初始化
在“开始”中运行pgadmin4,输入密码,连接实例,创建测试数据库:hrdb

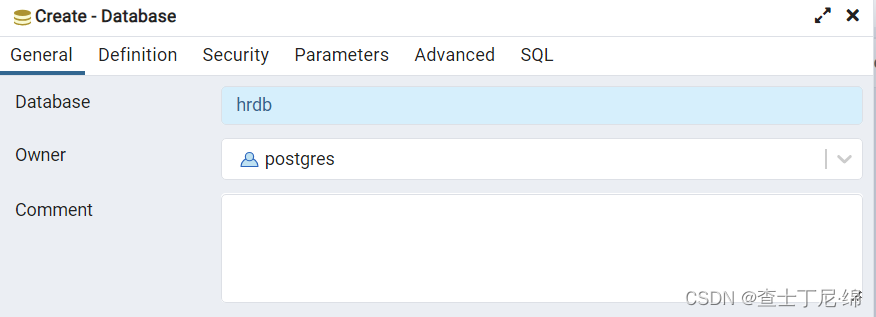 开启查询工具面板。
开启查询工具面板。

https://download.csdn.net/download/hy19930118/88419281
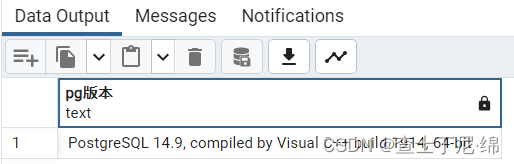
SELECT version() AS "pg版本"
简单查询
SELECT first_name, last_name FROM employees;
SELECT first_name AS "名字", last_name "姓氏"
FROM employees;

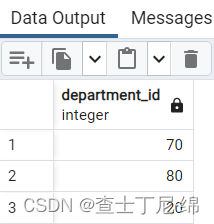
SELECT DISTINCT department_id FROM employees;
/*
查询不同部门编号
*/
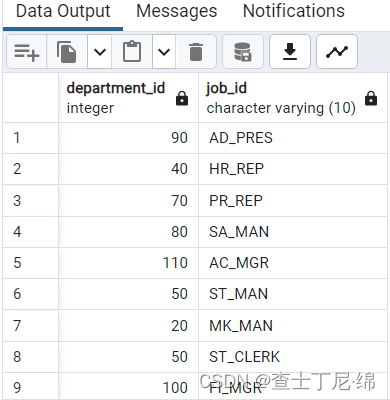
SELECT DISTINCT department_id,job_id --查询部门、职位组合的不同值
FROM employees;
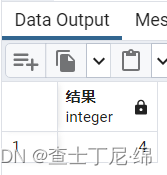
SELECT 1+3 AS "结果"
条件过滤
SELECT *
FROM employees
WHERE employee_id = 100; -- 等于
/*
WHERE employee_id != 100; -- 不等于
WHERE employee_id <> 100; -- 不等于
WHERE hire_date > '2005-01-01'; -- 大于
WHERE hire_date < '2005-01-01'; -- 小于
WHERE hire_date >= '2005-01-01'; -- 大于等于
WHERE salary BETWEEN 10000 AND 12000; -- 之间
WHERE salary IN (10000,11000); -- 之间
*/
模糊查询
SELECT first_name
FROM employees
WHERE first_name LIKE 'S%';
SELECT first_name
FROM employees
WHERE first_name LIKE '%s'; -- 多字符后面一个s
-- SELECT 'xasds' LIKE '%s'; --返回true
SELECT first_name
FROM employees
WHERE first_name LIKE '%s%';
-- SELECT 'vgskl' LIKE '%s%'; -- 返回true
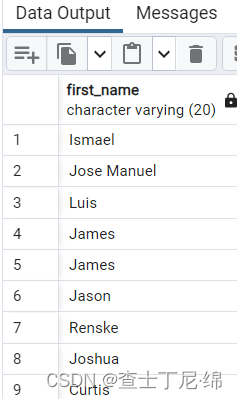
SELECT first_name
FROM employees
WHERE first_name LIKE 's_'; -- s后面单独一个字符
-- SELECT 'sa' LIKE 's_'; -- 返回true
-- 转义,查询包含25%的字段
SELECT 字段1 FROM 表名 WHERE 字段2 LIKE '%25\%'; --默认
SELECT 字段1 FROM 表名 WHERE 字段2 LIKE '%25#%%' ESCAPE #; --自定义
SELECT first_name
FROM employees
WHERE first_name NOT LIKE 'S%'; --区分大小写
-- ILIKE --不区分大小写
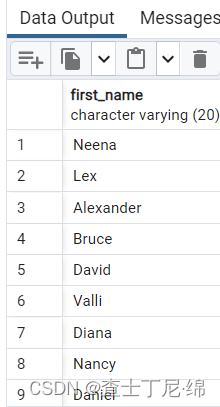
空值
SELECT * FROM employees WHERE manager_id IS NULL;-- null为缺失值
/*
SELECT * FROM employees WHERE manager_id NOTNULL;
*/
SELECT 1 IS DISTINCT FROM 2; --1与2不同?返回true
SELECT 1 IS DISTINCT FROM 1; --1与1不同?返回false
SELECT 1 IS NOT DISTINCT FROM 1; --双重否定是肯定,1与1相同?返回true
SELECT 1 IS NOT DISTINCT FROM 2; --1与2相同?返回false
SELECT 1 IS DISTINCT FROM null; --DISTINCT支持对空值判断,返回true
SELECT * FROM employees WHERE manager_id IS NOT DISTINCT FROM null; --manager_id为空值

