]
y
i
[
1
−
π
(
x
i
)
]
1
−
y
i
\prod_{i=1}^{N}[\pi(x_i)]^{y_i}[1-\pi(x_i)]^{1-y_i}
i=1∏N[π(xi)]yi[1−π(xi)]1−yi
对数似然函数为:
L
(
w
)
=
∑
i
=
1
N
[
y
i
log
π
(
x
i
)
+
(
1
−
y
i
)
log
(
1
−
π
(
x
i
)
)
]
=
∑
i
=
1
N
[
y
i
log
π
(
x
i
)
1
−
π
(
x
i
)
+
log
(
1
−
π
(
x
i
)
)
]
=
∑
i
=
1
N
[
y
i
(
w
⋅
x
i
)
−
log
(
1
+
exp
(
w
⋅
x
i
)
)
]
\begin{aligned} L(w) =&\, \sum\limits_{i=1}^{N}[y_i\log \pi (x_i)+(1-y_i)\log(1-\pi(x_i))] \\ =&\, \sum\limits_{i=1}^{N}\left[ y_i \log\frac{\pi(x_i)}{1-\pi(x_i)}+\log(1-\pi(x_i)) \right] \\ =&\, \sum\limits_{i=1}^{N}[y_i (w\cdot x_i)-\log (1+\exp(w\cdot x_i))] \end{aligned}
L(w)===i=1∑N[yilogπ(xi)+(1−yi)log(1−π(xi))]i=1∑N[yilog1−π(xi)π(xi)+log(1−π(xi))]i=1∑N[yi(w⋅xi)−log(1+exp(w⋅xi))]
对
L
(
w
)
L(w)
L(w) 求极大值,得到
w
w
w 的估计值
w
^
\hat w
w^ 。逻辑斯蒂的最优化问题通常使用梯度下降法及拟牛顿法进行学习。
L
(
w
)
L(w)
L(w) 其实就是交叉熵函数的相反数,交叉熵函数可以写成:
loss
=
∑
i
=
1
N
(
y
i
log
y
^
i
+
(
1
−
y
i
)
log
(
^
1
−
y
i
)
)
\text{loss}=\sum\limits_{i=1}^{N}(y_i\log \hat y_i+(1-y_i)\log \hat (1-y_i))
loss=i=1∑N(yilogy^i+(1−yi)log(^1−yi))
其中
y
^
i
\hat y_i
y^i 为模型预测第
i
i
i 个实例属于正类的概率,即
π
(
x
i
)
\pi(x_i)
π(xi) ;
多项逻辑斯蒂回归
二项逻辑斯蒂回归推广到多项逻辑斯蒂回归,并不是使用 OVR 或 OVO 策略,而是从原理的角度进行推广。设
Y
Y
Y 的取值集合是
{
1
,
2
,
⋯
,
K
}
\set{1,2,\cdots,K}
{1,2,⋯,K} ,那么:
P
(
Y
=
k
∣
x
)
=
exp
(
w
k
⋅
x
)
1
+
∑
k
=
1
K
−
1
exp
(
w
k
⋅
x
)
,
k
=
1
,
2
,
⋯
,
K
−
1
P(Y=k|x)=\frac{\exp (w_k\cdot x)}{1+\sum\limits_{k=1}^{K-1}\exp{(w_k\cdot x})},\quad k=1,2,\cdots,K-1
P(Y=k∣x)=1+k=1∑K−1exp(wk⋅x)exp(wk⋅x),k=1,2,⋯,K−1
P
(
Y
=
K
∣
x
)
=
1
1
+
∑
k
=
1
K
−
1
exp
(
w
k
⋅
x
)
P(Y=K|x)=\frac{1}{1+\sum\limits_{k=1}^{K-1}\exp{(w_k\cdot x})}
P(Y=K∣x)=1+k=1∑K−1exp(wk⋅x)1
其中
x
∈
R
n
+
1
x\in \R^{n+1}
x∈Rn+1 ,
w
k
∈
R
n
+
1
w_k\in \R^{n+1}
wk∈Rn+1 ;
多项逻辑斯蒂回归的对数似然函数为:
L
(
w
)
=
∑
i
=
1
N
∑
k
=
1
K
I
(
y
i
=
k
)
log
P
(
Y
=
k
∣
x
i
)
L(w)=\sum\limits_{i=1}^{N}\sum\limits_{k=1}^{K}I(y_i=k)\log P(Y=k|x_i)
L(w)=i=1∑Nk=1∑KI(yi=k)logP(Y=k∣xi)
下面介绍的最大熵原理,运用在逻辑斯蒂回归中,就是极小化交叉熵,即极大化对数似然函数。(是吗)
最大熵模型
最大熵模型由最大熵原理推导实现。
原理
最大熵原理认为,学习概率模型时,在所有可能的概率模型(即概率分布)中,熵最大的模型是最好的模型。通常使用约束条件来确定可行的概率模型的集合,然后在满足约束条件的前提下选取熵最大的模型。最大熵模型最终学习到的实际上是一个条件概率分布,即 P ( Y ∣ X ) P(Y|X) P(Y∣X) ;
设离散随机变量
X
X
X 的概率分布是
P
(
X
)
P(X)
P(X) ,则熵为(之后的对数都是以
e
\text{e}
e 为底的):
H
(
P
)
=
−
∑
x
P
(
x
)
log
P
(
x
)
H(P)=-\sum\limits_{x}P(x)\log P(x)
H(P)=−x∑P(x)logP(x)
熵满足以下不等式:
0
≤
H
(
P
)
≤
log
∣
X
∣
0\leq H(P) \leq \log |X|
