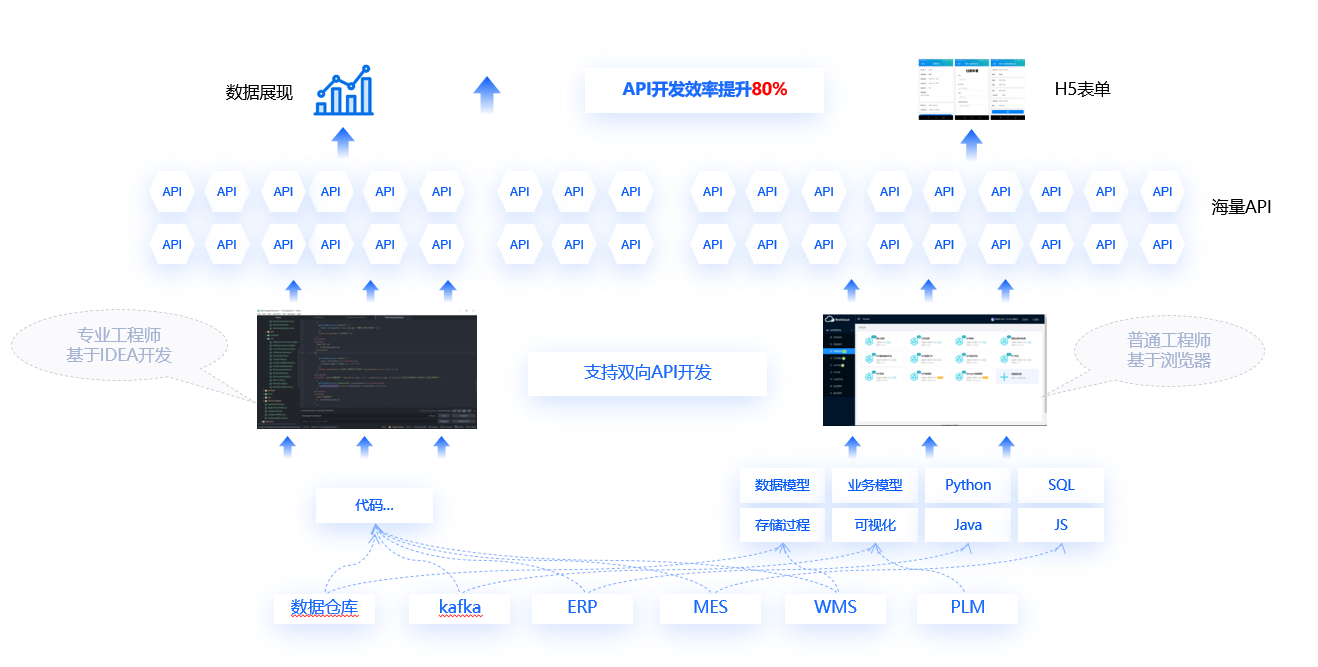
【lmbench----lmbench性能测试工具迁移至openEuler操作系统实践】
文章目录
- 一、openEuler系统上编译部署与运行
- 1.1 安装基础依赖
- 1.2 下载 lmbench 源码
- 1.3 编译安装
- 1.4 执行 lmbench 测试
- 1.5 结果查看
- 二、lmbench 性能测试结果解析
- 2.1 处理器性能
- 2.2 数学运算性能
- 2.3 上下文切换性能
- 2.3 本地通信性能
- 2.4 文件及内存时延
- 2.5 本地通信带宽性能
- 2.6 内存操作时延
一、openEuler系统上编译部署与运行
1.1 安装基础依赖
dnf install -y git
dnf install -y libtirpc libtirpc-devel
1.2 下载 lmbench 源码
如下 github 上 lmbench 代码仓 是经过对openEuler系统x86_64和aarch64架构适配的,可以直接通过下载此代码仓代码,执行如下命令
cd /opt/
git clone https://github.com/redrose2100/lmbench.git
1.3 编译安装
cd /opt/lmbench/src
make
1.4 执行 lmbench 测试
(1)执行如下命令启动
cd /opt/lmbench/src
make results
(2)设置是否并行运行,这里先选择默认1,即直接回车即可

(3)然后输入 1,选择允许调度,然后回车
(4)然后可以选择默认,直接回车

(5)然后继续保持默认,直接回车
(6)继续保持默认,直接回车
(7)继续保持默认,直接回车
(8)继续保持默认,直接回车

(9)继续保持默认,直接回车
(10)继续保持默认,直接回车
(11)继续保持默认,直接回车
(12)继续保持默认,直接回车

(13)是否发送邮件,这里设置no,然后回车
(14)然后即开始执行 lmbench 了,此时可能需要等待较长时间,需要慢慢等待
1.5 结果查看
执行完成后,通过如下命令可以查看性能测试结果
make see
比如如下所示:
[root@redrose2100-lmbench lmbench]# make see
cd results && make summary percent 2>/dev/null | more
make[1]: Entering directory '/opt/lmbench/results'
L M B E N C H 3 . 0 S U M M A R Y
------------------------------------
(Alpha software, do not distribute)
Processor, Processes - times in microseconds - smaller is better
------------------------------------------------------------------------------
Host OS Mhz null null open slct sig sig fork exec sh
call I/O stat clos TCP inst hndl proc proc proc
--------- ------------- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ----
redrose21 Linux 5.10.0- 1598 0.45 0.51 1.23 2.48 5.96 0.52 1.25 339. 1681 2634
Basic integer operations - times in nanoseconds - smaller is better
-------------------------------------------------------------------
Host OS intgr intgr intgr intgr intgr
bit add mul div mod
--------- ------------- ------ ------ ------ ------ ------
redrose21 Linux 5.10.0- 0.2100 0.9800 7.4800 8.2600
Basic float operations - times in nanoseconds - smaller is better
