一、OLTP 阵营
OLTP(在线事务、交易处理):RDBMS( Relational Database Management System)、NoSQL、NewSQL
OLTP阵营可以分为:
- 传统的关系型数据库
- NoSQL
- NewSQL
1、NoSQL
NoSQL类系统普遍存在下面一些共同特征:
不需要预定义数据模式(No-Upfront-Schema)或表结构:数据中的每条记录都可能有不同的属性和格式。当插入数据时,并不需要预先定义它们的模式。
无共享(Shared Nothing)架构:NoSQL通常把数据划分后存储在各个本地服务器上。因为从本地磁盘读取数据的性能往往好于通过网络传输(如NAS/SAN)来读取数据的性能,从而提高了系统的性能,当然,代价是多份数据拷贝及数据一致性保证。
无共享架构(Shared Nothing Architecture (SNA) )是一种分布式计算架构,由多个不共享资源的独立节点组成。节点是独立和自给自足的,因为它们有自己的磁盘空间和内存。
分区:NoSQL需要对数据集进行分区,将记录分散在多个节点上面。并在分区的同时进行复制。这样既提高了并行性能,又能保证没有单点失效的问题。
弹性可扩展:可以在系统运行的时候,动态添加或者删除节点。不需要停机维护,数据可以自动迁移。
异步复制:和RAID存储系统不同的是,NoSQL中的复制,往往是基于日志的异步复制。这样,数据就可以尽快地写入一个节点,而不会被网络传输引起迟延。缺点是并不总是能保证一致性,这样的方式在出现故障的时候,可能会丢失少量的数据。
符合BASE模型:BASE提供的是最终一致性和软事务(相对于事务严格的ACID模型,下文中的NewSQL在NoSQL基础上实现了对ACID模型的支持)。
以下再对颇具代表性的MongoDB(文档型)、Cassandra(宽表型)、Redis(键值型)和Ultipa Graph(图数据库)解决方案进行介绍。
一种通过牺牲高一致性来获得可用性或可靠性的模型。主要包括基本可用性、软状态(柔事务性)和最终一致性。
文档型NoSQL—MongoDB
作为文档型NoSQL数据库的代表,MongoDB采用了一种与RDBMS反其道而行之的设计理念,不需要预先定义数据结构,使用了与JSON(JavaScript Object Notation)兼容的BSON(Binary JSON)的轻量级数据传输与存储结构(相对于笨重、复杂的XML而言,XML一直以其解析复杂而被广大Web开发人员所诟病),也不需要对存储的数据结构像关系型数据库一样进行正则化(Normalization,目的是减少重复数据)。
例如:构建一个数字图书馆,如果用传统的RDBMS则至少需要对书名、作者等相关信息使用多个正则化的表结构来存储,在进行数据检索与分析的时候则需要频繁的(且昂贵的)表JOIN操作。
而MongoDB中则只需要通过对JSON(在MongoDB中称作BSON,Binary JSON)描述的简单文档型数据结构进行一次读操作即可完成。
对于提高性能以及在商用硬件上扩展而言MongoDB的优势不言而喻,同时MongoDB也兼顾关系型数据库操作习惯,例如它保留了left-outer JOIN操作……
宽表型NoSQL—Cassandra
Cassandra是目前最流行的宽表数据库(Wide Column),最早由Facebook开发并开源。相信Facebook是受到了谷歌的高性能存储系统BigTable(基于GFS等技术,服务于MapReduce等任务)的启发而来的。它的最大特点是:
① 无特殊节点(如主、备服务器),因此无单点故障;
② 服务器集群可跨多个物理数据中心,无需主服务器的异步同步功能支持。
Cassandra系统中有几个关键概念:
- 数据分区(Data Partitioning)与一致性哈希(Consistent Hashing):鉴于Cassandra的核心设计理念是一个逻辑数据库中的数据由所有集群中的节点分散保存,也就是所谓分区。数据的分布式会带来两个潜在的问题:
① 如何判断指定的数据存储在哪个节点之上?
