在进行一个新项目的时候,往往缺少一些真实数据,导致没办法进行模型训练,这时候就需要算法工程师自行制作一些数据了,比如这篇文章分享的 bag 目标检测,在检测区域没有真实的 bag数据
此时,就可以采用图像拼接的方式将凑集到的 bag图像粘贴到场景图像中【前提,目标图一般为“大头贴”】,当然场景图片并不是所有的位置都可以粘贴,一般有特定区域,比如 地面、墙壁、某设备等,因此还需要采用标注工具将这些目标区域标注出来,算法通过读取对应的目标区域,随机设定区域内的坐标点进行粘贴,将目标图粘贴到场景图当中
当然并不是任何形式的目标图都可以粘贴,为了更好的融合场景当中,还需要将目标从 大头贴当中给 扣出来,即除了目标区域,其他区域设置为透明格式,这样拼接的效果才“更”加真实一些【还是很假的!!!】
具体的操作过程如何所示,代码附最后,如有 bug 还望见谅!
1、制作底片模版
博主采用的 LabelImg标注工具,将底片待粘贴区域标注好
标注完成的 txt 内容
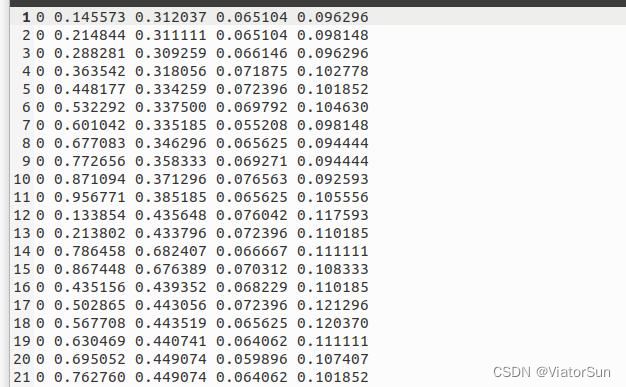
labelImg 的显示界面

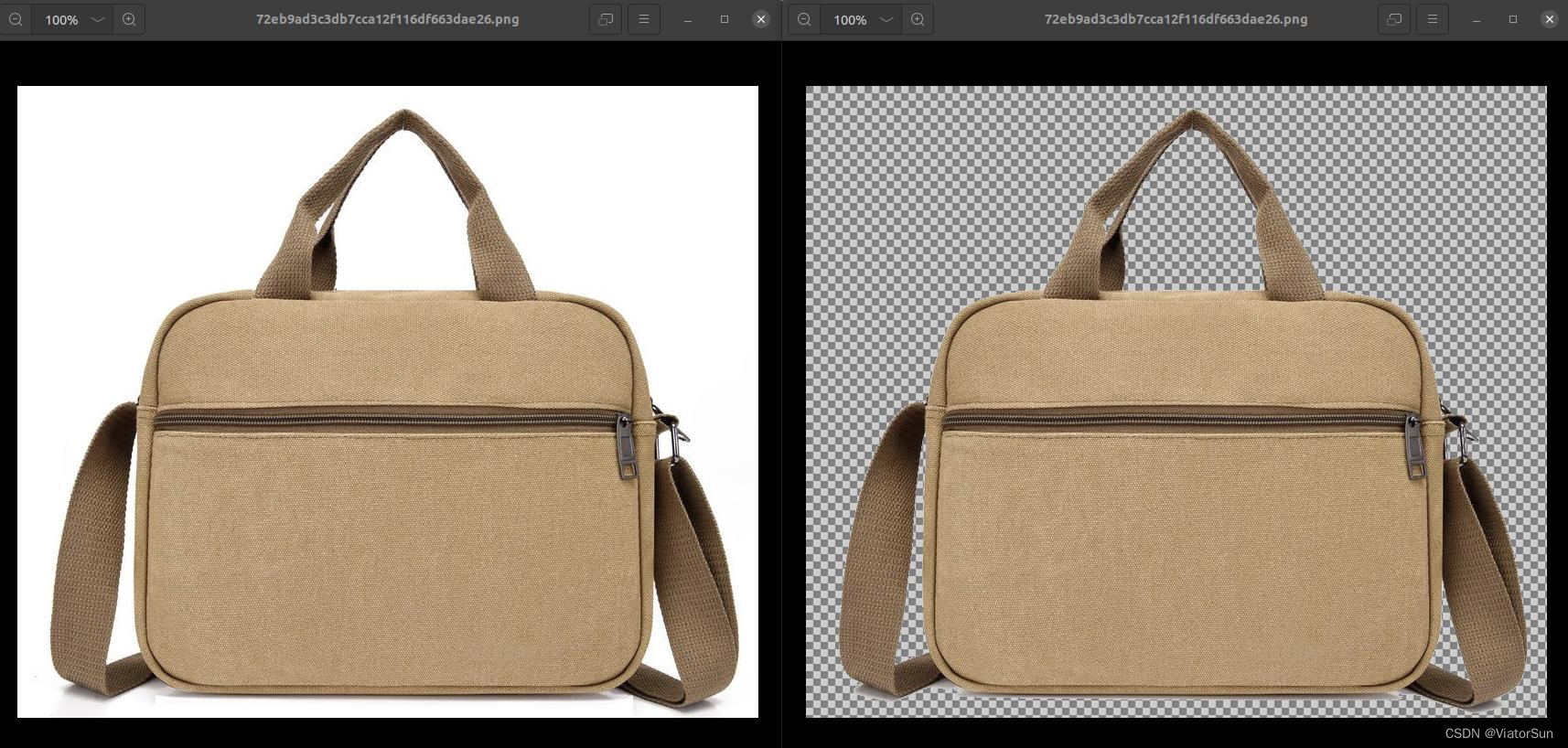
2、将对应的大头贴目标头图处理
从 jpg 图像将目标 “扣” 出来,此处采用的像素抠图,将白色区域设置为透明,此处并不通用,不同目标的小伙伴自行修改代码,png的图像格式可以保存 alpha通道
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2023.11
# @Author : 绿色羽毛
# @Email : lvseyumao@foxmail.com
# @Blog : https://blog.csdn.net/ViatorSun
# @Note : jpg2png.py
import os
import cv2
import numpy as np
import os.path as osp
file_path = "/media/yinzhe/DataYZ/DataSet/DataSet/bag_masknew"
save_path = file_path + "_out"
if not osp.exists(save_path):
os.makedirs(save_path)
img_lst = []
for path, dirs, files in os.walk(file_path):
for file in files:
if os.path.splitext(file)[1] in ['.jpg', ".png", ".JPG", ".jpeg"]: # 扫描指定格式文件
img_dir = osp.join(path, file)
img_save = osp.join(save_path, file)
img = cv2.imread(img_dir)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 转换为RGB格式
png_img = osp.join(save_path, file.split(".")[0] + ".png")
white_mask = cv2.inRange(img, (200, 200, 200), (255, 255, 255)) # 提取白色部分
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGRA)
img[:,:,3][white_mask == 255] = 0 # 将白色部分变成透明
cv2.imwrite(png_img, img)
3、将底片与透明目标进行叠加融合
叠加融合的方法有很多种,此处只采用了最简单的叠加方式,也可以考虑 cv2.seamlessClone
最终成果如下图所示

除了生成合成图片,标注信息也同步生成

注意! 此处的标注信息是按照标注框尺寸保存的【此处隐藏bug后续优化】
提示:可以根据目标区域的非透明区域进行保存

# !/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2023.10
# @Author : 绿色羽毛
# @Email : lvseyumao@foxmail.com
# @Blog : https://blog.csdn.net/ViatorSun
# @Note : ps_merge_img.py
import os
import cv2
import random
from random import sample
import numpy as np
import argparse
def read_label_txt(label_dir):
labels = []
with open(label_dir) as fp:
for f in fp.readlines():