-----------------------------------------------------------------
Host OS float float float float
add mul div bogo
--------- ------------- ------ ------ ------ ------
redrose21 Linux 5.10.0- 0.9500 0.9500 3.5100 0.8000
Basic double operations - times in nanoseconds - smaller is better
------------------------------------------------------------------
Host OS double double double double
add mul div bogo
--------- ------------- ------ ------ ------ ------
redrose21 Linux 5.10.0- 0.9500 0.9500 4.4500 1.4500
Context switching - times in microseconds - smaller is better
-------------------------------------------------------------------------
Host OS 2p/0K 2p/16K 2p/64K 8p/16K 8p/64K 16p/16K 16p/64K
ctxsw ctxsw ctxsw ctxsw ctxsw ctxsw ctxsw
--------- ------------- ------ ------ ------ ------ ------ ------- -------
redrose21 Linux 5.10.0- 5.7100 5.4700 6.2900 8.7600 18.3 8.91000 11.1
*Local* Communication latencies in microseconds - smaller is better
---------------------------------------------------------------------
Host OS 2p/0K Pipe AF UDP RPC/ TCP RPC/ TCP
ctxsw UNIX UDP TCP conn
--------- ------------- ----- ----- ---- ----- ----- ----- ----- ----
redrose21 Linux 5.10.0- 5.710 12.9 10.7 22.7 27.6 27.4 34.4 68.
File & VM system latencies in microseconds - smaller is better
-------------------------------------------------------------------------------
Host OS 0K File 10K File Mmap Prot Page 100fd
Create Delete Create Delete Latency Fault Fault selct
--------- ------------- ------ ------ ------ ------ ------- ----- ------- -----
redrose21 Linux 5.10.0- 9.9702 6.9090 21.3 11.2 37.1K 0.764 1.328
*Local* Communication bandwidths in MB/s - bigger is better
-----------------------------------------------------------------------------
Host OS Pipe AF TCP File Mmap Bcopy Bcopy Mem Mem
UNIX reread reread (libc) (hand) read write
--------- ------------- ---- ---- ---- ------ ------ ------ ------ ---- -----
redrose21 Linux 5.10.0- 3242 7813 3863 6257.4 7326.2 8393.1 4079.9 7401 5750.