运算符
SELECT *
FROM employees
-- WHERE first_name = 'Steven' AND last_name = 'King';
WHERE first_name = 'Steven' OR last_name = 'King';
SELECT 1=1 OR 1/0=1; --短路运算:返回true
SELECT 1=0 AND 2-1=1; --短路运算:返回fasle
/*
SELECT * FROM employees WHERE salary = 10000 OR salary = 12000 AND department_id = 80;
查找月薪在10000到12000并且部门编号为80的员工。AND优先级比OR高,所以条件应该为salary = 10000 OR (salary = 12000 AND department_id = 80)
*/
(salary = 10000 OR salary = 12000) AND department_id = 80
SELECT * FROM employees WHERE NOT first_name = 'Steven';
/*
NOT BETWEEN
NOT LIKE
NOT IN
*/
排序
SELECT employee_id, first_name, last_name, hire_date, salary
FROM employees
ORDER BY first_name; --按字母,默认升序
ORDER BY hire_date ASC; --升序
ORDER BY hire_date DESC; --降序
SELECT employee_id, first_name, last_name, hire_date, salary
FROM employees
ORDER BY first_name, last_name DESC --姓按照升序排,名按照降序排


SELECT employee_id, first_name, last_name, hire_date, salary
FROM employees
ORDER BY 2, 3 DESC --也可输入要查询字段的顺序号码
SELECT employee_id, manager_id
FROM employees
ORDER BY manager_id DESC; --排序时null是最大的值
SELECT employee_id, manager_id
FROM employees
ORDER BY manager_id NULLS FIRST; --指定排序时null是第一
限制返回数量
-- 前十名
SELECT first_name, last_name, salary
FROM employees
ORDER BY salary
-- FETCH FIRST 10 ROWS ONLY;
LIMIT 10; --无相同值
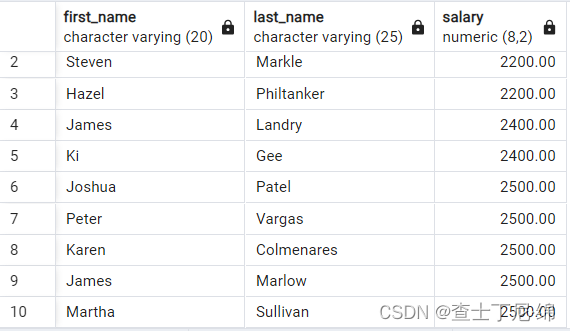
SELECT first_name, last_name, salary
FROM employees
ORDER BY salary
FETCH FIRST 10 ROWS WITH TIES;
-- 返回数据包含相同值
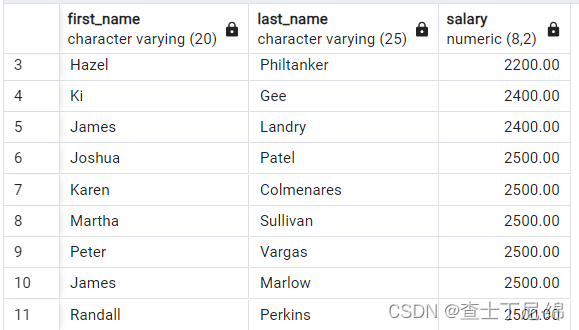
SELECT first_name, last_name, salary
FROM employees
ORDER BY salary
OFFSET 10 ROWS --实现翻页,第一次1-10,第二次11-20,第三次,21-30
-- OFFSET 20 ROWS
-- OFFSET 30 ROWS
FETCH FIRST 10 ROWS ONLY;
SELECT first_name, last_name, salary
FROM employees
ORDER BY salary
LIMIT 10 OFFSET 10; --同实现翻页
-- LIMIT 10 OFFSET 20;
-- LIMIT 10 OFFSET 20;
汇总统计
SELECT COUNT(*), SUM(salary), AVG(SALARY), MAX(salary), MIN(salary)
FROM employees;
-- 行数、和、平均、最大、最小
SELECT COUNT(*), COUNT(manager_id) FROM employees;
--因为实验表中有一名员工的manager_id为null,聚合函数会忽略null,但count(*)特殊
SELECT COUNT(DISTINCT manager_id) FROM employees; -- 聚合函数中的distinct会先去重
SELECT STRING_AGG(first_name, ';') FROM employees; --字符串聚合,以分号隔离
SELECT STRING_AGG(first_name, ';' ORDER BY first_name) FROM employees; --添加排序
分组统计
SELECT hire_date, COUNT(*)
FROM employees
GROUP BY hire_date;
SELECT extract(year from hire_date), COUNT(*)
FROM employees
GROUP BY extract(year from hire_date);
-- GROUP BY 1;
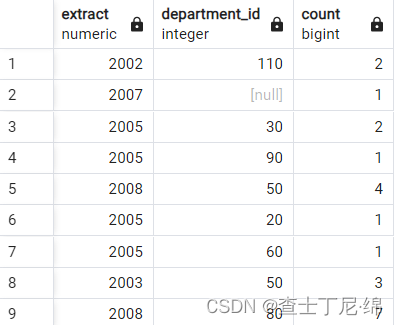
SELECT extract(year from hire_date), department_id, COUNT(*)
FROM employees
GROUP BY 1,2;
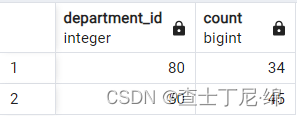
SELECT department_id, COUNT(*)
FROM employees
GROUP BY department_id
HAVING COUNT(*)>10;
-- 对分组后的数据进行二次统计用having,不能用where