大纲
- Tumbling Count Windows
- map
- reduce
- Window Size为2
- Window Size为3
- Window Size为4
- Window Size为5
- Window Size为6
- 完整代码
- 参考资料
之前的案例中,我们的Source都是确定内容的数据。而Flink是可以处理流式(Streaming)数据的,就是数据会源源不断输入。

对于这种数据,我们称之为无界流,即没有“终止的界限”。但是程序在底层一定不能等着无止境的数据都传递结束再处理,因为“无止境”就意味着“终止的界限”触发计算的条件是不存在的。那么我们可以人为的给它设置一个“界”,这就是我们本节介绍的窗口。
Tumbling Count Windows
Tumbling Count Windows是指按元素个数计数的滚动窗口。
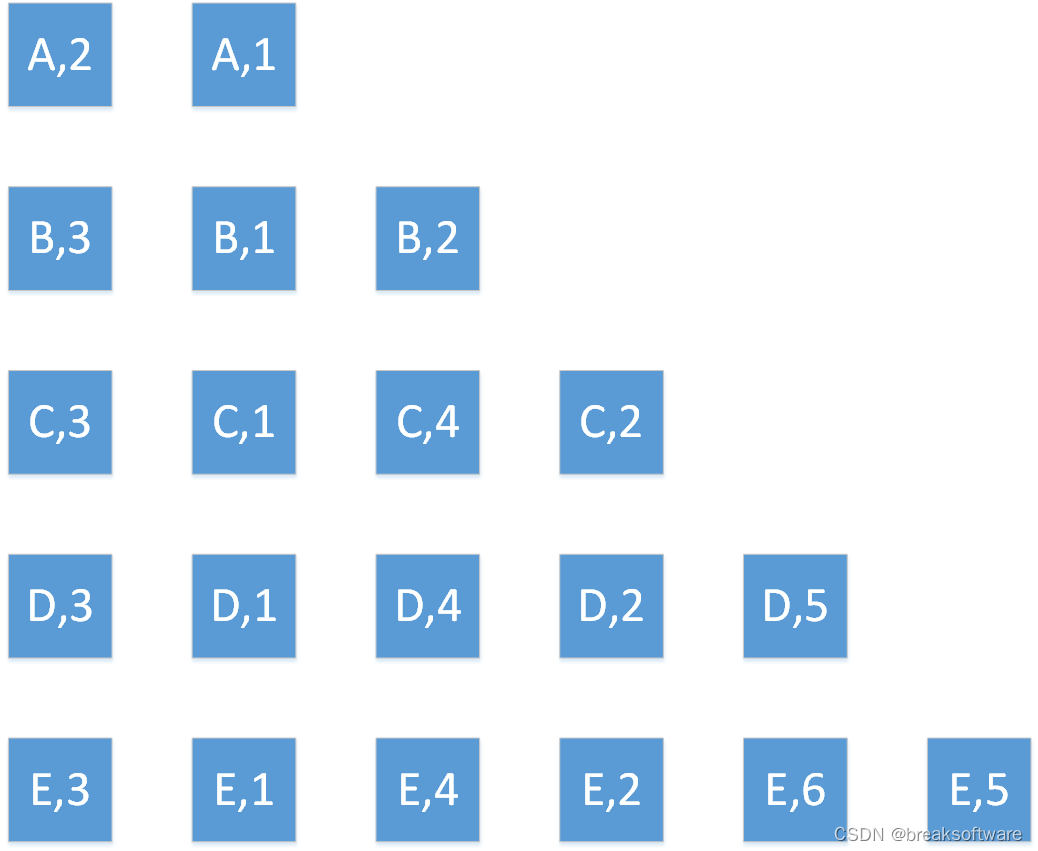
滚动窗口是指没有元素重叠的窗口,比如下面图是个数为2的窗口。(元素重叠的窗口我们会在《0基础学习PyFlink——个数滑动窗口(Sliding Count Windows)》介绍)

个数为3的窗口

我们用代码探索下这个概念
map
word_count_data = [
("A",2),("A",1),
("B",3),("B",1),("B",2),
("C",3),("C",1),("C",4),("C",2),
("D",3),("D",1),("D",4),("D",2),("D",5),
("E",3),("E",1),("E",4),("E",2),("E",6),("E",5)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