Memory latencies in nanoseconds - smaller is better
(WARNING - may not be correct, check graphs)
------------------------------------------------------------------------------
Host OS Mhz L1 $ L2 $ Main mem Rand mem Guesses
--------- ------------- --- ---- ---- -------- -------- -------
redrose21 Linux 5.10.0- 1598 1.3240 6.8310 29.1 92.3
make[1]: Leaving directory '/opt/lmbench/results'
二、lmbench 性能测试结果解析
2.1 处理器性能
处理器性能结果如下所示:
Processor, Processes - times in microseconds - smaller is better
------------------------------------------------------------------------------
Host OS Mhz null null open slct sig sig fork exec sh
call I/O stat clos TCP inst hndl proc proc proc
--------- ------------- ---- ---- ---- ---- ---- ---- ---- ---- ---- ---- ----
redrose21 Linux 5.10.0- 1598 0.45 0.51 1.23 2.48 5.96 0.52 1.25 339. 1681 2634
其中:
- null call: 表示执行 getppid 需要的时间
- null I/O: 表示从 /dev/zero 读取一个字节的时长和写一个字节到 /dev/null 的时长的平均值
- stat: stat 表示得到一个文件的信息所需时长;
- open clos: 表示打开一个文件然后再关闭该文件所用时间(不包含读目录和节点的时间)
- slct TCP: 表示通过 TCP 网络连接选择 100 个文件描述符所消耗的时间;
- sig inst: 表示安装信号所耗时长;
- sig hndl: 表示处理信号所耗时长;
- fork proc: 表示fork一个完全相同的进程,并把原来的进程关闭一共所消耗的时间;
- exec proc: 表示模拟一个shell进程的工作过程:fork 一个新进程执行新命令消耗的时间。
- sh proc: 表示fork一个进程,同时询问系统 shell 来找到并运行一个新程序所用时间。
2.2 数学运算性能
数学运算性能结果如下,数学运算性能指标比较明显,即加减乘除以及模运算的性能。如下设计整型运算、单精度浮点型运算、双精度浮点型运算
Basic integer operations - times in nanoseconds - smaller is better
-------------------------------------------------------------------
Host OS intgr intgr intgr intgr intgr
bit add mul div mod
--------- ------------- ------ ------ ------ ------ ------
redrose21 Linux 5.10.0- 0.2100 0.9800 7.4800 8.2600
Basic float operations - times in nanoseconds - smaller is better
-----------------------------------------------------------------
Host OS float float float float
add mul div bogo
--------- ------------- ------ ------ ------ ------
redrose21 Linux 5.10.0- 0.9500 0.9500 3.5100 0.8000
Basic double operations - times in nanoseconds - smaller is better
------------------------------------------------------------------
Host OS double double double double
add mul div bogo
--------- ------------- ------ ------ ------ ------
redrose21 Linux 5.10.0- 0.9500 0.9500 4.4500 1.4500
2.3 上下文切换性能
上下文切换性能结果如下所示:
Context switching - times in microseconds - smaller is better
-------------------------------------------------------------------------
Host OS 2p/0K 2p/16K 2p/64K 8p/16K 8p/64K 16p/16K 16p/64K
ctxsw ctxsw ctxsw ctxsw ctxsw ctxsw ctxsw
--------- ------------- ------ ------ ------ ------ ------ ------- -------
redrose21 Linux 5.10.0- 5.7100 5.4700 6.2900 8.7600 18.3 8.91000 11.1
其中:
- 2p/0k: 每个进程的 size 为 0(不执行任何任务),进程数为 2 时上下文切换所消耗的时间
- 2p/16k: 每个进程 size 为 16K(执行任务),进程数为 2 时上下文切换所消耗的时间
- 2p/64k: 每个进程的 size 为 64k(不执行任何任务),进程数为 2 时上下文切换所消耗的时间
- 8p/16k: 每个进程 size 为 16K(执行任务),进程数为 8 时上下文切换所消耗的时间
- 8p/64k: 每个进程 size 为 64K(执行任务),进程数为 8 时上下文切换所消耗的时间
- 16p/16k: 每个进程 size 为 16K(执行任务),进程数为 16 时上下文切换所消耗的时间
- 16p/64k: 每个进程 size 为 64K(执行任务),进程数为 16 时上下文切换所消耗的时间
2.3 本地通信性能
本地通信性能结果如下:
*Local* Communication latencies in microseconds - smaller is better
---------------------------------------------------------------------
Host OS 2p/0K Pipe AF UDP RPC/ TCP RPC/ TCP
ctxsw UNIX UDP TCP conn
--------- ------------- ----- ----- ---- ----- ----- ----- ----- ----
redrose21 Linux 5.10.0- 5.710 12.9 10.7 22.7 27.6 27.4 34.4 68.
