引题
最近在看爬虫,也准备学习一下防爬的策略,世上莫大之事就是,我可以爬别人网站,别人不许爬我网站。
正文
什么是User-Agent
User-Agent是一个HTTP请求头的一部分,它向Web服务器提供关于客户端(通常是浏览器)的信息,以便服务器能够针对不同的浏览器提供适当的内容或在检测异常时进行诊断。 User-Agent字符串通常包含浏览器的名称、版本号、操作系统和硬件平台。 例如:下面这个就是我浏览器的User-Agent
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36User-Agent包含那些信息
Chrome/118.0.0.0表示使用的谷歌浏览器版本号为118.0.0.0。
Mozilla/5.0 表示引擎(版本 5.0)。
AppleWebKit/537.36表示使用引擎的版本号537.36。
(Windows NT 10.0; Win64; x64)表示运行在windows操作系统的64平台上。
User-Agent防爬
User-Agent防爬是一个比较常见的防爬策略。
判断User-Agent状态
在前端发送请求的时候需要判断User-Agent是否为空,正常浏览器发送请求的时候都会携带User-Agent进行发送请求。
我们后端c#可以利用HttpContext.Request.Headers.UserAgent来获取得到请求中的User-Agent。
创建一个post请求,判断User-Agent是否为空,不为空返回User-Agent。
[HttpPost]
public object Add()
{
var PostUser = HttpContext.Request.Headers.UserAgent.ToString();
if (PostUser == "")
{
return "来爬虫都不带User-Agent的吗";
}
else
{
return PostUser;
}
}我们这里用postman不携带User-Agent测试一下,我们看到这样做是可以的。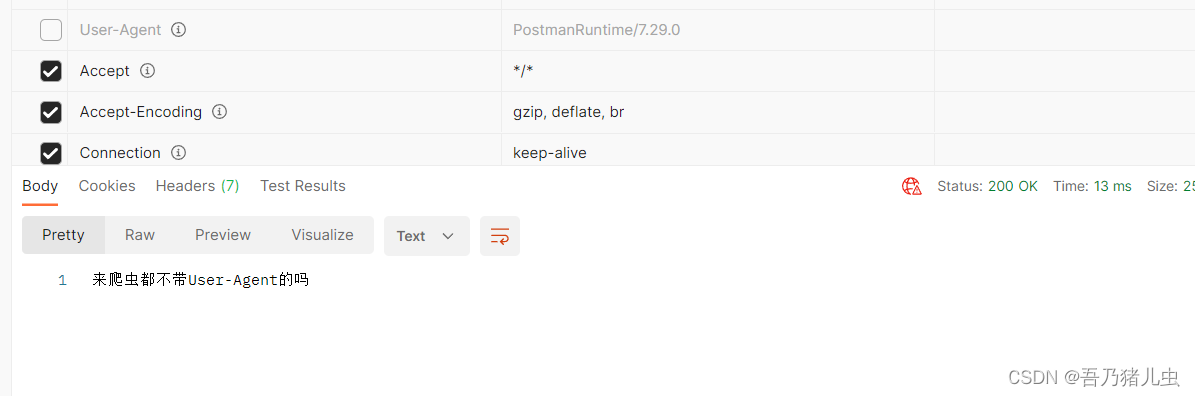
当然,我们也可以限制某些浏览器或者设备的访问。同时,我们也可以将对请求中携带的User-Agent进行计数,在一定时间内访问超过多少次数限制访问,毕竟那个正常用户一个小时访问成百上千。
python中的headers
应对User-Agent防爬
1. 更换User-Agent:在爬虫程序中设置随机的User-Agent,增加请求的隐蔽性,避免被网站识别为爬虫。
2. 伪装成浏览器:模拟真实用户的行为,设置与浏览器一致的User-Agent,同时增加一些随机的请求头和请求参数,模拟用户浏览网页的行为,这样能够避免网站识别为爬虫。
3. 使用代理IP:使用代理IP进行请求,可以将真实的IP地址隐藏起来,避免网站识别爬虫。
4. 避免频繁访问:设置合理的爬取时间间隔,避免频繁的请求,避免网站识别为爬虫。
5. 使用验证码识别接口:部分网站会通过验证码来防止爬虫,可以使用验证码识别接口来自动化处理验证码,绕过该限制。
一般对User-Agent的防爬并不能起到多大作用,毕竟python中可以伪装,在发送HTTP请求时需要设置User-Agent为相应的搜索引擎标识。
我们使用requests库发送一个GET请求,并设置请求头中的User-Agent为伪装的User-Agent。这样服务器就会认为这个请求来自于伪装的User-Agent,返回的结果也可能会有所不同。
import requests
url='网站'
headers={
'User-Agent':'模拟User-Agent'
}
response=requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
print(response.text)但是,我爬别人的网站也要多这样的代码,所以,别人爬我网站也要多一些工作量!!!







![[ZenTao]禅道邮件通知设置](https://img-blog.csdnimg.cn/47869da27aea46bfb000c65ab6b9fab3.png)