0≤H(P)≤log∣X∣
更直观地理解,最大熵原理的约束条件指的是概率分布徐需要满足已有的事实,在此基础上,其余不确定的部分都是“等可能”的,就可以令熵最大化。
例:设随机变量 X X X 有 5 个取值 { A , B , C , D , E } \set{A,\,B,\,C,\,D,\,E} {A,B,C,D,E} ,要估计各个取值的概率。
在没有任何约束条件的前提下,根据最大熵原理,我们应当估计为:
P
(
A
)
=
P
(
B
)
=
P
(
C
)
=
P
(
D
)
=
P
(
E
)
=
1
5
P(A)=P(B)=P(C)=P(D)=P(E)=\frac{1}{5}
P(A)=P(B)=P(C)=P(D)=P(E)=51
假设我们从先验知识中学习到了一些对概率值的约束条件,如:
P
(
A
)
+
P
(
B
)
=
3
10
P(A)+P(B)=\frac{3}{10}
P(A)+P(B)=103
则相应的估计应为:
P
(
A
)
=
P
(
B
)
=
3
20
P
(
C
)
=
P
(
D
)
=
P
(
E
)
=
7
30
\begin{aligned} P(A)=&\, P(B)=\frac{3}{20} \\ P(C)=&\, P(D)=P(E)=\frac{7}{30} \end{aligned}
P(A)=P(C)=P(B)=203P(D)=P(E)=307
定义
最大熵模型的推导:跟上面的例题一样,给定训练集:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
)
}
T=\set{(x_1,y_1),\,(x_2,y_2),\,\cdots,\,(x_N,y_N)}
T={(x1,y1),(x2,y2),⋯,(xN,yN)}
训练集中可以得到联合分布
P
(
X
,
Y
)
P(X,\,Y)
P(X,Y) 和边缘分布
P
(
X
)
P(X)
P(X) 的经验分布:
P
~
(
X
=
x
,
Y
=
y
)
=
ν
(
X
=
x
,
Y
=
y
)
N
P
~
(
X
=
x
)
=
ν
(
X
=
x
)
N
\begin{aligned} &\, \tilde P(X=x,Y=y)=\frac{\nu(X=x,Y=y)}{N} \\ &\, \tilde P(X=x)=\frac{\nu(X=x)}{N} \end{aligned}
P~(X=x,Y=y)=Nν(X=x,Y=y)P~(X=x)=Nν(X=x)
其中
ν
\nu
ν 表示频数,经验概率即为频率。
我们用特征函数
f
(
x
,
y
)
f(x,y)
f(x,y) 描述输入
x
x
x 和输出
y
y
y 之间的某一个事实,即:
f
(
x
,
y
)
=
{
1
,
x
与
y
满足某一事实
0
,
else
f(x,y)=\left\{ \begin{array}{ll} 1, & \text{$x$与$y$满足某一事实} \\ 0, & \text{else} \end{array} \right.
f(x,y)={1,0,x与y满足某一事实else
特征函数
f
(
x
,
y
)
f(x,y)
f(x,y) 关于经验分布
P
~
(
X
,
Y
)
\tilde P(X,Y)
P~(X,Y) 的期望值,为:
E
P
~
(
f
)
=
∑
x
,
y
P
~
(
x
,
y
)
f
(
x
,
y
)
E_{\tilde P}(f)=\sum\limits_{x,y}\tilde P(x,y)f(x,y)
EP~(f)=x,y∑P~(x,y)f(x,y)
特征函数
f
(
x
,
y
)
f(x,y)
f(x,y) 关于模型
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) 与经验分布
P
~
(
X
)
\tilde P(X)
P~(X) 的期望值,为:
E
P
(
f
)
=
∑
x
,
y
P
(
y
∣
x
)
P
~
(
x
)
f
(
x
,
y
)
E_P(f)=\sum\limits_{x,y}P(y|x)\tilde P(x)f(x,y)
EP(f)=x,y∑P(y∣x)P~(x)f(x,y)
如果这俩期望值是相等的,则说明模型能够获取训练数据中的信息,我们将该条件作为模型学习的约束条件:
E
P
(
f
)
=
E
P
~
(
f
)
E_P(f)=E_{\tilde P}(f)
EP(f)=EP~(f)
其中
f
f
f 是我们规定的特征函数。假如有
n
n
n 个特征函数,那么就有
n
n
n 个约束条件,每个特征函数描述了
x
x
x 与
y
y
y 的某一个特征。
其实我刚开始觉得有点奇怪,为什么是
P
~
(
x
,
y
)
\tilde P(x,y)
P~(x,y) 和
P
(
y
∣
x
)
P
~
(
x
)
P(y|x)\tilde P(x)
P(y∣x)P~(x) 比较,而不是把经验联合分布和经验边缘分布放在一起,然后变成
P
~
(
x
,
y
)
P
~
(
x
)
\frac{\tilde P(x,y)}{\tilde P(x)}
P~(x)P~(x,y) 和
P
(
y
∣
x
)
P(y|x)
P(y∣x) 比较;后面发现是因为根据特征函数的定义,需要
X
X
X 和
Y
Y
Y 的联合概率密度才能计算期望。但其实比较:
∑
x
,
y
P
~
(
x
,
y
)
P
~
(
x
)
f
(
x
,
y
)
=
?