labels.append(f.strip().split(' '))
return labels
def rescale_yolo_labels(labels, img_shape):
height, width, nchannel = img_shape
rescale_boxes = []
for box in list(labels):
x_c = float(box[1]) * width
y_c = float(box[2]) * height
w = float(box[3]) * width
h = float(box[4]) * height
x_left = x_c - w * .5
y_left = y_c - h * .5
x_right = x_c + w * .5
y_right = y_c + h * .5
rescale_boxes.append([box[0], int(x_left), int(y_left), int(x_right), int(y_right)])
return rescale_boxes
def xyxy2xywh(image, bboxes):
height, width, _ = image.shape
boxes = []
for box in bboxes:
if len(box) < 4:
continue
cls = int(box[0])
x_min = box[1]
y_min = box[2]
x_max = box[3]
y_max = box[4]
w = x_max - x_min
h = y_max - y_min
x_c = (x_min + x_max) / 2.0
y_c = (y_min + y_max) / 2.0
x_c = x_c / width
y_c = y_c / height
w = float(w) / width
h = float(h) / height
boxes.append([cls, x_c, y_c, w, h])
return boxes
def cast_color(img, value):
img_t = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
h,s,v = cv2.split(img_t)
# 增加图像对比度
v2 = np.clip(cv2.add(2*v,value),0,255)
img2 = np.uint8(cv2.merge((h,s,v2)))
img_cast = cv2.cvtColor(img2,cv2.COLOR_HSV2BGR) # 改变图像对比度
return img_cast
def brightness(img, value):
img_t = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
h,s,v = cv2.split(img_t)
# 增加图像亮度
v1 = np.clip(cv2.add(1*v,value),0,255)
img1 = np.uint8(cv2.merge((h,s,v1)))
img_brightness = cv2.cvtColor(img1,cv2.COLOR_HSV2BGR) # 改变图像亮度亮度
return img_brightness
def add_alpha_channel(img):
""" 为jpg图像添加alpha通道 """
b_channel, g_channel, r_channel = cv2.split(img) # 拆分jpg图像通道
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255 # 创建Alpha通道
img_new = cv2.merge((b_channel, g_channel, r_channel, alpha_channel)) # 融合通道
return img_new
def merge_img(jpg_img, png_img, y1, y2, x1, x2):
""" 将png透明图像与jpg图像叠加
y1,y2,x1,x2为叠加位置坐标值
"""
# 判断jpg图像是否已经为4通道
if jpg_img.shape[2] == 3:
jpg_img = add_alpha_channel(jpg_img)
'''
当叠加图像时,可能因为叠加位置设置不当,导致png图像的边界超过背景jpg图像,而程序报错
这里设定一系列叠加位置的限制,可以满足png图像超出jpg图像范围时,依然可以正常叠加
'''
yy1 = 0
yy2 = png_img.shape[0]
xx1 = 0
xx2 = png_img.shape[1]
if x1 < 0:
xx1 = -x1
x1 = 0
if y1 < 0:
yy1 = - y1
y1 = 0
if x2 > jpg_img.shape[1]:
xx2 = png_img.shape[1] - (x2 - jpg_img.shape[1])
x2 = jpg_img.shape[1]
if y2 > jpg_img.shape[0]:
yy2 = png_img.shape[0] - (y2 - jpg_img.shape[0])
y2 = jpg_img.shape[0]
# 获取要覆盖图像的alpha值,将像素值除以255,使值保持在0-1之间
alpha_png = png_img[yy1:yy2, xx1:xx2, 3] / 255.0
alpha_jpg = 1 - alpha_png
# 开始叠加
for c in range(0, 3):
jpg_img[y1:y2, x1:x2, c] = ((alpha_jpg * jpg_img[y1:y2, x1:x2, c]) + (alpha_png * png_img[yy1:yy2, xx1:xx2, c]))
return jpg_img
def random_add_patches_on_objects(image, mask_lst, rescale_boxes, paste_number):
img = image.copy()
new_bboxes = []
cl = 0
random.shuffle(rescale_boxes)
for i, rescale_bbox in enumerate(rescale_boxes[:int(len(mask_lst))]): # 待ps图像 目标框中
p_img = mask_lst[i]
bbox_h, bbox_w, bbox_c = p_img.shape
obj_xmin, obj_ymin, obj_xmax, obj_ymax = rescale_bbox[1:]
obj_w = obj_xmax - obj_xmin + 1 # 目标框尺寸
obj_h = obj_ymax - obj_ymin + 1
while not (bbox_w < obj_w and bbox_h < obj_h): # 如果目标框小于 mask尺寸,对mask进行缩放以确保可以放进 bbox中
new_bbox_w = int(bbox_w * random.uniform(0.5, 0.8))
new_bbox_h = int(bbox_h * random.uniform(0.5, 0.8))
bbox_w, bbox_h = new_bbox_w, new_bbox_h
success_num = 0
while success_num < paste_number:
center_search_space = [obj_xmin, obj_ymin, obj_xmax - new_bbox_w - 1, obj_ymax - new_bbox_h - 1] # 选取生成随机点区域
if center_search_space[0] >= center_search_space[2] or center_search_space[1] >= center_search_space[3]:
print('============== center_search_space error!!!! ================')
success_num += 1
continue
new_bbox_x_min = random.randint(center_search_space[0], center_search_space[2]) # 随机生成点坐标
new_bbox_y_min = random.randint(center_search_space[1], center_search_space[3])
new_bbox_x_left, new_bbox_y_top, new_bbox_x_right, new_bbox_y_bottom = new_bbox_x_min, new_bbox_y_min, new_bbox_x_min + new_bbox_w - 1, new_bbox_y_min + new_bbox_h - 1
new_bbox = [cl, int(new_bbox_x_left), int(new_bbox_y_top), int(new_bbox_x_right), int(new_bbox_y_bottom)]
success_num += 1
new_bboxes.append(new_bbox)
p_img = cv2.resize(p_img, (new_bbox_w, new_bbox_h))
img = merge_img(img, p_img, new_bbox_y_top, new_bbox_y_bottom+1, new_bbox_x_left, new_bbox_x_right+1)
return img, new_bboxes
if __name__ == "__main__":