② 在增加或删除节点时如何尽量减少数据的跨节点移动?解决方案就是通过持续的一致性哈希运算(即实现对Cassandra分区索引)。
-
数据复制(Data Replication):所有无共享(Shared-Nothing)架构避免单点故障都是通过对数据进行多份复制(类似于拷贝)来实现的。
-
一致性级别(Consistency Level):在Cassandra系统中可以定制一致性级别,也就是说需要多少节点返回读写操作的确认。
业界对于Cassandra的使用相当广泛,大部分用它来做数据分析服务,甚至是实时数据分析及流数据处理,还有些公司试图用Cassandra全面取代MySQL。
例如Twitter,不过貌似这一尝试并未获得成功,而始作俑者Facebook本来最早用Cassandra来做邮箱搜索(Inbox Search),后来因为最终一致性的问题而换成了HBase,不过这丝毫不影响业界对它趋之若鹜。
Cassandra一直宣称是NoSQL数据库中线性可扩展(Linear Scalability)做得最好的,目前已知全球最大的商用Cassandra部署恐怕是苹果公司,有超过十万个节点和数以十PB计的数据对其地图、iTunes、iCloud及iAd服务进行管理与分析。
键值型NoSQL—Redis
Redis是由早期的键值(Key-Value Pair)数据库发展而来的。
因此,即便今天它已经支持了更为丰富的数据结构类型(如列表、集合、哈希、比特数组、字符串、HyperLogLogs等),它依然被大家看作一款基于内存(高速)的键值(Key-Value)型NoSQL数据库。
Redis区别于RDBMS的关键在于不需要数据库索引(Indexing),而通过主键检索(Key)来实现数据结构与算法,而且主键可以是任何binary-safe(二进制安全)数据类型(如子串、数字、图片、音乐甚至一段视频)。
因此Redis适用于快速查询、检索类操作(特别是以读操作为主的应用)。和所有NoSQL数据库一样,Redis也具有高度水平可扩展性(Scale-Out)。下图展示的是在2个数据中心中构建一个Redis集群,每个数据中心可以就近满足客户应用(App Server)的SLA访问时间需求(如相应时间≤200ms),这样的设计对于以读操作为主的应用类型特别适合。
2、NewSQL数据库
颠覆了CAP “理论” 的NewSQL类系统(兼具可扩展性、数据可用性与一致性)。确切地说NewSQL可以兼顾OLTP + OLAP,但在一般分类上,我们还是主要突出了它的交易、事务处理对ACID的支持上,因此归为OLTP阵营。
最早的NewSQL系统是H-Store15,由美国东海岸的四所大学(Brown、CMU、MIT和Yale)在美国国家科学基金会、加拿大工程与研究委员会及Intel大数据科技中心的资助下联合开发,于2007年面世。H-Store的意义在于它真的开发够早,要知道NewSQL这个词汇是2011年才出现的(451group分析师Matthew Aslett的2011年的一篇文章中首次提及)。
H-Store显然是一个学院派的NewSQL实现,距离商用还有相当距离,于是基于H-Store的商业版NewSQL实现VoltDB17应运而生。VoltDB的作者都是业界赫赫有名的大家,比如Michael Stonebreaker,此公在加州Berkeley任教期间开发了Ingres、Postgres等关系型数据库系统;后来转战到MIT任教又开发了C-Store、H-Store等系统。此公的学生也多是赫赫有名之辈,比如VMware的前COE,Diane Greene, Cloudera的创始人Mike Olson,Sybase的创始人Robert Epstein等。最后要提一点,Stonebreaker老先生现在已年逾花甲了(1943年生人),想来老先生开发VoltDB时已然是六十大几了,反观国内的研发人员不到30岁就都纷纷要转型做people-manager(经理),实在是令人唏嘘。没有持续多年的第一手技术累积所搭建出来的系统是很难经得起时间的检验的,写下这段文字,与读者共勉!