∑
x
,
y
P
(
y
∣
x
)
f
(
x
,
y
)
\sum\limits_{x,y}\frac{\tilde P(x,y)}{\tilde P(x)}f(x,y) \overset{?}{=} \sum\limits_{x,y}P(y|x)f(x,y)
x,y∑P~(x)P~(x,y)f(x,y)=?x,y∑P(y∣x)f(x,y)
我觉得问题也不大,只是等式左右两边的值的含义不好解释。
最大熵模型:假设满足所有约束条件的模型集合为:
C
≡
{
P
∈
P
∣
E
P
(
f
i
)
=
E
P
~
(
f
i
)
,
i
=
1
,
2
,
⋯
,
n
}
\mathcal{C}\equiv \set{P\in \mathcal{P}|E_P(f_i)=E_{\tilde P}(f_i),\quad i=1,2,\cdots,n}
C≡{P∈P∣EP(fi)=EP~(fi),i=1,2,⋯,n}
定义在条件概率分布
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) 上的条件熵为:
H
(
P
)
=
−
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
H(P)=-\sum\limits_{x,y}\tilde P(x)P(y|x)\log P(y|x)
H(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)
则模型集合
C
\mathcal{C}
C 中条件熵
H
(
P
)
H(P)
H(P) 最大的模型称为最大熵模型。
学习
书上的求导过程有点怪,我按照自己的理解写一遍:
原始问题与对偶问题:对于给定的数据集
T
T
T 和若干特征函数
f
i
(
x
,
y
)
f_i(x,y)
fi(x,y) ,
i
=
1
,
2
,
⋯
,
n
i=1,2,\cdots,n
i=1,2,⋯,n ,最大熵模型的学习等价于如下约束最优化问题:
max
P
∈
C
H
(
P
)
=
−
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
s.t.
E
P
(
f
i
)
=
E
P
~
(
f
i
)
,
i
=
1
,
2
,
⋯
,
n
∑
y
P
(
y
∣
x
)
=
1
,
x
∈
T
x
\begin{aligned} \max_{P\in\mathcal{C}}&\,H(P)=-\sum\limits_{x,y}\tilde P(x)P(y|x)\log P(y|x) \\ \text{s.t.}&\,\, E_P(f_i)=E_{\tilde P}(f_i),\quad i=1,2,\cdots,n \\ &\,\, \sum\limits_{y}P(y|x)=1, \quad x\in T_x \end{aligned}
P∈Cmaxs.t.H(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)EP(fi)=EP~(fi),i=1,2,⋯,ny∑P(y∣x)=1,x∈Tx
第二个约束条件对于训练集中的每个
x
x
x 都成立,但这样求解起来很麻烦。我们发现
∑
y
P
(
y
∣
x
)
=
1
\sum\limits_{y}P(y|x)=1
y∑P(y∣x)=1 的约束条件对某个
x
x
x 有效,(以下内容是我自己的猜想,这样拆开后的约束条件会比原来的更严格)假设
E
P
(
f
i
)
=
E
P
~
(
f
i
)
E_P(f_i)=E_{\tilde P}(f_i)
EP(fi)=EP~(fi) 的约束条件也可以拆成对每个
x
x
x 分别成立:
E
P
(
f
i
(
x
)
)
=
∑
y
P
~
(
x
,
y
)
f
(
x
,
y
)
=
∑
y
P
(
y
∣
x
)
P
~
(
x
)
f
(
x
,
y
)
=
E
P
~
(
f
i
(
x
)
)
E_{P}(f_i(x))=\sum\limits_{y}\tilde P(x,y)f(x,y)=\sum\limits_{y}P(y|x)\tilde P(x)f(x,y)=E_{\tilde P}(f_i(x))
EP(fi(x))=y∑P~(x,y)f(x,y)=y∑P(y∣x)P~(x)f(x,y)=EP~(fi(x))
则对于每个
x
x
x ,都可以得到如下的子问题:
max
P
∈
C
H
x
(
P
)
=
−
∑
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
s.t.