# write all the data to one file
env.set_parallelism(1)
source_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
# define the source
# mappging
source = env.from_collection(word_count_data, source_type_info)
# source.print()
# keying
keyed=source.key_by(lambda i: i[0])
这段代码构造了一个KeyedStream,用于存储word_count_data中的数据。
我们并没有让Source是流的形式,是因为为了降低例子复杂度。但是我们将runntime mode设置为流(STREAMING)模式。
reduce
我们需要定义一个Reduce类,用于对元组中的数据进行计算。这个类需要继承于WindowFunction,并实现相应方法(本例中是apply)。
apply会计算一个相同key的元素个数。比如key是“E”的元组个数是6。
class SumWindowFunction(WindowFunction[tuple, tuple, str, CountWindow]):
def apply(self, key: str, window: CountWindow, inputs: Iterable[tuple]):
return [(key, len([e for e in inputs]))]
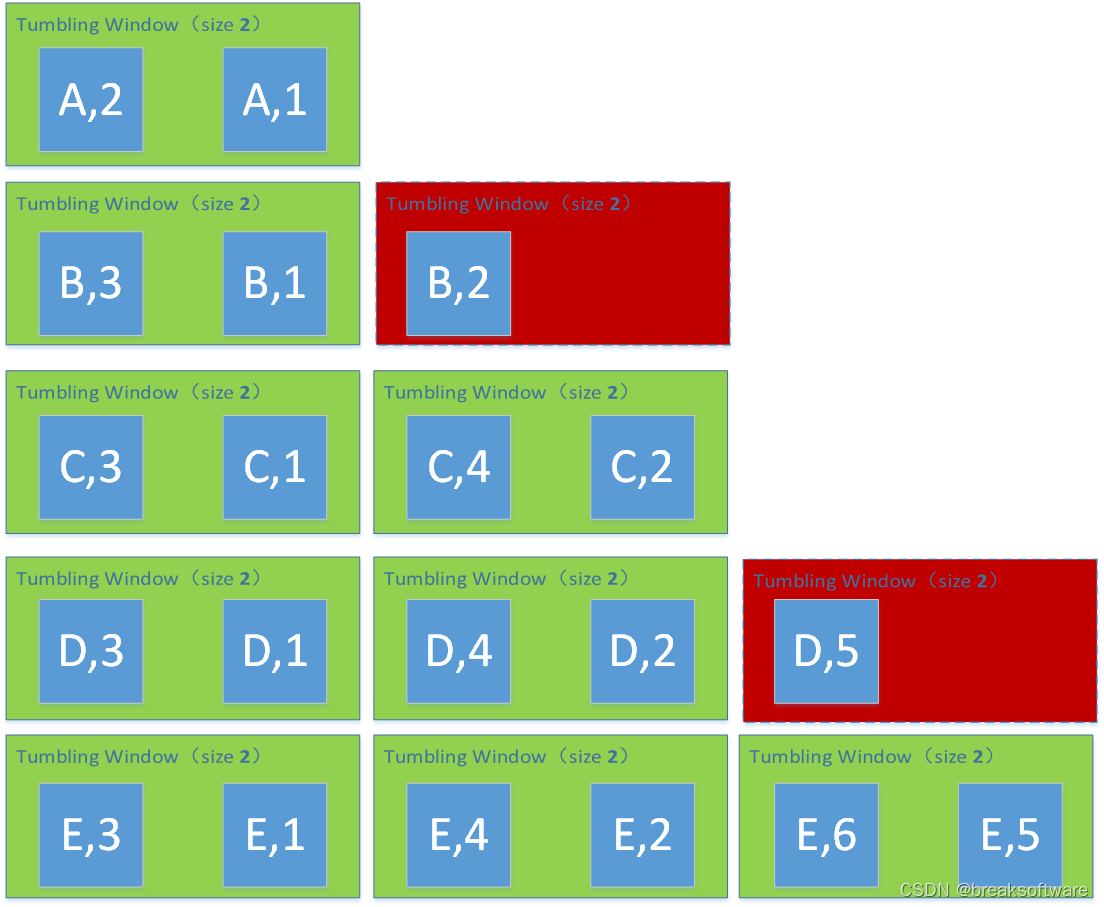
Window Size为2
# reducing
reduced=keyed.count_window(2) \
.apply(SumWindowFunction(),