# 用来装载参数的容器
parser = argparse.ArgumentParser(description='PS')
# 给这个解析对象添加命令行参数
parser.add_argument('-i', '--images', default= '/media/yinzhe/DataYZ/DataSet/DataSet/bag_model',type=str, help='path of images')
parser.add_argument('-t', '--mask', default= '/media/yinzhe/DataYZ/DataSet/DataSet/bag_mask',type=str, help='path of masks')
parser.add_argument('-s', '--saveImage',default= '/media/yinzhe/DataYZ/DataSet/DataSet/bag_save', type=str, help='path of ')
parser.add_argument('-c', '--scale', default= 0.2, type=float, help='number of img')
parser.add_argument('-n', '--num', default= 5, type=int, help='number of img')
args = parser.parse_args() # 获取所有参数
mask_filedirs = args.mask
images_path = args.images
save_path = args.saveImage
scale, num = args.scale, args.num
mask_paths = []
if not os.path.exists(save_path):
os.makedirs(save_path)
# 读取所有的 mask 模版
mask_lst = []
for t_path in os.listdir(mask_filedirs):
mask = cv2.imread(os.path.join(mask_filedirs, t_path), cv2.IMREAD_UNCHANGED)
if (mask.shape[2] != 4): # RGB alpha
break
mask_lst.append(mask)
# template_paths = random.shuffle(template_paths) #打乱顺序
for image_path in os.listdir(images_path) :
if "txt" in image_path:
continue
image = cv2.imread(os.path.join(images_path, image_path))
pre_name = image_path.split('.')[0]
bbox_lst = read_label_txt(os.path.join(images_path, pre_name + ".txt"))
if image is None or len(bbox_lst) == 0:
print("empty image !!! or empty label !!!")
continue
# yolo txt转化为x1y1x2y2
rescale_bboxes = rescale_yolo_labels(bbox_lst, image.shape) # 转换坐标表示
# maskes_path = sample(mask_paths, int(len(bbox_lst) * scale))
#
for i in range(num):
maskes = sample(mask_lst, int(len(bbox_lst) * scale))
img, bboxes = random_add_patches_on_objects(image, maskes, rescale_bboxes, 1)
boxes = xyxy2xywh(img, bboxes)
img_name = pre_name + '_' + str(i) + '.jpg'
print('handle img:', img_name)
cv2.imwrite(os.path.join(save_path, img_name), img)
with open(os.path.join(save_path, img_name[:-4] + ".txt"), 'a') as f:
for box in boxes:
mess = str(3) + " " + str(box[1]) + " " + str(box[2]) + " " + str(box[3] * 0.6) + " " + str(box[4]* 0.6) + "\n"
f.write(mess)