E
P
(
f
i
(
x
)
)
=
E
P
~
(
f
i
(
x
)
)
,
i
=
1
,
2
,
⋯
,
n
∑
y
P
(
y
∣
x
)
=
1
\begin{aligned} \max_{P\in\mathcal{C}}&\,H_x(P)=-\sum\limits_{y}\tilde P(x)P(y|x)\log P(y|x) \\ \text{s.t.}&\,\, E_P(f_i(x))=E_{\tilde P}(f_i(x)),\quad i=1,2,\cdots,n \\ &\,\, \sum\limits_{y}P(y|x)=1 \end{aligned}
P∈Cmaxs.t.Hx(P)=−y∑P~(x)P(y∣x)logP(y∣x)EP(fi(x))=EP~(fi(x)),i=1,2,⋯,ny∑P(y∣x)=1
而原始问题的目标函数正好是所有子问题的目标函数的和,那么对每个子问题求极大值,就可以得到全局的极大值。因此,我们以下仅对某个子问题进行求解。
要转化为对偶问题,我们要将原始问题变为极小问题
min
P
∈
C
−
H
x
(
P
)
\min\limits_{P\in \mathcal{C}}-H_x(P)
P∈Cmin−Hx(P) ,然后引入拉格朗日乘子
w
0
w_0
w0 ,
w
1
w_1
w1 ,
⋯
\cdots
⋯ ,
w
n
w_n
wn ,得到 Lagrangian 为:
L
x
(
P
,
w
)
≡
−
H
x
(
P
)
+
w
0
(
1
−
∑
y
P
(
y
∣
x
)
)
+
∑
i
=
1
n
w
i
[
E
P
~
(
f
i
(
x
)
)
−
E
P
(
f
i
(
x
)
)
]
=
∑
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
+
w
0
(
1
−
∑
y
P
(
y
∣
x
)
)
+
∑
i
=
1
n
w
i
(
∑
y
P
~
(
x
,
y
)
f
i
(
x
,
y
)
−
∑
y
P
(
y
∣
x
)
P
~
(
x
)
f
i
(
x
,
y
)
)
\begin{aligned} L_x(P,w)\equiv &\, -H_x(P)+w_0\left(1-\sum\limits_{y}P(y|x)\right) +\sum\limits_{i=1}^{n}w_i[E_{\tilde P}(f_i(x))-E_{P}(f_i(x))] \\ =&\, \sum\limits_{y}\tilde P(x)P(y|x)\log P(y|x) +w_0\left(1-\sum\limits_{y}P(y|x)\right) \\ +&\, \sum\limits_{i=1}^{n}w_i\left( \sum\limits_{y}\tilde P(x,y)f_i(x,y) -\sum\limits_{y}P(y|x)\tilde P(x)f_i(x,y) \right) \end{aligned}
Lx(P,w)≡=+−Hx(P)+w0(1−y∑P(y∣x))+i=1∑nwi[EP~(fi(x))−EP(fi(x))]y∑P~(x)P(y∣x)logP(y∣x)+w0(1−y∑P(y∣x))i=1∑nwi(y∑P~(x,y)fi(x,y)−y∑P(y∣x)P~(x)fi(x,y))
原始的最优化问题为:
min
P
∈
C
max
w
L
x
(
P
,
w
)
\min\limits_{P\in \mathcal{C}} \max\limits_{w} L_x(P,w)
P∈CminwmaxLx(P,w)
对偶问题为:
max
w
min
P
∈
C
L
x
(
P
,
w
)
\max\limits_{w} \min\limits_{P\in\mathcal{C}} L_x(P,w)
wmaxP∈CminLx(P,w)
(这样每个子问题求解出来的其实只是
P
P
P 的一部分,即
P
(
Y
∣
x
)
P(Y|x)
P(Y∣x) ,只需要对所有的子问题求解即可)
对偶问题求解: L x L_x Lx 是 P P P 的凸函数,主要看 P ( y ∣ x ) log P ( y ∣ x ) P(y|x)\log P(y|x) P(y∣x)logP(y∣x) ,即 f ( x ) = x ln x f(x)=x\ln x f(x)=xlnx ,它是个凸函数;而后边的线性部分不影响凹凸性。所以我们可以通过求解对偶问题赖求解原始问题。
- 首先,求 min P ∈ C L x ( P , w ) \min\limits_{P\in\mathcal{C}} L_x(P,w) P∈CminLx(P,w) ,记:
Ψ x ( w ) = min P ∈ C L x ( P , w ) \Psi_x(w)=\min\limits_{P\in\mathcal{C}} L_x(P,w) Ψx(w)=P∈CminLx(P,w)
称
Ψ
(
w
)
\Psi(w)
Ψ(w) 为对偶函数。同时,将其解记为:
P
w
=
arg
min
P
∈
C
L
x
(
P
,
w
)
=
P
w
(
Y
∣
x
)
P_w=\arg \min\limits_{P\in\mathcal{C}} L_x(P,w) =P_w(Y|x)
Pw=argP∈CminLx(P,w)=Pw(Y∣x)
FOC 为:
∂
L
x
(
P
,
w
)
∂
P
(
y
∣
x
)
=
P
~
(
x
)
(
log
P
(
y
∣
x
)
+
1
)
−
w
0
−
P
~
(
x
)