Types.TUPLE([Types.STRING(), Types.INT()]))
# # define the sink
reduced.print()
# submit for execution
env.execute()
(A,2)
(B,2)
(C,2)
(C,2)
(D,2)
(D,2)
(E,2)
(E,2)
(E,2)
- A的个数是2是因为A的确只有两个元组,而一个Size为2的Window正好承载了这两个元素。于是有(A,2)这个结果;
- B的个数是3。但是会产生两个窗口,第一个窗口承载了前两个元素,第二个窗口当前只有一个元素。于是第一个窗口进行了Reduce计算,得出一个(B,2);第二个窗口还没进行reduce计算,就没有展现出结果;
- C有4个,正好可以被2个窗口承载。这样我们就看到2个(C,2)。
- D有5个,情况和B类似。它被分成了3个窗口,只有2个窗口满足个数条件,于是就输出2个(D,2);最后一个窗口因为元素不够,就没尽兴reduce计算了。
- E有6个,正好被3个窗口承载。我们就看到3个(E,2)。
Window Size为3
# reducing
reduced=keyed.count_window(3) \
.apply(SumWindowFunction(),
Types.TUPLE([Types.STRING(), Types.INT()]))
(B,3)
(C,3)
(D,3)
(E,3)
(E,3)
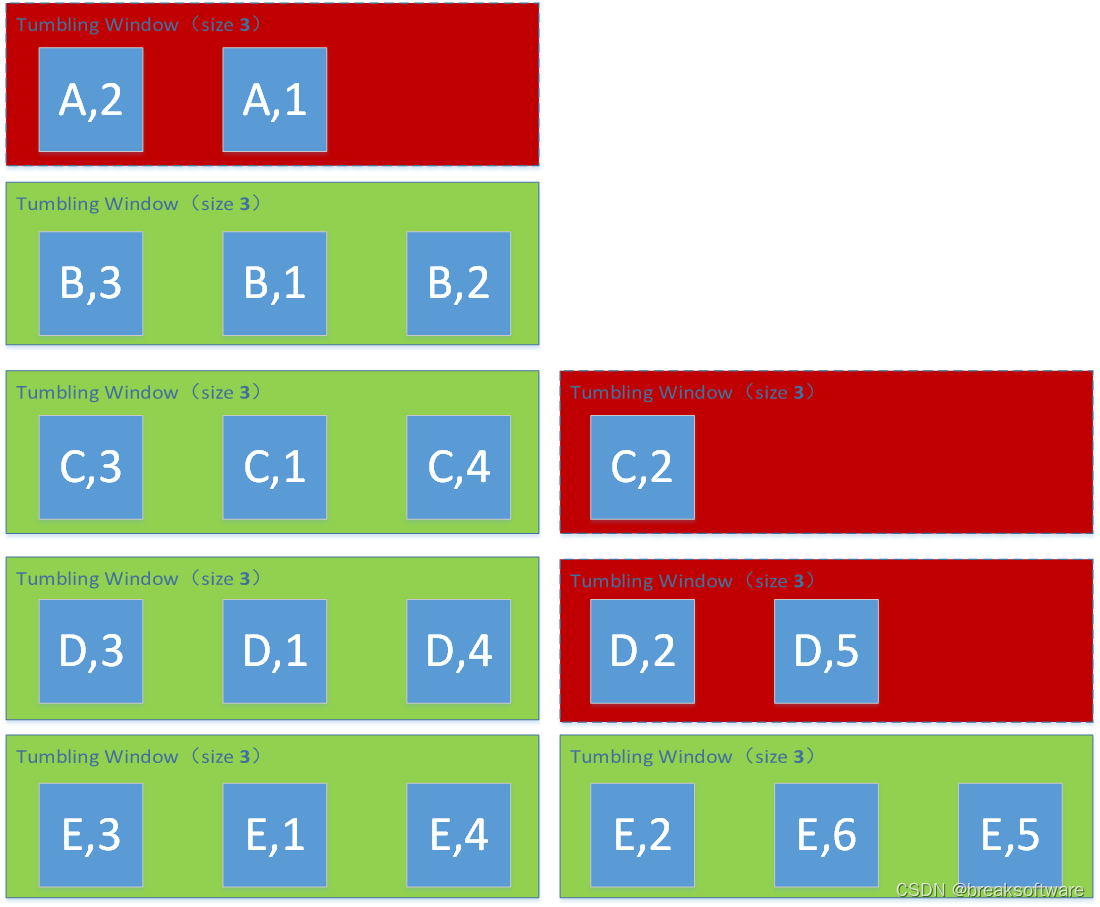
Window Size为4
# reducing
reduced=keyed.count_window(4) \
.apply(SumWindowFunction(),
Types.TUPLE([Types.STRING(), Types.INT()]))