其中:
- 2p/0k: 每个进程的 size 为 0(不执行任何任务),进程数为 2 时上下文切换所消耗的时间
- Pipe: 即所谓的 hot potato 测试,两个没有具体任务的进程之间使用 pipe 通信,一个 token 在两个进程间来回传递,传递一个来回所消耗时长的平均值
- AF UNIX: 同 Pipe 测试项,但进程间通信使用的是 socket 通信
- UDP: 同 Pipe 测试项,但进程间通信使用的是 UDP 通信
- RPC/UDP: 同 Pipe 测试项,但进程间通信使用的是 RPC 通信,默认情况下,RPC 采用 UDP 协议传输
- TCP: 同 Pipe 测试项,但进程间通信使用的是 TCP 通信
- RPC/TCP: 同 Pipe 测试项,但进程间通信使用的是 RPC 通信,指定 RPC 采用 TCP 协议传输
- TCP conn: 创建 socket 描述符和建立连接所用时间
2.4 文件及内存时延
文件及内存时延如下
File & VM system latencies in microseconds - smaller is better
-------------------------------------------------------------------------------
Host OS 0K File 10K File Mmap Prot Page 100fd
Create Delete Create Delete Latency Fault Fault selct
--------- ------------- ------ ------ ------ ------ ------- ----- ------- -----
redrose21 Linux 5.10.0- 9.9702 6.9090 21.3 11.2 37.1K 0.764 1.328
其中:
- 0K File Create: 0K 文件创建所用时间
- 0K File Delete: 0K 文件删除所用时间
- 10K File Create: 10K 文件创建所用时间
- 10K File Delete: 10K 文件删除所用时间
- Mmap Latency: 将指定文件的开头 n 个字节 mmap 到内存,然后 unmap,并记录每次 mmap 和 unmap 共消耗的时间,去每次消耗时间的最大值
- Port Fault: 保护页延时时间
- Page Faule: 缺页延时时间
- 100fd selct: 对 100 个文件描述符配置 select 的时间
2.5 本地通信带宽性能
本地通信带宽性能如下
*Local* Communication bandwidths in MB/s - bigger is better
-----------------------------------------------------------------------------
Host OS Pipe AF TCP File Mmap Bcopy Bcopy Mem Mem
UNIX reread reread (libc) (hand) read write
--------- ------------- ---- ---- ---- ------ ------ ------ ------ ---- -----
redrose21 Linux 5.10.0- 3242 7813 3863 6257.4 7326.2 8393.1 4079.9 7401 5750.
其中:
- Pipe: 在两个进程建立 pipe,pipe 的每个 chunk 为 64K,通过该管道移动 50MB 数据所消耗的时间
- AF UNIX: 两个进程之间建立 unix stream socket 连接,每个 chunk 为 64K,通过该 socket 传输 10MB 数据所用的时间
- TCP: 同 Pipe 测试项,但进程间使用 TCP/IP socket 通信,传输数据量为 3MB;
File reread: 读文件并将其汇总一起所用的时间 - Mmap reread: 将文件 mmap 到内存中,从内存中读文件并将其汇总一起所用时间
- Bcopy(libc): do bw_mem $i bcopy,从指定内存区域拷贝指定数量的字节内容到另一个指定内存区域的速度
- Bcopy(hand): do bw_mem %i fcp,把数据从磁盘的一个位置拷贝到另一个位置所用的时间;
- Mem read: bw_mem $i frd,累加数组中的整数值,测试把数据读入 processor 的带宽
- Mem write: do bw_mem $i fwr,把整数数组的每个成员设置为 1,测试写数据到内存的带宽
2.6 内存操作时延
内存操作时延如下
Memory latencies in nanoseconds - smaller is better
(WARNING - may not be correct, check graphs)
------------------------------------------------------------------------------
Host OS Mhz L1 $ L2 $ Main mem Rand mem Guesses
--------- ------------- --- ---- ---- -------- -------- -------
redrose21 Linux 5.10.0- 1598 1.3240 6.8310 29.1 92.3
其中:
- L1: 缓存1
- L2: 缓存2
- Main Mem: 连续内存
- Rand Mem: 内存随机访问延时
- Guesses:
假如 L1 和 L2 近似,会显示 “No L1 cache?”
假如 L2 和 Main Mem 近似,会显示 “No L2 cache?”