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
=
P
~
(
x
)
(
log
P
(
y
∣
x
)
+
1
−
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
−
w
0
=
0
\begin{aligned} \frac{\partial L_x(P,w)}{\partial P(y|x)} =&\,\tilde P(x)(\log P(y|x)+1)- w_0 -\tilde P(x)\sum\limits_{i=1}^{n}w_if_i(x,y) \\ =&\,\tilde P(x) \left( \log P(y|x)+1-\sum\limits_{i=1}^{n}w_if_i(x,y) \right)-w_0 \\ =&\, 0 \end{aligned}
∂P(y∣x)∂Lx(P,w)===P~(x)(logP(y∣x)+1)−w0−P~(x)i=1∑nwifi(x,y)P~(x)(logP(y∣x)+1−i=1∑nwifi(x,y))−w00
解得:
P
(
y
∣
x
)
=
exp
(
w
0
P
~
(
x
)
−
1
+
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
=
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
exp
(
1
−
w
0
P
~
(
x
)
)
P(y|x)=\exp\left( \frac{w_0}{\tilde P(x)}-1+\sum\limits_{i=1}^{n}w_if_i(x,y) \right)=\frac{\exp\left( \sum\limits_{i=1}^{n}w_if_i(x,y) \right)}{\exp(1-\frac{w_0}{\tilde P(x)})}
P(y∣x)=exp(P~(x)w0−1+i=1∑nwifi(x,y))=exp(1−P~(x)w0)exp(i=1∑nwifi(x,y))
由于需要满足约束条件
∑
y
P
(
y
∣
x
)
=
1
\sum\limits_{y}P(y|x)=1
y∑P(y∣x)=1 ,即对所有的
y
y
y 求和为一,那么上式中分子对
y
y
y 求和也等于分母,因此我们可以写做:
P
w
(
y
∣
x
)
=
1
Z
w
(
x
)
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
P_w(y|x)=\frac{1}{Z_w(x)}\exp\left( \sum\limits_{i=1}^{n}w_if_i(x,y) \right)
Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
其中
Z
w
(
x
)
Z_w(x)
Zw(x) 被称为规范化因子 :
Z
w
(
x
)
=
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
Z_w(x)=\sum\limits_{y}\exp\left( \sum\limits_{i=1}^{n}w_if_i(x,y) \right)
Zw(x)=y∑exp(i=1∑nwifi(x,y))
- 再求 max w ( min P ∈ C L x ( P , w ) ) \max\limits_{w} ( \min\limits_{P\in\mathcal{C}} L_x(P,w)) wmax(P∈CminLx(P,w)) :将所有的 P w ( Y ∣ x ) P_w(Y|x) Pw(Y∣x) 代入原始问题,得到所有子问题的对偶函数之和 Ψ ( w ) \Psi(w) Ψ(w) ,再求:
max w Ψ ( w ) \max_{w} \Psi(w) wmaxΨ(w)
将其解记为
w
∗
w^\ast
w∗ ,即:
w
∗
=
arg
max
w
Ψ
(
w
)
w^\ast =\arg \max_{w} \Psi(w)
w∗=argwmaxΨ(w)
由于前面得到的
P
w
(
Y
∣
X
)
P_w(Y|X)
Pw(Y∣X) 是解析解,因此最大熵模型的学习可以直接归结为对偶函数
Ψ
(
w
)
\Psi(w)
Ψ(w)
的极大化。
例:设随机变量
Y
Y
Y 有 5 个取值
{
y
1
,
y
2
,
y
3
,
y
4
,
y
5
}
\set{y_1,\,y_2,\,y_3,\,y_4,\,y_5}
{y1,y2,y3,y4,y5} ,且有约束条件:
P
~
(
y
1
)
+
P
~
(
y
2
)
=
3
10
\tilde P(y_1)+\tilde P(y_2)=\frac{3}{10}
P~(y1)+P~(y2)=103
使用最大熵模型估计各个取值的概率。
书上这个例题选得简单,但是太过简单了也不好,因为:
- 这里可以认为 X X X 只有一种取值,先验概率 P ~ ( X ) = 1 \tilde P(X)=1 P~(X)=1 ,因此要学习的 P ( Y ∣ X ) P(Y|X) P(Y∣X) 其实就是 P ( Y ) P(Y) P(Y) ;
- 这个问题的特征函数 f ( x , y ) f(x,y) f(x,y) 我也写不出来。。。
所以我也没法根据这个例题看懂最大熵模型学习的推导过程(悲);
该问题使用最大熵模型学习的最优化问题为:
min
P
∈
C
−
H
(
P
)
=
∑
i
=
1
5
P
(
y
i
)
log
P
(
y
i
)
s.t.