(C,4)
(D,4)
(E,4)
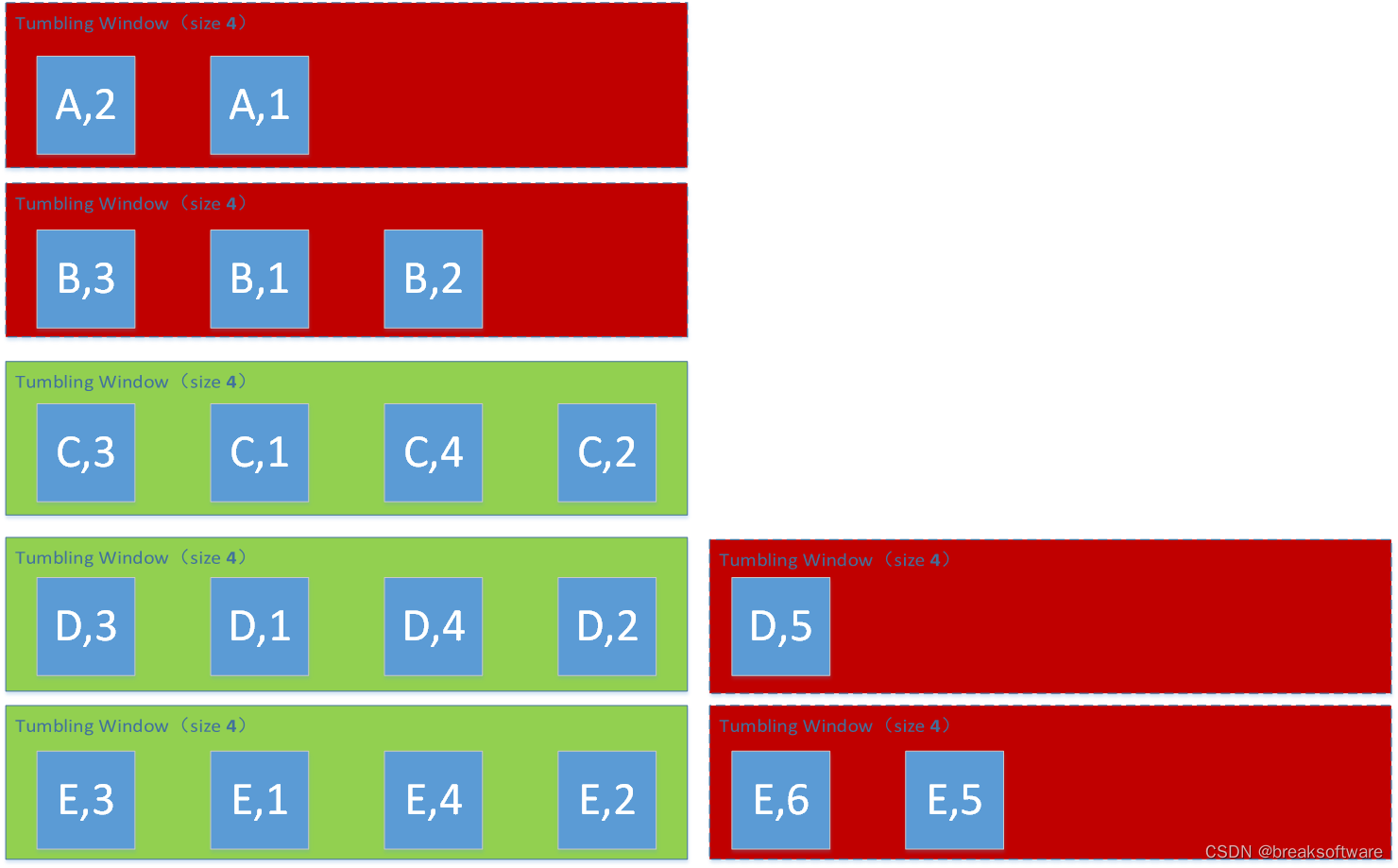
Window Size为5
# reducing
reduced=keyed.count_window(5) \
.apply(SumWindowFunction(),
Types.TUPLE([Types.STRING(), Types.INT()]))
(D,5)
(E,5)
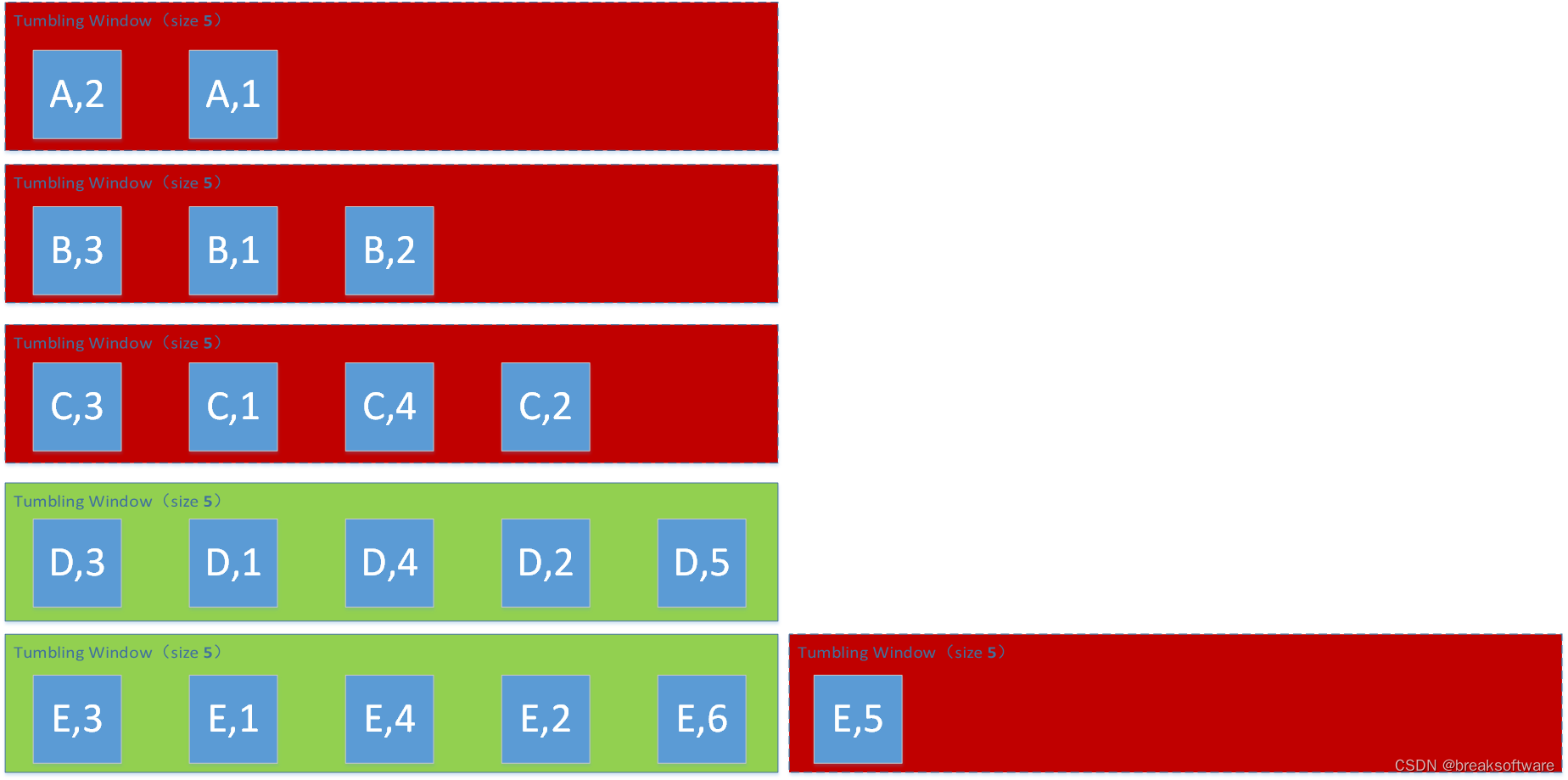
Window Size为6
# reducing
reduced=keyed.count_window(6) \
.apply(SumWindowFunction(),
Types.TUPLE([Types.STRING(), Types.INT()]))
(E,6)
完整代码
from typing import Iterable
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode, WindowFunction
from pyflink.datastream.window import CountWindow
class SumWindowFunction(WindowFunction[tuple, tuple, str, CountWindow]):
def apply(self, key: str, window: CountWindow, inputs: Iterable[tuple]):
return [(key, len([e for e in inputs]))]
word_count_data = [
("A",2),("A",1),
("B",3),("B",1),("B",2),
("C",3),("C",1),("C",4),("C",2),
("D",3),("D",1),("D",4),("D",2),("D",5),
("E",3),("E",1),("E",4),("E",2),("E",6),("E",5)]
def word_count():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
# write all the data to one file
env.set_parallelism(1)
source_type_info = Types.TUPLE([Types.STRING(), Types.INT()])
# define the source
# mappging
source = env.from_collection(word_count_data, source_type_info)
# source.print()
# keying
keyed=source.key_by(lambda i: i[0])
# reducing
reduced=keyed.count_window(2) \
.apply(SumWindowFunction(),
Types.TUPLE([Types.STRING(), Types.INT()]))
# # define the sink
reduced.print()
# submit for execution
env.execute()
if __name__ == '__main__':
word_count()
参考资料
- https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/learn-flink/streaming_analytics/