Michael Stonebraker 被称为数据库领域的布道者,著名的数据库科学家,美国工程院院士业界最早的商用NewSQL系统是谷歌公司经过五年内部开发后于2012年面世的Google Spanner,它具有四大NewSQL的特性:
ACID强一致性支持(用于交易处理)
SQL语言支持(向后兼容)
支持模式化表(Schematized Table)
半关系型数据模型(意味着数据多样性支持)
Spanner是第一个在全球范围内可以做到交易一致性的半关系型数据库(也就是说在各个大洲的数据中心之间的数据可以通过Spanner系统来实现读写同步)。Spanner系统主要用于服务谷歌的最赚钱的广告系统,而之前该系统是构建在一套相当复杂的分片化(Sharded)MySQL集群之上的。谷歌的Spanner系统显然是在可算作是NoSQL数据库鼻祖的BigTable系统之上的一次飞跃。
Spanner立足于高抽象层次,使用Paxos协议横跨多个数据集把数据分散到世界上不同数据中心的状态机中。出故障时,它能够在全球范围内响应客户副本之间的自动切换。当数据总量或服务器的数量发生改变时,为了平衡负载和处理故障,Spanner自动完成数据的重切片和跨机器,甚至跨数据中心的数据迁移。
区别于以往的任何已知NoSQL或分布式数据库,在技术架构上Spanner具备如下几个特点:
- 应用可以细粒度地进行动态控制数据的副本配置。应用可以详细规定:哪个数据中心包含哪些数据,数据距离用户有多远(控制用户读取数据的延迟),不同数据副本之间距离有多远(控制写操作的延迟),以及需要维护多少个副本(控制可用性和读操作性能)。数据可以动态、透明地在数据中心之间移动,从而平衡不同数据中心内资源的使用。
- 读写操作的外部一致性,时间戳控制下的跨越数据库的全球一致性的读操作。
Spanner的这两个重要的特性使得Spanner可以支持一致性的备份、一致性的 MapReduce 执行和原子性(Atomic)的模式更新,所有这些都是在全球范围内实现,即使存在正在处理中的事务也可以。
Spanner的全球时间同步机制是用一个具有GPS和原子钟的TrueTime API提供的。TrueTime API能够将不同数据中心的时间偏差缩短在10ms内。这个API可以提供一个精确的时间,同时给出误差范围。TrueTime API直观地揭示了时钟的不可靠性,它运行提供的边界更决定了时间标记。如果不确定性很大,Spanner会降低速度来等待不确定因素的消失。
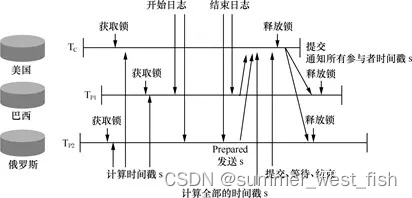
TrueTime技术被认为是Spanner可以实现跨大洋数据中心的交易强一致性的使能科技(Enabling Technology),通过它可以实现分布式lock-free的只读交易、二段锁(2PL,Two-phase Locking)写交易。下图展示的是在美国、巴西与俄罗斯三个数据中心间实现并发读写交易一致性的时序图。
Spanner系统中还有一些引领业界潮流的架构设计:
- 一个Spanner部署实例称之为一个Universe。而谷歌在全球范围内置用了3个实例:一个开发,一个测试,一个线上。因为一个Universe就能覆盖全球,谷歌认为他们不需要更多实例了。
- 每个Zone相当于一个数据中心,一个Zone在物理上必须在一起。而一个数据中心可能有多个Zone。可以在运行时添加移除Zone。一个Zone可以理解为一个BigTable部署实例。
其他业界知名的NewSQL系统还有如下:
- Clustrix:一家旧金山的创业公司的产品,Percona早前曾做过测试表明一个3节点的集群(Cluster)比一个类似处理能力的单节点MySQL服务器性能高73%,并且Clustrix的性能随节点数增加呈线性增长!
- Gemfire XD:Pivotal公司的基于内存的IMDG(In-Memory Data Grid,数据网格产品)产品,区别于基于内存的数据库的主要之处是其强大的可扩展性(通常可以到几千个节点),尽管它也能提供部分SQL访问接口,但是更多的为了实现高性能计算和实时交易处理。经典应用场景如12306网站的车票预订系统的后台就是10对X86服务器搭建而成的Gemfire XD IMDG —每天14亿次页面浏览、每秒超过4万次访问,服务超过5,700个火车站19。