P
(
y
1
)
+
P
(
y
2
)
=
P
~
(
y
1
)
+
P
~
(
y
2
)
=
3
10
∑
i
=
1
5
P
(
y
i
)
=
1
\begin{aligned} \min_{P\in\mathcal{C}}&\,-H(P)=\sum\limits_{i=1}^5P(y_i)\log P(y_i) \\ \text{s.t.}&\,\, P(y_1)+P(y_2)=\tilde P(y_1)+\tilde P(y_2)=\frac{3}{10}\\ &\,\, \sum\limits_{i=1}^{5}P(y_i)=1 \end{aligned}
P∈Cmins.t.−H(P)=i=1∑5P(yi)logP(yi)P(y1)+P(y2)=P~(y1)+P~(y2)=103i=1∑5P(yi)=1
其 Lagrangian 为:
L
(
P
,
w
)
=
∑
i
=
1
5
P
(
y
i
)
log
P
(
y
i
)
+
w
0
(
1
−
∑
i
=
1
5
P
(
y
i
)
)
+
w
1
(
3
10
−
P
(
y
1
)
−
P
(
y
2
)
)
L(P,w)=\sum\limits_{i=1}^5P(y_i)\log P(y_i)+w_0\left(1-\sum\limits_{i=1}^{5}P(y_i) \right)+w_1(\frac{3}{10}-P(y_1)-P(y_2))
L(P,w)=i=1∑5P(yi)logP(yi)+w0(1−i=1∑5P(yi))+w1(103−P(y1)−P(y2))
FOC 为:
∂
L
(
P
,
w
)
∂
P
(
y
1
)
=
log
P
(
y
1
)
+
1
−
w
0
−
w
1
=
0
∂
L
(
P
,
w
)
∂
P
(
y
2
)
=
log
P
(
y
2
)
+
1
−
w
0
−
w
1
=
0
∂
L
(
P
,
w
)
∂
P
(
y
3
)
=
log
P
(
y
3
)
+
1
−
w
0
=
0
∂
L
(
P
,
w
)
∂
P
(
y
4
)
=
log
P
(
y
4
)
+
1
−
w
0
=
0
∂
L
(
P
,
w
)
∂
P
(
y
5
)
=
log
P
(
y
5
)
+
1
−
w
0
=
0
\begin{aligned} \frac{\partial L(P,w)}{\partial P(y_1)}=&\, \log P(y_1)+1-w_0-w_1=0 \\ \frac{\partial L(P,w)}{\partial P(y_2)}=&\, \log P(y_2)+1-w_0-w_1=0 \\ \frac{\partial L(P,w)}{\partial P(y_3)}=&\, \log P(y_3)+1-w_0=0 \\ \frac{\partial L(P,w)}{\partial P(y_4)}=&\, \log P(y_4)+1-w_0=0 \\ \frac{\partial L(P,w)}{\partial P(y_5)}=&\, \log P(y_5)+1-w_0=0 \\ \end{aligned}
∂P(y1)∂L(P,w)=∂P(y2)∂L(P,w)=∂P(y3)∂L(P,w)=∂P(y4)∂L(P,w)=∂P(y5)∂L(P,w)=logP(y1)+1−w0−w1=0logP(y2)+1−w0−w1=0logP(y3)+1−w0=0logP(y4)+1−w0=0logP(y5)+1−w0=0
解得:
P
(
y
1
)
=
P
(
y
2
)
=
e
w
0
+
w
1
−
1
P
(
y
3
)
=
P
(
y
4
)
=
P
(
y
5
)
=
e
w
0
−
1
\begin{aligned} P(y_1)=&\, P(y_2)=\mathrm{e}^{w_0+w_1-1} \\ P(y_3)=&\, P(y_4)=P(y_5)=\mathrm{e}^{w_0-1} \end{aligned}
P(y1)=P(y3)=P(y2)=ew0+w1−1P(y4)=P(y5)=ew0−1
比较前面学习算法的解析解,我认为特征函数应当写成:(这个问题只有一个特征函数)
f
(
y
)
=
{
1
y
∈
{
y
1
,
y
2
}
0
else
f(y)=\left\{ \begin{array}{l} 1 & y\in\set{y_1,y_2} \\ 0 & \text{else} \end{array} \right.
f(y)={10y∈{y1,y2}else
代入
P
w
(
y
)
P_w(y)
Pw(y) ,得到特征函数为:
Ψ
(
w
)
=
−
2
e
w
0
+
w
1
−
1
−
3
e
w
0
−
1
+
w
0
+
3
10
w
1
\Psi(w)=-2\mathrm{e}^{w_0+w_1-1}-3\mathrm{e}^{w_0-1}+w_0+\frac{3}{10}w_1
Ψ(w)=−2ew0+w1−1−3ew0−1+w0+103w1
求
Ψ
(
w
)
\Psi(w)
Ψ(w) 的极大值,FOC 为:
∂
Ψ
∂
w
0
=
−
2
e
w
0
+
w
1
−
1
−
3
e
w
0
−
1
+
1
=
0
∂
Ψ
∂
w
1
=
−
2
e
w
0
+
w
1
−
1
+
3
10
=
0
\begin{aligned} \frac{\partial \Psi}{\partial w_0}=&\, -2\mathrm{e}^{w_0+w_1-1}-3\mathrm{e}^{w_0-1}+1=0 \\ \frac{\partial \Psi}{\partial w_1}=&\, -2\mathrm{e}^{w_0+w_1-1}+\frac{3}{10}=0 \end{aligned}
∂w0∂Ψ=∂w1∂Ψ=−2ew0+w1−1−3ew0−1+1=0−2ew0+w1−1+103=0
解得:
e
w
0
+
w
1
−
1
=
3
10
,
e
w
0
−
1
=
7
30
\mathrm{e}^{w_0+w_1-1}=\frac{3}{10},\quad \mathrm{e}^{w_0-1}=\frac{7}{30}
ew0+w1−1=103,ew0−1=307
因此学习到的概率分布为:
P
(
y
1
)
=
P
(
y
2
)
=
3
10
P
(
y
3
)
=
P
(
y
4
)
=
P
(
y
5
)
=
7
30
\begin{aligned} P(y_1)=&\, P(y_2)=\frac{3}{10} \\ P(y_3)=&\, P(y_4)=P(y_5)=\frac{7}{30} \end{aligned}
P(y1)=P(y3)=P(y2)=103P(y4)=P(y5)=307
极大似然估计
下面证明对偶函数的极大化等价于最大熵模型的极大似然估计。
已知训练数据的经验概率分布
P
~
(
X
,
Y
)
\tilde P(X,Y)
P~(X,Y) ,条件概率分布
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) 的对数似然函数为:
L
P
~
(
P
w
)
=
log
∏
x
,
y
P
(
y
∣
x
)
P
~
(
x
,
y
)
=
∑
x
,
y
P
~
(
x
,
y
)
log
P
(
y
∣
x
)
L_{\tilde P}(P_w)=\log \prod\limits_{x,y}P(y|x)^{\tilde P(x,y)}=\sum\limits_{x,y}\tilde P(x,y)\log P(y|x)
LP~(Pw)=logx,y∏P(y∣x)P~(x,y)=x,y∑P~(x,y)logP(y∣x)
理解一下这里的对数似然函数的形式。以前的话,比如对于某个离散型随机变量 X X X 的分布的参数估计,我们抽取一些样本 T = { x 1 , x 2 , ⋯ , x n } T=\set{x_1,x_2,\cdots,x_n} T={x1,x2,⋯,xn} ;则常见的对数似然函数为:
L ( x , θ ) = log ∏ i = 1 n P ( X = x i ) L(x,\theta)=\log \prod_{i=1}^{n}P(X=x_i) L(x,θ)=logi=1∏nP(X=xi)
但是,由于 X X X 是离散的,有可数种取值情况,因此也可以写成:
L ( x , θ ) = log ∏ x P ( X = x ) v ( x ) L(x,\theta)=\log \prod _{x}P(X=x)^{v(x)} L(x,θ)=logx∏P(X=x)v(x)
其中 v ( x ) v(x) v(x) 为 x x x 在样本 T T T 中出现的频率。两边开 n n n 次方得到:
L ( x , θ ) 1 n = log ∏ x P ( X = x ) v ( x ) n = log ∏ x P ( X = x ) P ~ ( X = x ) L(x,\theta)^{\frac{1}{n}}=\log \prod_{x}P(X=x)^\frac{v(x)}{n}=\log \prod_{x}P(X=x)^{\tilde P(X=x)} L(x,θ)n1=logx∏P(X=x)nv(x)=logx∏P(X=x)P~(X=x)
对 L ( x , θ ) 1 n L(x,\theta)^{\frac{1}{n}} L(x,θ)n1 求极值和对 L ( x , θ ) L(x,\theta) L(x,θ) 求极值是一样的,因此对数似然函数带有指数的形式。
同样地,我们将极大似然估计按照
x
x
x 的取值不同分为不同的子函数:
L
P
~
(
P
w
(
x
)
)
=
∑
y
P
~
(
x
,
y
)
log
P
(
y
∣
x
)
L_{\tilde P}(P_w(x))=\sum\limits_{y}\tilde P(x,y)\log P(y|x)
LP~(Pw(x))=y∑P~(x,y)logP(y∣x)
当条件概率分布
P
(
y
∣
x
)
P(y|x)
P(y∣x) 是最大熵模型时,即:
P
w
(
y
∣
x
)
=
1
Z
w
(
x
)