- SAP HANA:恐怕是业界最为知名的商用NewSQL型数据库系统了。一款完全基于内存的关系型列数据库(Column-oriented RDBMS),支持实时的在线分析处理(OLAP)与交易处理(OLTP)。SAP为了推出HANA前后收购了多家公司的核心技术,其中至少3个技术值得一提:基于内存TREX列搜索引擎、基于内存的P*Time OLTP数据库以及基于内存的liveCache引擎。HANA的战略重要性如此之高,SAP似乎已经把全部赌注压在其上了。整个业界对于实时性、低延迟的越来越高的期待似乎与SAP的赌注颇为吻合。到目前为止SAP HANA的客户每年在以翻倍的速度增长,而整个SAP的云计算 + 大数据分析战略似乎都围绕着HANA在构建。
最后,关于NewSQL和SQL,SQL作为一门数据库的操作语言,它有着一些天然的缺陷,而这种缺陷已经在阻碍行业的向前发展。熟悉SQL的同学都会明白几点:
- SQL不是一个递归型语言,也就是说SQL不善于处理深度的数据关联、穿透,而这些诉求恰恰是业务方所看重的;
- SQL同样不善于处理高维数据,或者可以理解为多表链接就会造成SQL类数据库的性能指数级下降,SQL与关系型数据库相伴而生,都是为二维表的世界而存在的,但是高维的世界用二维表来表达,杯水车薪;
- SQL是面向存储进程的,而存储进程是典型的T+1类型的操作,大量的存储进程拖累了数据库,甚至把数据库的实时化OLTP能力弱化为数仓的OLAP能力,这种弱化过去几十年大行其道,不得不说是关系型数据库的一段“黑历史”;
- SQL终将让路给GQL,过去40年来,数据库行业只有两个查询语言标准委员会,SQL和GQL(图查询语言),期待GQL的标准尽快出台。而GQL标准委员会的设立就是为了解决上面的几个问题。
二、OLAP 阵营
OLAP(在线分析处理):MapReduce、Hadoop、Spark等
OLAP阵营主要有两大主流方向:
一个是基于MapReduce而构建的Hadoop生态圈
一个是MPP(大规模并行)数据库阵营
1、Hadoop
Hadoop的整体架构其实非常简单,用公式表达就是:
Hadoop = HDFS + MapReduce
HDFS 负责分布式存储
MapReduce 负责分布式计算
HDFS分布式文件系统的设计核心理念(设计目标)有三条:
(1)可以扩展到数以千计的节点
(2)假设硬件、软件的故障、失败十分普遍
(3)一次写入,多次读写(写在HDFS中特指文件添加操作)
MapReduce = Map() + Reduce()
其中,Map()负责分而治之,Reduce()负责合并及减少基数。调用者只需要实现Map()与Reduce()的接口。
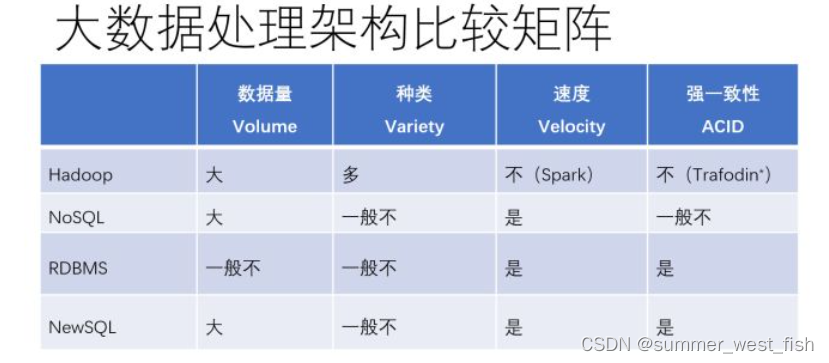
三、MPP 阵营
MPP(大规模并行处理):Greenplum、Teradata Aster等
和MapReduce类似,两者都采用大规模并行处理架构来对海量数据进行以大数据分析为主的工作,不同之处在于MPP通常原生支持并行的关系型查询与应用,不过这一点,Hadoop阵营也在逐渐通过在HDFS之上提供SQL查询接口来支持查询,甚至包括关系型查询。
MPP数据库通常具有如下特点。
- 无共享架构(Shared-Nothing):每台服务器有独立的存储、内存及CPU,可以动态增删节点
- 分区(Partitioning):数据分区可以跨多节点,通过分布式查询优化提高系统吞吐率
- 在OLAP基础上通常也支持OLTP类应用
MPP类型数据库阵营的玩家不少,从Amazon Redshift 到 Pivotal的Greenplum 到 Teradata的Aster到 IBM的Netezza,不一而足。不过除了Greenplum,其他产品形态多数为闭源(Closed-Source)商业产品。
四、流数据处理阵营
流数据管理:CEP/Esper、Storm、Spark Stream、Flume等
数据流管理来自于这样一个概念:
数据的价值随着时间的流逝而降低,所以需要在事件发生后尽快进行处理,最好是在事件发生时就进行处理(即实时处理),对事件进行一个接一个处理,而不是缓存起来进行批处理(如Hadoop)。在数据流管理中,需要处理的输入数据并不存储在可随机访问的磁盘或逻辑缓存中,它们以数据流的方式源源不断地到达。