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
P_w(y|x)=\frac{1}{Z_w(x)}\exp\left( \sum\limits_{i=1}^{n}w_if_i(x,y) \right)
Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
此时对数似然函数为:
L
P
~
(
P
w
(
x
)
)
=
∑
y
P
~
(
x
,
y
)
log
P
w
(
y
∣
x
)
=
∑
y
P
~
(
x
,
y
)
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
−
∑
y
P
~
(
x
,
y
)
log
Z
w
(
x
)
\begin{aligned} L_{\tilde P}(P_w(x)) =&\,\sum\limits_{y}\tilde P(x,y)\log P_w(y|x) \\ =&\,\sum\limits_{y}\tilde P(x,y)\sum\limits_{i=1}^{n}w_if_i(x,y)-\sum\limits_{y}\tilde P(x,y)\log Z_w(x) \end{aligned}
LP~(Pw(x))==y∑P~(x,y)logPw(y∣x)y∑P~(x,y)i=1∑nwifi(x,y)−y∑P~(x,y)logZw(x)
而对偶函数为:
Ψ x ( w ) = ∑ y P ~ ( x ) P w ( y ∣ x ) log P w ( y ∣ x ) + ∑ i = 1 n w i ( ∑ y P ~ ( x , y ) f i ( x , y ) − ∑ y P w ( y ∣ x ) P ~ ( x ) f i ( x , y ) ) = ∑ y P ~ ( x , y ) ∑ i = 1 n w i f i ( x , y ) + ∑ y P ~ ( x ) P w ( y ∣ x ) ( log P w ( y ∣ x ) − ∑ i = 1 n w i f i ( x , y ) ) = ∑ y P ~ ( x , y ) ∑ i = 1 n w i f i ( x , y ) − ∑ y P ~ ( x ) P w ( y ∣ x ) log Z w ( x ) = ∑ y P ~ ( x , y ) ∑ i = 1 n w i f i ( x , y ) − ∑ y P ~ ( x , y ) log Z w ( x ) \begin{aligned} \Psi_x(w) =&\, \sum\limits_{y}\tilde P(x)P_w(y|x)\log P_w(y|x) + \\ &\, \sum\limits_{i=1}^{n}w_i\left( \sum\limits_{y}\tilde P(x,y)f_i(x,y) -\sum\limits_{y}P_w(y|x)\tilde P(x)f_i(x,y) \\ \right) \\ =&\, \sum\limits_{y}\tilde P(x,y)\sum\limits_{i=1}^{n}w_if_i(x,y) +\sum\limits_{y}\tilde P(x)P_w(y|x)\left( \log P_w(y|x)-\sum\limits_{i=1}^{n}w_if_i(x,y)\right) \\ =&\, \sum\limits_{y}\tilde P(x,y)\sum\limits_{i=1}^{n}w_if_i(x,y) -\sum\limits_{y}\tilde P(x)P_w(y|x)\log Z_w(x) \\ =&\, \sum\limits_{y}\tilde P(x,y)\sum\limits_{i=1}^{n}w_if_i(x,y) -\sum\limits_{y}\tilde P(x,y)\log Z_w(x) \\ \end{aligned} Ψx(w)====y∑P~(x)Pw(y∣x)logPw(y∣x)+i=1∑nwi(y∑P~(x,y)fi(x,y)−y∑Pw(y∣x)P~(x)fi(x,y))y∑P~(x,y)i=1∑nwifi(x,y)+y∑P~(x)Pw(y∣x)(logPw(y∣x)−i=1∑nwifi(x,y))y∑P~(x,y)i=1∑nwifi(x,y)−y∑P~(x)Pw(y∣x)logZw(x)y∑P~(x,y)i=1∑nwifi(x,y)−y∑P~(x,y)logZw(x)
- 第二个等号并没有代入 P w ( y ∣ x ) P_w(y|x) Pw(y∣x) ,而是对原有的项进行排列组合以方便计算;
- 第三个等号代入了最后的 $ \log P_w(y|x)$ ;
- 最后一个等号是在满足约束条件的情况下满足的;
因此可以得到:
Ψ
(
w
)
=
L
P
~
(
P
w
)
\Psi(w)=L_{\tilde P}(P_w)
Ψ(w)=LP~(Pw)
最大熵模型与逻辑回归的学习都可以归结为以似然函数为目标的最优化问题,其学习通常通过迭代法求解,因为目标函数(似然函数)是光滑的凸函数。常见的方法还有:迭代尺度法、梯度下降法、牛顿法或拟牛顿法。
最大熵模型与逻辑回归具有类似的形式,都称为对数线性模型(log linear model) ,该模型的学习就是在给定训练数据条件下对模型进行极大似然估计或正则化的极大似然估计。




![[免费] 适用于 Windows的10 的十大数据恢复软件](https://img-blog.csdnimg.cn/58570ee6ac6c43319b84ee98c8546533.png)